Why web applications on mobile platforms are slow
From translator
This is a translation of the article by Drew Crawford “Why mobile web apps are slow, ” published on July 9, 2013. The article is very interesting, but big - mistakes are possible - please forgive and send comments to the PM.
As the sharp topic is touched upon, please note that the translator does not necessarily share the opinion of the author of the article !
When translating the text slightly modified, since the direct translation is not always clear conveys the meaning. To translate the term “native code” , Anglicism “native code ” was used, which is clearer and shorter than “platform native code” . The term “word processing” is translated as “layout of the text” , although this slightly narrows the original meaning. The term managed code (“managed code”) has not been translated, as there is no successful translation (in the translator’s opinion). The term “termination” of an application means its compulsory termination by the operating system.
The narrative in the article is from the first person: the author of the article.
The response to my previous article (claiming that web applications on mobile platforms are slow) was an unusually high amount of interesting discussions. From the article, as from a spark, the flame of discussion, which flowed both in the web and in real life, flared up. Unfortunately, this discussion is not so strongly based on the facts, as we would like.
In this article, I'm going to give the actual evidence related to the problem under discussion, instead of playing the game “who shouts to whom . ” You will see comparative tests, hear the opinions of experts, and even be able to read "sincere-how-to-confession" notes from subject magazines. There are over 100 quotes in this article, and this is not a joke. I do not guarantee that this article will convince you, moreover, I do not even guarantee that everything in it is absolutely authentic (this cannot be done in an article of this size), but I can guarantee that this is the most complete and objective approach to the problem Many iOS developers have already realized: that web applications on mobile platforms are slow and will work slowly in the foreseeable future.
')
I just want to warn you - the article is unrealistically large, more than 10,000 words. So it was intended. Last time I prefer informative articles to popular ones. This article - a contribution to the piggy bank of meaningful articles - as an attempt to practice what I myself preached before: deep, evidence-based discussions should be encouraged as opposed to writing empty but witty comments.
The article is written in dry language, because the topic under study has been sucked in different forms many times. If you wanted to read the 30-second chatter on the subject of "mobile web applications suck!" / "Hell! No , this article is not for you ( from the translator: here in the original article there is a mass of references to similar English-language discussions ). On the other hand, as far as I know, there is no full, objective, demonstrative discussion of this problem on the web. It may be a silly idea, but this article is an attempt to speak convincingly and substantively about a problem, 100% of which discussions usually come down to a holivor. In my defense I can say that I believe that this is not because of the problem itself, but because of the unwillingness to improve the quality of discussion by its participants. I believe that we will find out if this is so.
So, if you are painfully trying to understand what your friends - native mobile application developers - persistently writing perverse, native applications stubbornly, are at the top of the web revolution, then bookmark the article, pour yourself coffee, free the morning, find a comfortable chair ready.
SHORT REVIEW
My previous article , based on SunSpider performance tests, argued that, for the time being, web applications on mobile platforms are slow:
“If by 'web application' is meant a 'page with a couple of buttons', then cozy performance tests, like SunSpider, will fit perfectly. But lightweight photo editing, lightweight text layout, data storage on the user's side and animation between screens in a web application running on ARM architecture should be done for one reason only: if your life is in mortal danger. ”
You should read that article, but, in any case, here are the test results:
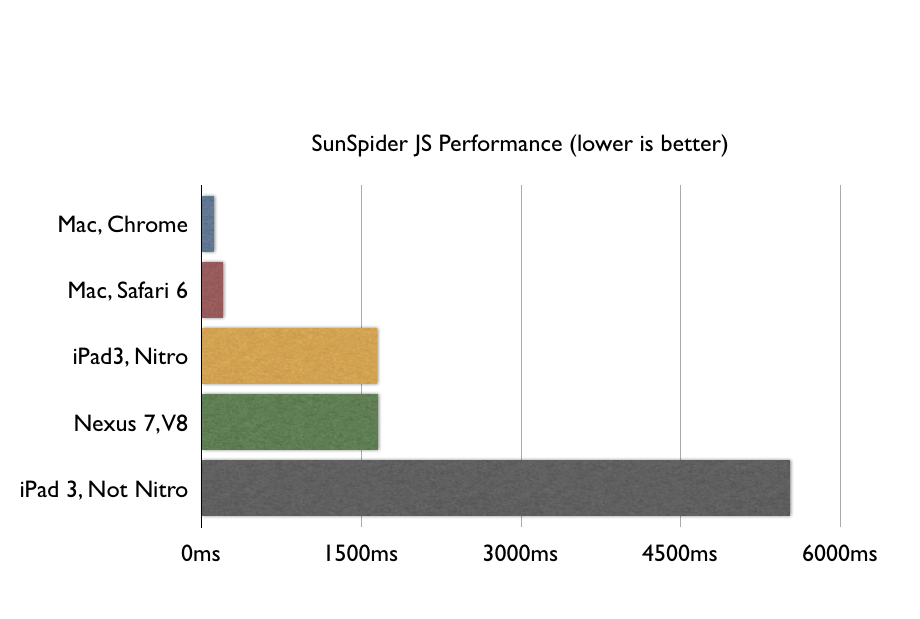
There are three significant categories of objections to this schedule:
1. The fact that JS is slower than native code is not new: everyone has known this since the days of CS1 and the discussions of compiled, JIT and interpreted languages. The only question is - is it too slow for JS to work for your specific task - and synthetic tests do not provide an answer to this question.
2. Yes, JS is slower and it interferes, but it gets faster and sooner or later it will become so fast that it pulls your task (see point 1), so it's time to start investing in JS.
3. I write server code in Python / PHP / Ruby and have no idea what you are talking about. I know that my servers are faster than your mobile phones, but I’m confidently holding X, 000 users using an interpreted programming language, but you can’t figure out how to satisfy one in the JIT-language?
I have a transcendental goal - I want to refute all these three statements in this article! Yes, JS is so slow that it becomes unusable; no, it will not become much faster in the coming years; No, your server programming experience in scripting languages cannot be adequately transferred to mobile platforms.
As a rule, in such articles, “they didn’t notice the elephant,” that is, no one tried to really measure how slower the JS was or suggested a useful, suitable way to do it (you know ... slow compared to what?). In this article, I will cite not one, but as many as three ways to measure performance equivalence with respect to JS performance. So, I’ll not just talk in the language “blah blah JS slows down”, but I’ll give measuring comparisons to several tasks that you actually encounter as developers, so you can calculate for yourself whether there is enough performance for your specific task.
OK, BUT HOW HOW TO MEASURELY measure JAVASCRIPT PERFORMANCE WITH RESPECT TO THE NATIVE CODE?
Good question. To answer it, I chose a random performance test from The Benchmarks Game. Then I found an old C program that does the same thing (the old one, since the new ones contain all sorts of x86 optimizations). Then I measured the performance of Nitro ( from the translator: JS-engine Safari ) in relation to LLVM on my correct iPhone 4S. All code is available on GitHub .
Yes, this is all very random code. But in real life, the code is no less random. Want to make a better experiment - a flag in your hands. I conducted this experiment simply for the reason that I did not find any other similar ones (comparing Nitro and LLVM).
In any case, in this synthetic test, LLVM ( from translator: that is, native code ) is about 4.5 times faster than Nitro ( from translator: JavaScript code ).

