Tale of a clustered index
After switching to SQL Server from Oracle, many things are surprising. It’s hard to get used to automatic transactions - after update you don’t need to type commit (which is nice), but in case of an error you won’t be able to type rollback (which is just awful). It's hard to get used to the architecture in which the log is used for both rollback and roll forward transactions. It is difficult to get used to the situation “the writer is blocking readers, the reader is blocking writers,” and when you get used to it, it is even harder to break the habit. And not the last place in the ranking of difficulties is dominated by clustered indexes. By default, the primary key of the table is a clustered index, and therefore almost all tables have it.
In fact, this beast is completely fearless and even very useful. Let's try to figure out why it is needed and how to use it.
The data of any table is physically stored in a database file. The database file is divided into pages (page) - logical storage units for the server. A page in MS SQL Server is necessarily 8 kilobytes (8192 bytes), of which 8060 bytes are allocated for data. For each row, you can specify its physical address, the so-called Row ID (RID): in which file it is located, in which in order of the page of this file, in which place of the page. A table is assigned to a page entirely - there can be only one table data on one page. Moreover, if you need to read / write a string, the server reads / writes the entire page, because it turns out much faster.
B-tree means balanced tree, "balanced tree." The index contains exactly one root page, which is the entry point for the search. The root page contains the key values and links to the next level pages for the given index values. When searching by index is the last value that does not exceed the desired value, and the transition to the corresponding page. At the last leaf level of the tree, all keys are listed, and for each of them there is a link (bookmark) to the data in the table. A natural candidate for the role of reference is RID, and it is in fact used in this capacity for the heap case. In the following illustration, the letters B denote references to rows in a table.
')
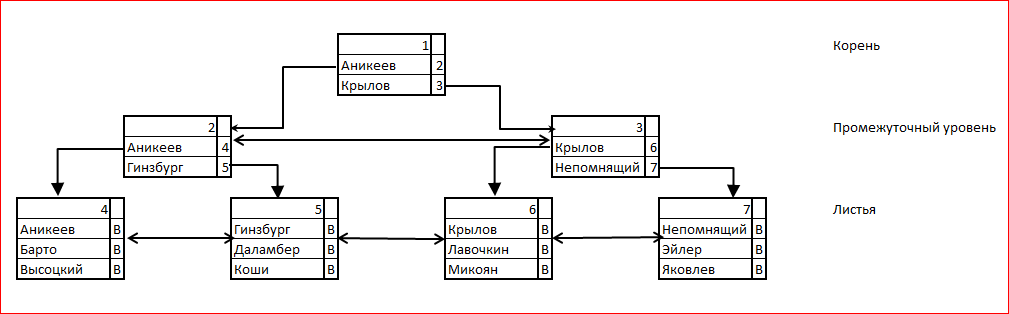
When adding a record to the table, you must also add it to the index. A new index entry referencing the table entry is inserted into the leaf level page. In this case, it may turn out that there is no free space on this page. Then:
It is clear that adding records to a table in the presence of an index becomes a much more expensive process - each page partitioning requires updating at least 4 pages (shared, next to shared, new, parent).
In this case, the presence of the index dramatically accelerates the search for data: instead of a continuous scan, you can conduct a binary search, going down the tree. Also, due to the presence of horizontal links to one level pages, it is possible to quickly go through a range of index keys. And we smoothly approach the main tasks of the sample: searching for a single value and scanning ranges.
Consider a model table organized in the form of a heap: there is no particular order in the records.
The RID that a record receives at the very beginning remains with it almost always. In rare cases, the records in the heap can move to another page — this happens when, after updating, the line no longer fits on the place it occupied. But in this case, the link to the new location remains in the same place - that is, knowing the RID obtained by the string upon adding, the line can always be found. Therefore, for indexes on a heap, the best choice for a reference to data is the RID .
Suppose there are 200 thousand records in a table, and from 48 to 52 records fit into each page. We assume that the table takes 4000 pages. Suppose we need to find all the records in which the [City] field is set to 'Perm'. Also suppose that there are only 3 of them, but we still do not know about it.
The server will have to scan all 4000 pages. Even if the server finds all 3 records, it will still have to go all the same - there is no guarantee that there are no more records needed. So, to fulfill the request, you will need 4000 logical reads of the page.
