Yandex, robots and Siberia - as we did a search system for the downloaded image
Today, Yandex has launched a search for images on the downloaded image . In this post, we want to talk about the technology behind this service and how it was done.
Technology inside Yandex is called Siberia. From CBIR - Content Based Image Retrieval .
Of course, the problem itself is not new, and a lot of research is devoted to it. But to make a prototype that works on an academic collection, and to build an industrial system that works with billions of images and a large flow of requests are very different stories.
')

There are three scenarios in which you need to search for the loaded picture and which we needed to learn how to process.
There are different approaches with which you can find similar images. The most common is based on the representation of the image in the form of visual words - quantized local descriptors, computed at particular points. Especially called the points that are most stable with changes in the image. To find them, the image is processed with special filters. The description of the areas around these points in digital form is a descriptor. To turn descriptors into visual words, a dictionary of visual words is used. It is obtained by clustering all descriptors counted for a representative set of images. In the future, each newly calculated descriptor is assigned to the corresponding cluster - this is how quantized descriptors (visual words) are obtained.
The process of searching for an image from a loaded picture in large collections is usually built in this order:
The method of image retrieval by image-request used by us is similar to the above traditional approach. However, checking the relative position of local features requires significant computational resources. And in order to search for a huge collection of images stored in the Yandex search index, we had to find more efficient ways to solve the problem. Our indexing method can significantly reduce the number of images that can be considered relevant to the sample (request).
The key to our implementation of the search for candidates is the transition from indexing visual words to indexing more discriminative traits, a special index structure.
For the selection of candidates two methods showed themselves equally well:
During validation, we use our own implementation of clustering transformations between images.
Now we will rise on level up and we will look at the product scheme as a whole.
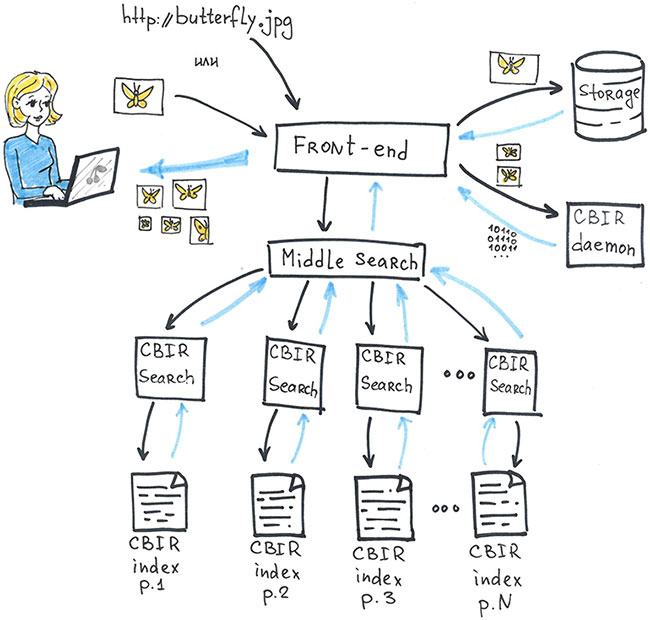
Each basic search works with its part of the index. This ensures the scalability of the system: as the index grows, new fragments and new replicas of the basic search are added. And fault tolerance is provided by duplicating basic searches and index fragments.
And one more important nuance. When we built our image search index, in order to improve the search efficiency, we used the knowledge we already have about duplicate images. We used it in such a way that from each group of duplicates we took only one representative and included it in the search index by image. The logic is simple: if the picture is relevant to the request, then all its copies will be the same relevant answer.


In this version, we expected to find only copies of the image, either entirely coinciding with the loaded picture, or containing matching fragments. But now our solution shows the ability to generalize: sometimes there is not just the same picture, but another picture, but containing the same object. For example, it often manifests itself in architecture.




