How GIL works in Ruby. Part 2
Last time, I suggested looking at the MRI code to figure out how to implement GIL and answer the remaining questions. What we will do today.
 The draft version of this article was full of pieces of C code, however, because of this, the essence was lost in details. In the final version, there is almost no code, and for fans of digging into the source code, I left links to the functions I mentioned.
The draft version of this article was full of pieces of C code, however, because of this, the essence was lost in details. In the final version, there is almost no code, and for fans of digging into the source code, I left links to the functions I mentioned.
After the first part, there are two questions:
')
The first question can be answered by looking at the implementation, so let's start with it.
Last time, we dealt with the following code:
Assuming the array is thread-safe, it is logical to expect that as a result we will get an array with five thousand elements. Since in reality the array is not thread-safe, when running code on JRuby or Rubinius, the result is different from the expected (an array with less than five thousand elements).
MRI gives the expected result, but is it a coincidence or a pattern? Let's start the study with a small piece of Ruby code.
To understand what is happening in this piece of code, you need to look at how the MRI creates a new thread, mainly on the code in the
First of all, a new native thread is created inside the
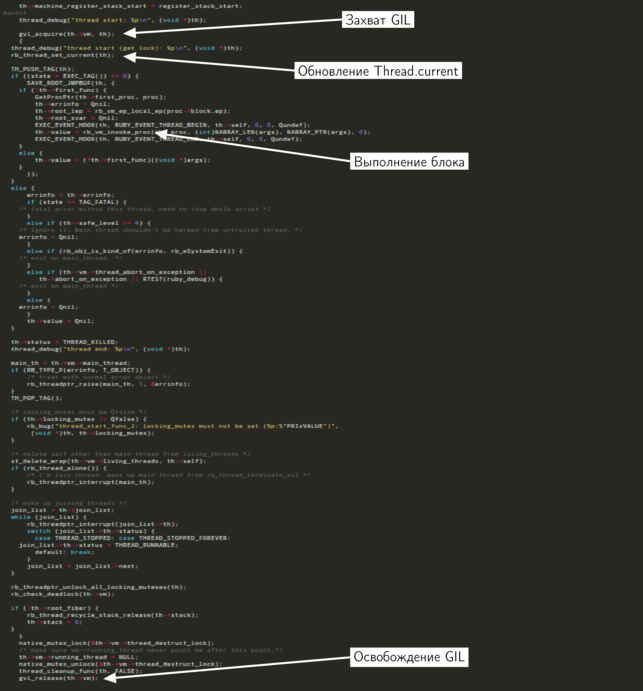
Not all code is important for us now, so I selected those parts that are interesting to us. At the beginning of the function, a new thread captures GIL, before waiting for it to be released. Somewhere in the middle of the function, the block with which the
In our case, a new thread is created in the main thread, which means that we can assume that at the moment the GIL is being held by it. Before proceeding, the new thread must wait until the main thread releases the lock.
Let's see what happens when a new thread tries to capture GIL.
This is part of the
First, it checks if the lock is already held. If held, the
The time stream ensures that the MRI threads work, avoiding the situation in which one of them constantly holds the GIL. But before proceeding to the description of the time stream, let's deal with GIL.
 I have already mentioned several times that there is a native stream behind each thread in the MRI. This is true, but this scheme assumes that the MRI flows work in parallel, as well as the native ones. GIL prevents this. Let's add to the scheme and make it more close to reality.
I have already mentioned several times that there is a native stream behind each thread in the MRI. This is true, but this scheme assumes that the MRI flows work in parallel, as well as the native ones. GIL prevents this. Let's add to the scheme and make it more close to reality.
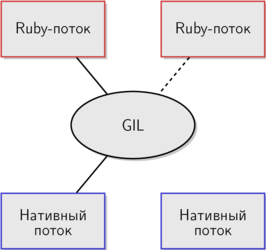 To enable the native stream, the Ruby stream must first capture the GIL. GIL serves as an intermediary between Ruby streams and corresponding native threads, significantly limiting parallelism. In the previous scheme, Ruby streams could use native streams in parallel. The second scheme is closer to reality in the case of MRI - only one thread can hold GIL at some point in time, so parallel execution of the code is completely excluded.
To enable the native stream, the Ruby stream must first capture the GIL. GIL serves as an intermediary between Ruby streams and corresponding native threads, significantly limiting parallelism. In the previous scheme, Ruby streams could use native streams in parallel. The second scheme is closer to reality in the case of MRI - only one thread can hold GIL at some point in time, so parallel execution of the code is completely excluded.
For the development team, MRI GIL protects the internal state of the system . Thanks to GIL, internal data structures do not require locks. If two threads cannot change the shared data at the same time, the race condition is impossible.
For you as a developer, the writing above means that concurrency in MRI is very limited.