And if we have an index in which we can search with a binary search - say, a tree of height 3? Then the server will need 3 readings of the index pages in order to find the address of the first record. The addresses of the second and third entries will be next to each other - either in the same page or in the following: the index pages are horizontally linked by links. That is, after a maximum of 4 readings, the server probably knows the RID of all three entries. If you are very unlucky, all 3 entries are in different pages. Thus, if there is an index after 7 logical page reads, all 3 records will most likely be found. 7 vs. 4000 - impressive.
But it will be so good when there are few records. And if this is not 'Perm', but 'Moscow', and the necessary entries are not 3, but 20 thousand? This is not very much, only 10 percent of the total number of records. But the picture quickly becomes not so rosy.
For 3 readings the server will find the first entry. And then he will need to read 20,000 RIDs and read the page 20,000 times to get a string: we remember that the server only reads data in whole pages. It may well turn out that the necessary records are scattered throughout the table, and in order to provide 20 thousand logical readings, it will be necessary to read most of the pages from the disk. More well, if not all. Instead of 4 thousand logical readings, we get 20 thousand.
The index works very well on finding a small number of values, but does not work well on the passage of large ranges.
The query optimizer is well aware of this. Therefore, if he expects that a search by index will give a sufficiently large range, instead of searching by index, he will select a full table scan. This, by the way, is one of the rare places where the Optimizer can make a mistake even having the correct statistics. If in fact the required data is located very compactly (for example, 20 thousand logical reads - this is 60 times to read a block from a disk and 19940 times to read a block in a cache), then the forced use of the index will give a gain in memory and speed.
The problem is that at the end of the index search, the server receives not the data, but only the address at which they lie. The server still needs to go to this address and take data from there. It would be great if at the end of the way the data were immediately lying!
Some, in fact, lie. The values of the keys, for example, lie in the index — you don't need to follow them. Only for non-key fields. And what will happen if non-key fields are also put in the index? Well, let's say not all, but only those that are needed by the scanning query?
And in this case there will be an index with additional (included) columns . It loses the usual index in size: its leaf pages contain not only the keys and addresses of the rows, but also part of the data. In the search for a single value, such an index works no worse, and in the scanning ranges - much, much better. If the index covers the query (that is, it contains all the columns listed in the query), then the table is not needed at all to execute the query. The ability to take all the required data from the index without referring to the bookmarks gives a huge win.
Let's return to our model example. Suppose that the required columns are included in the index. For simplicity, we assume that exactly 50 entries fall into the leaf index page (keys, added columns, links to entries). Then scanning 20 thousand records will require reading only 400 pages of the index - instead of 20 thousand logical readings for a non-covering index.
400 vs. 20 thousand - a difference of 50 times. Query optimizer loves to suggest including certain columns in the index.
Or maybe it’s worth adding all the columns to the index? Then any query will be covered by an index necessarily. Moreover, then the leaves do not even need the RID, because for any data such an index will not apply to the table, everything is at hand. Yes, in this case, the table itself is no longer needed!
And we come to the concept of a clustered index . It is arranged like a normal B-tree, but in its leaf pages instead of links to the records of the table, the data itself is located, and there is no longer a separate table from it. A table cannot have a clustered index; it can be a clustered index.
Any scan by key in a clustered index will be better than a full table scan. Even if you need to scan 97% of all entries.
The first is clear where. A clustered index is a table, and there can be only one table. The server must have a master copy of the data, and only from one index is it ready to throw out all the bookmarks and leave only the data itself. If there is another index in which all the fields are included, it will still contain the addresses of the lines.
There is a second catch. With a clustered index, the RID can no longer be used as the row address. The entries in the clustered index are sorted (physically - within the page, logically - horizontal links between the pages). When you add a record or change key fields, the record moves to the right place — often within a page, but it is also possible to move to another page. In other words, the RID in a clustered index ceases to identify the entry uniquely . Therefore, the key of the clustered index is used as the address of the string that uniquely identifies it.
That is, when searching in a nonclustered index after passing through its tree, we get not the address of the data, but the key of the clustered index. To get the data itself, you need to go through the clustered index tree too.
Imagine scanning a range of 20 thousand records on a nonclustered index built on a clustered one. Now you need to perform not 20 thousand logical readings of a page using a known RID, but 20 thousand searches in a clustered index — and each search will require 3, if not more, logical readings.
