Simple but effective Voice Activity Detection real-time algorithm
Below is a translation of the article.
A SIMPLE BUT EFFICIENT REAL-TIME VOICE ACTIVITY DETECTION ALGORITHM
M.H. Moattar and MM Homayonpour
Laboratory for Intelligent Sound and Speech Processing (LISSP), Computer Engineering and Information Technology Dept., Amirkabir University of Technology, Tehran, Iran
Original link
The Voice Activity Detection Algorithm (hereinafter referred to as VAD) is a very important method in speech and audio processing applications. The effectiveness of most, if not all, speech / audio processing methods depends strongly on the effectiveness of the VAD algorithm used. An ideal voice activity detector should be independent of the application's area of application, noise level and be least dependent on the maximum parameters of the application in which it is used. This article proposes a close to ideal VAD algorithm, which is both easy to implement and resistant to noise. The proposed method uses such short-term characteristics as Spectral Flatness (SF) (spectral flatness, evenness) and Short-term Energy, which makes the method suitable for use in real time. This method was tested on several records with different noise levels and was compared with recently proposed methods. Experiments have shown satisfactory results at different levels of noise.
Voice Activity Detection (VAD) —that is, the detection of silence in a speech or audio signal is a very important task for many applications that work with audio or speech, including encoding, recognizing, enhancing speech intelligibility, and audio indexing. For example, in the GSM 729 standard [1], two VAD modules are used for coding with a different number of bits in the sample. VAD noise tolerance is also very important for speech recognition (Automatic Speech Recognition ASR). A good detector will improve the accuracy and speed of any ASR in noisy environments.
')
According to [2], the necessary characteristics for an ideal voice activity detector are: reliability, stability, accuracy, adaptability, simplicity, possibility of application in real time, without information about the present noise. To achieve noise resistance is the hardest. Under conditions of high SNR (Signal-to-noise ratio), the simplest VAD algorithms work satisfactorily, but under conditions of low SNR, all VAD algorithms degrade to a certain extent. At the same time, the VAD algorithm must remain simple to meet the requirement of real-time applicability. Therefore, simplicity and noise resistance are two essential characteristics of a practical speech activity detector.
Many VAD algorithms have been proposed, the main difference of which is in the characteristics used. Among all the characteristics, Short-term Energy and zero-crossing rate were used more often because of their simplicity. However, they strongly degrade in the presence of noise. In order to correct this disadvantage, different stable acoustic characteristics were proposed based on the autocorrelation function [3, 4], spectrum (spectrum based) [5], and power in a narrow band (power in the band-limited region) [1, 6 , 7], MFCC (Mel-frequency Cepstral Coefficients [4] - Cepstral coefficients of tonal frequency. You can read in the book spbu), delt spectral frequencies (delta line spectral frequencies) [6] and higher-order statistics [8]. Experiments have shown that the use of these characteristics leads to an increase in noise resistance of VAD. Some papers suggest using different characteristics in combination with some modeling algorithms like CART (Classification and Regression Tree) [9] and ANN (Artificial Neural-Network) [10], however, these algorithms are comparable in complexity to VAD itself.
On the other hand, some methods use noise models [11], or use an improved speech spectrum obtained after statistical filtering of noise by a Wiener filter [7, 12]. Most of the characteristics suggest the presence of stationary noise for a certain period, so they are sensitive to changes in the SNR of the signal being processed. Some papers offer noise computation and adaptation to improve VAD resiliency [13], but these methods have greater computational complexity.
Also, there are VADs standards that are used to create new detection methods. Among them, GSM 729 [1], ETSI AMR [14] and AFE [15]. For example, the GSM 729 standard uses a linear spectrum of a pair of frequencies, full-band energy and low-band energy, zero-crossing rate, and applies a classifier using fixed boundaries in a limited space [1].
In this paper, a VAD algorithm is proposed that is both easy to implement and can be used for real-time speech / audio processing and also provides satisfactory noise immunity. Section 3 examines in detail the algorithm proposed by VAD.
In the proposed method, we use three different characteristics for each frame. The first characteristic is short-term energy (E). Energy is the most frequently used characteristic in the definition of speech / silence. However, it becomes ineffective under noise conditions, especially at low SNRs. Therefore, we use two more characteristics, which are calculated from the frequencies.
The second characteristic is a spectral flatness measure (SFM - Spectral Flatness Measure). The spectrum noise measurement shows itself well in voice / non-voice detection and silence detection.
It is considered SFM according to the following formula:
SMF db = 10log 10 (G m / A m )
Where A m and G m are respectively the arithmetic mean and the geometric mean of speech spectrum.
