Selection of mnemonic quotes for car and phone numbers
Sometimes it is difficult to remember a numeric or alphanumeric sequence, but if using a simple rule, a line of a poem learned in childhood can be converted to this number - everything will become easier. In this article, the Monte Carlo methods compare the results of the selection of such passages using two different methods of encoding numbers.
Let me give an example: If you encode digits in consonant letters, then each word or sentence corresponds to an integer. Usually choose the following encoding method 1-p, 2-d, 3-m, 4-h, 5-n, 6-sh, 7-s, 8-b, 9th (because 9 is “a lot”). Then the words “good my friend” correspond to the number 219513. But this is somewhat inconvenient, because without special training it is impossible to quickly throw out unnecessary letters, however, “good my friend” is rather difficult to forget, which will always allow you in a calm atmosphere to remember the number 219513. And this is very tempting, since the number itself is very abstract and can easily be confused with other similar abstract numbers.
There is quite a lot of information on mnemonics, here I tried not to reinvent the wheel, but to use the text selection features, which are quite difficult to use without the help of a computer system.
Just in case, the definition from Wikipedia: Mnemonic (Greek: the art of memorization), mnemonics - a set of special techniques and methods that facilitate the memorization of the necessary information and increase the amount of memory through the formation of associations (links). Replacing abstract objects and facts with concepts and representations that have a visual, audio or kinesthetic presentation, linking objects with information already available in different types of memory to simplify memorization.
')
In this case, the comparison of the abstract set of numbers of a text passage fills it with images and allows you to simplify its memorization. As already mentioned, the idea is to pick this text automatically. These are all known things, of course, I don’t pretend to have invented them, I recommend reading those textbooks to those who are interested in mnemonics themselves [1].
The initial idea was to try to pick up a quote from the poetic part of the school curriculum that would correspond to a given car number, that is, a random letter-tri_cy-two-letter sequence (the usual number without a region code). It was assumed that the first letter gives rise to the first word, each of the three digits is encoded by a consonant, each of which also gives rise to the word and the last two letters are two more words. Moreover, the Russian car number cannot contain any letters, only 12 of them are used: a, v, s, e, n, t, m, o, k, p, y, x. Several major poems were taken: Eugene Onegin, Poltava, Ruslan and Lyudmila, Romeo and Juliet + Krylov's fables. In the process of analysis, 1000 random numbers are generated, for which a quote from these works is selected.
The following script was written:
If a little comment on the code, then all incoming words are added to the queue, which grows no more than the length of the selected sequence. The length of the maximum match is memorized. Thus, it turns out the maximum number of letters from the beginning, which can be encoded with the help of some text.
The results are as follows:
We can say that these results did not please me, it turns out that only for two numbers out of 1000 it turned out to pick up a quote. Let's look at these two quotes: m052rk - “mine. They are a partisan soul Being jealous of ”; 817 - “From the inflamed Ruslan They suddenly hid among”. Some logic in these phrases is certainly present, but incompleteness and fragments makes their memorization not very easy. Nevertheless, the tests allowed to say that even on the basis of these texts in most cases it turns out to generate a sequence for three letters.
Of course, I became interested: what happens when the texts get bigger? Perhaps there is a greater number of fragments from which you can already choose. For the next test, I chose Moshkov from the library: two biblical testaments in synodal translation, all major Baudelaire poems, all Dostoevsky’s novels, “The Hobbit, or There and Back,” all Pushkin’s novels in verse, all of Shakespeare, all Tolstoy’s novels. The following results were obtained:
There were quite a few quotations themselves, so as not to bore the reader, I will not give them all, just to mention that their character remained the same, some incompletely mysterious: in 488th - “That's what, Vanya, believe one thing: Maslovoev”, t380 tm - “three thousand, he cried, three thousand ”, m081 -“ I enjoy the slavery of you. There is". Having read them all, one visits the thought of some divinations, which are arranged by books (when they open a random page, read a random line and try to somehow interpret it within their own lives). But I did not set such goals.