So, if you ask yourself the question “how much faster does my function execute natively, compared to execute it on Nitro JS,” then the answer is this: it works about 5 times faster . This result roughly corresponds to the results of the Benchmarks Game, where x86 / GCC / V8 are compared. They claim that GCC / x86 runs on average from two to nine times faster than V8 / x86. So the result I received does not fall out of the picture of the world, and it is true for the ARM architecture and for x86.
BUT DOWNTIME 640 KB OF MEMORY 1/5 PERFORMANCE IS NOT ENOUGH FOR EVERYONE?
Quite enough on x86. Well, really, well, how much resource-intensive to display a sign? Not too much. One problem: ARM is not x86.
According to GeekBench , the latest MacBook Pro is faster than the last iPhone by an order of magnitude . Well, okay, on the plates is still enough. We need 10% of performance. Give me a sec! You have not forgotten to divide these 10% by 5 more? So, in the bottom line, we have only 2% of the performance of the desktop (I’m a little careless rounding the units, but for our reasoning there’s enough accuracy).
Well, well, but how much resource-intensive is the text layout? Didn't they do it on m68k? Well, this question is easy to answer. Maybe you do not remember, but the joint work with documents appeared in Google Docs not immediately. They significantly rewrote the code and added this feature in April 2010. Let's look at the performance of browsers back in 2010:

This chart clearly shows that the iPhone 4S cannot compete with browsers at the time point when Google added document collaboration. Well, that is, IE8, he overtakes, congratulations!
Let's look at another serious JS application: Google Wave. Wave never worked in IE8 (according to Google ), because it was too slow.

