Launch Pentaho OLAP server step by step

So, dear habrovchane, I want to submit to your review the instructions, as we had to raise the OLAP-server in our company. Step by step, we will follow the path we have taken, starting with the installation and setup of Pentaho and ending with the preparation of data tables and the publication of the olap-cube on the server. Naturally, a lot of things here can be muddled / inaccurate / non-optimal, but when we needed to raise the server and see if Pentaho could replace our samopisny statistics, we didn’t have that ...
I divided the whole process of raising the OLAP server into 3 parts:
- Pentaho BI Server setup
- preparation of fact tables and measurements
- creating a cube and publishing it on the server
Configure Pentaho BI Server
Install the JDK .
We expose variable environments:
JAVA_HOME=c:\Program Files\Java\jdk1.7.0_15 JRE_HOME=c:\Program Files\Java\jdk1.7.0_15\jre PENTAHO_JAVA_HOME=c:\Program Files\Java\jdk1.7.0_15 Download and unpack the latest version of Pentaho Business Intelligence ( biserver-ce-4.8.0-stable.zip ). I uploaded the contents of the archive (the administration-console and biserver-ce folders) to the c: \ Pentaho folder. So, unpack - unpacked, but the server is not yet configured. We will deal with this now ...
')
Download the MySQL Connector for Java ( mysql-connector-java-5.1.23-bin.jar ). We drop it into the c: \ Pentaho \ biserver-ce \ tomcat \ lib folder.
By default, Pentaho uses the HSQLDB engine, i.e. creates and stores all databases in memory, including the sampled data test database. This is still normal for small tables (such as demo), but for combat data, the engine is usually changed to MySQL or Oracle, for example. We will use MySQL.
Fill in MySQL database hibernate and quartz. Both are used for Pentaho system needs. We download files 1_create_repository_mysql.sql and 2_create_quartz_mysql.sql from here . Import them into MySQL.
Now our MySQL server is configured as a Pentaho repository. We will configure the Pentaho server to use this repository by default. For this we will edit the following xml-ki:
1. \ pentaho-solutions \ system \ applicationContext-spring-security-hibernate.properties
Change driver, url and dialect to com.mysql.jdbc.Driver , jdbc: mysql: // localhost: 3306 / hibernate and org.hibernate.dialect.MySQL5Dialect respectively.
2. \ tomcat \ webapps \ pentaho \ META-INF \ context.xml
Change driverClassName parameters to com.mysql.jdbc.Driver , url parameters to jdbc: mysql: // localhost: 3306 / hibernate and jdbc: mysql: // localhost: 3306 / quartz respectively in 2 sections, change validationQuery parameters to select 1 .
3. \ pentaho-solutions \ system \ hibernate \ hibernate-settings.xml
In the <config-file> parameter, we change hsql.hibernate.cfg.xml to mysql5.hibernate.cfg.xml .
4. \ pentaho-solutions \ system \ simple-jndi \ jdbc.properties
We delete all unnecessary trash except Hibernate and Quartz.
5. We demolish the \ pentaho-solutions \ bi-developers , \ pentaho-solutions \ plugin-samples and \ pentaho-solutions \ steel-wheels folders . This test data, which we need in principle will not.
6. \ tomcat \ webapps \ pentaho \ WEB-INF \ web.xml
We delete or comment on all the servlets of the [BEGIN SAMPLE SERVLETS] and [BEGIN SAMPLE SERVLET MAPPINGS] sections , except for ThemeServlet.
Delete the [BEGIN HSQLDB STARTER] and [BEGIN HSQLDB DATABASES] sections.
Delete the lines:
<filter-mapping> <filter-name>SystemStatusFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> 7. Delete the \ data directory. This directory contains a test database, scripts to run this database and initialize the Pentaho repository.
8. \ pentaho-solutions \ system \ olap \ datasources.xml
Remove directories with the names SteelWheels and SampleData.
9. \ pentaho-solutions \ system \ systemListeners.xml
Delete or comment the line:
<bean id="pooledDataSourceSystemListener" class="org.pentaho.platform.engine.services.connection.datasource.dbcp.PooledDatasourceSystemListener" /> 10. \ tomcat \ webapps \ pentaho \ WEB-INF \ web.xml
We specify our solution-path: c: \ Pentaho \ biserver-ce \ pentaho-solutions .
11. \ system \ sessionStartupActions.xml
Comment out or delete all blocks
...Customize Pentaho web-face
After all manipulations with configs, you can already podzapust something. Go to the folder with our server and run start-pentaho.bat or sh-shnik, who needs what in its operating system. In theory, there should be no ERRORs in the console or tomkata logs anymore.
So, if everything went smoothly, then at
localhost:8080 localhost:8080 login form is displayed: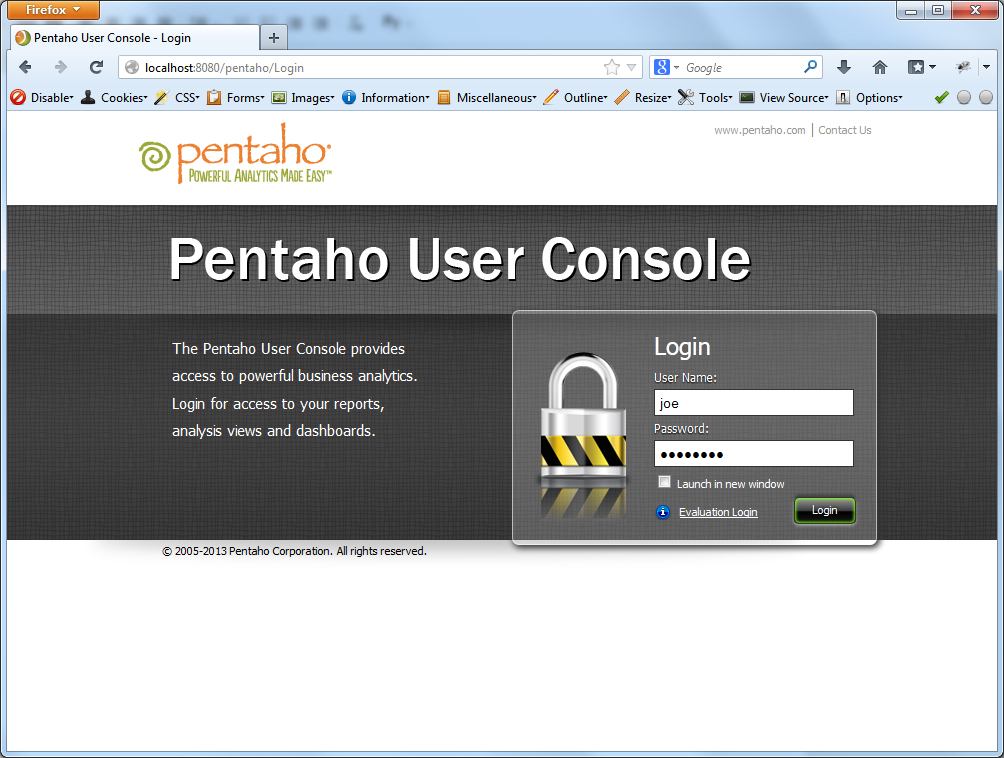
Enter the standard login / password ( joe / password ) and get inside. Now you need to install the olap-client, which will, in fact, display our requests to it. The paid version of Pentaho has its own client, for CE we used the Saiku plugin.
Go to the Pentaho Marketplace point of the top menu, install Saiku Analytics.
Everything is here, it's time to prepare data for analytics.
Preparation of fact tables and measurements
Pentaho is a ROLAP implementation of OLAP technology, i.e. All the data that we will analyze are stored in ordinary relational tables, except perhaps in some way prepared in advance. Therefore, all we need is to create the necessary tables.