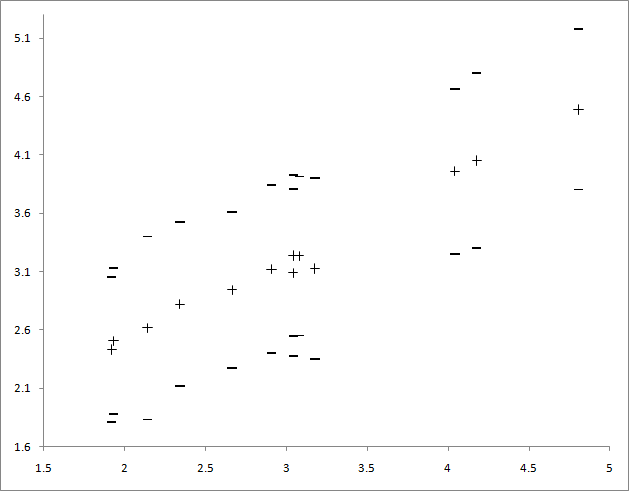
Graph of the average of the decimal logarithm of the volume (for Y - the average, plus or minus the standard deviation, and for X - the logarithm of the volume of the text used)
In principle, this type of dependence could be guessed, here only two volumes of the Bible are a little knocked out, and otherwise the average grows in proportion to the logarithm of the volume.
The first thing that comes to mind is that the way of coding leaves too much text out of consideration, that is, only 10 letters are used for numbers and 12 for letters, the rest of the words only break the chains. Of course, you can think of other encoding methods that use all the letters, or at least only consonants. These methods are described in the literature, but my idea was to make an easy-to-use tool, so that the user would not puzzle over how the phrase corresponds to this number, which letters to throw out, and which ones to take into account, otherwise apply coding to the first significant letter, it gives an unambiguity, but not convenient for a person. I got the idea to encode numbers by the number of letters in a word. With this coding, the problem of representing zero arises, but for now we will not stop there. In order to compare, I conducted a series of tests on the same set and according to the same rules (the code is almost the same, for this reason the listing would be one repetition):
We can say that the situation is much better, only immediately the same number 96 in the column “1” is alarming, here numbers are counted, for which the word for the first letter was found, but not for the first digit. These are naturally numbers starting with zero, about 100 such numbers are still in columns 2 and 3, as you can see, there are no more than 85. An example of the resulting quotation: v325nm - “you: I would be glad ... I can’t really.” Breaking in the case of verses can be compensated by quoting from the beginning of the line, the user will need to additionally remember where the number begins in the poem, for example, the quoted quotation should be issued as: “I swear to you: I would be happy ... I can’t right.” Or even with the previous line: “Ah, gracious knight, I swear to you: I would be glad ... right I can’t.” But already the beginning of the phrase ceases to be obvious. If you memorize the beginning of a phrase, then you can also remember the position of the zeros separately. Perhaps someone seems such an idea of mockery, but I think it is applicable at least.
The application of this idea gives the following results:
From these data, we can assume that for a random number with a probability of 22%, you can pick up the appropriate quotation from Dostoevsky, not bad. Quotes of course turn out to be very significant, as in the past case: v725 vr - “cheerfully watches our cheerful work”, m 582 - “my words seemed to touch her, she”, m 385 ns - “between that miraculously unusual resemblance”, k514nt - “The bloody battle and the day came the crowd”.
And what if it is generated not for car numbers, but for phone numbers? No sooner said than done:
These results suggest that for a six-digit random number with a probability of almost 40% there is a corresponding quotation from the work “Eugene Onegin”, and these are poems that are much more pleasant to memorize (not for everyone most likely, but for most people, I hope ).