In addition to these two characteristics, it was found that the speech component with the most dominant frequency component can be very useful for distinguishing frames with speech and silence. In this work, this characteristic is denoted by F. It is easily calculated by finding the frequency that corresponds to the maximum value of the spectrum | S (k) |.
In the proposed method for detecting voice activity, all three characteristics are calculated simultaneously for each frame.
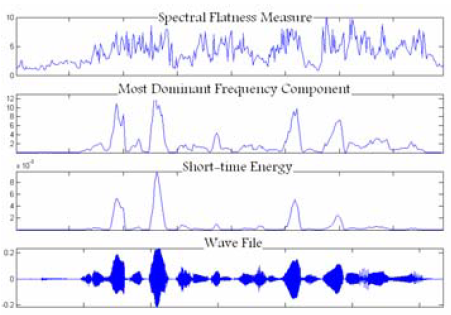
Image 1. Characteristic values on a clear speech signal

Figure 2. Characteristic value on a signal damaged by white noise.
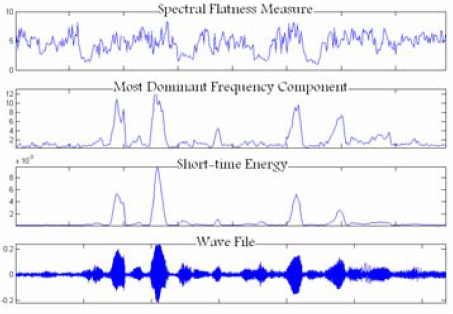
Figure 3. Characteristic value on a signal damaged by babble noise
Images 1-3 represent the effectiveness of these three characteristics on a clean and noise-damaged signal.
The proposed algorithm begins with splitting the audio signal into frames. In our implementation, the window function is not used. The first N frames are used to initialize the threshold value. Three characteristics are calculated for each incoming frame. An audio frame is considered speech if the value of more than one characteristic exceeds the threshold value. The full procedure of the proposed method is presented below:
The algorithm has three parameters that must be set first. These parameters were found automatically on the final set of clear speech signals. Below are the optimal values obtained as a result of experiments.
Energy_PrimThresh = 40
F_PrimThresh (Hz) = 185
SF_PrimThresh = 5
The original article provides the results of experiments conducted in conditions of different noise. I would like to know the opinion of the community about this topic and about the translation itself. Does it make sense to continue to upload translations on this topic? On all the inaccuracies of the translation, write errors in private messages.
I did not find how to indicate that this is a translation, except to assign a post to the Translations hub.
A SIMPLE BUT EFFICIENT REAL-TIME VOICE ACTIVITY DETECTION ALGORITHM
M.H. Moattar and MM Homayonpour
Laboratory for Intelligent Sound and Speech Processing (LISSP), Computer Engineering and Information Technology Dept., Amirkabir University of Technology, Tehran, Iran
Original link
SUMMARY
The Voice Activity Detection Algorithm (hereinafter referred to as VAD) is a very important method in speech and audio processing applications. The effectiveness of most, if not all, speech / audio processing methods depends strongly on the effectiveness of the VAD algorithm used. An ideal voice activity detector should be independent of the application's area of application, noise level and be least dependent on the maximum parameters of the application in which it is used. This article proposes a close to ideal VAD algorithm, which is both easy to implement and resistant to noise. The proposed method uses such short-term characteristics as Spectral Flatness (SF) (spectral flatness, evenness) and Short-term Energy, which makes the method suitable for use in real time. This method was tested on several records with different noise levels and was compared with recently proposed methods. Experiments have shown satisfactory results at different levels of noise.
1. INTRODUCTION
Voice Activity Detection (VAD) —that is, the detection of silence in a speech or audio signal is a very important task for many applications that work with audio or speech, including encoding, recognizing, enhancing speech intelligibility, and audio indexing. For example, in the GSM 729 standard [1], two VAD modules are used for coding with a different number of bits in the sample. VAD noise tolerance is also very important for speech recognition (Automatic Speech Recognition ASR). A good detector will improve the accuracy and speed of any ASR in noisy environments.
')
According to [2], the necessary characteristics for an ideal voice activity detector are: reliability, stability, accuracy, adaptability, simplicity, possibility of application in real time, without information about the present noise. To achieve noise resistance is the hardest. Under conditions of high SNR (Signal-to-noise ratio), the simplest VAD algorithms work satisfactorily, but under conditions of low SNR, all VAD algorithms degrade to a certain extent. At the same time, the VAD algorithm must remain simple to meet the requirement of real-time applicability. Therefore, simplicity and noise resistance are two essential characteristics of a practical speech activity detector.