I will say a little about the subject area for which we needed statistics. There is a website, there are customers and there are tickets that these customers can write. Also with comments, yes. Our support splits all these tickets according to various topics, projects, countries. And here we needed, for example, to find out how many tickets on the “Delivery” topic came from each project from Germany last month. And all this is divided by admins, i.e. see who is from support and how many such tickets processed, etc. etc.
All such sections technology OLAP and allows for. About OLAP itself I will not tell in detail. We assume that with the concepts of the OLAP-cube, dimensions and measures, the reader is familiar with and in general terms imagines what it is and what it eats with.
Of course, I will not analyze the real data of real customers as an example, but for this purpose I will use my small website with football statistics. There is little practical benefit from this, but as a sample it’s the most.
So, there is a table of players . Let's try to find all sorts of different useful and not very statistics: the number of players in each country, the number of players by role, the number of active players, the number of Russian midfielders aged from 30 to 40 years. Well, something like this ...
So what did I stop at? And, exactly, the preparation of tables. There are several ways to do this: recreate all the tables with your hands and bare SQLs or use the Pentaho Data Integration utility (PDI, also known as Kettle), a component of the Pentaho complex that is responsible for the extraction, transformation and unloading of data (ETL). It allows you to connect to a specific database and with the help of lots of different tools to prepare the tables we need. Download it . We throw the mysql-connector into the lib folder and launch PDI via Spoon.bat .
First, we collect the heart of our statistics - a table of players. Initially, its structure looks something like this:
CREATE TABLE IF NOT EXISTS `player` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` varchar(40) DEFAULT NULL COMMENT '', `patronymic` varchar(40) DEFAULT NULL COMMENT '', `surname` varchar(40) DEFAULT NULL COMMENT '', `full_name` varchar(255) DEFAULT NULL COMMENT ' ', `birth_date` date NOT NULL COMMENT ' ', `death_date` date DEFAULT NULL COMMENT ' ', `main_country_id` int(11) unsigned NOT NULL COMMENT 'ID ', `birthplace` varchar(255) DEFAULT NULL COMMENT ' ', `height` tinyint(3) unsigned DEFAULT NULL COMMENT '', `weight` tinyint(3) unsigned DEFAULT NULL COMMENT '', `status` enum('active','inactive') NOT NULL DEFAULT 'active' COMMENT ' - , ..', `has_career` enum('no','yes') NOT NULL DEFAULT 'no' COMMENT ' ', PRIMARY KEY (`id`), KEY `name` (`name`), KEY `surname` (`surname`), KEY `birth_date` (`birth_date`), KEY `death_date` (`death_date`), KEY `has_stat` (`has_career`), KEY `main_country_id` (`main_country_id`), KEY `status` (`status`), KEY `full_name_country_id` (`full_name_country_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='' AUTO_INCREMENT=1; Some of the fields (name, surname, patronymic, full_name or birthplace, for example) are not needed for statistics. Fields of the Enum type (status, has_career) need to be placed in separate dimension tables, and in the main table you just need to put down the foreign key ID keys.

So let's get started: File> New> Job (Ctrl + Alt + N). The job's workspace opens. Go to the View tab, create a new database connection ( Database connections> New ): drive the server, database, user and password, give the connection some name (I have fbplayers) and save ( c: \ Pentaho \ biserver-ce \ pentaho -solutions \ jobs \ fbplayers.kjb ).
Create a transformation ( File> New> Transformation , Ctrl + N). Save it as prepare_tables.ktr . In the same way as with the job (job), we add a connection to the database for transformation. Is done.
Go to the View tab and expand the Input section. Select the Data Grid tool. It is well suited if you need to render some fields with a small number of possible options in separate related tables. So, pull the Data Grid into the workspace and open it for editing with a double click. We drive in the name of this transformation step ( Player Status ), we begin to set the structure of this table (Meta tab) and the data itself (Data tab). In the structure we have 2 fields:
1. Name - id, Type - Integer, Decimal - 11
2. Name - status, Type - String, Length - 10.
In the Data tab, we drive in 2 lines: 1 - active, 2 - inactive.
Go to the Output section and pull out the Table Output element. Double-click, set the item name as Player Status Dim . The connection should appear in the next line. In the Target Table field, we write the name of the table that will be created in the database to store the status of players: player_status_dim. Set the Truncate Table checkbox. We bind the input and output elements: click on the Player Status and with the Shift button held down, drag the mouse to the Player Status Dim. The link should appear as an arrow connecting these elements.
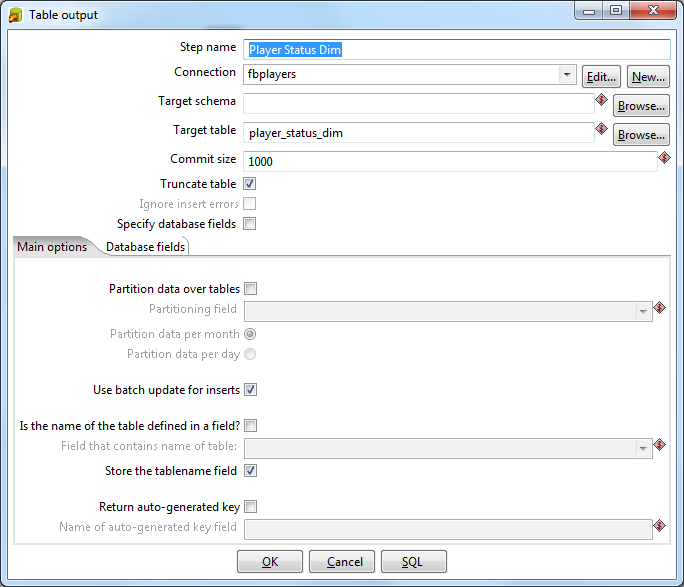
The same thing needs to be turned with a flag for a career ( Player Career ):
1. Name - id, Type - Integer, Decimal - 11
2. Name - has_career, Type - String, Length - 3.
In the Data tab we drive in 2 lines: 1 - no, 2 - yes.
Similarly, we collect the output table Player Career Dim .
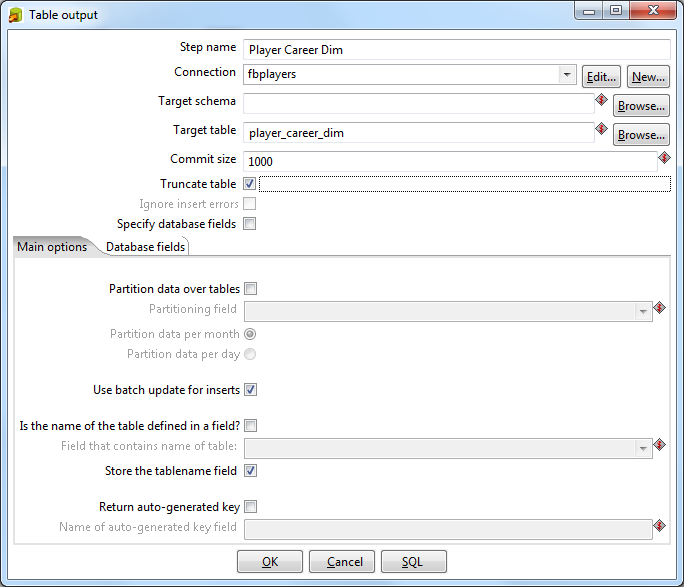
Now we will move the player's birth date to a separate measurement table. By and large, Pentaho allows you to use the date directly in the fact table, initially we did so with the data of our subject area. But there were several problems:
1. if you need to break 2 different fact tables (for example, Players and Trainers) by date of birth, then you need a common dimension for them (Dimension);
2. when dividing the date in the fact table itself into its constituent parts, an extract or year function (month, ...) will be applied to each row of the table to get the year, month, etc. What is not ice.
