How to make the online store withstand the load of 280,000 visitors per hour?

Hi, Habr!
Unfortunately, at this stage of web programming development in our country, project refactoring is often perceived as a programmer’s work in the “all bad” mode and is carried out only at the moment when the site is already in a critical state. We had to deal with a similar situation in 2012, when one large Russian online store came to our service with the following problem: starting from 10 am, the site fell every half hour for 5-10 minutes and rose either with great difficulty or after a hard reboot . After the reboots, the site worked a little, and then fell again. The fact that the New Year was approaching, the high season for all selling websites, and in this case the phrase “in 10 minutes the company loses tens of thousands of dollars” was not a joke, gave particular urgency to the problem.

Let's digress from our story a bit and talk about the fact that developers are now exceptionally happy people. Finally, server capacities have become so cheap that any system with a shortage of resources can be easily scaled to the desired size. Is something wrong programmed? Increased the load on the percent? Great, let's add a proc server. Not enough operatives? Let's add operatives. The problem of lack of resources is not a problem.
Many of you remember very well the time when people sat on a dial-up, thoughtfully listened to the sound of the modem, determining from the first notes whether it was possible to connect or to reconnect. At that time, the slow site simply closed in a minute, because it was very expensive to wait for it (in the literal sense of the word). Today, a slow site is a site that opens for more than 3 seconds without taking into account the speed of the channel. The world is increasing speed, time is expensive. And what if the site does not have enough speed? There are wonderful accelerators and more powerful and very cheap servers, there is a web cluster from the same 1C-Bitrix, for example, and as a last resort and a sea of software for the same purposes. It seems that you can no longer monitor the quality of the code, dramatically lower the level of developers and significantly save the company's budget.
')
However, it only seems. In our reality, the reality of web developers, on any of the most powerful hardware there is an endless cycle and a wonderful framework. And often there are situations when even the most powerful hardware does not pull the written code.
This was the case with our client, a large online store mentioned at the beginning. We saw six powerful servers, each of which could be freely scaled. The most logical and quick action at that moment was to add another pair of servers, which we immediately did. However, the site still continued to fall as scheduled.
In order to get some time out for normal operation, we decided to somehow stabilize the project first so that it could survive the New Year, and then conduct its global reengineering and refactoring.
What did we have at the entrance?
We knew that the graphs of the load on different parts of the system should be fairly smooth. For example, such:
This is due to the fact that very rarely in one second there are zero users on the site, and the next - all 110,000 peak load users.
However, what we saw on the client’s project contradicted our entire practice: all the charts jumped and led erratic lives.
It looked like this:
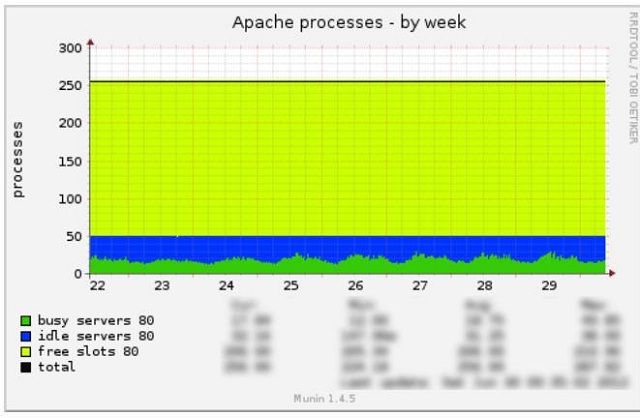
Apache:
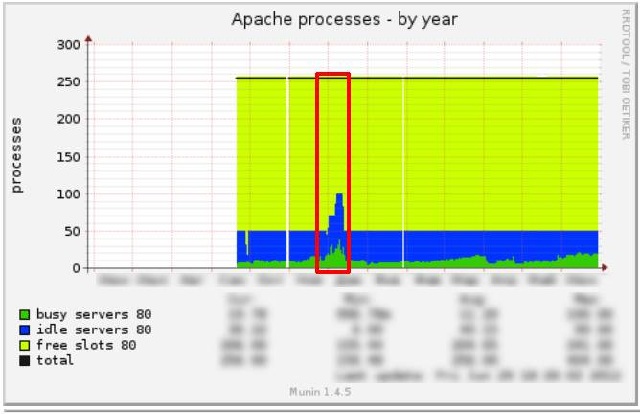
Perhaps it would be worthwhile to enjoy the increased load on schedules - more visitors, more money - but Google Analytics said that the number of visitors not only did not grow, but even fell.
