Morphology. Tasks and approaches to their solution

The contents of a series of articles about morphology
• Morphology and computational linguistics for the smallest
• The role of morphology in computational linguistics
• Morphology. Tasks and approaches to their solution
• Pseudo-lemmatization, composites and other strange words
• The role of morphology in computational linguistics
• Morphology. Tasks and approaches to their solution
• Pseudo-lemmatization, composites and other strange words
In the last article, we came close to solving the problem of lemmatization and found out whether we want it or not, but we will have to keep a dictionary with all the words of the described language in one form or another.
For the Russian language is a few hundred thousand words. Maybe it is not economical, but it gives us a lot of bonuses.
First, we can check if there is a word in the dictionary . With the help of rules based on regular expressions, we won’t find out if there is a word “by name” in Russian. The end is completely subject to the rules of the Russian language, the repetition of syllables is also not an exceptional case. This word will miss the regular expression, but in fact there is no “name” in Russian.
')
Another task that is solved by a dictionary stored in morphology is the correction of errors . As soon as we do not find any word in the dictionary, but we find another word there at a short distance from Levenshtein to the desired one, we make a decision to correct it.
To solve these problems, we need to store not only all the words, but all their forms. All the rules for the formation of forms for a group of words similar to each other are called the inflection paradigm . Take the verb "budlanut": budlanul, budlanesh, budlanet, budlanul, budlanula, budlanuli. You can find a mass of verbs that will be changed by the same rules; on the other hand, a huge number of verbs will vary according to different rules. This means that these verbs belong to different paradigms.
In order for us to answer syntax questions, we also store its grammatical meaning with each form.
Dictionary storage
Thus, the dictionary stored in the system solves a lot of problems, which is good news. But how to store this dictionary? There are several hundred thousand words in Russian. On average, there are 15 forms per word. Where do we get this number from? Consider the cases: there are 6 for the singular and 6 for the plural - already 12. And this is not to say that in Russian there are not 6 cases, as taught in school, but 8.
First, the prepositional case hides the case, which is called the locative. If we put the word “forest” in the prepositional case, we will have two options: “about the forest” and “in the forest”. In the forest, it is a locative case, not a prepositional one. For many nouns, the forms of these cases coincide because we do not distinguish “in the table”, “about the table”, and “on the table”. This is because there are no “in the table” locations, but there is a “in the forest” location.
The eighth case is called partitiv. This case shows a part of the whole. If we run out of tea, get up too lazy, and someone unoccupied walks alongside, we tell him: "Pour me, please, tea." As a rule, the form of words in a partitive coincides with the genitive or accusative case. Wikipedia gives us an excellent example of a word that has no other forms than the partitive of the plural - “cheek” (“Do you want a cheek?”; “Pour me a cheek!”)
 Total, 8 cases multiplied by 2 forms (singular and plural) - already 16. Verbs have time, number and gender. By simple arithmetic calculations, we obtain that 15 forms are a rather modest estimate from below.
Total, 8 cases multiplied by 2 forms (singular and plural) - already 16. Verbs have time, number and gender. By simple arithmetic calculations, we obtain that 15 forms are a rather modest estimate from below.The average empirical number of characters in a Russian word is 9. We multiply the obtained results, not forgetting to take into account that there are 2 bytes per character, and it turns out that 50 megabytes is necessary for a dictionary of all forms of the Russian language. In practice, our ideal 50 megabytes is increased by one and a half times: as a result, a text file with all forms of Russian words takes up more than 75 megabytes.
In addition, even if we write all these words to a file, we will need to search for it (otherwise why is it needed?). That is, we must sort the words alphabetically and in addition to each word add a pointer to the initial form of the word. Pointers, though not heavy one by one, still add significant weight to our dictionary. The search speed will be

And this is only in Russian, and there are still English, French, Spanish, Italian, and many other beautiful and rich languages. If we want, for example, FineReader to recognize and support many languages, we need only morphological dictionaries to fit into a gigabyte. What to say about recognition patterns and other dlls? A user with such heavy technology will not understand us - and he will be right. You have to be more modest and keep better.