Please note that the supported browsers were in 1000, and the one that issued 3800 was excluded because it is slow. The iPhone produces 2400. And, like IE8, it is not sufficiently productive to launch Wave.
For clarity: sharing documents on mobile devices is possible. But not on JS. The performance difference between the native and the web application is comparable to the performance difference between FireFox and IE8 and is too big for serious work.
BUT I HAVE SEEN THAT THE PERFORMANCE OF V8 / MODERN-JAVASCRIPT IS COMPARABLE WITH THE PERFORMANCE OF APPLICATION ON C?
Depends on what is considered "comparable". If the C program runs in 10 ms, then the 50 ms JS program can be considered “comparable”. But if the C-application takes 10 seconds, then 50 seconds JS application for most is already incomparable with it.
VIEW FROM THE HARDWARE
The lag 5 times is generally not scary on the x86 platform, because x86, to begin with, is an order of magnitude faster than ARM. There is stock. The solution is simple: increase ARM performance 10 times and - voila - we get desktop performance on a mobile device.
The feasibility of this somehow revolves around your belief in Moore's Law, which is trying to speed up a chip that runs on an 80 g battery. Not being a hardware engineer, I worked for a large semiconductor company and its employees told me that the current performance is the result of the process (here this one thing that is measured in nanometers). The impressive performance growth of the iPhone 5 is largely due to a decrease in process technology — from 45 nm to 32 nm — by about a third. To repeat this step, Apple will have to reduce the process technology to 22 nm.
Just in case, we note that Intel's next-generation Atom processor (Bay Trail) - on the 22 nm process - does not yet exist. And Intel had to invent a completely new type of transistor , as the old one simply could not work at 22 nm. Do you think they license this ARM technology? Think again. There are only plans for the construction of 22 nm factories and most of them are controlled by Intel.
In fact, ARM will reduce the process technology to 28 nm in the next year or so (watch A7), and Intel is preparing for the transition to 22 nm (and maybe 20 nm) a little later. At the hardware level, I am much more willing to believe that x86 will be inserted into a mobile phone before an ARM chip with comparable performance appears.
Comments from a former Intel engineer:
I am a former engineer who worked on microprocessors for the mobile platform and later on Atoms. My (incredibly biased) opinion: it will be easier to plug x86 into the phone, abandoning some of the functionality, than to increase the performance of ARM to x86, adding functionality to it from scratch.
Note from a robot engineer:
You are absolutely right when you say that there will be no significant increase in productivity, and that Intel will receive a more efficient mobile processor in only a few years. In fact, mobile processors have come up against the limit that desktop processors have come up against when they have reached ~ 3 Ghz: a further increase in frequency entails a sharp increase in power consumption and this rule will also apply to the following processes, although they will slightly increase IPC ( by 10-20%). Reaching this limit, desktop processors have become multi-core, but mobile systems-on-a-chip are multi-core, so there won't be an easy performance boost.
So, maybe Moore's Law is fulfilled, but on condition that the entire mobile ecosystem goes to x86. It is not absolutely impossible - they did this before . But at that time, sales amounted to about a million devices per year, and now for one quarter, 62 million are sold. This was done using virtualization, which emulated the old architecture at 60% performance , while modern hypothetical virtualization for optimized (O3) ARM code is closer to 27% .
In order to believe that JS performance will cease to be a problem sooner or later, the easiest way is to follow a hardware path. Either within five years, Intel will have a viable chip for the iPhone (which is likely) and Apple will switch to it (which is unlikely), or ARMs will catch up over the next decade (ask 10 engineers on this score and get 10 opinions). But the decade is still a long time, in my opinion, for something that shoots.
I'm afraid my knowledge of hardware ends here. If you want to believe that ARM will catch up with x86 in 5 years, then the first step is to find someone who works for ARM or Intel and who agrees with you. I consulted with many similar engineers and they all rejected this statement. From which it follows that this is likely not to happen.
VIEW FROM SOFTWARE
Many competent programmers make the same mistake. They speculate as follows: JavaScript has already become much faster than it was! And it will be getting faster and faster!
Package is correct. JavaScript has greatly accelerated. But we are currently at the peak of javascript performance. Further acceleration is hardly possible.
Cause? To begin with, we note that most of the JS improvements in its history are in fact related to the hardware . Jeff Atwood writes :
I found that javascript performance increased from 1996 to 2006 100 times . Building Web 2.0 “on the skeleton” of JavaScript was made possible mainly due to the increase in productivity, according to Moore's law.
If we associate the increase in JS performance with the increase in productivity of the hardware platform, then we should not expect a significant increase in software performance in the near future. Do you want to or not, but if you believe that the speed of JS will increase, then it is most likely that this will happen because of the increase in hardware performance, since such are the trends.
What about JIT ( from translator: virtual machines that sped up JS execution )? V8, Nitro / SFX, TraceMonkey / IonMonkey, Chakra and so on? Well, at the time of their appearance, they played a role, but still not as large as you would like to think. V8 was released in September 2008. I dug out a copy of Firefox 3.0.3 from about the same amount of time:

You just do not get me wrong - a 9-fold increase in productivity is not a joke; after all, something like this is the difference in power between ARM and x86. However, the difference in performance between Chrome 8 and Chrome 26 is a gentle curve, because since 2008, nothing revolutionary has happened here. The rest of the browser makers pulled up - somewhere a little slower, somewhere a little faster, but no one could seriously improve the speed of the code since then.
IS THE JAVASCRIPT PERFORMANCE GROWTH OBSERVED AT THE PRESENT TIME?

