Zipkin from Twitter
 Zipkin is a distributed tracing system that helps us collect data about the execution time of all disparate services on Twitter. It manages the collection and retrieval of data through the services of Collector and Query. We designed the Zipkin along the lines of Google Dapper . Subscribe to
Zipkin is a distributed tracing system that helps us collect data about the execution time of all disparate services on Twitter. It manages the collection and retrieval of data through the services of Collector and Query. We designed the Zipkin along the lines of Google Dapper . Subscribe to @ZipkinProject and follow the events.And why this distributed trace?
Collecting traces helps developers gain more insight into how certain queries are executed in a distributed system. Let's say we have problems with user requests, say, exceeding the timeout. We can view traces of requests that have fallen off and show them in the web interface. We can quickly find a service guilty for an unexpected increase in response time. If the service has been thoroughly annotated, we will also be able to find exactly where in the service the problem occurred.
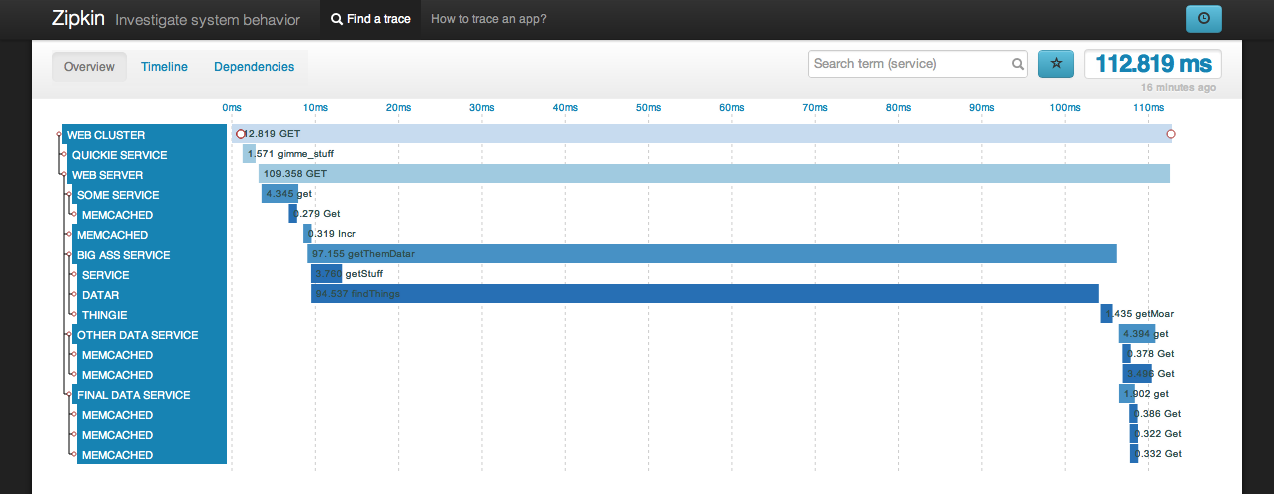
Architecture
These components make up a complete trace system.
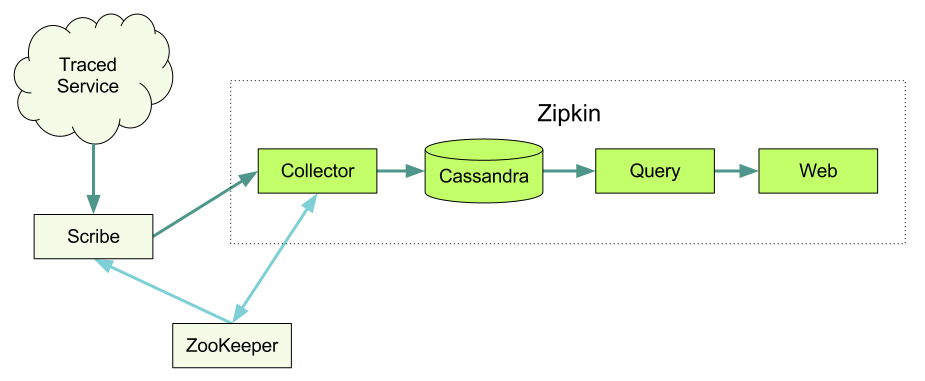
')
Tool libraries
Tracing information is collected at each node using tool libraries that direct it to the Zipkin node. When a host makes a request to another service, it passes some trace identifiers along with the request, so you can later put this data together.