So, for these reasons, we redesigned our original structure and created a table with all the unique time values, leaving the clock to a minimum. For our test example, there will be no such detail; there will be only years, months and days.
Create a new transformation ( initial_sql ). Do not forget about the connection. From the collection of elements, select Scripting> Execute SQL Script . In it we write date collector:
DROP TABLE IF EXISTS `player_birth_date_dim`; CREATE TABLE IF NOT EXISTS `player_birth_date_dim` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `year` smallint(5) unsigned NOT NULL COMMENT '', `month` tinyint(2) unsigned NOT NULL COMMENT '', `day` tinyint(2) unsigned NOT NULL COMMENT '', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=' ' AUTO_INCREMENT=1 ; INSERT INTO `player_birth_date_dim` (SELECT DISTINCT NULL, YEAR(p.birth_date) as `year`, MONTH(p.birth_date) as `month`, DAY(p.birth_date) as `day` FROM ( SELECT DISTINCT birth_date FROM player ) AS p) 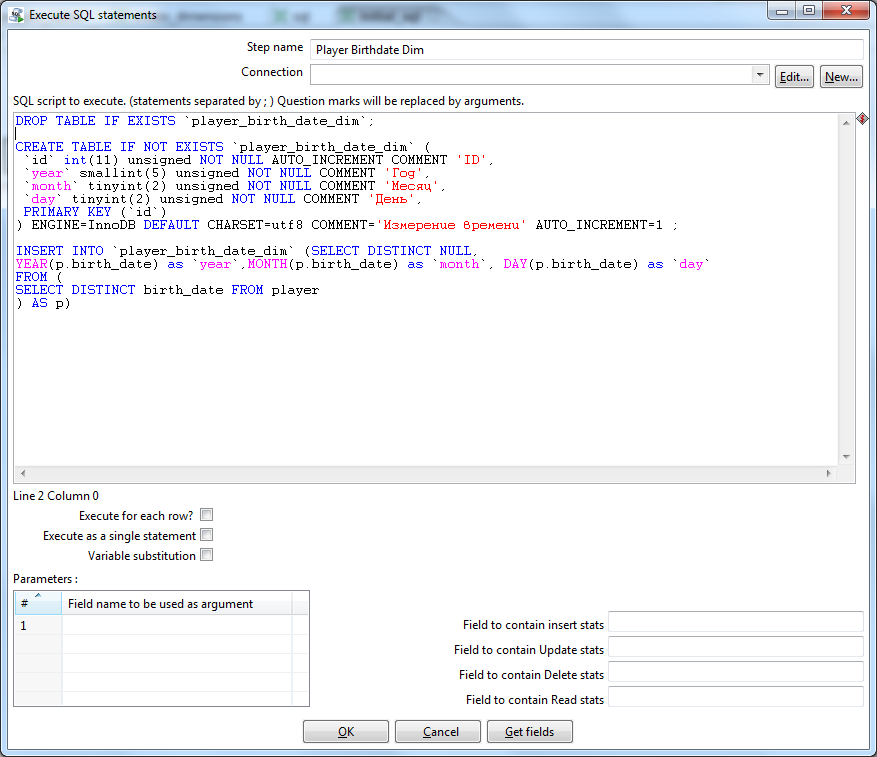
Right there, in this transformation, we create another 2 SQL scripts - to create the Player Career Dim and Player Status Dim tables:
DROP TABLE IF EXISTS player_career_dim; CREATE TABLE IF NOT EXISTS `player_career_dim` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `has_areer` varchar(3) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; 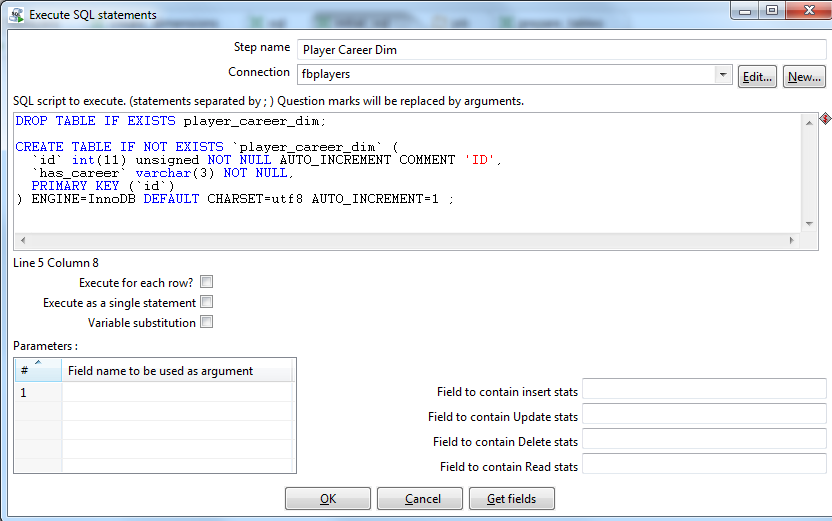
DROP TABLE IF EXISTS player_status_dim; CREATE TABLE IF NOT EXISTS `player_status_dim` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `status` varchar(10) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; 
We proceed to the main part of our mission - the assembly of the fact table. Create a transformation ( player_fact.ktr ). About the connection is not forgotten, right? From the Input tab, throw Table Input, from Output - Table Output, respectively. In the Table Input we write a cool SQL nickname:
SELECT p.id AS player_id, dd.id AS birth_date_id, p.main_country_id, p.height, p.weight, CASE p.status WHEN 'active' THEN 1 WHEN 'inactive' THEN 2 END as status_id, CASE p.has_career WHEN 'no' THEN 1 WHEN 'yes' THEN 2 END as has_career_id FROM player AS `p` INNER JOIN player_birth_date_dim AS dd ON YEAR(p.birth_date) = dd.`year` AND MONTH(p.birth_date) = dd.`month` AND DAY(p.birth_date) = dd.`day` In Table Output, specify the name of the table - player_fact . We link the source and result tables with an arrow.
Again we go to our job. From the General tab, add a new transformation. Open it, give the name Prepare Tables and specify the path to our saved transformation prepare_tables.ktr .
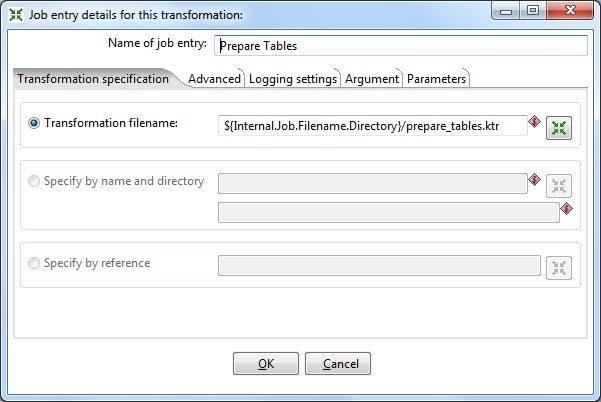
Do the same with the transformations Initial SQL and Player Fact .
We drop the Start button on the form and connect the elements in the following sequence: Start> Initial SQL> Prepare Tables> Load Player Fact .
