Paginated data sampling - an alternative look at the long-known
The problem of paging information from the database is as old as the database itself, and, accordingly, discussed more than one thousand times. No, perhaps, not a single client-server system, in which this problem was somehow not addressed and solved. Today I want to talk about one slightly non-standard way of interaction between the client layer and the MS SQL back-end when organizing a page-by-page sample in a typical public web application.
To begin with, we outline the typical business requirements and derive the input conditions from them - we select data from a certain list (users, products, transactions) with pages of N records on each, starting with M. Sampling is carried out with the acceptance of one or more filters and some sorting criterion. The problems of purely client solutions such as interactive grids in javascript, in which you need to load all the data, will not be considered here, but we’ll dwell on more moderate options in which page by page output is done on the server.
How is this done traditionally? The application layer transmits the filter values, the index of the first required record, and the required number of records per page to the backend. In response, the database, applying filters to the entire sample, orders the entire filtered subset, and returns the entries from M to M + N-1. How exactly this or that developer and / or this or that version of RDBMS will do this is not important for us now - it is only important that whatever method is used (temporary table in MS SQL 2000, ROW_NUMBER OVER () in 2005- 2008, or TOP / OFFSET in 2011), the need for issuing a numbered subset from a filtered ordered set necessarily means unwinding the entire intermediate result after the filter and sorting it. It is also irrelevant where this unwinding will take place — directly on the data space, or on the index field (for example, using full index coverage or INCLUDED columns) —this principle does not change the difference.
')
It is clear that if the filtration coefficient is low and the filter is labor intensive (for example, full-text search), then the efficiency of this method will be very low, especially as it approaches the last pages of the sample. And even if the filter is parametric (for example, by the type of user in the user table), and works on a specially created index, throwing almost 100% of the server’s efforts for each request for the last pages evokes a sincere pity for the piece of hardware on which the RDBMS itself and spinning.
In real client-server applications, there are several other issues that complicate the situation:
a) in order to properly render a page with pagination (I apologize for the term), the application layer must know the total number of records passing through the filter — in order to divide it by N and round up (with an obvious qualification), get the number of pages needed for navigation menu. In order to achieve this, the backend must actually either perform a search query at each page selection twice - the first time in a truncated version - simply choosing ... COUNT (1) ... WHERE, without partial sampling and sorting, and the second one - in full, with sampling the necessary set records. Either perform COUNT at the first transition to the filtered output, and memorize this value.
b) if during the user’s navigation through the pages, a new (or existing) entry will appear in the database, which falls under the filter condition - the navigation will go away, and the user has every chance to either skip or re-view one or more entries.
c) generally speaking, the database is the least scalable link in public systems built on the ACID principle. Hence the conclusion that if you once designed your system as reliably having all the data at the same time, then it is straightforward to save database resources in the first place, and everything that is possible to carry to easily scalable application servers.
A typical algorithm of operations during page-by-page navigation looks like this in a C-like code (functions with a DB prefix are performed in the database):
Now let's try to improve it, getting rid of re-filtering records in DB_get_records during the first viewing and each subsequent navigation. To do this, instead of requesting a sample of the number of records matching the filter, select the entire array of their primary keys sorted in the required order. Here it is assumed that the primary keys of records are compact (for example, int or bigint), and sampling, even with minimal filtering, gives a reasonable number of records. If this is not the case, then in the first case it is possible to use surrogate keys (in the overwhelming majority of cases, this is done), and in the second case - to limit the sample to a reasonable number (say, 100,000), or to make a palliative solution, choosing keys in portions.
By analogy with the pseudocode DB_get_count function, let's call it DB_get_keys
The second step is to rewrite the data selection function from N to N + M-1 by the specified filters and sorting to a function that selects N records with keys corresponding to the key array sent to it strictly in the order in which they are in the array. Let her be the signature
Now we will try to give a qualitative assessment of the speed of its implementation relative to the classical one. Let us assume that the transfer time of the selected key array from the backend is negligible compared to the search time for the necessary data (this is usually the case when transferring a small amount of them and a good network interface between the database server and the application servers). Since the general algorithm of operation remains unchanged, we need only compare the difference between the DB_get_count ?? database functions ?? DB_get_keys and DB_get_records ?? DB_get_records_by_keys.