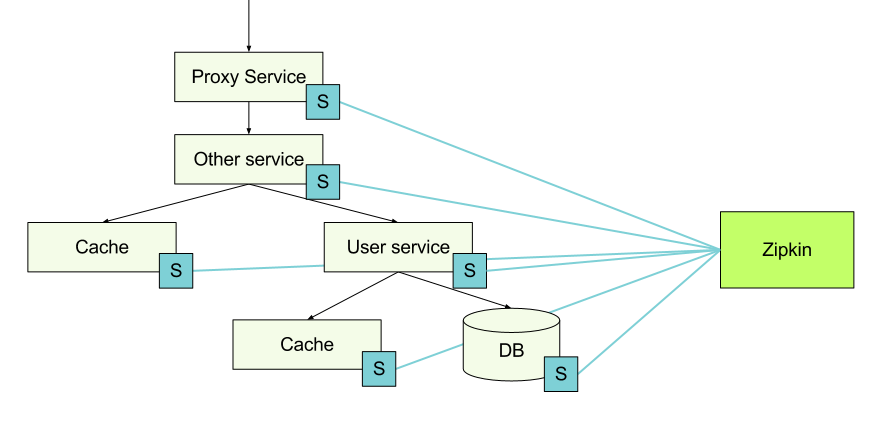
Finagle
Finagle is an asynchronous network stack for JVM that can be used to create asynchronous clients and remote procedure call (RPC) servers in Java, Scala, or any other language that uses the JVM.
Finagle is actively used inside Twitter, and therefore became an obvious starting point for tracing support. So far we have a client / server that supports Thrift and HTTP, as well as a client that only supports Memcache and Redis.
To configure the Finagle server in Scala, simply follow these steps. Adding a trace is simply adding a dependency on finagle-zipkin and calling the
tracer in ServerBuilder . ServerBuilder() .codec(ThriftServerFramedCodec()) .bindTo(serverAddr) .name("servicename") .tracer(ZipkinTracer.mk()) .build(new SomeService.FinagledService(queryService, new TBinaryProtocol.Factory())) Configuring tracing for clients is similar. After you set the Zipkin tracer as shown above, a small sample of your requests will be traced automatically. We will record when the request started, when it ended, as well as the services and hosts participating in the request.
In case you want to record additional information, you can add a custom note to the code.
Trace.record("starting that extremely expensive computation"); In the example above, a note in the form of a string will be attached to the point in time when it was executed. You can also add a note by key value. It looks like this:
Trace.recordBinary("http.response.code", "500"); Ruby thrift
This is the gem we use to trace requests. In order to embed a trace and generate trace trace identifiers, you can use this gem in RackHandler. See the zipkin-web example where we track the tracers.
To track calls from Ruby code, we rely on Twitter client Ruby Thrift . See below for an example of how to use a client.
client = ThriftClient.new(SomeService::Client, "127.0.0.1:1234") client_id = FinagleThrift::ClientId.new(:name => "service_example.sample_environment") FinagleThrift.enable_tracing!(client, client_id), "service_name") Querulous
Querulous is the Scala library for interacting with databases. Includes tracking the timings of the query and the execution of SQL.
Cassie
Cassie is a Finagle-based client library for Cassandra. The configuration of the tracer in Cassie almost coincides with that in Finagle, but in the case of Cassie KeyspaceBuilder is used.
cluster.keyspace(keyspace).tracer(ZipkinTracer.mk()); Transport
We use Scribe to transfer all traces from various services to Zipkin and Hadoop. Scribe was developed on Facebook, and it consists of a daemon that can be run on every server on your system. It scans the log messages and sends them to the correct service receiver, depending on the category.
Demon Zipkin Sollector
As soon as the trace data arrives at the Collector daemon, we check their correctness, save and build the index for the search.
Storage
We use Cassandra for data storage. It is scalable, has a flexible scheme and is heavily used on Twitter. We tried to make this component modular, so it should not be difficult to replace it with something else.
Request daemon
After the data is recorded and indexed, we need a convenient way to retrieve it. This is where Query daemon comes to the rescue, providing users with a simple Thrift API the ability to search and extract traces. See an example Thrift file .
User interface
Most of our users access the data through our developed UI. This is a Rails application that uses D3 to visualize trace data. Please note that the user interface does not have a built-in authorization function.
Modules

Installation
To quickly get up to date, check out the Ubuntu Quickstart and Mac Quickstart manuals . They will help you run Zipkin on a single computer, so you can experiment with it.
A bit about customization.
Cassandra
Zipkin is most often used in conjunction with Cassandra. There is also a plugin for Redis and we would like to see support for other databases.
- Visit the Cassandra website for instructions on how to run the cluster.
- Use an adapted scheme for Zipkin. You can create it with the following
$ cassandra-cli -host localhost -port 9160 -f zipkin-cassandra/src/schema/cassandra-schema.txt:$ cassandra-cli -host localhost -port 9160 -f zipkin-cassandra/src/schema/cassandra-schema.txt$ cassandra-cli -host localhost -port 9160 -f zipkin-cassandra/src/schema/cassandra-schema.txt
ZooKeeper
Zipkin can use ZooKeeper for coordination. This is where we store the reference values and register the servers themselves.
Visit the ZooKeeper website for installation instructions.
Scribe
Scribe is a logging framework that we use on Twitter as a trace data transport. There are several other ways to pass trace data to Zipkin; in particular, if you simply want to try Zipkin, you can skip this step completely and send ZipkinTracer directly to Collector.