What other possibilities remained behind the scenes: the generation of texts, namely the generation of corresponding words or sentences of a certain structure (with the required number of letters or something else), in principle, this has already been done for a long time without computers. The textbook indicated in the literature offers for each number from 0 to 1000 some word that has already been chosen by the author, but, unfortunately, this method does not allow to memorize large numbers, since images cannot be joined, this, according to the author, leads to erasing them. It is understandable, everything begins to accumulate, and so on. For example, a simple way: you can encode the numbers by common associations - 3 (from 03) - a doctor, 7 - an ax (because of the form), and for example, 5 - Friday. In this case, picking up three images for each digit (for each position) all three-digit numbers can be encoded with very bright stories like “375 - the doctor was hacked to death on Friday”, but only a very small number of numbers can be remembered, because everything will get in the way, make additional parallels to remember exactly when they killed the doctor this time.
The generation algorithm for word lengths is implemented in an application that recognizes car numbers on mobile devices and is a non-commercial development just for fun. In addition, such a selection is carried out on the website YaZapomnil [2].
It seemed to me quite interesting that the diversity of texts with respect to such strange metrics as a sequence of numbers of letters or a sequence of first letters of words increases with increasing text size. Moreover, the results are pretty good on the line. When you increase the text, the possibility of choosing between fragments increases, it is possible to improve their quality.
At the moment, I think about a source that would contain a large number of beautiful texts, as well as a way of comparison, which would be obvious to a person and would allow to select more quotes.
I would be glad if the idea seems interesting.
Let me give an example: If you encode digits in consonant letters, then each word or sentence corresponds to an integer. Usually choose the following encoding method 1-p, 2-d, 3-m, 4-h, 5-n, 6-sh, 7-s, 8-b, 9th (because 9 is “a lot”). Then the words “good my friend” correspond to the number 219513. But this is somewhat inconvenient, because without special training it is impossible to quickly throw out unnecessary letters, however, “good my friend” is rather difficult to forget, which will always allow you in a calm atmosphere to remember the number 219513. And this is very tempting, since the number itself is very abstract and can easily be confused with other similar abstract numbers.
There is quite a lot of information on mnemonics, here I tried not to reinvent the wheel, but to use the text selection features, which are quite difficult to use without the help of a computer system.
Just in case, the definition from Wikipedia: Mnemonic (Greek: the art of memorization), mnemonics - a set of special techniques and methods that facilitate the memorization of the necessary information and increase the amount of memory through the formation of associations (links). Replacing abstract objects and facts with concepts and representations that have a visual, audio or kinesthetic presentation, linking objects with information already available in different types of memory to simplify memorization.
')
In this case, the comparison of the abstract set of numbers of a text passage fills it with images and allows you to simplify its memorization. As already mentioned, the idea is to pick this text automatically. These are all known things, of course, I don’t pretend to have invented them, I recommend reading those textbooks to those who are interested in mnemonics themselves [1].
First letter coding
The initial idea was to try to pick up a quote from the poetic part of the school curriculum that would correspond to a given car number, that is, a random letter-tri_cy-two-letter sequence (the usual number without a region code). It was assumed that the first letter gives rise to the first word, each of the three digits is encoded by a consonant, each of which also gives rise to the word and the last two letters are two more words. Moreover, the Russian car number cannot contain any letters, only 12 of them are used: a, v, s, e, n, t, m, o, k, p, y, x. Several major poems were taken: Eugene Onegin, Poltava, Ruslan and Lyudmila, Romeo and Juliet + Krylov's fables. In the process of analysis, 1000 random numbers are generated, for which a quote from these works is selected.