Most likely, DB_get_count will work a little faster, mainly due to the fact that counting the rows selected by the filter (that is, counting the primary keys of the rows) does not require internal sorting, plus no need to issue these keys from the SQL engine to the outside. For comparison - two execution planes: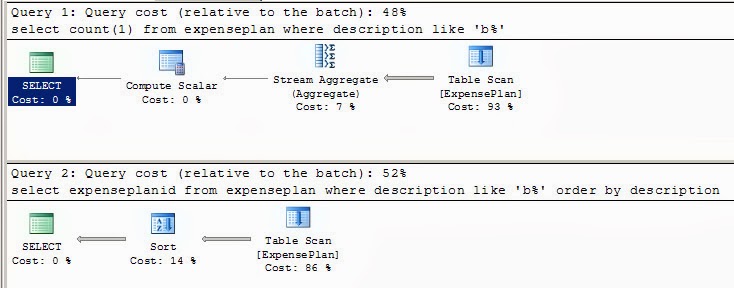
Comparing DB_get_records and DB_get_records_by_keys, in any case, is clearly not in favor of the first method, since selection of records by primary keys is only a small part of their search operations.
As a result, we predict that the new method will give a gain, and the greater, the more laborious the filter and the greater the average number of page turning by the user per operation of changing the filter or sorting criterion. Note also that changing the sorting criterion to the reverse of the same field (statistically quite frequent operation) with this method can be performed without reference to the database by simply inverting the movement of the pointer to the initial element during navigation and adding a parameter to DB_get_records_by_keys, which selects records by keys in the inverse transmitted order.
From the point of view of the implementation of the whole idea of a database, there remains only one thing - how to effectively transfer [under] an array of keys as a parameter to a state or procedure so that the resulting output preserves the order of the keys in the array?
Splitting this task into two - transferring the array as a parameter to the database code and, in fact, maintaining order. There are several solutions to the first task - based on XML or CSV-representation, or creating and filling in a table variable. The SQL itself that converts an input array to a rowset can be executed as a dynamic SQL query, procedure, or table function.
The most flexible is the version that was executed without dynamics as a table function (TF) using CTE - the so-called Common Table Expressions, which in MS SQL 2008 allow recursive queries to be built to process nested data.
This CTE capability, along with the TF capability to be used as a table source in composite queries, is what we use.
The task of preserving the sort order will be solved by adding the identity field to the structure returned by the TF table with the desired seed and increment values (so that it can be sorted outside), and indicating the explicit order of inserting records into the returned table (inside). The function ended up with this:
We illustrate the use of an example.
Create a table with test data and make sure that they are quite diverse;):
We simulate the selection of keys with our DB_get_keys function with reverse sorting by the required field and immediately convert it to CSV:
And finally, imitate DB_get_records_by_keys:
To make it all work in conjunction with the application server, you need to save in the user context (for the web - in the session) an array of key values during navigation, which would seem to require a large amount of memory. However, if the keys are integer, and are stored in a simple scalar array, and not in an array of objects (a fundamental difference!), Then say 100,000 keys will occupy only 400 kBytes on the application server, which by modern standards is quite a bit.
Now about the sensitivity of the method to the added / deleted during the navigation records. It is clear that the newly added records that fall under the filter criteria the user will not see - because the values of their keys will appear after the moment of sampling the entire list. As for deletion, naturally, the missing record will not be returned, and the number of actually received records on the key set may be less than the requested one. This situation can be handled on the application layer by comparing the ID of the received records with the requested ones and removing some blank of the “Viewed record was deleted” in place of the missing ones in order not to disturb the layout due to the change in the total number. And you can also make a LEFT JOIN result of a table function with a business table — in this case, for remote recording, all fields will be NULL — and this fact will be processed on the client. In general, options are available.
And the last. This method was applied when upgrading an online auction system to view the lots selected by the filter (pages or one by one - back and forth) with the possibility of bidding and continuing navigation. For such an application, the average number of navigations on a single filter is quite large, so replacing the classic pagination with this one was one of the effective measures that made it possible to noticeably ease the fate of the SQL server during peak times.
To begin with, we outline the typical business requirements and derive the input conditions from them - we select data from a certain list (users, products, transactions) with pages of N records on each, starting with M. Sampling is carried out with the acceptance of one or more filters and some sorting criterion. The problems of purely client solutions such as interactive grids in javascript, in which you need to load all the data, will not be considered here, but we’ll dwell on more moderate options in which page by page output is done on the server.
How is this done traditionally? The application layer transmits the filter values, the index of the first required record, and the required number of records per page to the backend. In response, the database, applying filters to the entire sample, orders the entire filtered subset, and returns the entries from M to M + N-1. How exactly this or that developer and / or this or that version of RDBMS will do this is not important for us now - it is only important that whatever method is used (temporary table in MS SQL 2000, ROW_NUMBER OVER () in 2005- 2008, or TOP / OFFSET in 2011), the need for issuing a numbered subset from a filtered ordered set necessarily means unwinding the entire intermediate result after the filter and sorting it. It is also irrelevant where this unwinding will take place — directly on the data space, or on the index field (for example, using full index coverage or INCLUDED columns) —this principle does not change the difference.