Here is Chrome 8 on my Mac (the earliest one that still works, December 2010). But Chrome 26 .
Can you tell the difference? Because there is none. Recently, nothing revolutionary has happened in the code that executes JavaScript .
If it seems to you that the web has accelerated in comparison with 2010, then this is most likely due to the fact that your computer is faster and has nothing to do with Chrome improvements.
NOTE . Some clever men noted that the SunSpider test is not suitable at the current time (without citing concrete evidence). In the interest of truth, I launched Octane (an old Google performance test) on older versions of Chrome and saw some improvements:

In my opinion, the performance gain over this period is too small to claim that JS will catch up with the native code in a reasonable period of time. Honestly, I went over a bit: JS performance grew over this period. However, in my opinion, these figures still confirm my hypothesis: that JS will not catch up with the native code in a reasonable time. You need to increase performance from 2 to 9 times to catch up with LLVM. There are improvements, but they are insufficient. END OF COMMENTS.
In fact, the idea is to speed up JS with the help of JIT - 60 years and during this period all kinds of research and thousands of optimizations have been done for all conceivable programming languages. But this came to an end, guys, we squeezed out of these ideas all that was possible. The end of the film. Maybe in the next 60 years we will come up with something new.
BUT SAFARI IS EVERYTHING WORKING FASTER THAN BEFORE
But if everything is as you say, why do we constantly hear about a significant increase in JS performance? Every week someone talks about the next acceleration in the next performance test. Apple claims that it has achieved a tremendous speed increase of 3.8 times on the JBench test:

Perhaps Apple is in the hands of the fact that this version of Safari is still under the NDA agreement ( from translator: non-disclosure ), so no one else is able to publish independent measurements. But let me draw some conclusions based solely on public information.
I find it quite amusing that Apple’s JS performance in the JSBench test is much higher than the claimed performance in traditional tests such as SunSpider. For JSBench are well-known personalities , such as Brenden Eich (creator of JavaScript). However, unlike traditional tests, JSBench does not use programs that multiply numbers or do something similar. Instead, JSBench sucks up what Amazon, Facebook, and Twitter give out and builds its performance tests on this basis. If you are writing a browser that most people use to go on Facebook, then of course having a test that mimics Facebook will be quite useful. On the other hand, if you are writing a tabular application, a game or a graphic filter, it seems to me that the traditional performance test with its multiplications and calculations of md5 hashes will be much more adequate and useful than information about how fast Facebook analytics works.
Another important fact is that the improvement in the SunSpider test (according to Apple) does not mean that everything else is automatically accelerated. In a note representing Apple’s preferred performance test, Eich and others write:
This chart clearly shows that, according to the SunSpider test, the performance of FireFox has increased 13 times from version 1.5 to version 3.6. However, if you look at the performance in the amazon test, here we see a moderate increase of 3 times. Curiously, over the past two years, productivity growth in the amazon test is practically not observed. I believe that many optimizations that worked perfectly in the SunSpider test do not play a role for the amazon test.
In this article, the creator of JavaScript and one of the top architects of Mozilla openly admits that over the past two years, nothing has happened to JavaScript in the Amazon test, moreover, nothing revolutionary has happened in the whole history. This is an example of how the guys from the marketing department overestimate things a bit lately.
(They keep insisting that the Amazon test helps predict the Amazon runtime better than the SunSpider test [hello KO!], So it's useful for browsers that people use to go to Amazon. But none of this will help you write a photo web application).
In any case, based on publicly available information, I want to note that the assurances of Apple in the 3.8-th performance increase will not bring you any benefit. I also have to say that, even with tests in hand, which refute Apple’s statement that Safari is ahead of Chrome, I would not have the right to publish them.
Let's end this section with the conclusion that even if someone drew a graph on which his browser has become faster, it does not necessarily mean that JavaScript as a whole becomes faster.
But there is a bigger problem.
DESIGNED NOT FOR HIGH PERFORMANCE