Many VAD algorithms have been proposed, the main difference of which is in the characteristics used. Among all the characteristics, Short-term Energy and zero-crossing rate were used more often because of their simplicity. However, they strongly degrade in the presence of noise. In order to correct this disadvantage, different stable acoustic characteristics were proposed based on the autocorrelation function [3, 4], spectrum (spectrum based) [5], and power in a narrow band (power in the band-limited region) [1, 6 , 7], MFCC (Mel-frequency Cepstral Coefficients [4] - Cepstral coefficients of tonal frequency. You can read in the book spbu), delt spectral frequencies (delta line spectral frequencies) [6] and higher-order statistics [8]. Experiments have shown that the use of these characteristics leads to an increase in noise resistance of VAD. Some papers suggest using different characteristics in combination with some modeling algorithms like CART (Classification and Regression Tree) [9] and ANN (Artificial Neural-Network) [10], however, these algorithms are comparable in complexity to VAD itself.
On the other hand, some methods use noise models [11], or use an improved speech spectrum obtained after statistical filtering of noise by a Wiener filter [7, 12]. Most of the characteristics suggest the presence of stationary noise for a certain period, so they are sensitive to changes in the SNR of the signal being processed. Some papers offer noise computation and adaptation to improve VAD resiliency [13], but these methods have greater computational complexity.
Also, there are VADs standards that are used to create new detection methods. Among them, GSM 729 [1], ETSI AMR [14] and AFE [15]. For example, the GSM 729 standard uses a linear spectrum of a pair of frequencies, full-band energy and low-band energy, zero-crossing rate, and applies a classifier using fixed boundaries in a limited space [1].
In this paper, a VAD algorithm is proposed that is both easy to implement and can be used for real-time speech / audio processing and also provides satisfactory noise immunity. Section 3 examines in detail the algorithm proposed by VAD.
2. SHORT-TERM FEATURE (short term performance)
In the proposed method, we use three different characteristics for each frame. The first characteristic is short-term energy (E). Energy is the most frequently used characteristic in the definition of speech / silence. However, it becomes ineffective under noise conditions, especially at low SNRs. Therefore, we use two more characteristics, which are calculated from the frequencies.
The second characteristic is a spectral flatness measure (SFM - Spectral Flatness Measure). The spectrum noise measurement shows itself well in voice / non-voice detection and silence detection.
It is considered SFM according to the following formula:
SMF db = 10log 10 (G m / A m )
Where A m and G m are respectively the arithmetic mean and the geometric mean of speech spectrum.
In addition to these two characteristics, it was found that the speech component with the most dominant frequency component can be very useful for distinguishing frames with speech and silence. In this work, this characteristic is denoted by F. It is easily calculated by finding the frequency that corresponds to the maximum value of the spectrum | S (k) |.
In the proposed method for detecting voice activity, all three characteristics are calculated simultaneously for each frame.
Image 1. Characteristic values on a clear speech signal
Figure 2. Characteristic value on a signal damaged by white noise.
Figure 3. Characteristic value on a signal damaged by babble noise
Images 1-3 represent the effectiveness of these three characteristics on a clean and noise-damaged signal.
3. PROPOSED VAD ALGORITHM
The proposed algorithm begins with splitting the audio signal into frames. In our implementation, the window function is not used. The first N frames are used to initialize the threshold value. Three characteristics are calculated for each incoming frame. An audio frame is considered speech if the value of more than one characteristic exceeds the threshold value. The full procedure of the proposed method is presented below:
1 - Frame_Size = 10ms - ( Num_of_frames ) // 2 - . // * (Energy_PrimTreshhold) * F (F_PrimTreshhold) * SFM (SF_PrimTreshhold) 3 - For i 1 Num_of_frames 3.1 - (E(i)) 3.2 - FFT 3.2.1 - F(i) = arg max (S(k)) - 3.2.2 - Measure(SFM(i)) 3.3 - 30 - , (Min_E), F (Min_F), SMF (Min_SF) 3.4 - E, F, SFM * Tresh_E = Energy_PrimTresh * log(Min_E) * Tresh_F = F_PrimTresh * Tresh_SF = SF_PrimTresh 3.5 - Counter = 0 * ((E(i) - Min_E) >= Tresh_E) Counter++ * ((F(i) - Min_F) >= Tresh_F) Counter++ * ((SFM(i) - Min_SF) >= Tresh_SF) Counter++ 3.6 - Counter > 1 , 3.7 - , tythubb Min_E = ((Silence_Count * Min_E) + E(i)) / (Silence_Count + 1) 3.8 Tresh_E = Energy_PrimTresh * log(Min_E) 4 - 10 5 - 5 . The algorithm has three parameters that must be set first. These parameters were found automatically on the final set of clear speech signals. Below are the optimal values obtained as a result of experiments.