')
It is clear that if the filtration coefficient is low and the filter is labor intensive (for example, full-text search), then the efficiency of this method will be very low, especially as it approaches the last pages of the sample. And even if the filter is parametric (for example, by the type of user in the user table), and works on a specially created index, throwing almost 100% of the server’s efforts for each request for the last pages evokes a sincere pity for the piece of hardware on which the RDBMS itself and spinning.
In real client-server applications, there are several other issues that complicate the situation:
a) in order to properly render a page with pagination (I apologize for the term), the application layer must know the total number of records passing through the filter — in order to divide it by N and round up (with an obvious qualification), get the number of pages needed for navigation menu. In order to achieve this, the backend must actually either perform a search query at each page selection twice - the first time in a truncated version - simply choosing ... COUNT (1) ... WHERE, without partial sampling and sorting, and the second one - in full, with sampling the necessary set records. Either perform COUNT at the first transition to the filtered output, and memorize this value.
b) if during the user’s navigation through the pages, a new (or existing) entry will appear in the database, which falls under the filter condition - the navigation will go away, and the user has every chance to either skip or re-view one or more entries.
c) generally speaking, the database is the least scalable link in public systems built on the ACID principle. Hence the conclusion that if you once designed your system as reliably having all the data at the same time, then it is straightforward to save database resources in the first place, and everything that is possible to carry to easily scalable application servers.
A typical algorithm of operations during page-by-page navigation looks like this in a C-like code (functions with a DB prefix are performed in the database):
while (1) { create_filter(FormData, &F, &S); // F S // FormData DB_get_count(F, &C); // - while (1) // , F S ( ) { DB_get_records(F, N, M, S); // N , M F S if (SORT_OR_FILTER_CHANGED == do_navigation(FormData, C, &N, &M, &S)) // { break; // - } } } Now let's try to improve it, getting rid of re-filtering records in DB_get_records during the first viewing and each subsequent navigation. To do this, instead of requesting a sample of the number of records matching the filter, select the entire array of their primary keys sorted in the required order. Here it is assumed that the primary keys of records are compact (for example, int or bigint), and sampling, even with minimal filtering, gives a reasonable number of records. If this is not the case, then in the first case it is possible to use surrogate keys (in the overwhelming majority of cases, this is done), and in the second case - to limit the sample to a reasonable number (say, 100,000), or to make a palliative solution, choosing keys in portions.
By analogy with the pseudocode DB_get_count function, let's call it DB_get_keys
The second step is to rewrite the data selection function from N to N + M-1 by the specified filters and sorting to a function that selects N records with keys corresponding to the key array sent to it strictly in the order in which they are in the array. Let her be the signature
DB_get_records_by_keys(*K, N) where K is the address of the array of keys from the desired point (that is, with M, and N is the number of records that must be selected by these keys. Our pseudo-algorithm will now look like this: while (1) { create_filter(FormData, &F, &S); // F S // FormData DB_get_keys(F, S, K); // K F S while (1) // , F S ( ) { DB_get_records_by_keys(&(K[M]), N); // N , M if (SORT_OR_FILTER_CHANGED == do_navigation(FormData, C, &N, &M, &S)) // { break; // - } } } Now we will try to give a qualitative assessment of the speed of its implementation relative to the classical one. Let us assume that the transfer time of the selected key array from the backend is negligible compared to the search time for the necessary data (this is usually the case when transferring a small amount of them and a good network interface between the database server and the application servers). Since the general algorithm of operation remains unchanged, we need only compare the difference between the DB_get_count ?? database functions ?? DB_get_keys and DB_get_records ?? DB_get_records_by_keys.
Most likely, DB_get_count will work a little faster, mainly due to the fact that counting the rows selected by the filter (that is, counting the primary keys of the rows) does not require internal sorting, plus no need to issue these keys from the SQL engine to the outside. For comparison - two execution planes:
Comparing DB_get_records and DB_get_records_by_keys, in any case, is clearly not in favor of the first method, since selection of records by primary keys is only a small part of their search operations.
As a result, we predict that the new method will give a gain, and the greater, the more laborious the filter and the greater the average number of page turning by the user per operation of changing the filter or sorting criterion. Note also that changing the sorting criterion to the reverse of the same field (statistically quite frequent operation) with this method can be performed without reference to the database by simply inverting the movement of the pointer to the initial element during navigation and adding a parameter to DB_get_records_by_keys, which selects records by keys in the inverse transmitted order.
From the point of view of the implementation of the whole idea of a database, there remains only one thing - how to effectively transfer [under] an array of keys as a parameter to a state or procedure so that the resulting output preserves the order of the keys in the array?