And if the clustered index key is not unique? And it does not happen. For the server, it is necessarily unique. If the user asked to create a non-unique clustered index, the server will assign a 4-byte integer to each key, which will ensure the uniqueness of the key. This is done transparently to users: the server not only does not inform them of the exact value of the number, but does not even give out the fact of its presence. The uniqueness of the key is needed precisely for the possibility of unique identification of records so that the key of the clustered index can serve as the address of a string.
Armed with theory, we can describe a rational procedure for building a clustered index. It is necessary to write out all the indices that the table needs, and select from them the candidate for clustering.
You do not need to do a clustered index only for it to be. If an index key is not intended to be scanned - this is not a very good candidate for clustering (if it is assumed for other indexes to be scanned, then even a very bad candidate). Wrong selection of a candidate for clustering will degrade performance because all other indexes will work worse than they did on the heap.
The following selection algorithm is proposed:
When I started writing this article - I understood perfectly why a table cannot have more than one clustered index. In the middle of writing, I stopped to understand this and now I don’t understand it (although, which is funny, I can still explain it). Now I have only hypotheses.
The clustered index, firstly, contains all the data in the leaf vertices, and secondly, it does not contain any references to these tables (because there is no table external to it). Well, what's stopping to get a few indexes arranged this way - containing all the fields and not containing links? I dont know. I can only offer.
First of all, we can have as many indices as we want, in which all fields will be included. This means that the entire gain, which is promised to us by the presence of several clustered indexes, is relatively small: there will be no references to the data at the leaf level of the additional indexes, that is, we will save some space. And what problems will entail the creation of several clustered indexes?
Now I am inclined to think that the prohibition of multiple clustered indexes is related to the fact that the implementation of this concept is costly and fraught with errors (that is, a decrease in reliability), and would bring relatively few benefits. In other words, it is technically possible to make several clustered indexes, but it is expensive, inconvenient and useless.
It is possible that I do not see any considerations due to which it is impossible to do several clustered indexes. I would be very grateful if someone would show me these considerations.
Good luck to everyone in clustering your indexes!
In fact, this beast is completely fearless and even very useful. Let's try to figure out why it is needed and how to use it.
Files, Pages, RID
The data of any table is physically stored in a database file. The database file is divided into pages (page) - logical storage units for the server. A page in MS SQL Server is necessarily 8 kilobytes (8192 bytes), of which 8060 bytes are allocated for data. For each row, you can specify its physical address, the so-called Row ID (RID): in which file it is located, in which in order of the page of this file, in which place of the page. A table is assigned to a page entirely - there can be only one table data on one page. Moreover, if you need to read / write a string, the server reads / writes the entire page, because it turns out much faster.
How does the B-tree index work?
B-tree means balanced tree, "balanced tree." The index contains exactly one root page, which is the entry point for the search. The root page contains the key values and links to the next level pages for the given index values. When searching by index is the last value that does not exceed the desired value, and the transition to the corresponding page. At the last leaf level of the tree, all keys are listed, and for each of them there is a link (bookmark) to the data in the table. A natural candidate for the role of reference is RID, and it is in fact used in this capacity for the heap case. In the following illustration, the letters B denote references to rows in a table.
')
When adding a record to the table, you must also add it to the index. A new index entry referencing the table entry is inserted into the leaf level page. In this case, it may turn out that there is no free space on this page. Then:
- The index is allocated a new page - also at the leaf level.
- Half of the entries from the previous page are transferred to the new one (so that if you add consecutively you don’t run into a situation where you have to select the page again for the next line). The new page is embedded in horizontal links: instead of the Previous Next, the Old Previous Next links are configured.
- A link to a new page with a corresponding key is entered into the parent page. At the same time, the parent page may overflow; then the process of data separation will repeat at a higher level. If the overflow reaches the very top, the root page will be split in two, and a new root will appear, and the tree height will increase by 1.
It is clear that adding records to a table in the presence of an index becomes a much more expensive process - each page partitioning requires updating at least 4 pages (shared, next to shared, new, parent).
In this case, the presence of the index dramatically accelerates the search for data: instead of a continuous scan, you can conduct a binary search, going down the tree. Also, due to the presence of horizontal links to one level pages, it is possible to quickly go through a range of index keys. And we smoothly approach the main tasks of the sample: searching for a single value and scanning ranges.
Heap is small
Consider a model table organized in the form of a heap: there is no particular order in the records.