As I said, the timer stream prevents the GIL from being held permanently by one thread. The timer stream is the native stream for internal needs of the MRI, it does not have a corresponding Ruby stream. It starts when the interpreter is started in the
When the MRI has just started and only the main thread is running, the timer stream is sleeping. But as soon as a thread starts to wait for GIL to be released, the timer stream wakes up.
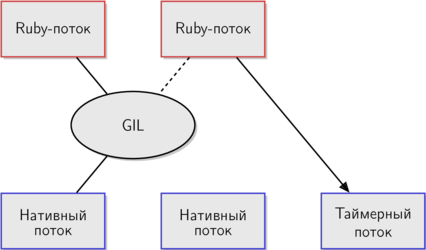
This diagram more precisely illustrates how GIL is implemented in MRI. The thread on the right has just started and, since only it is waiting for GIL to be released, it wakes up the timer stream.
Every 100 ms, the timer thread sets the flag to interrupt the thread that is currently holding the GIL using the
This is similar to the concept of time slicing in the OS, if you are familiar with it.
Setting the flag does not immediately interrupt the stream (if it were, it would be safe to say that the expression
In the depths of the
If the thread interrupt flag is set, the code execution is suspended before returning the value. Before you run any other Ruby code, the current thread releases the GIL and calls the
Here is the answer to the first question:
That is, this code:
guaranteed to give the expected result, being launched at the MRI (we are talking only about the predictability of the length of the array, there are no guarantees about the order of elements - lane comment)
But keep in mind that this does not follow from the Ruby-code . If you run this code on another implementation that does not have GIL, it will produce an unpredictable result. It is useful to know what GIL provides, but writing code that relies on GIL is not a good idea. Doing this, you find yourself in a situation like vendor loku .
GIL does not provide a public API. There is no documentation or specification on GIL. One day, an MRI development team can change the behavior of GIL or even get rid of it. That's why writing code that depends on GIL in its current implementation is not a good idea.
So we know that
What about something like that?
Before calling the
But GIL only makes atomic methods implemented in C. There are no guarantees for Ruby methods.
Is the call to
In the first part of the article, we saw what could happen if the context switch had to be somewhere in the middle of a function. GIL prevents such situations - even if a context switch occurs, other threads will not be able to continue execution, as they will have to wait for the GIL to be released. All this happens only under the condition that the method is implemented in C, does not refer to the Ruby code, and does not release GIL itself ( in the comments to the original article give an example - adding an element to the associative array (Hash) implemented in C is not atomic, because Ruby code to get a hash of the element - note. )
GIL makes it impossible to race inside the implementation of MRI, but it does not make Ruby code thread-safe. It can be said that GIL is just an MRI feature designed to protect the internal state of the interpreter.
The translator will be happy to hear comments and constructive criticism.
The draft version of this article was full of pieces of C code, however, because of this, the essence was lost in details. In the final version, there is almost no code, and for fans of digging into the source code, I left links to the functions I mentioned.In the previous series
After the first part, there are two questions:
')
- Does GIL
array << nilatomic operation? - Does GIL make Ruby code thread safe?
The first question can be answered by looking at the implementation, so let's start with it.
Last time, we dealt with the following code:
array = [] 5.times.map do Thread.new do 1000.times do array << nil end end end.each(&:join) puts array.size Assuming the array is thread-safe, it is logical to expect that as a result we will get an array with five thousand elements. Since in reality the array is not thread-safe, when running code on JRuby or Rubinius, the result is different from the expected (an array with less than five thousand elements).
MRI gives the expected result, but is it a coincidence or a pattern? Let's start the study with a small piece of Ruby code.
Thread.new do array << nil end Let's start with
To understand what is happening in this piece of code, you need to look at how the MRI creates a new thread, mainly on the code in the
thread*.c files.First of all, a new native thread is created inside the
Thread.new implementation, which will be used by the Ruby stream. After this, the thread_start_func_2 function is thread_start_func_2 . Take a look at it, without particularly going into details.Not all code is important for us now, so I selected those parts that are interesting to us. At the beginning of the function, a new thread captures GIL, before waiting for it to be released. Somewhere in the middle of the function, the block with which the
Thread.new method was called is Thread.new . In the end, the lock is released and the native thread completes its work.In our case, a new thread is created in the main thread, which means that we can assume that at the moment the GIL is being held by it. Before proceeding, the new thread must wait until the main thread releases the lock.
Let's see what happens when a new thread tries to capture GIL.
static void gvl_acquire_common(rb_vm_t *vm) { if (vm->gvl.acquired) { vm->gvl.waiting++; if (vm->gvl.waiting == 1) { rb_thread_wakeup_timer_thread_low(); } while (vm->gvl.acquired) { native_cond_wait(&vm->gvl.cond, &vm->gvl.lock); } This is part of the
gvl_acquire_common function, which is called when a new thread tries to capture a GIL.First, it checks if the lock is already held. If held, the
waiting attribute is incremented. In the case of our code, it becomes equal to 1 . The next line should check if the waiting 1 attribute is not equal. It is equal, so the next line wakes up the time stream.The time stream ensures that the MRI threads work, avoiding the situation in which one of them constantly holds the GIL. But before proceeding to the description of the time stream, let's deal with GIL.