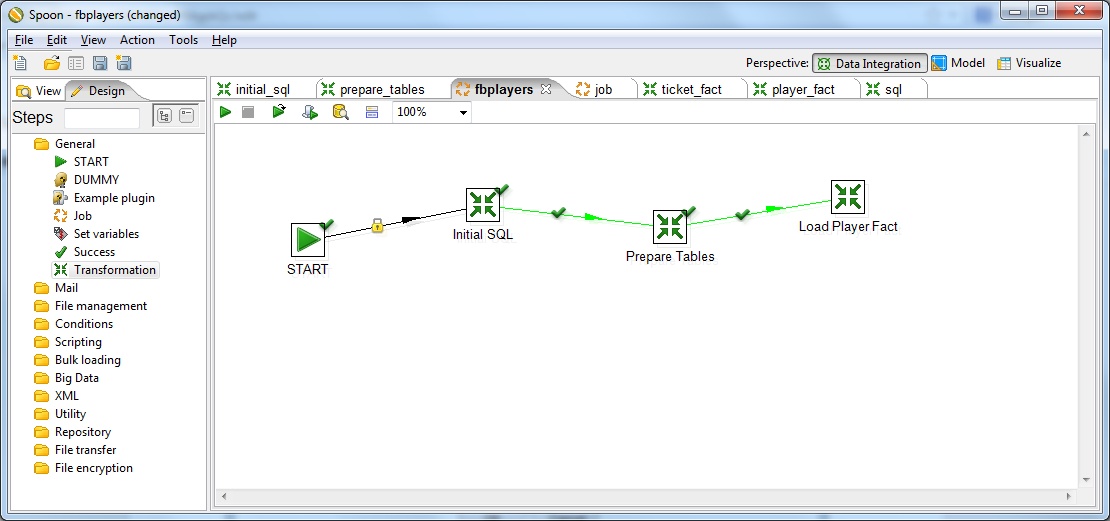
Now you can try to run the task. In the toolbar click the green triangle. If our hands were straight enough, then we will see a green tick near each of our elements. You can log into your server and check that the labels are really created. If something went wrong, the log will show all our sins.
Creating a cube and publishing it on the server
Now that we have the data prepared, let's finally deal with the OLAP. Pentaho has a Schema Workbench utility to create olap cubes. Download, unpack, throw the mysql-connector in the drivers folder, run workbench.bat .
Immediately go to the menu Options> Connection . Enter our parameters for connecting to the database.
Getting Started: File> New> Schema . Immediately save the scheme (I have fbplayers.xml ). Set the name to the schema.
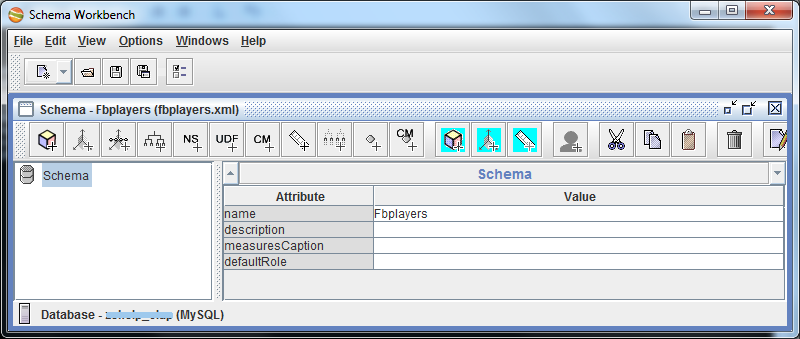
Using the context menu of the scheme, we create a cube. Let's call it the name of the entity, the statistics for which we assume, i.e. Player .
Inside the cube, we specify the table that will be our fact table: player_fact .
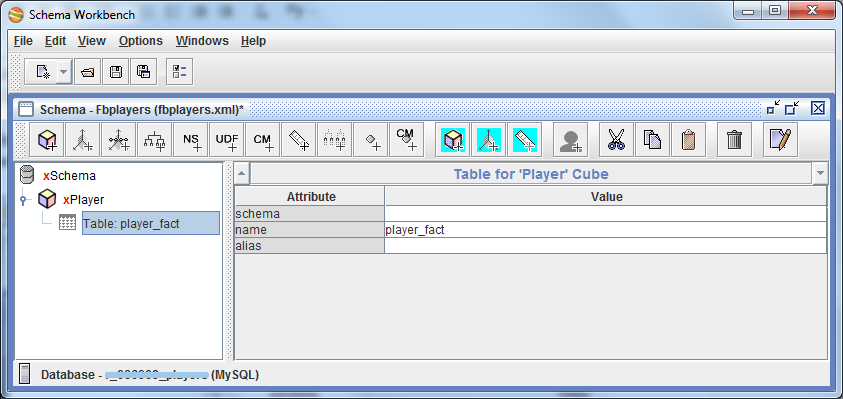
If you select the Player cube, the red line at the bottom of the right pane will tell us that Dimensions should be specified in the cube, i.e. Those parameters, which will be made data slices.
There are 2 ways to define a cube dimension: directly inside it (via Add Dimension ) and inside a schema (Add Dimension for the schema plus Add Dimension Usage at the cube itself). We used the second option in our statistics, since it allows one dimension to be applied to several fact tables at once (to several cubes). We then combined these cubes into a virtual cube, which allowed us to display statistics on several cubes at the same time.
In our test project, we also use the second method, except that we will not create virtual cubes.
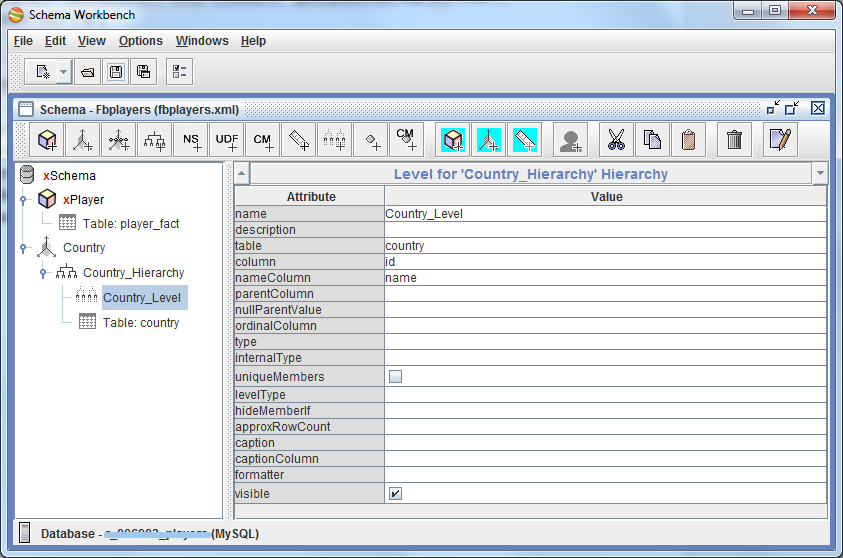
So, add the first dimension (by country). Create a schema dimension, give it the name Country . Inside it there is already 1 hierarchy, we will set the name Country_Hierarchy to it . Add a table to this hierarchy that stores the values of the Country dimension, i.e. country.
This is my usual mysql table with a list of countries of the following structure:
CREATE TABLE IF NOT EXISTS `country` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` varchar(40) NOT NULL COMMENT '', `english_name` varchar(40) NOT NULL COMMENT ' ', `iso_alpha_3` varchar(3) NOT NULL COMMENT ' ISO 3166-1', PRIMARY KEY (`id`), KEY `name` (`name`), KEY `england_name` (`english_name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='' AUTO_INCREMENT=1 ; After that we add 1 level to the hierarchy (Add Level). Let's call it Country_Level and link the fact table with this dimension table: set the table field to country, column to id, nameColumn to name. Those. this means that when comparing the country ID from the fact table country ID from the country table, the country name will be returned as a result (for readability). The remaining fields, in principle, can not be filled.
