The role of morphology in computational linguistics
The contents of a series of articles about morphology
• Morphology and computational linguistics for the smallest
• The role of morphology in computational linguistics
• Morphology. Tasks and approaches to their solution
• Pseudo-lemmatization, composites and other strange words
• The role of morphology in computational linguistics
• Morphology. Tasks and approaches to their solution
• Pseudo-lemmatization, composites and other strange words
Previously, automatic translation worked as follows:
- Analyzed the forms of words in the original sentence;
- Tried to choose one of the syntactic schemes of the source language, which would fit the sentence with the found forms;
- Found the appropriate syntax for the target language;
- Found a translation for each of the word forms in the original sentence;
- Words translations put in the form necessary for the target syntactic scheme.
Modern technology is trying to go further.
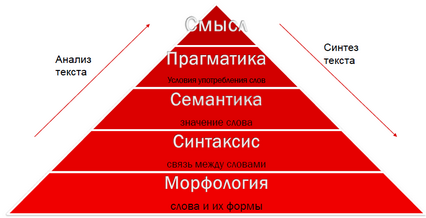
They try to explain the meaning of each word in a sentence, rising to the level of semantics in the pyramid in the figure. This helps to clarify the translation, since hypotheses are dismissed in which the semantics of individual words are inconsistent. In addition, for semantic reasons, some syntactic rules may not be applicable to all words of the language. As well as semantics to some extent allows you to get rid of homonymy.
For example:
- Standard steel helmets were painted matt greenish-gray. -> Standard steel helmets were painted matt greenish gray.
- Konstantin Somov painted this exquisite still-life in 1923. -> Konstantin Somov wrote this exquisite still life in 1923.
The ultimate goal of this process is to understand the meaning of the text. Nevertheless, in our pyramid there is a whole level between meaning and meaning, which we have not yet overcome.
Pragmatics of the language - this is how a person relates to what he says. The classic example: “Can a double statement mean negation?” - “Well, yes, of course!”. Here a pragmatic layer of language understanding is hidden behind a double statement.
But let's not get ahead of ourselves, go up the pyramid from below.
')
Morphology
The basic level of the pyramid of natural text understanding is the morphological layer. Without knowledge of the morphology of the language above, it is very difficult to go, as, incidentally, go down. Morphology represents knowledge of the forms in the dictionary and their grammatical meanings.
Syntax
 The next level of the pyramid is syntax. Syntax defines the connection of words in a sentence, the control of words, the relationship between words in natural language. The syntax should be able to handle the grammatical meanings that it receives from morphology. This is the data that comes to it from the bottom up (see the diagram at the beginning of the post) at the stage of text analysis. He transmits the same data to the level of morphology during the synthesis of the text, determining in what form a particular word should be in the target language.
The next level of the pyramid is syntax. Syntax defines the connection of words in a sentence, the control of words, the relationship between words in natural language. The syntax should be able to handle the grammatical meanings that it receives from morphology. This is the data that comes to it from the bottom up (see the diagram at the beginning of the post) at the stage of text analysis. He transmits the same data to the level of morphology during the synthesis of the text, determining in what form a particular word should be in the target language.This is the translation. We have been given a proposal in Russian. First, we analyze it morphologically, then syntactically, then semantically. After this, the semantics determines the syntactic form of the sentence in the target language (for example, in English), the syntax builds all the lexemes into the desired forms, and from the morphology we get directly the specific forms of these words.
Semantics
At the semantic level, the task is significantly complicated. We need to understand what these words mean. Morphology works with words separately, it takes a separate word, for example, "bokra", and says: "This is a masculine noun in the genitive case." The syntax looks at the connection "bokra" with other words in the sentence. “Budlanula bokra” - “bokr” refers to the verb “budlanula” as an addition.
But at the level of semantics, we are powerless: we do not know who such a "bokr" is, and we do not know what it means to "blued." Until recently, automatic text translation technology was powerless even in those cases that may seem obvious to us. She doesn’t know what is hiding behind the phrase “Do you want a cup of tea?” Maybe this is a cup of tea (cup as a sports cup), or maybe just a cup.
Pragmatics
Teaching a translator to understand and track pragmatics is even more difficult, but local problems are also solved in this area. In a large text, for example, through several blog entries, we are trying to automatically understand the emotional coloring of the text. If we teach the computer to understand not only the words from the text, but also the words that the author had in mind for them, then we can say that we taught the computer "to read between the lines."
Morphology tasks
Computational linguistics can be viewed as a large building, and morphology as the foundation of a building that solves specific problems. After all, the program is a separate dll'ka, providing a specific API, from which we want to get a specific result. The label below organizes the tasks that are assigned to the morphology module.
| Task | How to use |
| Getting the initial form - Lemmatization | Search |
| Putting a word into a given form | Automatic translation Speech synthesis |
| Getting all forms of the word | Search Knowledge base Text editor OCR |
| The grammatical meaning of the word | Automatic translation OCR Speech recognition |
| Word vocabulary | OCR |
| Word correction | Search Text editor |
Lemmatization
 Let's start in order: lemmatization is getting the initial form of a word, or, in a different way, lemmas. If we need to restore the initial form of the word “budlanula”, the word “budlanut” immediately appears in our head. However, if you try to turn a similar experiment with a word in an unknown language for us, the task will quickly cease to seem trivial.
Let's start in order: lemmatization is getting the initial form of a word, or, in a different way, lemmas. If we need to restore the initial form of the word “budlanula”, the word “budlanut” immediately appears in our head. However, if you try to turn a similar experiment with a word in an unknown language for us, the task will quickly cease to seem trivial.When I was learning German at the institute, it was terrible for me to look in the paper dictionary for the word “gemacht” and not to find that word. Or find the wrong word and try to understand how it relates to other words in a sentence. And the reason is that this is a form of the verb “machen”, and not a noun “Gemächt”.
Frankly, I did not learn the German language, but I always remembered that dictionaries should be able to restore the initial form of the word, and, if this word is in the dictionary, show it. So, besides the search listed in the table, the scope of lemmatization is also computer dictionaries.
Putting a word into a given form
The inverse problem is the formulation of the word in a given form. When we try to put a word in a given form, we synthesize speech, that is, we get the text in a specific target language. Accordingly, this technology is used in automatic translation and in the synthesis of artificial speech.
Getting all forms of the word
The next task - obtaining all forms of the word - is most often used when searching. There are two approaches to text indexing: the first is to match a word from a query with all forms of this word in the index, the second is to obtain the lemma of the requested word and the subsequent comparison with the initial forms in the index. In this case, the implementation depends on the specifics of the problem being solved. Maybe you are trying to index the entire Internet, and maybe, on the contrary, some local knowledge base, but you need high accuracy of the results.
Getting the grammatical meaning of a word
The need to query the module morphology of grammatical meaning arises if necessary to understand the meaning that can be removed from the grammatical meaning (for example, action before us or not, past tense or present).
Word vocabulary
We have already stopped at this point before, so we just fix it: the word vocabulary is very important for text recognition - whether the word belongs to the language or does not belong.
Word correction
 When working with text editors and, moreover, in modern mobile devices, fast typing often makes typos. Previously, T9 technology served to identify them, which restored symbols using nine buttons. Now smartphones use a full qwerty-keyboard, but the fingers often do not fall on the right buttons, and the word needs to be corrected. Correction - the task of morphology. Now any self-respecting smartphone will tell you how the word is actually spelled.
When working with text editors and, moreover, in modern mobile devices, fast typing often makes typos. Previously, T9 technology served to identify them, which restored symbols using nine buttons. Now smartphones use a full qwerty-keyboard, but the fingers often do not fall on the right buttons, and the word needs to be corrected. Correction - the task of morphology. Now any self-respecting smartphone will tell you how the word is actually spelled.In addition, the word fix is used when indexing the Internet. In the case of the web, performance becomes especially important, because misspelled words are very common. We cannot find them in the dictionary in the form in which the user entered them, but must translate, because a person, having read this word, would understand what the interlocutor meant. As they say, “Vilasiped” or “bicycle”, he will not become a moped, no matter how you write (by the way, one of the implementations of the “intelligent” spell checker can be read in this article ).
Problem solving. Let's start with a simple one: lemmatization