As a rule, in a stable and correct system state, an increase in Apache load is correlated with an increase in MySQL load. But in our case everything looked different.
MySQL:
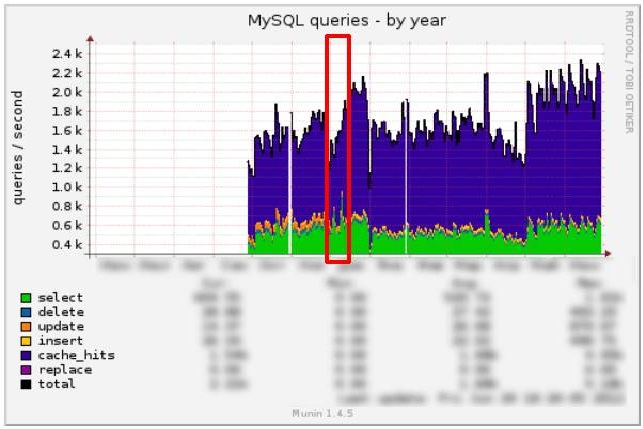
And now let's compare the MySQL and Apache graphics:
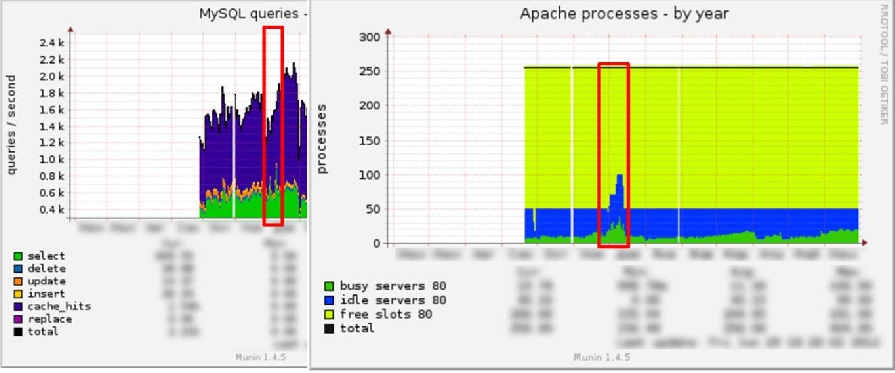
Something obviously went wrong. And we started looking for a problem.
What did we discover?
First, we found the modified core CMS "1C-Bitrix", and it was changed in those parts that work with the cache, which meant a potentially incorrect work with it. In principle, there was some logic to this - if the cache fails and is reset, then there will be surges on Apache at these moments. But then there should have been a surge in MySQL, but there were none.
Secondly, due to the changed CMS core, the project has not been updated for several years, since any update has broken the site.
Thirdly, the server was configured incorrectly. Since our story is about refactoring, we will not dwell on this point in detail.
Fourth, the project was created around 2005-2006 and was calculated on a completely different load - 10 times less than the current one. The project architecture and code were not designed at all for the increased load. Requests that, under the old load, were performed within the tolerable 0.5 - 1 seconds, with the new load, were performed already 4–15 seconds and fell into the slow log.
And fifthly: in the process of customer cooperation with different contractors over the years of the project, there appeared a lot of duplicate code in it, unnecessary cycles and an inefficient cache.
Actually, a little debugger, a couple of gigabytes of logs, a live analyst weighing at least 60 kg, salt, pepper, mix - there we got an excellent recipe for quick stabilization of the project. He was able to survive the peak of the new year and acquired a small, but still a margin of safety.
How to fix everything else?
Recall that the project was on the "1C-Bitrix." First, we updated the CMS version to the last one, which led, as we assumed at the beginning, to the fact that a significant part of the functionality stopped working, it had to be restored. After basic analytics, it turned out that more than 1000 files were changed in the kernel and in standard components. After the upgrade, the first stage we had to restore the site to a fully functional version. But this allowed us to connect the Web Cluster module with all the buns.
At the second stage, we analyzed the project architecture, database queries and code, and found that, due to the specific architecture, from one catalog page, from 3000 to 4000 queries were generated to the database without a cache, with a cache — about two hundred queries. At the same time, it was dropped non-optimally and with any content update.
To optimize queries to the database, we had to modify the structure of information blocks: to denormalize part of the data and transfer part of the data to separate tables. This made it possible to get rid of the most difficult joins with the execution speed of 30-40s and replace them with several quick selects. We also put down the indices on the most used data and removed the excess, remaining from the old structure. All this has significantly increased the overall speed of query execution.