( from the translator: the left book is called “JavaScript: good sides”, the right one is “JavaScript: a complete reference book” ).
To quote Herb Sutter , a large size in the world of modern C ++:
This meme can no longer be destroyed - “just wait for the next generation (JIT or regular) compilers, and the managed code will work on them relatively efficiently” . Yes, I'm waiting for improvements in the C # and Java compilers - and JIT, and NGEN-like static compilers. But, no, they will not erase the performance difference with native code for two reasons. First, JIT compilation is not a major issue. The root cause of the lag is more fundamental: managed platforms were deliberately designed to increase programmer productivity, even if this was at the expense of performance . In particular, the creators of managed platforms decided to spend resources on certain opportunities, even if they are not used by the application; The main features of this feature are: always running garbage collection, virtual machine execution system and metadata. But not only that, there are other examples: in managed languages, function calls are virtual by default, while in C ++, calls are inline by default ( from the translator: that is, the function body is directly compiled into code instead of call / ret ) and a spoon inline- .
Miguel de Icaza Mono, «, JIT-». He says:
managed (.NET, Java JavaScript). managed .
Alex Gaynor , JIT Ruby JIT Python:
, . -. ( : , ) , C- -, C . . -, C — . , Python, Ruby, JavaScript , … , …
Google , , , JavaScript :
- — Google — , .
, . Brendan Eich. , , , JavaScript.
Mike : . Lua , JS. , , , JIT- ( JS)
:
JS Lua, , ( ?), , , . , , , . JS , Lua. : Lua ( metatable) JS.
, , JS ( ) ( ) C, , , . - , — ( - ) — . « JIT- C» , , : «, API».
.

, , — , — . — . , , , — . , . , , , .
2012 Apple ( , John Gruber ). OSX. , . « ». Ruby, Python, JavaScript, Java, C#, , 1990, , , . , ObjC. , , . - , . ? , Apple:
, ARC , OSX (- Session 101, Platforms Kickoff, 2012, ~01:13:50)
? . , - . , , «---»? Matz- RubyConf. ? .
-, — - . , .
, : — , ? , ARC — Apple , , . , iOS.
ARC
, , ARC — , Apple:

( :
ARC:
— runtime ;
— malloc, free, .
— :
— ;
— ;
— .
)
. , , , , , , . , . ARC — .
, ( , ) , — . It is not true. , .
,
Apple ARC GC ( ), :
, , iOS. . , . . , CPU . , GC . G, retain/release , , . , . , , (~Session 300, Developer Tools Kickoff, 2011, 00:47:49).
?! :
1. ;
2. Windows Mobile, Android, MonoTouch GC.
.
,
, . N . 2013 . .
, . , :

- , . Y — , . X — « ». ? .
, : « 6 , , — . , 4 ». :
, 5 , , . , , . 3- , , 17% , — 70% . , . , .
() :
These graphs show that if an application has a reasonable amount of memory available (but not enough to fit the entire application), both direct memory managers are much faster than all garbage collectors. For example, pseudoJBB with 63 MB of available memory and the Lea allocator complete the task in 25 seconds. The same amount of GenMS memory takes 10 times longer (255 seconds). Similar behavior is observed on all tests included in the set. The most distinctive test is 213 javac: for 36 MB of memory with the Lea allocator, the total running time is 14 seconds, while the test time for GenMS is 211 seconds, which is 15 times longer.
The fundamental conclusion is that the performance of the garbage collector in an environment with a limited amount of memory is sharply reduced. If you are programming on Python, Ruby or JavaScript on desktops, then most likely, you are always on the right side of the graph and in your entire life you will never encounter a slow garbage collector. Go to the left side to understand what others are dealing with.
HOW MUCH MEMORY IS AVAILABLE APP ON IOS?
It is hard to say for sure. The amount of physical memory on devices varies from 512 MB on iPhone 4 to 1 GB on iPhone 5. But most of this memory is used by the system and also for multitasking. The only way to check is to run in real conditions. Jan Ilavsky has created an application for this purpose , but it seems no one has yet published the results. Up to this day.
It is important to measure the memory in “normal” conditions, because if you do it right after loading, the results will be better, because there are no costs for pages opened in Safari and the like. So I literally took my devices scattered around the apartment and drove the tests for them.


