Data Center Risks: Engineering System Redundancy
It is necessary to start repairing it before it breaks - the broken one can be repaired much more reluctantly.
Yuri Tatarkin
 After secured walls and a roof overhead for the data center (the article “Data Center Risks: Choosing a Location” ), the next step in ensuring its resiliency should be the redundancy of engineering systems. By building data centers for more than 10 years, we made sure that not all customers fully realize the importance of duplicating basic communications. Spaceships and those fall, and the equipment in the data center, ideally, should work 365 days a year and 24 hours a day. Any part that has failed or needs to be prevented should be replaced without interrupting the operation of all critical services.
After secured walls and a roof overhead for the data center (the article “Data Center Risks: Choosing a Location” ), the next step in ensuring its resiliency should be the redundancy of engineering systems. By building data centers for more than 10 years, we made sure that not all customers fully realize the importance of duplicating basic communications. Spaceships and those fall, and the equipment in the data center, ideally, should work 365 days a year and 24 hours a day. Any part that has failed or needs to be prevented should be replaced without interrupting the operation of all critical services.
As our readers rightly pointed out, not all companies need a reliable data center. For some, its smooth operation is not a matter of concern, and many will prefer to store their data in a public cloud. This public is intended to a greater extent for those who, for whatever reason of security or communication channels, made their choice in favor of their own data center and services with at least three nines available (idle time not more than 1.6 hours per year) .
According to the standards of the Uptime Institute, four levels of fault tolerance of the data center infrastructure are distinguished:
')
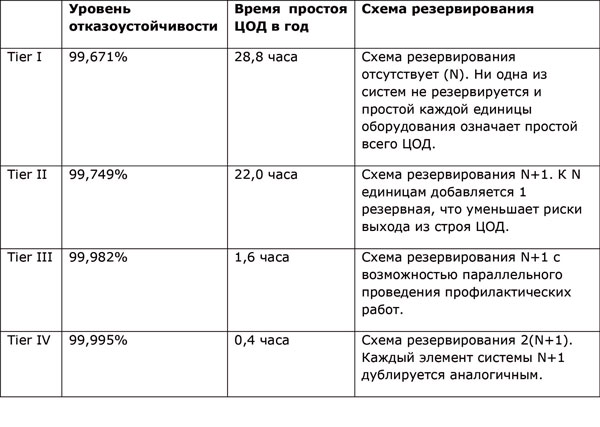
The use of Tier classification implies that all engineering systems and data center components, up to the fuel supply for a diesel generator, are perceived as a whole. The presence of at least one unreserved component leads to a decrease in the level of fault tolerance and an increase in the possible hours of data center idle time. The number of such components, as well as statistics on planned and unplanned data center failures per year, affect the allowable downtime. For example, a Tier I data center is characterized by unplanned outages 1.2 times per year. Plus, due to the lack of backup systems, the data center will not work two more times for twelve hours during scheduled maintenance. As a result, the total idle time will be calculated as: 12 + 12 + 4x1.2 = 28.8 hours.
To calculate the level of fault tolerance in percent, you need: ((t work - idle t) × 100%) / t work, where
t work - the maximum number of data center operating hours per year (24 hours a day, 365 days a year).
t idle is the planned idle time of the data center per year.
When classifying backup methods, it is customary to distinguish the following schemes: N + 1, 2N and 2 (N + 1). The use of N + 1 and N + 2 schemes, compared with 2N, provides significant budget savings and with a good level of fault tolerance (all the elements of the system are unlikely to fail at the same time). However, it must be remembered that with the growth in the number of work units (N), according to probability theory, the availability of the system deteriorates. In the situation of a large number of elements (large N, for example, uninterruptible power supply), it is more appropriate to use the 2N scheme, when each component of the system is completely duplicated. This will significantly increase the fault tolerance and reduce downtime. At the same time, neither N + 1 nor 2N reserve the system as a whole, and therefore do not exclude the danger of an accident in the area between the reserved elements of the system. Therefore, Tier IV recommends using 2 independent circuits, each of which is fully duplicated, 2 (N + 1).
The basis of reliable data center operation is the power supply: uninterrupted (uninterruptible power supplies - UPS) and guaranteed (diesel generator sets - diesel generator sets). At the time of the disappearance of the voltage of the urban network, the UPS must maintain power to the equipment until the diesel generator set is fully started, which can provide the entire data center with electricity.
In order for the data center to not stand in the absence of power supply, it is extremely important, firstly, to reserve the UPS, and, secondly, to conduct regular service work.
The risks that the presence of only one UPS can bring are generally understandable. At best, we will not be able to test the source, at worst - we will get a simple data center. But sometimes even the presence of several UPS does not give freedom of action. So in one organization there were two sources in the data center, but each fed only its own server group, and did not serve as a reserve for each other. When carrying out maintenance from a service engineer, he grabbed his back. Falling, he somehow managed to de-energize the output of the UPS. And, according to the law of meanness, shutting down at the height of the working day, the source de-energized a group of servers with the most critical applications.