The RID that a record receives at the very beginning remains with it almost always. In rare cases, the records in the heap can move to another page — this happens when, after updating, the line no longer fits on the place it occupied. But in this case, the link to the new location remains in the same place - that is, knowing the RID obtained by the string upon adding, the line can always be found. Therefore, for indexes on a heap, the best choice for a reference to data is the RID .
Suppose there are 200 thousand records in a table, and from 48 to 52 records fit into each page. We assume that the table takes 4000 pages. Suppose we need to find all the records in which the [City] field is set to 'Perm'. Also suppose that there are only 3 of them, but we still do not know about it.
The server will have to scan all 4000 pages. Even if the server finds all 3 records, it will still have to go all the same - there is no guarantee that there are no more records needed. So, to fulfill the request, you will need 4000 logical reads of the page.
And if we have an index in which we can search with a binary search - say, a tree of height 3? Then the server will need 3 readings of the index pages in order to find the address of the first record. The addresses of the second and third entries will be next to each other - either in the same page or in the following: the index pages are horizontally linked by links. That is, after a maximum of 4 readings, the server probably knows the RID of all three entries. If you are very unlucky, all 3 entries are in different pages. Thus, if there is an index after 7 logical page reads, all 3 records will most likely be found. 7 vs. 4000 - impressive.
But it will be so good when there are few records. And if this is not 'Perm', but 'Moscow', and the necessary entries are not 3, but 20 thousand? This is not very much, only 10 percent of the total number of records. But the picture quickly becomes not so rosy.
For 3 readings the server will find the first entry. And then he will need to read 20,000 RIDs and read the page 20,000 times to get a string: we remember that the server only reads data in whole pages. It may well turn out that the necessary records are scattered throughout the table, and in order to provide 20 thousand logical readings, it will be necessary to read most of the pages from the disk. More well, if not all. Instead of 4 thousand logical readings, we get 20 thousand.
The index works very well on finding a small number of values, but does not work well on the passage of large ranges.
The query optimizer is well aware of this. Therefore, if he expects that a search by index will give a sufficiently large range, instead of searching by index, he will select a full table scan. This, by the way, is one of the rare places where the Optimizer can make a mistake even having the correct statistics. If in fact the required data is located very compactly (for example, 20 thousand logical reads - this is 60 times to read a block from a disk and 19940 times to read a block in a cache), then the forced use of the index will give a gain in memory and speed.
But what about the ranges?
The problem is that at the end of the index search, the server receives not the data, but only the address at which they lie. The server still needs to go to this address and take data from there. It would be great if at the end of the way the data were immediately lying!
Some, in fact, lie. The values of the keys, for example, lie in the index — you don't need to follow them. Only for non-key fields. And what will happen if non-key fields are also put in the index? Well, let's say not all, but only those that are needed by the scanning query?
And in this case there will be an index with additional (included) columns . It loses the usual index in size: its leaf pages contain not only the keys and addresses of the rows, but also part of the data. In the search for a single value, such an index works no worse, and in the scanning ranges - much, much better. If the index covers the query (that is, it contains all the columns listed in the query), then the table is not needed at all to execute the query. The ability to take all the required data from the index without referring to the bookmarks gives a huge win.
Let's return to our model example. Suppose that the required columns are included in the index. For simplicity, we assume that exactly 50 entries fall into the leaf index page (keys, added columns, links to entries). Then scanning 20 thousand records will require reading only 400 pages of the index - instead of 20 thousand logical readings for a non-covering index.
400 vs. 20 thousand - a difference of 50 times. Query optimizer loves to suggest including certain columns in the index.
Or maybe it’s worth adding all the columns to the index? Then any query will be covered by an index necessarily. Moreover, then the leaves do not even need the RID, because for any data such an index will not apply to the table, everything is at hand. Yes, in this case, the table itself is no longer needed!
And we come to the concept of a clustered index . It is arranged like a normal B-tree, but in its leaf pages instead of links to the records of the table, the data itself is located, and there is no longer a separate table from it. A table cannot have a clustered index; it can be a clustered index.
Any scan by key in a clustered index will be better than a full table scan. Even if you need to scan 97% of all entries.
Where is the catch?
The first is clear where. A clustered index is a table, and there can be only one table. The server must have a master copy of the data, and only from one index is it ready to throw out all the bookmarks and leave only the data itself. If there is another index in which all the fields are included, it will still contain the addresses of the lines.
