Technology Real Time MapReduce in Yandex. How to speed up something very big
Some time ago, we told Habré that the search for Yandex had become more personalized. It takes into account not only constant, but also immediate interests of the user, focusing on the last few requests and actions.
Today we want to talk about technology Real Time MapReduce, through which all this has become possible. It provides the transfer and processing of huge amounts of data needed for this task, and to do this, we did not even have to rewrite the code for MapReduce, which we have already used.

')
In order to personalize the search results, you need to define the range of interests of the user, for which we store information about his behavior on the search page. Data on user actions are recorded in the logs, and then processed using special algorithms that allow us to make the most relevant issue on request for each individual user. At first, log processing was launched once a day, for which the MapReduce distributed computing technology was very well suited. It does an excellent job analyzing large amounts of data.
The incoming data (in our case, the logs) goes through several successive steps Map (data is broken down by keys) and Reduce (calculations are performed on a specific function and the result is collected). In this case, the result of the calculations that occur at each stage is simultaneously input data for the next stage. By running through special algorithms at each Reduce-step, the amount of data is reduced. As a result, we get a small amount of useful data from a huge amount of raw data.
However, as already mentioned in previous posts, users have not only permanent, but also momentary interests, which can be replaced literally in seconds. And here the data from the daily prescription can no longer help. We could speed up this process up to half an hour, some logs are processed with such frequency, but our task requires an instant reaction. Unfortunately, when using MapReduce, there is a well-defined reactivity ceiling, due to the nature of the treatment.
The processing steps are performed in strict sequence (after all, each stage generates data that will be processed in the next), and to get the final result using one key, you need to wait until all processing is completed. Even with minor changes in the input data, the entire chain of steps needs to be re-performed, since without recalculation it is impossible to determine which of the intermediate results will be affected by these changes. With a constant stream of incoming data (and from our search engines there is a stream at a speed of about 200 MB / s), such a system is unable to work effectively, and it is impossible to achieve a response to user actions in a few seconds.
We also need a system that could quickly change the final result with small changes in the incoming data. To do this, it must be able to determine which keys will be modified as a result of changes, and carry out recalculation only for them. Thus, the volume of data processed at each stage will decrease, and at the same time the processing speed will increase.
In Yandex, there are several projects that use classic cluster applications, where data is divided into nodes, between which there is an exchange of messages that allow you to change states for individual keys without producing a full recalculation. However, for complex calculations, which involves processing logs, such a model is not suitable because of too much load on the message handler.
In addition, most of the code that has accumulated in us that provides search quality is written under MapReduce. And almost all of this code, with minor modifications, could be reused to process user actions in real time. So the idea was born to create a system with an API, identical to the MapReduce interface, but at the same time capable of independently recognizing the keys affected by changes to the incoming data.
Initially, the plan seemed simple enough: it was necessary to make an architecture that can calculate MapReduce-functions, but also can incrementally and effectively update the value of functions in seconds with small changes in input data. The first prototype of RealTime MapReduce (RTMR) was ready in two weeks. However, in the process of testing began to open weaknesses.
Separately, all the problems seemed trivial, but in systems of this magnitude, linking everything with each other is not so easy. As a result, after the elimination of all problems, practically nothing remained of the initial prototype, and the amount of code increased by an order of magnitude.
In addition, it became clear that to ensure the necessary speed, all the data involved in the calculations must be stored in memory, for which we implemented a special architecture.
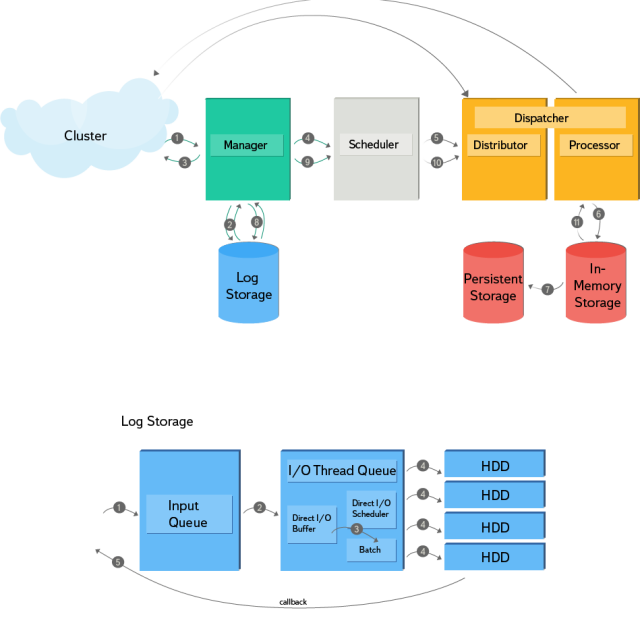
Let us examine in more detail the sequence of actions displayed on the diagram:
The second part of the scheme demonstrates the principle of operation of the log storage. It supports asynchronous recording with the incoming queue, as well as callback for notifications. The append-only structure and index for filtering records by key are implemented on the disk. The adaptive scheduler uses read-operation statistics to determine the size of a record, finding the optimal balance between the recording speed and the waiting time before it starts. Log storage consists of four non-RAID HDDs with sharding by key. Direct I / O is used to write data to discs.