Let's return to our kuzdr. How do we get the initial form from the word "bledanula"? The first thing that comes to mind: only the ending changes. Why not just replace some endings with others with the help of the good old regular expressions? By the way, a lot of morphologies, which can be found on the Internet in the public domain, are based on regular expressions. Replacing -la at the end of-in our case works great: “budlanula” to “budlanut”. However, it is worth digging a little deeper, and it turns out that it works far from always.
Pitfalls: homonymy

Homonymy is the coincidence of the forms of different words. Moreover, it happens that two forms of the same word coincide, and sometimes there are different words, as in our example. “Steel” is a past tense of a plural or is a plural form of the word “steel”. What is the initial form: “become” or “steel”? This problem cannot be solved at the level of morphology: morphology considers a single word out of context, therefore, whatever methods you use, you cannot resolve homonymy. But the most interesting thing is that even on the following levels, on the syntactic, and sometimes on the semantic, it is not always possible to resolve homonymy. The above common example is a clear confirmation of this.
As if this is not enough

There is another objection: not all words are used in all forms. If we make such a rule out of the “circle” - “circle” transition, that should be replaced with -th, then the word “appear” should be replaced with the word “show”. But there is no such word in Russian.
It's Complicated
Thus, it turns out that if you need low cost morphology - for example, you have indexed a large base, searched it, and you are satisfied with the quality of the search, you can, of course, stay at this zero approximation of lemmatization, but for more serious linguistic technologies this accuracy is not enough and need to do something else.
Actively looking
What else we do, how we store what we do, and what tasks of computational linguistics are still waiting to be solved, will be discussed in the next article.
Source: https://habr.com/ru/post/189020/
All Articles