Now we can return to the Player cube and assign it the newly created dimension (via Add Dimension Usage). We set the name (Country), source is our created Country dimension (it will be the only one in the drop-down list), and the foreignKey field is main_country_id, i.e. This tells Pentaho that when he sees some kind of main_country_id in the fact table, he refers to the dimension table (Country) on the specified column (id) and substitutes the name value in the place of main_country_id. Something like this…

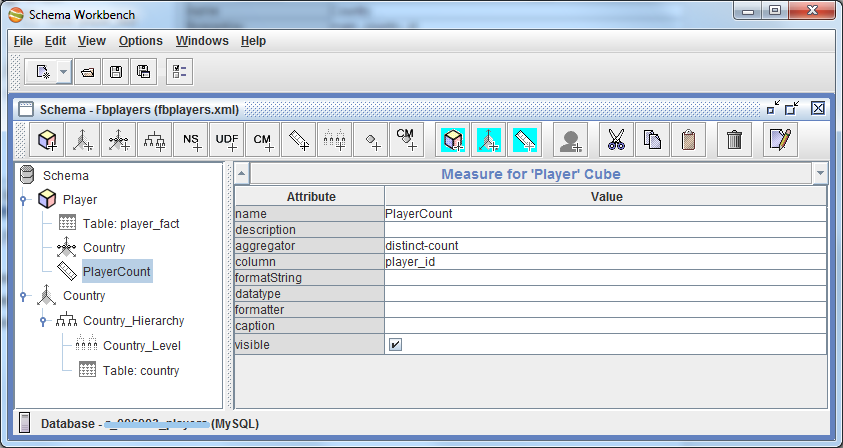
It remains only to specify the cube, that we actually want to aggregate something)) Add Measure to the cube ( Add Measure ). Give it the name PlayerCount, the aggregator - distinct-count and the field by which we aggregate - player_id. Done!
Let's stop on this for a while and check what we have conjured here. Launch Pentaho web:
localhost:8080/pentaho localhost:8080/pentaho (do not forget about start-pentaho.bat). Go to File> Manage> Data Sources . Click the add new source button. Select the type - Database Table (s). The most important thing we need here is to create a new connection (Connection). We set a name (Fbplayers) and we drive in our data for access to a DB. After saving Connection, we’ll click Cancel everywhere, we don’t need anything else.Next, we need to publish the created scheme on the Pentaho: File> Publish server. We set the url:
localhost:8080/pentaho localhost:8080/pentaho and enter the password for publication. This password is set in the file c: \ Pentaho \ biserver-ce \ pentaho-solutions \ system \ publisher_config.xml . Set this password to 123, for example, the user and password are standard - joe / password. If everything is normal, then after the folder selection window should appear, where to save our scheme. Enter the name of the connection that we created in the last step (Fbplayers) in the "Pentaho or JNDI Source" field. Create a schema folder and save the file in it. If everything went well, we should see a joyful window:
Let's go look! Go to the web-muzzle, open Saiku, choose our cube from the drop-down list. We see the appeared dimension Country and measure PlayerCount. We drag Country_Level in the field Rows, PlayerCount - in the Columns. By default, the automatic request button is pressed on the Saiku panel. It is usually worth pressing it before dragging measurements and measures, but this is not critical. If automatic execution is disabled, click the Run button. Rejoice!
But if suddenly instead of beautiful data you saw a message like “EOFException: Can not read response from server. “Expected to read 4 bytes, read 0 bytes before the connection was unexpectedly lost”, don't worry - it happens, just click Run again.
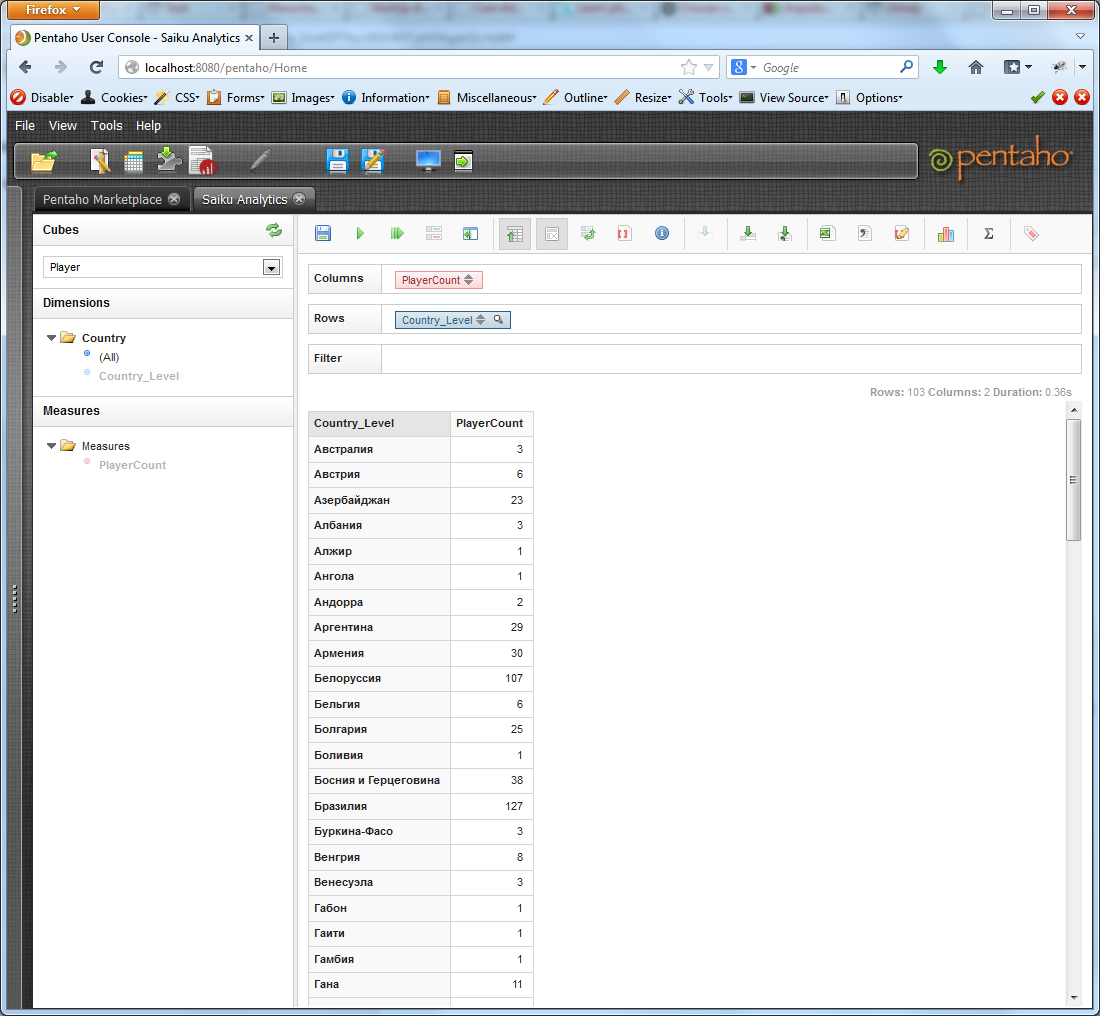
By clicking the arrows on the measure button, we can sort the resulting selection in descending or ascending order.