The following script was written:
#!/usr/bin/php <?php $path="school/"; $letters = array("", "", "", "", "", "", "", "", "", "", "", ""); $numbers = array("", "", "", "", "", "", "", "", "", ""); // ( array_rand , , ) function rn($a) { return $a[rand(0, count($a)-1)]; } // function getmax($handle, $required) { $result=array(); $max = 0; $queue = array(); fseek($handle, 0); while (($buffer = fgets($handle, 4096)) !== false) { $words=explode(" ", $buffer); for ($j=0;$j<count($words); $j++) { // $w = mb_strtolower(trim($words[$j], " \t.,\n\r0123456789:-!;?"), "UTF-8"); if (!$w) continue; $queue[]=$w; $avail = min(count($required), count($queue)); $match = $avail; for ($k=0;$k<$avail;$k++) { if (mb_strpos($queue[$k], $required[$k], 0, "UTF-8")!==0) { $match = $k; break; } } if ($max<$match) $max=$match; if ($match===count($required)) { $result[]=array_splice($queue, 0, $match); return array($max, $result); } if (count($queue)>=count($required)) array_shift($queue); } } return array($max, $result); } $plates = array(); for ($i=0;$i<1000;$i++) $plates[]=array(rn($letters), rn($numbers), rn($numbers), rn($numbers), rn($letters), rn($letters)); $files=scandir($path); for ($i=0;$i<count($files);$i++) { if (is_dir($path.$files[$i])) continue; $handle = @fopen($path.$files[$i], "r"); if ($handle) { $cnt=array(0,0,0,0,0,0,0); $max = 0; $avg = 0; $best = array(); for ($j=0;$j<count($plates);$j++) { list($c, $seq) = getmax($handle, $plates[$j]); if (($max && $max<$c) || !$max) { $max = $c; $best=array(implode("", $plates[$j])=>$seq);} else if ($max===$c) $best[implode("", $plates[$j])]=$seq; $cnt[$c] += 1; $avg += $c; } $avg/=count($plates); print $files[$i]."\t".$avg; for ($j=0;$j<count($cnt);$j++) print "\t".$cnt[$j]; print "\n"; print_r($best); fclose($handle); } } If a little comment on the code, then all incoming words are added to the queue, which grows no more than the length of the selected sequence. The length of the maximum match is memorized. Thus, it turns out the maximum number of letters from the beginning, which can be encoded with the help of some text.
The results are as follows:
| Title | The average | 0 | one | 2 | 3 | four | five | 6 | Volume |
| Krylov's fables | 2.434 | 0 | 35 | 530 | 403 | thirty | 2 | 0 | 83Kb |
| Eugene Onegin | 3.237 | 0 | 0 | 120 | 549 | 306 | 24 | one | 1.1Mb |
| Poltava | 2.507 | 0 | 17 | 510 | 424 | 47 | 2 | 0 | 85KB |
| Romeo and Juliet | 2.821 | 0 | 36 | 239 | 598 | 122 | five | 0 | 219Kb |
| Ruslan and Ludmila | 2.617 | 0 | 68 | 359 | 469 | 97 | 6 | one | 138Kb |
We can say that these results did not please me, it turns out that only for two numbers out of 1000 it turned out to pick up a quote. Let's look at these two quotes: m052rk - “mine. They are a partisan soul Being jealous of ”; 817 - “From the inflamed Ruslan They suddenly hid among”. Some logic in these phrases is certainly present, but incompleteness and fragments makes their memorization not very easy. Nevertheless, the tests allowed to say that even on the basis of these texts in most cases it turns out to generate a sequence for three letters.
Of course, I became interested: what happens when the texts get bigger? Perhaps there is a greater number of fragments from which you can already choose. For the next test, I chose Moshkov from the library: two biblical testaments in synodal translation, all major Baudelaire poems, all Dostoevsky’s novels, “The Hobbit, or There and Back,” all Pushkin’s novels in verse, all of Shakespeare, all Tolstoy’s novels. The following results were obtained:
| Title | The average | 0 | one | 2 | 3 | four | five | 6 | Volume |
| Old Testament | 3.09 | 0 | 0 | 188 | 557 | 235 | 17 | 3 | 1.1Mb |
| New Testament | 3.126 | 0 | 13 | 180 | 498 | 289 | 17 | 3 | 1.5Mb |
| Dostoevsky | 4.053 | 0 | 0 | ten | 206 | 526 | 237 | 21 | 15MB |
| Tolkien | 3.12 | 0 | ten | 148 | 581 | 234 | 27 | 0 | 807Kb |
| Pushkin | 3.234 | 0 | 0 | 114 | 565 | 295 | 25 | one | 1.2Mb |
| Baudelaire | 2.943 | 0 | four | 231 | 594 | 160 | eleven | 0 | 461Kb |
| Shakespeare | 4.489 | 0 | 0 | 0 | 49 | 474 | 416 | 61 | 64MB |
| Tolstoy | 3.96 | 0 | 0 | eight | 236 | 555 | 190 | eleven | 11MB |
There were quite a few quotations themselves, so as not to bore the reader, I will not give them all, just to mention that their character remained the same, some incompletely mysterious: in 488th - “That's what, Vanya, believe one thing: Maslovoev”, t380 tm - “three thousand, he cried, three thousand ”, m081 -“ I enjoy the slavery of you. There is". Having read them all, one visits the thought of some divinations, which are arranged by books (when they open a random page, read a random line and try to somehow interpret it within their own lives). But I did not set such goals.