Prefix tree
A prefix tree comes to the rescue. How does it work? It all starts from the top - an empty symbol in which the alphabet is stored. For the first letter, the entire alphabet is stored there, more precisely, an array of 33 pointers. Each pointer corresponds to its character. The first pointer is to symbol A, the second is to symbol B, a certain K-th pointer is to symbol K and a certain F-th one is to symbol P. By the signs we can get the following nodes of this tree, which correspond to the letters of the Russian alphabet.
The following nodes again store arrays. And for the speed of the search, we neglect the fact that the letters for which we need pointers will be less than 33 (we are unlikely to need a combination of “ay”, for example). We leave the dimension of the array unchanged, inserting null pointers for missing characters.
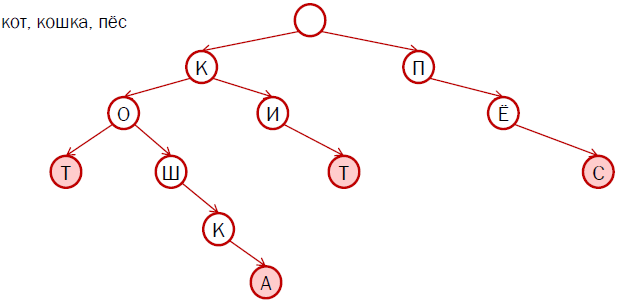
The figure shows an example of a prefix tree for four words: “cat”, “cat”, “whale” and “dog”. Pink painted final vertices.
The advantage of this approach is that we do not store huge chains of repetitive characters for the same word, standing in different forms. Thus, we reduce the file size with a dictionary. For example, for the Russian language, this tree, along with additional data, takes about 2 megabytes. First, compared to 75 megabytes, this is certainly a success. Secondly, the search speed for such a tree is much higher than for a sorted file. Now it does not depend on the size of the entire dictionary, but only on what we are looking for. If we are looking for the union "a", we will find it in one step, and if we are looking for a long word, for example, "helicopter-building", we will have to search a little longer.
Of course, if we put all forms of all words without grammatical meanings into a tree, then we cannot talk about any computer linguistics: we cannot rise to the level of syntax, not to mention semantics, and without them automatic translation is impossible. Consequently, the data structure still needs some work.
What to store in the dictionary
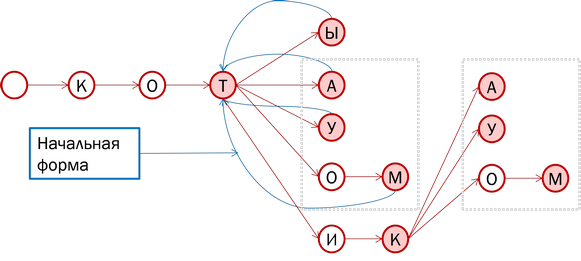
Theoretically, we can actually store all the forms of words in the tree, while keeping pointers to the initial form (the blue lines in the figure). However, pay attention: in spite of the fact that “cat” and “cat” belong to different word-formation paradigms, some of the inflections (as we call endings) coincide. What if these tails of words are stored separately, and in the tree leave the initial forms of cats, cats and whales? So it will be more effective.
Thorough approach
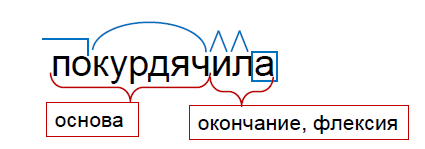
At school, the word is divided into its component parts as follows: prefix, root, several suffixes, and ending. We will go the other way. First, we will not separate the prefix from the root. This is due to the fact that often the prefix together with the root form a completely new meaning. Take for example the words "prefix" and "bet." “Pri-” is just a prefix of the word “bet”, but “prefix” and “bet” are completely different things.