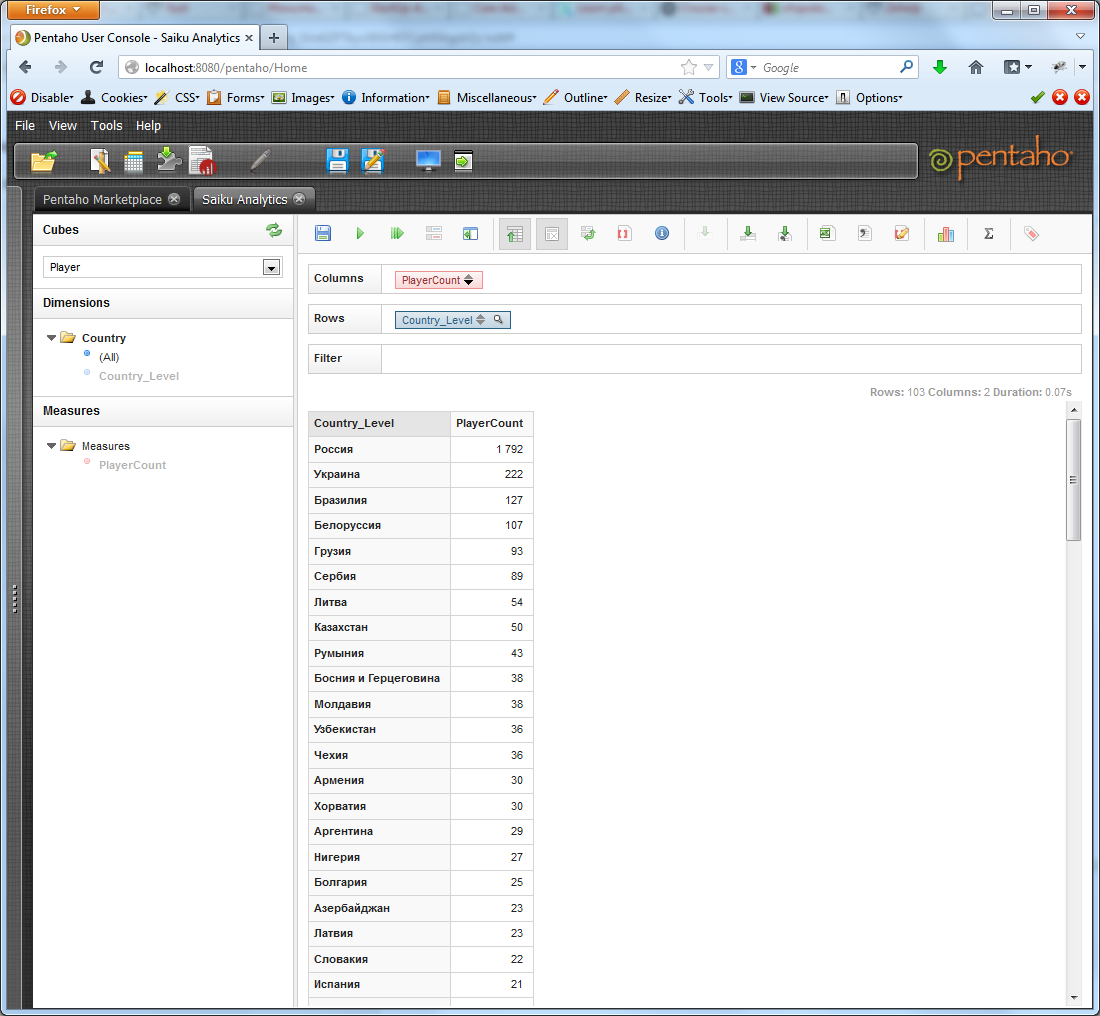
While we have some data, let's see what else is available. It is possible to limit the output data, say, only by countries with the letter A:
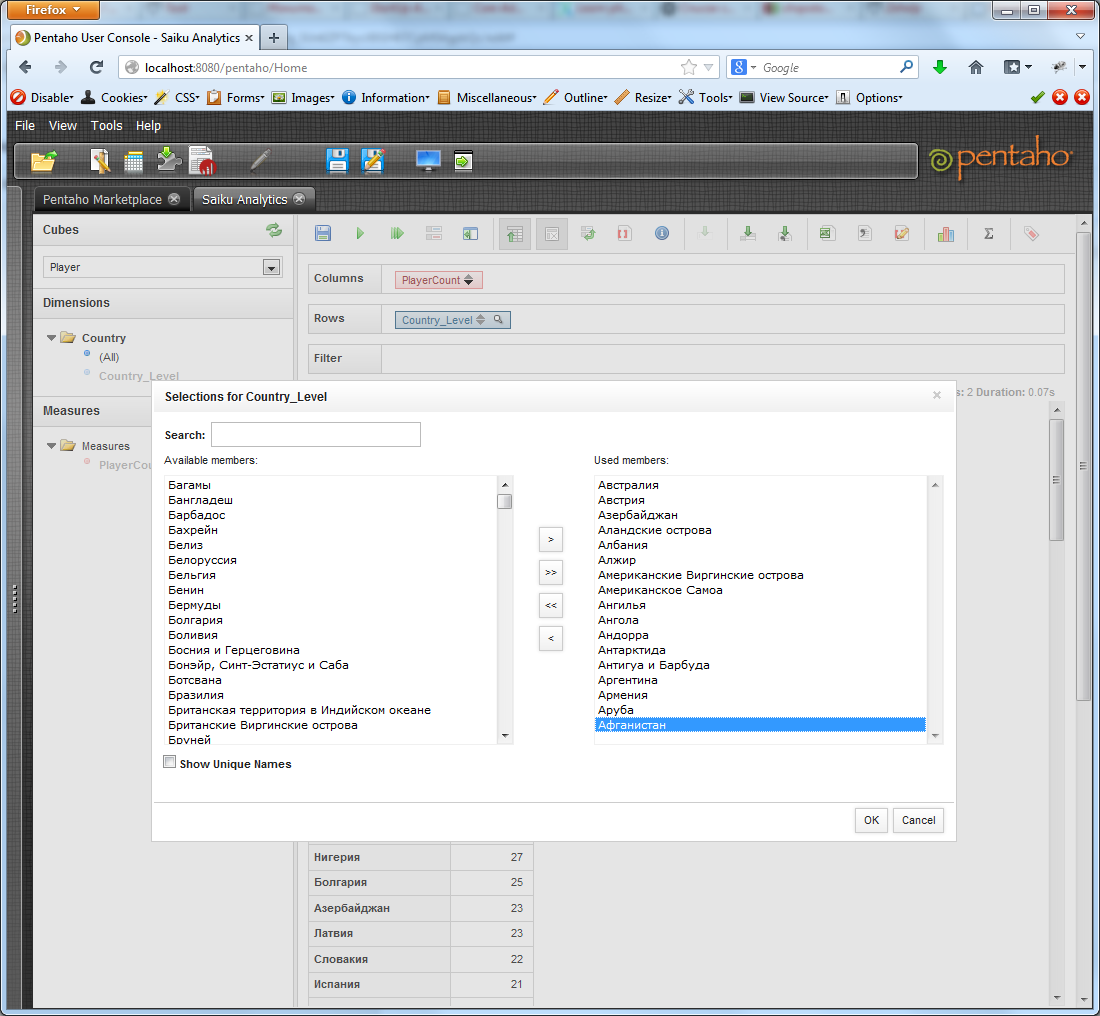
We get:
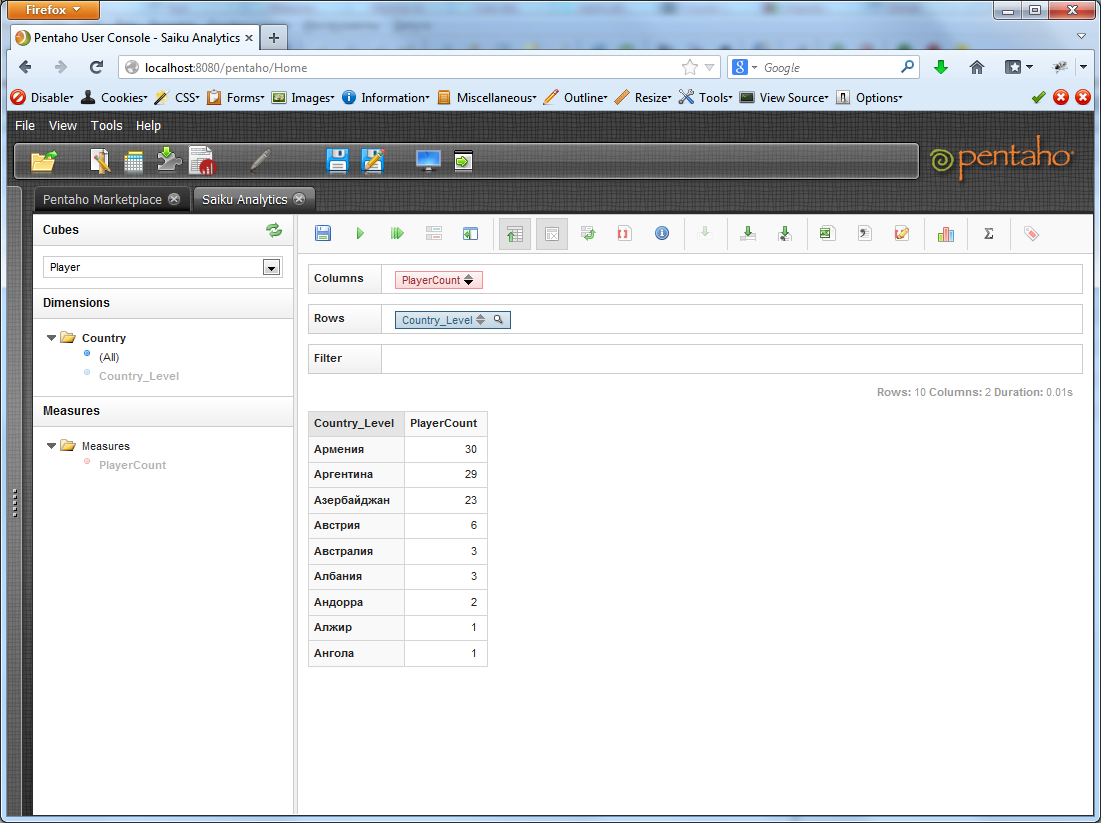
You can see the graphics. This is usually beautiful if there is not much data in the sample.