To see the details, click on the picture, but, strictly speaking, on the iPhone 4S, the application begins to receive warnings about a lack of memory, allocating about 40 MB, and is terminated at (approximately) 213 MB. On the iPad 3, a warning of 400 MB and a termination of 550 MB. Of course, these are my results - if the user listens to background music, then the memory may be much less, but this is at least some guide to start. It seems a lot (213 MB should be enough for everyone, right?), But from a practical point of view, not enough. For example, the iPhone 4S takes pictures of 3264 × 2448 pixels. This is approximately 30 MB of data per snapshot. This means receiving a warning when there are only two snapshots in memory and terminating an application that holds 7 snapshots in memory . Oh, you wanted to write a cycle on the photos in the album? The application will be closed!
It is important to emphasize that in practice very often the same snapshot is stored in several places in memory. For example, if you take a picture from a camera, then 1) the screen of the camera is stored in memory, which displays what it sees 2) the picture that the camera took 3) the buffer in which you compress the JPEG image to save to disk 4) the version of the snapshot you want to show on the next screen 5) the version of the snapshot that you upload to some server.
At some point, you will realize that using a 30 MB image buffer for displaying thumbnails is not a good idea and add 6) a buffer for the thumbnail to the next screen 7) a buffer in which the thumbnails are actually created in the background (since this is not possible in the main stream — too slowly). And then you suddenly realize that thumbnails are actually required of 5 different sizes and slowly begin to go crazy. In short, even when working with a single photo, it is easy to exceed the available memory limit. You may not believe me:
The worst idea with a limited amount of memory is to cache images. When the image is copied to the output context or displayed on the screen, it is necessary to decode it into a bitmap. 4 bytes are allocated for each pixel in the bitmap, regardless of the image size. This bitmap is “suspended” to the object with the original image and its lifetime coincides with the lifetime of the image object. So, if you cache images that have been displayed on the screen at least once, then for each one you now store the associated bitmap. Therefore, never put UIImages or CGImages into the cache, unless you have a very valid (and short) reason to do so. - Session 318, iOS Performance In Depth, 2011
Yes, you can even not believe them. In fact, the size of the memory that your application allocates is the tip of the iceberg. Seriously, here is the slide on which the iceberg itself is presented (Session 242, iOS App Performance - Memory, 2012):

(slide translation: NOT ONLY OBJECTS
* heap memory
- * + [NSObject] alloc] / malloc
- * objects / buffers allocated by frameworks
* another memory
- * code and global variables (___TEXT, ___DATA)
- * thread stacks
- * image data
- * CALayer buffer
- * database caches
* memory, outside your application
)
And this candle burns from both ends. It’s much harder to work with photos if you have only 213 MB, unlike the desktop. And at the same time, the demand for photo applications is much higher, since your desktop does not have a cool camera and it does not fit in your pocket .
Take another example. For iPad 3, the display resolution is likely to exceed the resolution of your monitor (in terms of cinematography, this screen is in the range between 2K and 4K). Each image frame takes 12 MB. If you do not want to violate the memory limits, you can store approximately 45 frames of uncompressed video or animation in memory at the same time, which takes 1.5 seconds at 30 FPS, or .75 seconds with the system 60 FPS. Randomly placed in the buffer a second full-screen animation? The application will be closed. And here you can also note that the delay in AirPlay is 2 seconds , so for any media application you are guaranteed not enough memory .
And here again the same problem of multiple copies of the image arises. For example, Apple claims that “CALayer is associated with each UIView and the images of the layers remain in memory while CALayer is in the hierarchy of objects”. This means that there may be many images in memory with an intermediate representation of your view hierarchy.
There are also clipping rectangles and layer buffers. This is a great architecture in terms of CPU savings, but its performance is achieved by allocating as much memory as possible. iOS is not designed in terms of saving memory, but in terms of high performance . Which is not very well combined with garbage collection.
And again the candle burns from two ends. We have not only a very limited environment for full-screen animation. But the huge demand for high-quality video and animation, since this terrible, little-memorable environment is in fact the only form factor in which you can purchase a high-quality film display. If you want to create programs for such permission on desktops, then first convince your users to spend $ 700 only on the monitor. Or they can buy an iPad for $ 500, and it already has a computer.
WILL THE NUMBER OF AVAILABLE MEMORY INCREASE?
Some clever people say to me - “OK, you convinced us that we won’t get a faster mobile CPU. But the amount of memory will grow, right? Grew up on desktops. ”
The problem with this theory is that the ARM memory is on the processor itself . This scheme is called package on package (PoP) (from translator: chip on chip) . So the difficulties of increasing the memory volumes are in fact similar to the difficulties of overclocking the CPU, since they boil down to how to fit more transistors per chip. Memory transistors can be slightly lighter, they are the same in size, but still difficult.
If you look at the A6 image on the iFixit website , you will see that almost 100% of the area on the chip's surface is occupied by memory. This means that to increase memory, it is necessary to reduce the process technology or increase the chip . And if measured relative to technical process, then an increase in memory every time is associated with an increase in chip size:

Silicon is not an ideal material, so with the increase in size, there is an exponential increase in the cost of suitable chips. And such chips are harder to cool and put in a mobile phone. And they have the same problems as the CPU, because the memory is the top layer of the chip, into which more transistors have to be pushed.
What I don't know is why manufacturers, in the face of these PoP problems, continue to use it. I did not find an ARM engineer who would explain it to me. Maybe someone will write a comment. It may be worth refusing from PoP in favor of separate memory modules as on desktops. But since this is not, then there is some reason not to do it.
However, several engineers wrote to me.
Former Intel engineer:
As for PoP. This architecture greatly increases throughput and simplifies routing. But I don’t do ARM and I don’t know everything.
Robotics engineer:
When PoP becomes lacking, “3D” memory will be able to give “enough memory for all”: memory chips stacked up with the ability to place more than 10 layers of 1 GB of memory in the same volume as now. But: costs will increase, and the voltage and frequency will have to be reduced in order to meet the power limits.
Mobile memory bandwidth will not grow as fast as it did before. It is limited by the number of lines between the CPU and the memory. Currently, most of the CPU peripheral connections are used for the memory bus. The middle part of the CPU cannot be used for this due to technical limitations. The next breakthrough should be expected from the integration of memory right inside the CPU: this will increase the bandwidth, there will be more CPU design freedom and the voltage will drop. And perhaps a large fast cache will appear.
BUT HOW, THEN MONO / ANDROID / WINDOWS MOBILE SUCCESSFULLY MANAGE WITH THIS?
There are two answers to this question. The first follows from the schedule ( from the translator: memory consumption by the garbage collector ): if you have 6 times more memory than you need, then garbage collection is fast. If, say, you are programming a text editor, then you can easily keep within 35 MB, which is 1/6 of the memory limit on which the application on the iPhone 4S is terminated. So you can take Mono, write an editor, make sure that it works quickly and calculate that garbage collection is quite fast. And you will be right.
Yes, but the flight simulator is included with Xamarin. It turns out that garbage collection works fine for large mobile applications? Or not ?
What problems did you encounter while developing this game? “Performance was a major issue and continues to be so on all platforms. The first Windows Phone were rather slow and we had to spend a lot of time optimizing in order to achieve an acceptable FPS. These optimizations affected both the simulation code and the 3D engine. “Narrow neck” is garbage collection and GPU weakness. ”
Without the slightest hint of a question, developers cite garbage collection as one of the main performance bottlenecks. If people in your development team do it, you should consider . But maybe Xamarin is not a typical example. Read developers on Android:
Please note - applications run on my Galaxy Nexus - to name that language does not turn slow. Look at the time spent rendering. On the desktop, these images were created in a couple of hundred ms, while on a mobile device it was spent two orders of magnitude more time . More than 6 seconds on “inferno” ( from translator: a planet with complex rendering )? Madness! .. During this time, the garbage collector will work 10-15 times.
More :
If you are going to be engaged in processing camera snapshots on Android devices for recognizing objects in real-time or for creating Augmented Reality, you probably heard about the problem of camera preview memory. Whenever a Java application receives a preview image, a new buffer is allocated in memory. When this buffer is released by the garbage collector, the system freezes for 100–200 ms. Even worse, if the system is under load (I do image recognition - it eats away the entire CPU). If you look at the sources of Android 1.6, you will see that this happens for the reason that the wrapper (which protects us from the native code) allocates a new memory buffer for each new frame. The built-in native code of this problem, of course, does not .
Or we can read Stack Overflow :
I am engaged in improving the performance of an interactive Java game for Android. From time to time there is a delay in garbage collection in the display or interaction. It usually lasts less than a tenth of a second, but sometimes it can take 200 ms on slow devices ... If I suddenly need hashes in the internal loop, I know that I need to be careful or rewrite them myself instead of using the Java Collections framework because allow extra garbage collection.
Here is the most significant answer, 27 votes "for":
I was involved in Java mobile games ... The best way to avoid garbage collection (which will occur at an arbitrary point in time and kill the game's performance) is not to create objects in the main loop at all. There is no other way ... Onlyhardcoremanual control of objects, alas . So do all the major high-performance games on mobile devices.
Listen to Jon Perlow from Facebook:
The garbage collector is a huge performance problem when developing "smooth" applications on Android. In Facebook, one of the main problems is the fading of the UI stream during garbage collection. When you process a large number of bitmaps, garbage collection occurs frequently and cannot be avoided. One such collection results in the loss of several frames. Even if the assembly blocks the main thread for only a few milliseconds, it may not allow the frame to be generated in the 16 ms allocated for it.
Read Microsoft MVP :
Normally, your display code will be set at 33.33 ms ( from translator: one frame ), while maintaining an acceptable 30 FPS ... However, garbage collection takes time. If you do not litter on the heap, the assembly will work quickly and will not be a problem. But keeping the hip “clean” enough to quickly process the garbage collector is a complex programmer task that requires careful planning and rewriting of the code and still does not guarantee stable operation (as a rule, a lot of things are stored in a complex game of hip) . It is easier (if possible) to limit or, in general, not to allocate memory during the game process .
The best way to beat the garbage collector is not to play at all . This statement (in a more mild form) is in the official Android documentation :
Creating an object is not free. A garbage collector that uses generations and pools for each stream can speed memory allocation, but memory allocation is always more expensive than memory allocation. As you allocate more and more objects, you will encounter periodic garbage collection, which causes small interface delays. The garbage collector, which appeared in Android 2.3, works better, but you still need to avoid unnecessary work. So do not create objects that you do not need ... More precisely, you should not create temporary objects if this is not necessary. Fewer objects, less assembly, which has a positive effect on usability.
Still not convinced. Let's ask the Garbage Collection Engineer . Which writes collectors. And earns his bread by this. In short, this is the guy who has to know all this by work .
However, with the advent of WP7, device capabilities in terms of CPU and memory performance have increased dramatically. There were games and applications on Silverlight, occupying 100 MB of memory each. As the available memory increases, the number of objects has grown exponentially . According to the scheme (described above), the garbage collector must bypass each object and all its links in order to mark them (mark) and later to clean (sweep). So the time spent on garbage collection has also increased significantly and has become dependent on the size of the “reference network” of the application. This has led to very long pauses in cases of large XNA games and SL applications, which leads to their long loading (since the assembly is working at this time) and jerking during the game / animation.
Still not convinced? Chrome has a test that measures the performance of garbage collection. Let's see how he copes ...