I have already mentioned several times that there is a native stream behind each thread in the MRI. This is true, but this scheme assumes that the MRI flows work in parallel, as well as the native ones. GIL prevents this. Let's add to the scheme and make it more close to reality. To enable the native stream, the Ruby stream must first capture the GIL. GIL serves as an intermediary between Ruby streams and corresponding native threads, significantly limiting parallelism. In the previous scheme, Ruby streams could use native streams in parallel. The second scheme is closer to reality in the case of MRI - only one thread can hold GIL at some point in time, so parallel execution of the code is completely excluded.For the development team, MRI GIL protects the internal state of the system . Thanks to GIL, internal data structures do not require locks. If two threads cannot change the shared data at the same time, the race condition is impossible.
For you as a developer, the writing above means that concurrency in MRI is very limited.
Timer flow
As I said, the timer stream prevents the GIL from being held permanently by one thread. The timer stream is the native stream for internal needs of the MRI, it does not have a corresponding Ruby stream. It starts when the interpreter is started in the
rb_thread_create_timer_thread function.When the MRI has just started and only the main thread is running, the timer stream is sleeping. But as soon as a thread starts to wait for GIL to be released, the timer stream wakes up.
This diagram more precisely illustrates how GIL is implemented in MRI. The thread on the right has just started and, since only it is waiting for GIL to be released, it wakes up the timer stream.
Every 100 ms, the timer thread sets the flag to interrupt the thread that is currently holding the GIL using the
RUBY_VM_SET_TIMER_INTERRUPT macro. These details are important for understanding whether the expression array << nil atomic.This is similar to the concept of time slicing in the OS, if you are familiar with it.
Setting the flag does not immediately interrupt the stream (if it were, it would be safe to say that the expression
array << nil not atomic).Interrupt flag handling
In the depths of the
vm_eval.c file is the code for handling the method call in Ruby. It sets the environment for the method call and calls the required function. At the end of the vm_call0_body function, just before returning the method value, the interrupt flag is checked.If the thread interrupt flag is set, the code execution is suspended before returning the value. Before you run any other Ruby code, the current thread releases the GIL and calls the
sched_yield function. sched_yield is a system function that requests the OS scheduler to resume the next thread in the queue. After that, the interrupted stream tries to capture GIL again, before waiting for it until another stream releases it.Here is the answer to the first question:
array << nil is an atomic operation. Thanks to the GIL, all Ruby methods implemented exclusively in C are atomic.That is, this code:
array = [] 5.times.map do Thread.new do 1000.times do array << nil end end end.each(&:join) puts array.size guaranteed to give the expected result, being launched at the MRI (we are talking only about the predictability of the length of the array, there are no guarantees about the order of elements - lane comment)
But keep in mind that this does not follow from the Ruby-code . If you run this code on another implementation that does not have GIL, it will produce an unpredictable result. It is useful to know what GIL provides, but writing code that relies on GIL is not a good idea. Doing this, you find yourself in a situation like vendor loku .
GIL does not provide a public API. There is no documentation or specification on GIL. One day, an MRI development team can change the behavior of GIL or even get rid of it. That's why writing code that depends on GIL in its current implementation is not a good idea.
What about the methods implemented in Ruby?
So we know that
array << nil is an atomic operation. In this expression, one Array#<< method is called, to which a constant is passed as a parameter and implemented on C. Context switching, if it happens, does not lead to data integrity violation - this method in any case will release GIL only before completion.What about something like that?
array << User.find(1) Before calling the
Array#<< method, you need to calculate the value of the parameter, that is, call User.find(1) . As you may know, User.find(1) in turn invokes many methods written in Ruby.But GIL only makes atomic methods implemented in C. There are no guarantees for Ruby methods.
Is the call to
Array#<< still atomic in the new example? Yes, but do not forget that you still need to execute the right-hand expression. In other words, you first need to make a call to the User.find(1) method, which is not atomic, and only then the value returned by it will be passed to Array#<< .What does all this mean to me?
In the first part of the article, we saw what could happen if the context switch had to be somewhere in the middle of a function. GIL prevents such situations - even if a context switch occurs, other threads will not be able to continue execution, as they will have to wait for the GIL to be released. All this happens only under the condition that the method is implemented in C, does not refer to the Ruby code, and does not release GIL itself ( in the comments to the original article give an example - adding an element to the associative array (Hash) implemented in C is not atomic, because Ruby code to get a hash of the element - note. )
GIL makes it impossible to race inside the implementation of MRI, but it does not make Ruby code thread-safe. It can be said that GIL is just an MRI feature designed to protect the internal state of the interpreter.
The translator will be happy to hear comments and constructive criticism.
Source: https://habr.com/ru/post/189486/
All Articles