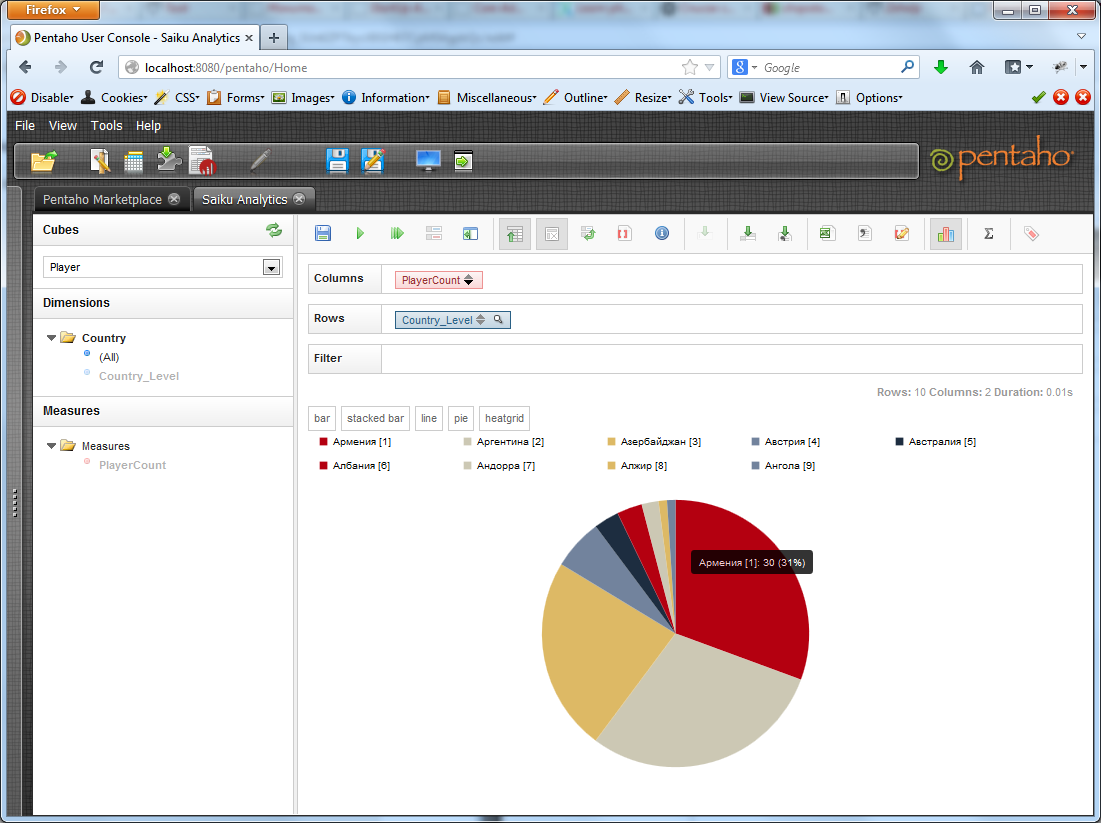
You can see the statistics on the sample: minimum, maximum rate, average value, etc. You can unload all this property in xls or csv. We can also save the query that we have created using the constructor on the server in order to return to it later.
So, the essence is clear. Let's create a couple more measurements. In principle, measurements by player status and career availability are no different from measurements by country. And the result in both cases will be just 2 lines (active / inactive and has / no).
Much more interesting is the case with the hierarchy of the type Date. We will create it now. Go back to Workbench, add a new dimension ( BirthDate ). He instead of StandardDimension set the parameter TimeDimension . Hierarchy is already there. Add a dimension table - player_birth_date_dim .
Add the first level - Year . Set the values table = player_birth_date_dim, column = id, levelType = TimeYears. For this level, add the Key Expression property with the value of `year`.
Add the second level - Month . Set the values table = player_birth_date_dim, column = id, levelType = TimeMonths. For this level, add the Key Expression property with the value `month`, Caption Expression with the value“ CONCAT (`year`, ',', MONTHNAME (STR_TO_DATE (` month`, '% m'))) ”.
Add the third level - Day . Set the values table = player_birth_date_dim, column = id, levelType = TimeDays. For this level, add the Caption Expression property with the value “CONCAT (LPAD (` day`, 2, 0), '.', LPAD (`month`, 2, 0), '.',` Year`) ”.
Add the created dimension to the cube, specifying bith_date_id as foreignKey.
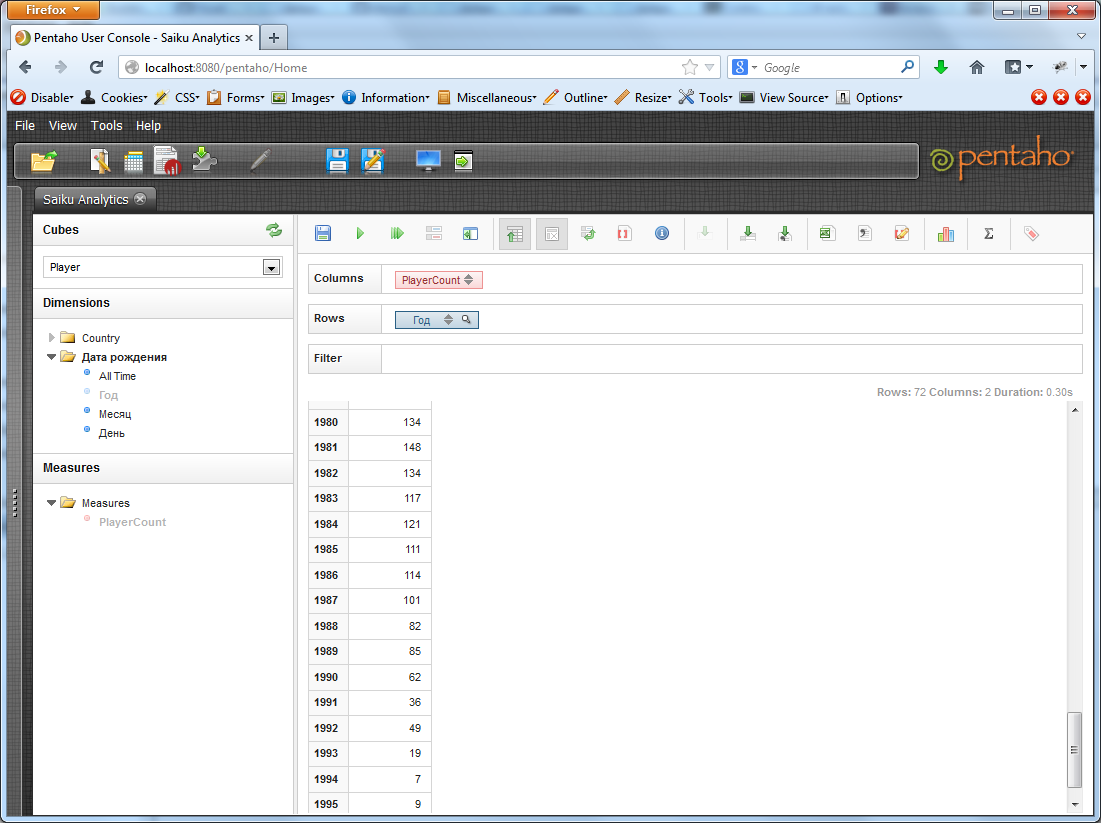
We publish. Let's try to break all the players by year of birth.