Graph of the average of the decimal logarithm of the volume (for Y - the average, plus or minus the standard deviation, and for X - the logarithm of the volume of the text used)
In principle, this type of dependence could be guessed, here only two volumes of the Bible are a little knocked out, and otherwise the average grows in proportion to the logarithm of the volume.
Length coding
The first thing that comes to mind is that the way of coding leaves too much text out of consideration, that is, only 10 letters are used for numbers and 12 for letters, the rest of the words only break the chains. Of course, you can think of other encoding methods that use all the letters, or at least only consonants. These methods are described in the literature, but my idea was to make an easy-to-use tool, so that the user would not puzzle over how the phrase corresponds to this number, which letters to throw out, and which ones to take into account, otherwise apply coding to the first significant letter, it gives an unambiguity, but not convenient for a person. I got the idea to encode numbers by the number of letters in a word. With this coding, the problem of representing zero arises, but for now we will not stop there. In order to compare, I conducted a series of tests on the same set and according to the same rules (the code is almost the same, for this reason the listing would be one repetition):
| Title | The average | 0 | one | 2 | 3 | four | five | 6 | Volume |
| Krylov's fables | 2.831 | 0 | 96 | 203 | 490 | 197 | 13 | one | 83Kb |
| Onegin | 3.497 | 0 | 96 | 85 | 166 | 536 | 113 | four | 1.1Mb |
| Poltava | 2.808 | 0 | 96 | 231 | 459 | 199 | 13 | 2 | 85KB |
| Romeo and Juliet | 3.149 | 0 | 96 | 116 | 377 | 371 | 34 | 6 | 219Kb |
| Ruslan and Ludmila | 2.94 | 0 | 96 | 178 | 443 | 258 | 23 | 2 | 138Kb |
We can say that the situation is much better, only immediately the same number 96 in the column “1” is alarming, here numbers are counted, for which the word for the first letter was found, but not for the first digit. These are naturally numbers starting with zero, about 100 such numbers are still in columns 2 and 3, as you can see, there are no more than 85. An example of the resulting quotation: v325nm - “you: I would be glad ... I can’t really.” Breaking in the case of verses can be compensated by quoting from the beginning of the line, the user will need to additionally remember where the number begins in the poem, for example, the quoted quotation should be issued as: “I swear to you: I would be happy ... I can’t right.” Or even with the previous line: “Ah, gracious knight, I swear to you: I would be glad ... right I can’t.” But already the beginning of the phrase ceases to be obvious. If you memorize the beginning of a phrase, then you can also remember the position of the zeros separately. Perhaps someone seems such an idea of mockery, but I think it is applicable at least.