To prevent unwanted downtime requires regular comprehensive service work. In one of the data center checks were carried out only in relation to the DSU. The UPS regularly showed 10 minutes of autonomy, but no one served it. The age of batteries by that time exceeded 5 years, and during one of the combat launches they were able to work only 29 seconds. While DSU started up and was able to take over the load after only 33 seconds. In addition, all the equipment was powered by one UPS (the second was decided to be abandoned at the implementation stage due to budget constraints). In the end - the fall of the data center. Full restoration of all computing systems took about 12 hours.
Major errors:
• Failure at the implementation stage of the second UPS. Difficult times are over, but the second UPS has not been acquired.
• Lack of comprehensive maintenance of all engineering data center systems. With regular maintenance of the UPS, their unsatisfactory condition would be known in advance.
• Lack of regulations for routine maintenance of the data center and chaos during its operation.
Are your UPSs reserved and do you maintain them regularly? Well done, but do not even think about it! Reserve also the data center power supply cable lines, and install 2 ATS, which completely reserve each other. Ideally, they should be connected to different independent electrical panels. In the extreme case, you can stretch two lines from one shield, so that the situation does not work out, like at one of our customers.
When implementing the dispatching system in a small but significant data center, it was necessary to install current transformers on the main input. The problem was that there was only one input, and it was impossible to de-energize the data center. After all the preparatory work, the power was turned off. While the data center equipment was battery powered, the installers worked tirelessly, and the engineer, wiping sweat from his forehead, counted the minutes on the UPS display.
Major errors:
• The dispatching system was undeservedly forgotten in the design.
• The data center power line has not been reserved.
Do not forget about the reservation of air conditioning systems. Over the past two months, two projects have been seen to cool the data center using the chiller-fan-coil system without reserving the route between the chillers and dry coolers. Using this solution in real life with a high degree of probability leads to a data center downtime. In case of replacement of the coolant (which is not uncommon), only the backup route can keep the cooling system, and hence the entire data center, working.
Another very important point - the separation of external and internal cooling circuits. So in one project on the roof of the seventh floor it was proposed to install two two-ton chillers, a cold storage tank, a powerful pumping-up pumping station. The delivery and return flow of two hundred meters was planned directly from the roof to the cooling units in the data center, which was located in the basement. As a result, with even a small pipe breakthrough or loose connections of the internal cooling units, all ten tons of ethylene glycol under pressure could flood the data center and the switchboard customer.
Do not forget about reserving not only computing equipment, but also basic engineering systems, and let your data center work forever!
Yuri Tatarkin
After secured walls and a roof overhead for the data center (the article “Data Center Risks: Choosing a Location” ), the next step in ensuring its resiliency should be the redundancy of engineering systems. By building data centers for more than 10 years, we made sure that not all customers fully realize the importance of duplicating basic communications. Spaceships and those fall, and the equipment in the data center, ideally, should work 365 days a year and 24 hours a day. Any part that has failed or needs to be prevented should be replaced without interrupting the operation of all critical services.As our readers rightly pointed out, not all companies need a reliable data center. For some, its smooth operation is not a matter of concern, and many will prefer to store their data in a public cloud. This public is intended to a greater extent for those who, for whatever reason of security or communication channels, made their choice in favor of their own data center and services with at least three nines available (idle time not more than 1.6 hours per year) .
Fault tolerance and redundancy: what does global experience say?
According to the standards of the Uptime Institute, four levels of fault tolerance of the data center infrastructure are distinguished:
')
The use of Tier classification implies that all engineering systems and data center components, up to the fuel supply for a diesel generator, are perceived as a whole. The presence of at least one unreserved component leads to a decrease in the level of fault tolerance and an increase in the possible hours of data center idle time. The number of such components, as well as statistics on planned and unplanned data center failures per year, affect the allowable downtime. For example, a Tier I data center is characterized by unplanned outages 1.2 times per year. Plus, due to the lack of backup systems, the data center will not work two more times for twelve hours during scheduled maintenance. As a result, the total idle time will be calculated as: 12 + 12 + 4x1.2 = 28.8 hours.
To calculate the level of fault tolerance in percent, you need: ((t work - idle t) × 100%) / t work, where
t work - the maximum number of data center operating hours per year (24 hours a day, 365 days a year).
t idle is the planned idle time of the data center per year.
When classifying backup methods, it is customary to distinguish the following schemes: N + 1, 2N and 2 (N + 1). The use of N + 1 and N + 2 schemes, compared with 2N, provides significant budget savings and with a good level of fault tolerance (all the elements of the system are unlikely to fail at the same time). However, it must be remembered that with the growth in the number of work units (N), according to probability theory, the availability of the system deteriorates. In the situation of a large number of elements (large N, for example, uninterruptible power supply), it is more appropriate to use the 2N scheme, when each component of the system is completely duplicated. This will significantly increase the fault tolerance and reduce downtime. At the same time, neither N + 1 nor 2N reserve the system as a whole, and therefore do not exclude the danger of an accident in the area between the reserved elements of the system. Therefore, Tier IV recommends using 2 independent circuits, each of which is fully duplicated, 2 (N + 1).