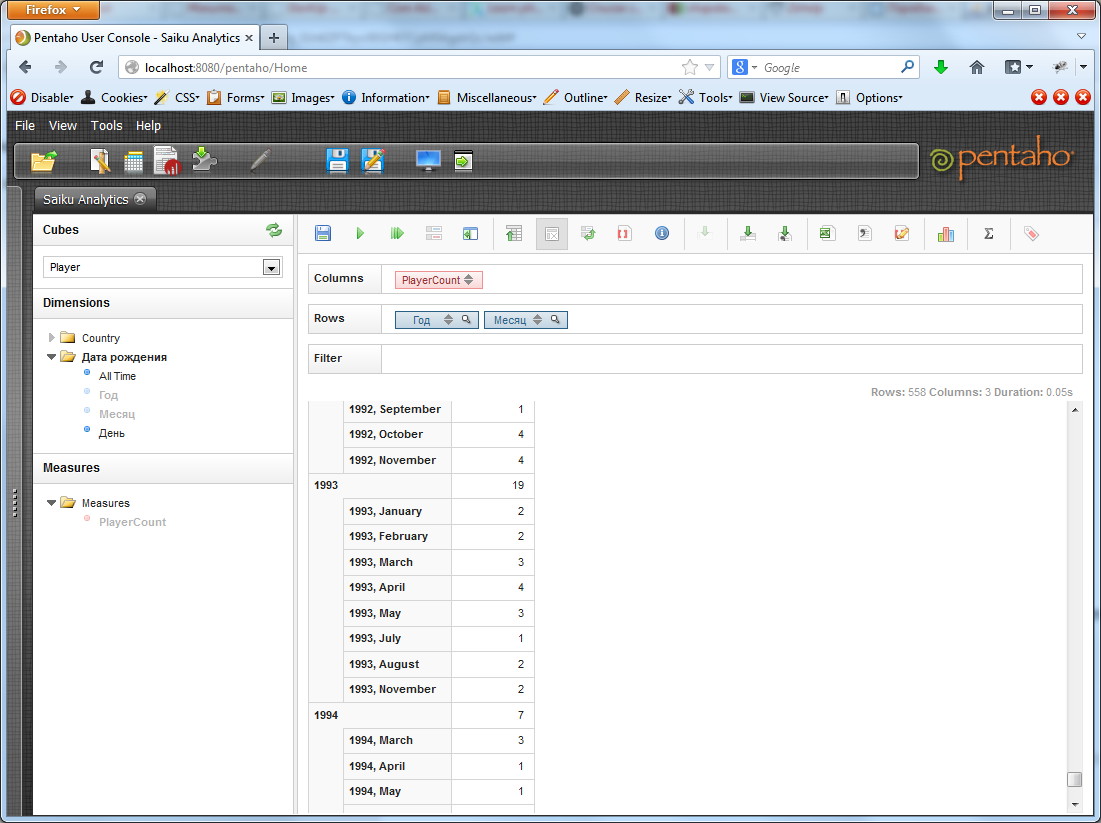
And now we add to the “Year” parameter also the “Month” parameter. Pentaho will break each of the years into months and count the number of players born in a particular month of each year. By default, only the data by months is displayed, but if you press the “Hide Parents” button in the toolbar, you can see the total number of players for the given year.
But the main strength of Pentaho, and the whole OLAP, in fact, is not in such simple samples, but in sections on several dimensions at the same time. Those.for example, find the number of players born in each country after 1990.
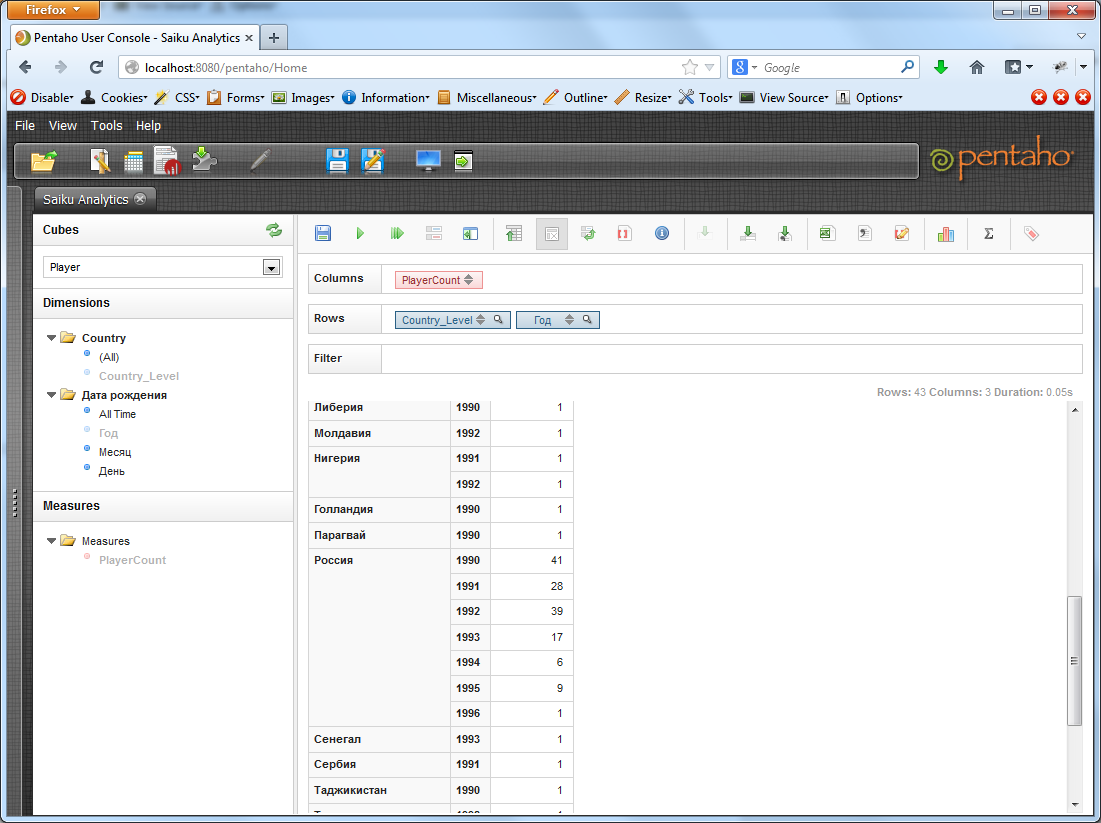
With the increase in the number of metrics, queries can become more and more complex and targeted, reflecting a specific static need.
This concludes our long-long article. I hope this tutorial will help someone take a fresh look at OLAP solutions, or maybe even introduce these solutions in their organizations.
Source: https://habr.com/ru/post/187782/
All Articles