To use Scribe with Zipkin, you need to create a network storage, which is specified in the Collector daemon. Setting up storage in Zipkin might look something like this:
<store> category=zipkin type=network remote_host=123.123.123.123 remote_port=9410 use_conn_pool=yes default_max_msg_before_reconnect=50000 allowable_delta_before_reconnect=12500 must_succeed=no </store> If you do not want to hard-sew the IP address of your collector, then there are several options. One is to use internal DNS records for the collectors, so you will have one place where you have to change addresses when adding or removing collectors. In addition, you can use a modified version of Scribe, which collects the addresses of collectors through ZooKeeper. When the collector starts, it registers itself with ZooKeeper, and when it finishes, it is automatically deleted. The modified Scribe receives notifications when changes occur to the collectors. To activate this mode, change the
remote_host in the configuration to zk://zookeeper-hostname:2181/scribe/zipkin or similar.Zipkin Servers
We developed Zipkin with Scala 2.9.1, SBT 0.11.2 and JDK7.
The Ubuntu Quickstart and Mac Quickstart manuals explain how to install and start the Collector and Query services.
Zipkin ui
The UI is a regular Rails 3 application.
- Update your ZooKeeper server configuration. It is used to search for Query daemons.
- Deploy a suitable application server under Rails. The following is also suitable for testing:
$ bundle install && bundle exec rails server
Gem Zipkin-tracer adds tracing to the Rails application via the Rack Handler. Add to config.ru:
use ZipkinTracer::RackHandler run <YOUR_APPLICATION> If the Rails application itself serves static assets, then the trace of these requests will be saved.
Running a task in Hadoop
It is possible to configure Scribe to store data in Hadoop. If you do this, you can create various reports from data that are not easily processed on the fly in Zipkin itself.
We use a library called Scalding to form the tasks for Hadoop from Scala.
- To run a task in Hadoop, first of all you need to build a jar.
$ sbt 'project zipkin-hadoop' compile assembly - Change in scald.rb the name of the node to which you want to copy the jar and run the task.
- Update the jar version in scald.rb, if necessary.
- Now you can run the task using our script scald.rb.
$ ./scald.rb --hdfs com.twitter.zipkin.hadoop.[classname] --date yyyy-mm-ddThh:mm yyyy-mm-ddThh:mm --output [dir]
How to prepare libraries
We have instructed several libraries and protocols on our own, but still hope to get some help in expanding their number. Before we begin, we need to know a few things about how the trace data is structured.
- Annotation - includes some value, time stamp and node address;
- Span - set of Annotation, which correspond to a specific RPC;
- Trace - Span set, which share one root Span.
The above is used when sending trace data to a Zipkin. Some details are described here .
Another important part of tracing is the lightweight header that we use to transfer information between services. The header consists of:
- Trace Id - identifies the trace;
- Span Id - identifiers of individual requests;
- Optional Parent Span Id - added if this request was made within another;
- Sampled (logical field) - tells us whether to keep trace data or not.
Now that we know a little bit about the data types, let's take a look at step by step how the instrumentation works. In the example below, I will describe how HTTP tracing works in Finagle. For other libraries and protocols, actions, of course, may differ, but the general principle is preserved.
Server side
- Check if there are trace headers in the incoming request. If so, we accept the identifiers associated with this request. If not, then we generate a Trace id, Span id and decide whether to save the data or not. See HttpServerTracingFilter for an example.
- If the current request is included in the sample, then we collect information such as the service name, host name, Span name (http get / put for example) and our note directly. We create “server received” notes when we receive a request and “server send” when we have completed processing and are going to send the result. Again you can see an example in HttpServerTracingFilter .
- The generated trace data is passed to the tracer object that was specified in ServerBuilder. This may be, for example, ConsoleTracer, but in our case, ZipkinTracer is used. When ZipkinTracer receives trace data, it groups it by Span Id.
- As soon as ZipkinTracer receives an “end of span” event, such as a “server received” note or a timeout, it sends aggregated data to the Scribe in the form of a Thrift structure. If such an event does not occur, the data will still be transmitted. We are open to adding other data delivery methods, Thrift and Scribe make sense for us, but perhaps JSON and Http will work better for some cases.
Client side
- Find out if we are already part of the trace before executing the query. Maybe this client is used within the server and Trace Id is already assigned. We reuse this Trace id, but create a new Span Id for the new query. We also install the Parent Span Id of the previous Span, if one is available. Some examples here and here .
- Similar to the server version, we have HttpClientTracingFilter , which adds trace headers to the outgoing Http request.
- We also need to create relevant notes, such as “client send” before the request and “client receive” after receiving a response from the server.
- Similar to the server option, the data is transferred to the ZipkinTracer, which sends it to the Zipkin.
Source: https://habr.com/ru/post/187902/
All Articles