Energy_PrimThresh = 40
F_PrimThresh (Hz) = 185
SF_PrimThresh = 5
The original article provides the results of experiments conducted in conditions of different noise. I would like to know the opinion of the community about this topic and about the translation itself. Does it make sense to continue to upload translations on this topic? On all the inaccuracies of the translation, write errors in private messages.
I did not find how to indicate that this is a translation, except to assign a post to the Translations hub.
Links
[1] A. Benyassine, E. Shlomot, HY Su, D. Massaloux, C. Lamblin and JP Petit, “ITU-T Recommendation G.729 Annex B: optimized for V. 70 digital simultaneous voice and data applications, "IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] MH Savoji, "Speech Communication, pp." 45-60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] RE Yantorno, KL Krishnamachari and JM Lovekin, “The Spectral Autocorrelation Peak Valley Ratio (SAPVR) - A Prod. IEEE Int. Workshop Intell. Signal Process. 2001.
[6] M. Marzinzik and B. Kollmeier, “IEEE Trans. Speech Audio Process, 10, pp. 109-118, 2002.
[7] ETSI standard document, ETSI ES 202 050 V 1.1.3., 2003.
[8] K. Li, NS Swamy and MO Ahmad, “An improved voice activity,” IEEE Trans. Speech Audio Process., 13, pp. 965-974, 2005.
[9] WH Shin, "Speech / non-speech classification using robust endpoint detection," ICASSP, 2000.
[10] GD Wuand and CT Lin, “Word boundary detection system with noisy environment,” IEEE Trans. Speechand Audio Processing, 2000.
[11] A. Lee, K. Nakamura, R. Nisimura, H. Saruwatari and K. Shikano, “Noise robust world world spoken dialogue using GMM based rejection,” Interspeech, pp. 173-176, 2004.
[12] J. Sohn, NS Kim and W. Sung, “A statistical modelbased voice activity detection,” IEEE Signal Process. Lett., Pp. 1-3, 1999.
[13] B. Lee and M. Hasegawa-Johnson, “Minimum Mean Squared Error Around,” in Proc. Biennial on DSP for In-Vehicle and Mobile Systems, Istanbul, Turkey, June 2007.
[14] ETSI EN 301 708 recommendations, “Voice activity detector for adaptive multi-rate (AMR) speech traffic channels,” 1999.
REFERENCES:
[1] A. Benyassine, E. Shlomot, HY Su, D. Massaloux, C. Lamblin and JP Petit, “ITU-T Recommendation G.729 Annex B: optimized for V. 70 digital simultaneous voice and data applications, "IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] MH Savoji, "Speech Communication, pp." 45-60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] RE Yantorno, KL Krishnamachari and JM Lovekin, “The Spectral Autocorrelation Peak Valley Ratio (SAPVR) - A Prod. IEEE Int. Workshop Intell. Signal Process. 2001.
[6] M. Marzinzik and B. Kollmeier, “IEEE Trans. Speech Audio Process, 10, pp. 109-118, 2002.
[7] ETSI standard document, ETSI ES 202 050 V 1.1.3., 2003.
[8] K. Li, NS Swamy and MO Ahmad, “An improved voice activity,” IEEE Trans. Speech Audio Process., 13, pp. 965-974, 2005.
[9] WH Shin, "Speech / non-speech classification using robust endpoint detection," ICASSP, 2000.
[10] GD Wuand and CT Lin, “Word boundary detection system with noisy environment,” IEEE Trans. Speechand Audio Processing, 2000.
[11] A. Lee, K. Nakamura, R. Nisimura, H. Saruwatari and K. Shikano, “Noise robust world world spoken dialogue using GMM based rejection,” Interspeech, pp. 173-176, 2004.
[12] J. Sohn, NS Kim and W. Sung, “A statistical modelbased voice activity detection,” IEEE Signal Process. Lett., Pp. 1-3, 1999.
[13] B. Lee and M. Hasegawa-Johnson, “Minimum Mean Squared Error Around,” in Proc. Biennial on DSP for In-Vehicle and Mobile Systems, Istanbul, Turkey, June 2007.
[14] ETSI EN 301 708 recommendations, “Voice activity detector for adaptive multi-rate (AMR) speech traffic channels,” 1999.
Source: https://habr.com/ru/post/192954/
All Articles