The application of this idea gives the following results:
| Title | The average | 0 | one | 2 | 3 | four | five | 6 | Volume |
| Krylov's fables | 3.444 | 0 | 0 | 114 | 426 | 367 | 88 | five | 83Kb |
| Onegin | 4.26 | 0 | 0 | 2 | 93 | 596 | 261 | 48 | 1.1Mb |
| Poltava | 3.413 | 0 | 0 | 132 | 414 | 367 | 83 | four | 85KB |
| Romeo and Juliet | 3.791 | 0 | 0 | 39 | 298 | 508 | 143 | 12 | 219Kb |
| Ruslan and Ludmila | 3.611 | 0 | 0 | 83 | 356 | 445 | 99 | 17 | 138Kb |
| Old Testament | 4.189 | 0 | 0 | five | 126 | 585 | 243 | 41 | 1.1Mb |
| New Testament | 4.292 | 0 | 0 | 3 | 83 | 581 | 285 | 48 | 1.5Mb |
| Dostoevsky | 5.019 | 0 | 0 | 0 | 0 | 208 | 565 | 227 | 15MB |
| Tolkien (The Hobbit) | 4.123 | 0 | 0 | 2 | 155 | 587 | 230 | 26 | 807Kb |
| Pushkin | 4.251 | 0 | 0 | 3 | 94 | 593 | 269 | 41 | 1.2Mb |
| Baudelaire | 3.946 | 0 | 0 | 18 | 214 | 591 | 158 | nineteen | 461Kb |
From these data, we can assume that for a random number with a probability of 22%, you can pick up the appropriate quotation from Dostoevsky, not bad. Quotes of course turn out to be very significant, as in the past case: v725 vr - “cheerfully watches our cheerful work”, m 582 - “my words seemed to touch her, she”, m 385 ns - “between that miraculously unusual resemblance”, k514nt - “The bloody battle and the day came the crowd”.
And what if it is generated not for car numbers, but for phone numbers? No sooner said than done:
| Title | The average | one | 2 | 3 | four | five | 6 | 7 |
| Krylov's fables | 4.145 | 0 | 23 | 270 | 387 | 214 | 71 | 35 |
| Onegin | 5.248 | 0 | 0 | 9 | 260 | 347 | 242 | 142 |
| Poltava | 4.131 | 0 | sixteen | 293 | 385 | 193 | 76 | 37 |
| Romeo and Juliet | 4.608 | 0 | 0 | 138 | 374 | 286 | 146 | 56 |
| Ruslan and Ludmila | 4.349 | 0 | eleven | 212 | 381 | 256 | 93 | 47 |
These results suggest that for a six-digit random number with a probability of almost 40% there is a corresponding quotation from the work “Eugene Onegin”, and these are poems that are much more pleasant to memorize (not for everyone most likely, but for most people, I hope ).
other methods
What other possibilities remained behind the scenes: the generation of texts, namely the generation of corresponding words or sentences of a certain structure (with the required number of letters or something else), in principle, this has already been done for a long time without computers. The textbook indicated in the literature offers for each number from 0 to 1000 some word that has already been chosen by the author, but, unfortunately, this method does not allow to memorize large numbers, since images cannot be joined, this, according to the author, leads to erasing them. It is understandable, everything begins to accumulate, and so on. For example, a simple way: you can encode the numbers by common associations - 3 (from 03) - a doctor, 7 - an ax (because of the form), and for example, 5 - Friday. In this case, picking up three images for each digit (for each position) all three-digit numbers can be encoded with very bright stories like “375 - the doctor was hacked to death on Friday”, but only a very small number of numbers can be remembered, because everything will get in the way, make additional parallels to remember exactly when they killed the doctor this time.
Conclusion
The generation algorithm for word lengths is implemented in an application that recognizes car numbers on mobile devices and is a non-commercial development just for fun. In addition, such a selection is carried out on the website YaZapomnil [2].
It seemed to me quite interesting that the diversity of texts with respect to such strange metrics as a sequence of numbers of letters or a sequence of first letters of words increases with increasing text size. Moreover, the results are pretty good on the line. When you increase the text, the possibility of choosing between fragments increases, it is possible to improve their quality.
At the moment, I think about a source that would contain a large number of beautiful texts, as well as a way of comparison, which would be obvious to a person and would allow to select more quotes.
I would be glad if the idea seems interesting.
Links
- Kozarenko V. . Textbook of mnemonics, 2002, electronic publication
- Selection of quotes by the number of yazapomnil.ru/n/
Source: https://habr.com/ru/post/188370/
All Articles