We also added a bonus for subsequent developers of the project: in order to make the code easy to read in the future, we scattered thousands of sheets of code into separate classes and files, commented on them and cleaned outdated obsolete files.
What is the result?
It took us about 6 months to consistently carry out all the works listed. Then we conducted load testing on the site. The tests were from both the external network and the inside of the cluster (to level the effect of the channel speed on the test).
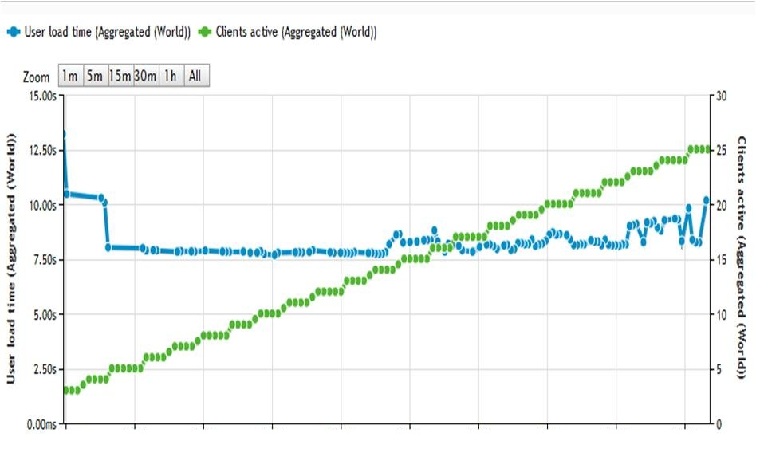
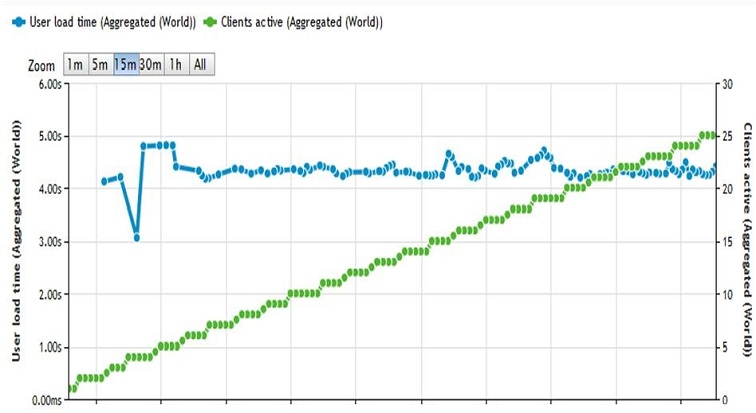
On the test graphs from the outside it can be seen that before refactoring and reengineering the system with a load of 25 simultaneous users, the page is loaded for about 8s, and after that - only 4.2s.
Before:
After:
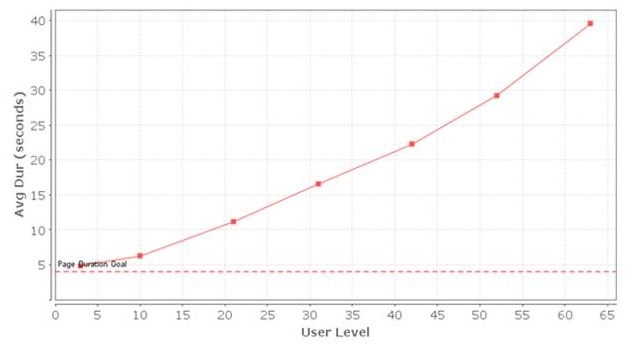
On the test graphs from the inside of the cluster, it can be seen that, for example, the main page before refactoring with 200,000 visitors loaded 40s, and began to load 1.9s.
Before:
After:
What we have pleased their developers?
We have reduced the number of queries to the database with and without cache. Increased code readability. Simplified the internal structure of the project. Removed obsolete data. Changed over 14,000 files. Simplified project scaling. And in the final - gave a significant margin to the project to increase the load.
So that we want to complete the article to advise all web developers:
- Use server status monitoring. Usually everything is visible there.
- Use debuggers, watch out for the most demanding operations and cycles.
- Cache everything that is used constantly. Flush the cache in parts, not completely.
- Keep track of the number of queries to the database as with the cache, and without a cache
- Profile queries, monitor the amount of data transferred from the database to the Apache. Follow the logic and optimal execution of the request.
- Arrange the indexes on the tables in the database.
- Update CMS.
Natalya Chilikina, head of bitrix-development department ADV / web-engineering
Source: https://habr.com/ru/post/189016/
All Articles