We see a considerable number of stops spent on garbage collection. Yes, this is a stress test, but still. Are you really ready to wait 1 second when rendering a frame? You are crazy.
LISTEN, QUOTE TOO MUCH, CAN'T ALL THEM READ THEM. LET'S ALREADY CONCLUSION.
Here is the conclusion: on mobile devices, memory management is not easy . iOS has developed a culture of manual control of most things, with the compiler doing simple things. Android promotes improved garbage collection, which they themselves are trying hard not to use. In any case, when writing applications for mobile devices it is necessary to break the head over memory management. It is simply impossible to avoid.
When JavaScript or Ruby or Python programmers hear about garbage collection, they think it is garbage collection as a magic wand. They think "garbage collection gives me the opportunity not to think about memory management." But on mobile devices there is no such “magic wand”. , — , . «-» , — 10 , .
JavaScript , . :
- ? — .
ECMA « » (allocation), «» , «» (host-defined).
ECMA 6 , ( ):
, … , () , .
, : , , , . . , :
, , , . , , .
-: JavaScript ( ) , , , . , , , . : iOS , . , , iOS , . , . JavaScript . , , . , SunSpider , CPU, , JavaScript «--», .
, , - , , , . . JavaScript , .
?
— «, JavaScript . . -, , JavaScript. , - ?»
, , . , , — RubyMotion .
, Ruby. , — ( ?). , ARC. - :
: , RM-3 ( : RubyMotion , 11 2013 ) - , RubyMotion.
Ben Sheldon :
. , ( SIGSEGV SIGBUS), 10-20% .
, :
RM-3 Laurent, Watson. Watson , RM-3 — , Laurent , , . , .
, :
, , , , . , . ( , ). : instance_eval. .
RubyMotion — . . , 2 200 . , . .
: Ruby , , . , . , « , ( ) ».
, JavaScript, — . , .
Addition. Rust:
Rust, (zero-overhead memory safety). GC- "@-" ( "@ T" T) , , . , , ( ). , , , JavaScript.
, ASM.JS?
ams.js , JavaScript, . , «» API, . , « ».
Mozilla, , . . , Google: Dart PNaCl. , V8 . Apple, WebKit . IE? .
, , JavaScript . — JavaScript. , . C/C++ . , .
?
«X » «X » , . , «» , . , , , .
— , iPhone 4S Nitro IE8, . . JS , - , . , .
— x86 C/C++ , - iPhone 4S C , 50 , . ARM 5 — JavaScript. -JavaScript , .
— Java, Ruby, Python, C# , - iPhone 4S . , , ( ARM) , 35 , . , 213 . , . , — , .
:
* 2013 JavaScript , .:
— 5 ;
— IE8;
— , x86 C/C++, 50 ;
— , Java/Ruby/Python/C# 10 , 35 ;
* — . , ;
* , API, ;
* . , ;
* , — — ;
* JavaScript , ;
* , , ;
* asm.js, , , C\C++, - JS.
, , , ( , ) , « » « , , ». .
, - : , , , . « - ». — Facebook HTML5 .
, - . - .
Source: https://habr.com/ru/post/188580/
All Articles