Splitting this task into two - transferring the array as a parameter to the database code and, in fact, maintaining order. There are several solutions to the first task - based on XML or CSV-representation, or creating and filling in a table variable. The SQL itself that converts an input array to a rowset can be executed as a dynamic SQL query, procedure, or table function.
The most flexible is the version that was executed without dynamics as a table function (TF) using CTE - the so-called Common Table Expressions, which in MS SQL 2008 allow recursive queries to be built to process nested data.
This CTE capability, along with the TF capability to be used as a table source in composite queries, is what we use.
The task of preserving the sort order will be solved by adding the identity field to the structure returned by the TF table with the desired seed and increment values (so that it can be sorted outside), and indicating the explicit order of inserting records into the returned table (inside). The function ended up with this:
CREATE FUNCTION [dbo].[TF_IDListToTableWithOrder] ( @ListString varchar(MAX), @Delim char(1) ) RETURNS @ID TABLE ( RowIdx INT IDENTITY(0, 1) PRIMARY KEY CLUSTERED, -- ID INT -- ) AS BEGIN SET @ListString = REPLACE(@ListString, ' ', '') IF LTRIM(RTRIM(ISNULL(@ListString, ''))) = '' RETURN -- , SET @ListString = @ListString + @Delim -- , CHARINDEX > 0, ; -- CTE WITH IDRows (ID, Pos) AS ( -- ( ) SELECT CONVERT(INT, SUBSTRING(@ListString, 1, CHARINDEX(@Delim, @ListString, 1) - 1)), CHARINDEX(@Delim, @ListString, 1) + 1 UNION ALL -- ( , ) SELECT CONVERT(INT, SUBSTRING(@ListString, Pos, CHARINDEX(@Delim, @ListString, Pos) - Pos)), CHARINDEX(@Delim, @ListString, Pos) + 1 FROM IDRows WHERE Pos < LEN(@ListString) -- ) -- CTE INSERT INTO @ID (ID) SELECT ID FROM IDRows ORDER BY Pos -- - .. OPTION (MAXRECURSION 32767) -- 100 ( , ) RETURN END We illustrate the use of an example.
Create a table with test data and make sure that they are quite diverse;):
DECLARE @testdata TABLE (ID INT IDENTITY PRIMARY KEY CLUSTERED, Name VARCHAR(128)) INSERT INTO @testdata SELECT TOP 1000 A.name + B.name FROM sysobjects A CROSS JOIN sysobjects B ORDER BY NEWID() SELECT * FROM @testdata We simulate the selection of keys with our DB_get_keys function with reverse sorting by the required field and immediately convert it to CSV:
DECLARE @STR VARCHAR(MAX) = '' SELECT TOP 20 @STR = @STR + ',' + CONVERT(VARCHAR, ID) FROM @testdata WHERE Name LIKE 'C%' ORDER BY Name DESC IF LEN(@STR) > 0 SET @STR = RIGHT(@STR, LEN(@STR)-1) SELECT @STR And finally, imitate DB_get_records_by_keys:
SELECT TD.* FROM @testdata TD INNER JOIN dbo.TF_IDListToTableWithOrder(@STR, ',') LTT ON TD.ID = LTT.ID ORDER BY LTT.RowIdx To make it all work in conjunction with the application server, you need to save in the user context (for the web - in the session) an array of key values during navigation, which would seem to require a large amount of memory. However, if the keys are integer, and are stored in a simple scalar array, and not in an array of objects (a fundamental difference!), Then say 100,000 keys will occupy only 400 kBytes on the application server, which by modern standards is quite a bit.
Now about the sensitivity of the method to the added / deleted during the navigation records. It is clear that the newly added records that fall under the filter criteria the user will not see - because the values of their keys will appear after the moment of sampling the entire list. As for deletion, naturally, the missing record will not be returned, and the number of actually received records on the key set may be less than the requested one. This situation can be handled on the application layer by comparing the ID of the received records with the requested ones and removing some blank of the “Viewed record was deleted” in place of the missing ones in order not to disturb the layout due to the change in the total number. And you can also make a LEFT JOIN result of a table function with a business table — in this case, for remote recording, all fields will be NULL — and this fact will be processed on the client. In general, options are available.
And the last. This method was applied when upgrading an online auction system to view the lots selected by the filter (pages or one by one - back and forth) with the possibility of bidding and continuing navigation. For such an application, the average number of navigations on a single filter is quite large, so replacing the classic pagination with this one was one of the effective measures that made it possible to noticeably ease the fate of the SQL server during peak times.
Source: https://habr.com/ru/post/189946/
All Articles