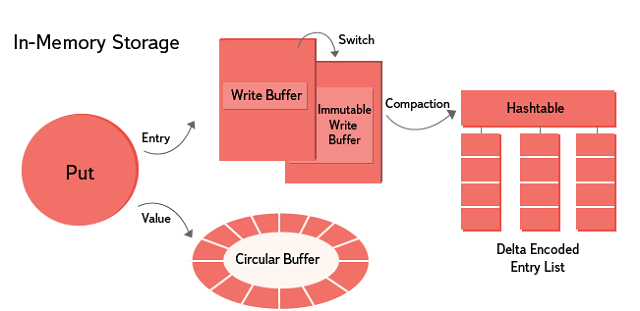
In-memory storage implements a sequential write and parallel read approach. Sharding is carried out by key. Data is stored for a certain period of time in the settings, after which it can be overwritten with new ones. A lock-free ring buffer is used to store the value data. For entries (key, subkey, table, timestamp + additional information) use the append-only lock-free Skip List. After filling in the Skip List, a new one is created, and the old one is combined with the existing immutable data. For each key, entries are sorted and delta-encoded.
Coordination of nodes in the cluster is carried out with the help of Zookeeper. The master / slave definition is done through consistent hashing. Outgoing transactions are processed by the master and additionally saved on the slaves. Sections are also placed both on the master and on the slaves. When reshuffling a new master collects data from the slice on the cluster, as well as the raw transaction from the log on its range of keys, catches up with its state and is included in the processing.
It is worth noting that in addition to personalizing the search for RTMR, you can find other applications. In most cases, the algorithms used in the search can be rearranged to work in real time. For example, it can be used to improve the quality of searching through fresh documents, publications in the media and blogs. After all, the ranking of fresh documents depends not only on the speed of their crawling and indexing, this is not the most difficult process, and in most cases our robot has been doing this for quite some time in a few seconds. However, much of the data for ranking is taken from information sources external to the document, and MapReduce is used to aggregate this data. As mentioned above, the limitations of the batch processing methods do not allow aggregation in less than 20-30 minutes. Therefore, without RTMR, part of the external signals for fresh documents comes with a delay.
Adjustment of search hints can also be made instant. Then the query options offered to the user will depend on what he was looking for a few seconds ago.
Since our system is still quite young, in the near future we have an expansion of the MapReduce paradigm: the addition of new interfaces to it, sharpened specifically for real-time work. For example, operations that are capable of doing preliminary incomplete preaggregation.
In addition, we plan to produce a unified for MapReduce and RTMR declarative description of data flows and a graph of calculations. Stages of RTMR calculations for different keys, unlike MapReduce, work inconsistently, which means that the sequential launching of stages from code loses all meaning.
Today we want to talk about technology Real Time MapReduce, through which all this has become possible. It provides the transfer and processing of huge amounts of data needed for this task, and to do this, we did not even have to rewrite the code for MapReduce, which we have already used.
')
In order to personalize the search results, you need to define the range of interests of the user, for which we store information about his behavior on the search page. Data on user actions are recorded in the logs, and then processed using special algorithms that allow us to make the most relevant issue on request for each individual user. At first, log processing was launched once a day, for which the MapReduce distributed computing technology was very well suited. It does an excellent job analyzing large amounts of data.
The incoming data (in our case, the logs) goes through several successive steps Map (data is broken down by keys) and Reduce (calculations are performed on a specific function and the result is collected). In this case, the result of the calculations that occur at each stage is simultaneously input data for the next stage. By running through special algorithms at each Reduce-step, the amount of data is reduced. As a result, we get a small amount of useful data from a huge amount of raw data.
However, as already mentioned in previous posts, users have not only permanent, but also momentary interests, which can be replaced literally in seconds. And here the data from the daily prescription can no longer help. We could speed up this process up to half an hour, some logs are processed with such frequency, but our task requires an instant reaction. Unfortunately, when using MapReduce, there is a well-defined reactivity ceiling, due to the nature of the treatment.
The processing steps are performed in strict sequence (after all, each stage generates data that will be processed in the next), and to get the final result using one key, you need to wait until all processing is completed. Even with minor changes in the input data, the entire chain of steps needs to be re-performed, since without recalculation it is impossible to determine which of the intermediate results will be affected by these changes. With a constant stream of incoming data (and from our search engines there is a stream at a speed of about 200 MB / s), such a system is unable to work effectively, and it is impossible to achieve a response to user actions in a few seconds.
We also need a system that could quickly change the final result with small changes in the incoming data. To do this, it must be able to determine which keys will be modified as a result of changes, and carry out recalculation only for them. Thus, the volume of data processed at each stage will decrease, and at the same time the processing speed will increase.