This is our first step in finding images by content. Of course, we will develop similar technologies and make new products based on them. And what is something, and we have enough ideas and desires for this.
Technology inside Yandex is called Siberia. From CBIR - Content Based Image Retrieval .
Of course, the problem itself is not new, and a lot of research is devoted to it. But to make a prototype that works on an academic collection, and to build an industrial system that works with billions of images and a large flow of requests are very different stories.
')
What is all this for?
There are three scenarios in which you need to search for the loaded picture and which we needed to learn how to process.
- A person needs the same or a similar picture, but in a different resolution (usually the largest), or maybe of a different color, better quality or not cropped.
- You need to understand what is in the picture. In this case, a short description next to the image is enough to make it clear who or what is on it.
- It is necessary to find a site on which there is the same picture. For example, when I wanted to read about what is in the picture. Or look at the same pictures. Or buy what is shown in the picture - in this case, shops are needed.
How it works?
There are different approaches with which you can find similar images. The most common is based on the representation of the image in the form of visual words - quantized local descriptors, computed at particular points. Especially called the points that are most stable with changes in the image. To find them, the image is processed with special filters. The description of the areas around these points in digital form is a descriptor. To turn descriptors into visual words, a dictionary of visual words is used. It is obtained by clustering all descriptors counted for a representative set of images. In the future, each newly calculated descriptor is assigned to the corresponding cluster - this is how quantized descriptors (visual words) are obtained.
The process of searching for an image from a loaded picture in large collections is usually built in this order:
- Getting a set of visual words for the loaded image.
- Search for candidates by inverted index, which, according to a given set of visual words, determines the list of images containing it.
- Checking the relative position of the matching descriptors for the sample image and the image under study. This is the stage of validation and ranking of candidates. Clustering of Hough or RANSAC transformations is traditionally used.
Ideas of the approach are presented in the articles:
- J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman. Object retrieval with large vocabularies and fast spatial matching. In CVPR, 2007
- J. Sivic and A. Zisserman. Video google: a text retrieval approach to object matching in videos. In ICCV, 2003.
- James Philbin Joseph Sivic Andrew Zisserman Geometry Lens Dirichlet Allocation for a Large-scale Image Datasets (Items 3.1, 3.2)
The method of image retrieval by image-request used by us is similar to the above traditional approach. However, checking the relative position of local features requires significant computational resources. And in order to search for a huge collection of images stored in the Yandex search index, we had to find more efficient ways to solve the problem. Our indexing method can significantly reduce the number of images that can be considered relevant to the sample (request).
The key to our implementation of the search for candidates is the transition from indexing visual words to indexing more discriminative traits, a special index structure.
For the selection of candidates two methods showed themselves equally well:
- Indexing high-level features or visual phrases (phrases). They are a combination of visual words and parameters that characterize the relative position and other relative characteristics of the corresponding local features of the image.
- Multi-index, where the key is composed of quantized parts of descriptors (product quantization). The method was published: download.yandex.ru/company/cvpr2012.pdf
During validation, we use our own implementation of clustering transformations between images.
Now we will rise on level up and we will look at the product scheme as a whole.
- User picture is in temporary storage.
- From there, a reduced copy of the image gets into the daemon, where descriptors and visual words are computed for the image and a search query is formed from them.
- The request is sent first to the average meta-search and from there is distributed to the basic search. On each basic search there can be a set of images.
- Found images are sent back to the average meta-search. There the results are merged, and the resulting ranked list is shown to the user.
Each basic search works with its part of the index. This ensures the scalability of the system: as the index grows, new fragments and new replicas of the basic search are added. And fault tolerance is provided by duplicating basic searches and index fragments.
And one more important nuance. When we built our image search index, in order to improve the search efficiency, we used the knowledge we already have about duplicate images. We used it in such a way that from each group of duplicates we took only one representative and included it in the search index by image. The logic is simple: if the picture is relevant to the request, then all its copies will be the same relevant answer.
In this version, we expected to find only copies of the image, either entirely coinciding with the loaded picture, or containing matching fragments. But now our solution shows the ability to generalize: sometimes there is not just the same picture, but another picture, but containing the same object. For example, it often manifests itself in architecture.
This is our first step in finding images by content. Of course, we will develop similar technologies and make new products based on them. And what is something, and we have enough ideas and desires for this.
Source: https://habr.com/ru/post/192404/
All Articles