There is a second catch. With a clustered index, the RID can no longer be used as the row address. The entries in the clustered index are sorted (physically - within the page, logically - horizontal links between the pages). When you add a record or change key fields, the record moves to the right place — often within a page, but it is also possible to move to another page. In other words, the RID in a clustered index ceases to identify the entry uniquely . Therefore, the key of the clustered index is used as the address of the string that uniquely identifies it.
That is, when searching in a nonclustered index after passing through its tree, we get not the address of the data, but the key of the clustered index. To get the data itself, you need to go through the clustered index tree too.
Imagine scanning a range of 20 thousand records on a nonclustered index built on a clustered one. Now you need to perform not 20 thousand logical readings of a page using a known RID, but 20 thousand searches in a clustered index — and each search will require 3, if not more, logical readings.
And if the clustered index key is not unique? And it does not happen. For the server, it is necessarily unique. If the user asked to create a non-unique clustered index, the server will assign a 4-byte integer to each key, which will ensure the uniqueness of the key. This is done transparently to users: the server not only does not inform them of the exact value of the number, but does not even give out the fact of its presence. The uniqueness of the key is needed precisely for the possibility of unique identification of records so that the key of the clustered index can serve as the address of a string.
So do or not do?
Armed with theory, we can describe a rational procedure for building a clustered index. It is necessary to write out all the indices that the table needs, and select from them the candidate for clustering.
You do not need to do a clustered index only for it to be. If an index key is not intended to be scanned - this is not a very good candidate for clustering (if it is assumed for other indexes to be scanned, then even a very bad candidate). Wrong selection of a candidate for clustering will degrade performance because all other indexes will work worse than they did on the heap.
The following selection algorithm is proposed:
- Determine all indexes for which a single value is searched. If such an index is unique, it should be clustered. If several - go to the next step.
- Add to indexes from the previous step all indexes for which range scanning is supposed. If there are none, a clustered index is not needed, several indexes on the heap will work better. If there is - each of them should be made covering, adding all the columns that are needed for scanning queries on this index. If such an index is unique, it should be clustered. If there are more than one, go to the next step.
- There is no clear best choice among all the covering indexes for a clustering candidate. You should cluster any of these indices, taking into account the following:
- Key length The clustered index key is a string reference and is stored on the leaf level of a nonclustered index. Shorter key lengths mean less storage and better performance.
- Degree of coverage. A clustered index contains all the fields for free, and the covering index with the largest set of fields is a good candidate for clustering.
- Frequency of use. Searching for a single value in a covering index is the fastest possible search, and a clustered index is covering for any query.
P.S. Why is he the only one?
When I started writing this article - I understood perfectly why a table cannot have more than one clustered index. In the middle of writing, I stopped to understand this and now I don’t understand it (although, which is funny, I can still explain it). Now I have only hypotheses.
The clustered index, firstly, contains all the data in the leaf vertices, and secondly, it does not contain any references to these tables (because there is no table external to it). Well, what's stopping to get a few indexes arranged this way - containing all the fields and not containing links? I dont know. I can only offer.
First of all, we can have as many indices as we want, in which all fields will be included. This means that the entire gain, which is promised to us by the presence of several clustered indexes, is relatively small: there will be no references to the data at the leaf level of the additional indexes, that is, we will save some space. And what problems will entail the creation of several clustered indexes?
- The keys of a clustered index are references to data that is stored in the leaves of nonclustered indexes. If there could be several clustered indexes, one would still have to allocate the “main” index, the one whose keys are data identifiers.
- If a non-key column needs to be added to a clustered index, then the index will have to be completely rebuilt, and nonclustered indexes on it do not need to be changed at all. If there were several clustered indexes, everything would have to be rebuilt, and it would be impossible to determine in advance how long it would take.
- There would be many situations fraught with errors. For example, if there are multiple clustered indexes, the user deletes the master index (the one whose keys serve as references to data in nonclustered indexes), then the server will have to automatically select a new master index.
Now I am inclined to think that the prohibition of multiple clustered indexes is related to the fact that the implementation of this concept is costly and fraught with errors (that is, a decrease in reliability), and would bring relatively few benefits. In other words, it is technically possible to make several clustered indexes, but it is expensive, inconvenient and useless.
It is possible that I do not see any considerations due to which it is impossible to do several clustered indexes. I would be very grateful if someone would show me these considerations.
Good luck to everyone in clustering your indexes!
Source: https://habr.com/ru/post/188704/
All Articles