In addition, the prefix does not express any grammatical category. When we add the prefix "re-" ("remake" or "perekurdyachit"), we change the lexical meaning of the word, not the grammatical. Therefore, we consider the prefix and the root as a whole and call it the basis of the word.
Another difference from school: we almost never separate the suffixes from endings, since in most cases they express the grammatical category. In our example, “-l-" and "-a" express the past tense, the feminine gender, and we combine them into flexion. With this division, we get the variable part of the word - flexion and unchangeable - the base.
Convenient assumptions

You, probably, have already got used to the fact that nothing in computer linguistics just happens. Here it is: even a part of the root can change in different forms of the word. Of course, it can be tedious to argue that this is just a changeable consonant in the root of "friend-g" and "friend-z," but for solving practical problems it is more convenient for us to accept that these words have the same basis as "friend-" inflections are different.
So, we have determined that lexemes (word bases) and flexions will be stored separately. Finally, we come close to how our morphological module in ABBYY solves the problems of lemmatization.
Final lemmatization
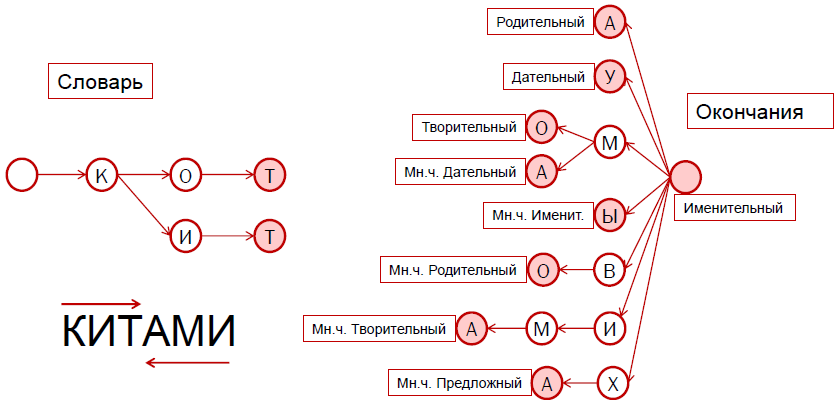
In the picture on the left, in the form of a prefix tree already familiar to you, one hundred thousandth part of the dictionary of the Russian language is shown. On the right is a dictionary of endings that is stored in the same way.
If you look closely at the endings, you will notice that they can be attributed to both the “cat” and the “whale”. If we add "a", we get a genitive case, if "y" is dative and so on. All these are different forms of two words that belong to the same paradigm and therefore change in the same way.
Whale analysis
When we get the form of a word, we begin to analyze it not at first, but from the end. First, we assume that there is a zero ending, which is marked in pink and shows that the nominative case is in front of us, the only number. Then we follow the word "whales" given to us and meet the letter "and." We find the letter “and” in the prefix tree. The next letter is “m”. These letters are not the last, so we continue to move deep into the tree. The next letter "a", which is marked pink, is the final node in the tree. Hence, “-ami” from left to right, or “-im” from right to left, is one of the ending options with which the word can end.
So, we found two endings: empty and "-ami". Now we need to look for the basis in the prefix dictionary tree. This search is carried out from left to right. We consistently find the letters “k”, “i” and “t”, and on the letter “t” the tree ends. That is, “whale” is one of the words stored in this tree. If we try to search further, we will see that the next letter is “a”, but there are no pointers to the next vertex, which means that we stop the search.
We see that the three letters on the left and the three letters on the right have grown into a word, but the empty ending did not come in handy. We decide that "whales" is a plural form, the instrumental case, a lexeme with the initial form "whale".
On the not yet illuminated problems solved by the morphology subsystem, read the next post.
Source: https://habr.com/ru/post/190158/
All Articles