Inexhaustible energy
The basis of reliable data center operation is the power supply: uninterrupted (uninterruptible power supplies - UPS) and guaranteed (diesel generator sets - diesel generator sets). At the time of the disappearance of the voltage of the urban network, the UPS must maintain power to the equipment until the diesel generator set is fully started, which can provide the entire data center with electricity.
In order for the data center to not stand in the absence of power supply, it is extremely important, firstly, to reserve the UPS, and, secondly, to conduct regular service work.
The risks that the presence of only one UPS can bring are generally understandable. At best, we will not be able to test the source, at worst - we will get a simple data center. But sometimes even the presence of several UPS does not give freedom of action. So in one organization there were two sources in the data center, but each fed only its own server group, and did not serve as a reserve for each other. When carrying out maintenance from a service engineer, he grabbed his back. Falling, he somehow managed to de-energize the output of the UPS. And, according to the law of meanness, shutting down at the height of the working day, the source de-energized a group of servers with the most critical applications.
"Combat" diesel generator start (PB) - checking the possibility of starting the diesel generator in automatic mode when the external network is lost. Produced by simulating a complete shutdown of external power to the data center. The time from power down to starting the diesel generator server equipment runs on UPS batteries (usually 1-3 minutes).
Starting a diesel generator under load (PN) - checking the ability of a diesel generator to maintain power to the equipment connected to it. It is performed by manual switching of the load on the generator (using the control panel) after it is started and is returned to normal operation. At the time of the transfer switch, the server equipment runs on UPS batteries (about 0.3-1 sec.). By the way, it is better to use motor-drives to switch the load on the DGU, although they work slower, but their service life and reliability are higher.
To prevent unwanted downtime requires regular comprehensive service work. In one of the data center checks were carried out only in relation to the DSU. The UPS regularly showed 10 minutes of autonomy, but no one served it. The age of batteries by that time exceeded 5 years, and during one of the combat launches they were able to work only 29 seconds. While DSU started up and was able to take over the load after only 33 seconds. In addition, all the equipment was powered by one UPS (the second was decided to be abandoned at the implementation stage due to budget constraints). In the end - the fall of the data center. Full restoration of all computing systems took about 12 hours.
Major errors:
• Failure at the implementation stage of the second UPS. Difficult times are over, but the second UPS has not been acquired.
• Lack of comprehensive maintenance of all engineering data center systems. With regular maintenance of the UPS, their unsatisfactory condition would be known in advance.
• Lack of regulations for routine maintenance of the data center and chaos during its operation.
Current migration paths
Are your UPSs reserved and do you maintain them regularly? Well done, but do not even think about it! Reserve also the data center power supply cable lines, and install 2 ATS, which completely reserve each other. Ideally, they should be connected to different independent electrical panels. In the extreme case, you can stretch two lines from one shield, so that the situation does not work out, like at one of our customers.
When implementing the dispatching system in a small but significant data center, it was necessary to install current transformers on the main input. The problem was that there was only one input, and it was impossible to de-energize the data center. After all the preparatory work, the power was turned off. While the data center equipment was battery powered, the installers worked tirelessly, and the engineer, wiping sweat from his forehead, counted the minutes on the UPS display.
Major errors:
• The dispatching system was undeservedly forgotten in the design.
• The data center power line has not been reserved.
It became hot
The “chiller-fan coil” system is an air conditioning system in which coolant fluid circulating under relatively low pressure — ordinary water (in a tropical climate) or an aqueous solution of ethylene glycol (in temperate and cold climates).
Do not forget about the reservation of air conditioning systems. Over the past two months, two projects have been seen to cool the data center using the chiller-fan-coil system without reserving the route between the chillers and dry coolers. Using this solution in real life with a high degree of probability leads to a data center downtime. In case of replacement of the coolant (which is not uncommon), only the backup route can keep the cooling system, and hence the entire data center, working.
Another very important point - the separation of external and internal cooling circuits. So in one project on the roof of the seventh floor it was proposed to install two two-ton chillers, a cold storage tank, a powerful pumping-up pumping station. The delivery and return flow of two hundred meters was planned directly from the roof to the cooling units in the data center, which was located in the basement. As a result, with even a small pipe breakthrough or loose connections of the internal cooling units, all ten tons of ethylene glycol under pressure could flood the data center and the switchboard customer.
Do not forget about reserving not only computing equipment, but also basic engineering systems, and let your data center work forever!
Source: https://habr.com/ru/post/190544/
All Articles