In Yandex, there are several projects that use classic cluster applications, where data is divided into nodes, between which there is an exchange of messages that allow you to change states for individual keys without producing a full recalculation. However, for complex calculations, which involves processing logs, such a model is not suitable because of too much load on the message handler.
In addition, most of the code that has accumulated in us that provides search quality is written under MapReduce. And almost all of this code, with minor modifications, could be reused to process user actions in real time. So the idea was born to create a system with an API, identical to the MapReduce interface, but at the same time capable of independently recognizing the keys affected by changes to the incoming data.
Architecture
Initially, the plan seemed simple enough: it was necessary to make an architecture that can calculate MapReduce-functions, but also can incrementally and effectively update the value of functions in seconds with small changes in input data. The first prototype of RealTime MapReduce (RTMR) was ready in two weeks. However, in the process of testing began to open weaknesses.
Separately, all the problems seemed trivial, but in systems of this magnitude, linking everything with each other is not so easy. As a result, after the elimination of all problems, practically nothing remained of the initial prototype, and the amount of code increased by an order of magnitude.
In addition, it became clear that to ensure the necessary speed, all the data involved in the calculations must be stored in memory, for which we implemented a special architecture.
Let us examine in more detail the sequence of actions displayed on the diagram:
- It all starts with the fact that the handler of the incoming request parses the data and starts a separate transaction for each key.
- In this case, the transaction is considered to be started only after receiving confirmation that the record of the start of the operation (PrepareRecord) is saved on the disk.
- After starting a transaction over the network, a response is sent to the incoming request, and the transaction is queued for processing by the workflow.
- Next, the workflow picks up the transaction and, depending on the locality of the key, either sends it over the network and waits for confirmation or creates content processing in which operations are performed.
- Subsequently, transactions are processed in isolation from each other: after the start, a brunch is set aside from the general state of the system, and at the end of processing changes are accepted.
- All data is stored in memory, which is extremely important for optimizing reduce-operations.
- Data on modified keys are periodically stored in permanent storage as backup copies.
- After processing the transaction, its result is recorded on the disk, and when it receives confirmation of the record from the log, it is considered complete.
- Also, a transaction can generate child transactions, in which case everything repeats, starting with the fourth item.
- In the process of restoring the state, the data is retrieved from the persistent storage and reproduced by the log, while the incomplete transactions are restarted. If it is necessary to abort a transaction, AbortRecord is written to the log (an indicator that this transaction does not need to be restarted when the state is restored).
The second part of the scheme demonstrates the principle of operation of the log storage. It supports asynchronous recording with the incoming queue, as well as callback for notifications. The append-only structure and index for filtering records by key are implemented on the disk. The adaptive scheduler uses read-operation statistics to determine the size of a record, finding the optimal balance between the recording speed and the waiting time before it starts. Log storage consists of four non-RAID HDDs with sharding by key. Direct I / O is used to write data to discs.
In-memory storage implements a sequential write and parallel read approach. Sharding is carried out by key. Data is stored for a certain period of time in the settings, after which it can be overwritten with new ones. A lock-free ring buffer is used to store the value data. For entries (key, subkey, table, timestamp + additional information) use the append-only lock-free Skip List. After filling in the Skip List, a new one is created, and the old one is combined with the existing immutable data. For each key, entries are sorted and delta-encoded.
Coordination of nodes in the cluster is carried out with the help of Zookeeper. The master / slave definition is done through consistent hashing. Outgoing transactions are processed by the master and additionally saved on the slaves. Sections are also placed both on the master and on the slaves. When reshuffling a new master collects data from the slice on the cluster, as well as the raw transaction from the log on its range of keys, catches up with its state and is included in the processing.
Perspective RealTime MapReduce
It is worth noting that in addition to personalizing the search for RTMR, you can find other applications. In most cases, the algorithms used in the search can be rearranged to work in real time. For example, it can be used to improve the quality of searching through fresh documents, publications in the media and blogs. After all, the ranking of fresh documents depends not only on the speed of their crawling and indexing, this is not the most difficult process, and in most cases our robot has been doing this for quite some time in a few seconds. However, much of the data for ranking is taken from information sources external to the document, and MapReduce is used to aggregate this data. As mentioned above, the limitations of the batch processing methods do not allow aggregation in less than 20-30 minutes. Therefore, without RTMR, part of the external signals for fresh documents comes with a delay.
Adjustment of search hints can also be made instant. Then the query options offered to the user will depend on what he was looking for a few seconds ago.
Since our system is still quite young, in the near future we have an expansion of the MapReduce paradigm: the addition of new interfaces to it, sharpened specifically for real-time work. For example, operations that are capable of doing preliminary incomplete preaggregation.
In addition, we plan to produce a unified for MapReduce and RTMR declarative description of data flows and a graph of calculations. Stages of RTMR calculations for different keys, unlike MapReduce, work inconsistently, which means that the sequential launching of stages from code loses all meaning.
Source: https://habr.com/ru/post/189362/
All Articles