False sharing in a multi-threaded Java application
JRE allows you to abstract from a specific platform, making writing cross-platform code much easier. Of course, the Write once, run anywhere does not reach the ideal, but life makes it much easier.
With the abundance of frameworks and the fullness of its own standard library, the idea that the program runs on a very specific hardware gradually fades into the background. In most cases, this is justified, but sometimes life makes its own adjustments.
The vast majority of modern processors have a cache for storing frequently used data. Cache memory is divided into blocks (Cache line). Mechanisms implementing Cache coherence ensure cache synchronization between the processor cores (s) in a computer system.
')
The term false sharing means access to different objects in a program that share the same block of cache memory. False sharing in a multi-threaded application, when variables are modified from different streams in one block, leads to a decrease in performance and an increase in the load on Cache coherence mechanisms. Details on how this happens can be found in the article on this topic.
The multithreaded application, the threads, at each iteration, take the previous value from their common array cell, perform calculations and add the results back.
Check that jvm didn’t make any unnecessary optimizations:
If globalArray is not volatile, then jvm will not read from memory every time:
In real life, when the computational method is not trivial, such optimization may not happen.
Create a new project in VTune Amplifier:
We create and run Generic Exploration analysis. In summary we see:
CPI - 2.100, with normal for settlement tasks 1 and less. Go to the view Hardware issues:
There is Contested access, meaning that the data written by one stream is read by another thread and at the same time the threads run on different cores / CPUs.
That is, the cells of the globalArray array fall into one cache line.
In order to avoid this situation, we will space the cells in memory by the cache line value. On the Intel i5, the cache line size is 64 bytes. Change the line
on
Why not i * 8? Because in the case of arrays, the first element after the title of the object is the length (field length). For element access operations, jvm can read this field to check the validity of the index.
We launch the repeated analysis in Vtune:
CPI - 0.586, Contested access is gone, In proportion to CPI, the operating time has changed, from 13.7 to 4.5 seconds.
Testing was conducted on a single-processor machine, in the case of a multiprocessor configuration, the overhead of synchronizing the cache memory will be even greater.
Naturally, the same problem may arise when accessing the fields of objects. But since the minimum size of the object (c one field) in the hostpot jvm is 16 bytes, the problem will be less common. The way to avoid false sharing for objects using inheritance can be viewed in the jmh source, in the BlackHole implementation. As one of the options - not to create bulk objects for all threads, but to spread this process over time.
Testing was conducted on a machine with an Intel Core i5 3.3 GHz processor, 64bit JDK 1.7.0_21, Intel Vtune Amplifier XE 2013 Update 11 (build 300544) Evaluation license, Windows 7 64bit.
Ps. Do not take the performance figures given in the article literally. The results will depend to a large extent on external factors, for example, on how the OS, together with jvm, distributes the threads among the processor cores (s). But if something is created high-performance, then such features of target platforms should be taken into account.
With the abundance of frameworks and the fullness of its own standard library, the idea that the program runs on a very specific hardware gradually fades into the background. In most cases, this is justified, but sometimes life makes its own adjustments.
The vast majority of modern processors have a cache for storing frequently used data. Cache memory is divided into blocks (Cache line). Mechanisms implementing Cache coherence ensure cache synchronization between the processor cores (s) in a computer system.
')
The term false sharing means access to different objects in a program that share the same block of cache memory. False sharing in a multi-threaded application, when variables are modified from different streams in one block, leads to a decrease in performance and an increase in the load on Cache coherence mechanisms. Details on how this happens can be found in the article on this topic.
Tools
- hsdis plugun for disassembling jit code.
- Intel® VTune ™ Amplifier XE 2013 for profiling and CPU metering.
Example
The multithreaded application, the threads, at each iteration, take the previous value from their common array cell, perform calculations and add the results back.
Hidden text
public class SArray { // volatile jvm private static volatile long globalArray[] = new long[512]; public static class MThread implements Runnable { private int aPos; private long iterations; public MThread(long iterations, int aPos) { this.aPos = aPos; this.iterations = iterations; } @Override public void run() { for(long l = 0; l < iterations; ++l) { ++globalArray[aPos]; } System.out.printf("A:TID:%d, count: %d\n", Thread.currentThread().getId(), globalArray[aPos]); } } private static final int THREAD_COUNT = Runtime.getRuntime().availableProcessors(); private static final long ITERATIONS = 1870234052L; public static void main(String[] args) throws Throwable { Thread[] threads = new Thread[THREAD_COUNT]; long smillis = System.currentTimeMillis(); for(int i = 0; i < THREAD_COUNT; ++i) { threads[i] = new Thread(new MThread(ITERATIONS, i)); } for(Thread t: threads) { t.start(); } for(Thread t: threads) { t.join(); } System.out.printf("Total iterations on %d threads: %d, took %d ms\n", THREAD_COUNT, ITERATIONS, System.currentTimeMillis() - smillis); } } Check that jvm didn’t make any unnecessary optimizations:
java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,SArray$MThread::run -XX:PrintAssemblyOptions=intel -cp target\falseshare-1.0-SNAPSHOT.jar SArray Hidden text
0x0000000002350540: mov r11d,DWORD PTR [r13+0xc] 0x0000000002350544: mov r10d,DWORD PTR [r8+0x70] ;*getfield aPos ; - SArray$MThread::run@15 (line 18) 0x0000000002350548: mov r9d,DWORD PTR [r12+r10*8+0xc] ; implicit exception: dispatches to 0x00000000023505dd 0x000000000235054d: cmp r11d,r9d 0x0000000002350550: jae 0x0000000002350599 ;*laload ; - SArray$MThread::run@19 (line 18) 0x0000000002350552: shl r10,0x3 ; >>>> ; 0x0000000002350556: inc QWORD PTR [r10+r11*8+0x10] ;*goto ; - SArray$MThread::run@27 (line 17) 0x000000000235055b: add rbx,0x1 ; OopMap{r8=Oop r13=Oop off=127} ;*goto ; - SArray$MThread::run@27 (line 17) 0x000000000235055f: test DWORD PTR [rip+0xfffffffffddefa9b],eax # 0x0000000000140000 ;*goto ; - SArray$MThread::run@27 (line 17) ; {poll} 0x0000000002350565: cmp rbx,QWORD PTR [r13+0x10] 0x0000000002350569: jl 0x0000000002350540 ;*ifge If globalArray is not volatile, then jvm will not read from memory every time:
Hidden text
0x00000000021e0592: add rbx,0x1 ;*ladd ; - SArray$MThread::run@25 (line 17) ; >>>> ; 1 0x00000000021e0596: add r8,0x1 ;*ladd ; - SArray$MThread::run@21 (line 18) 0x00000000021e059a: mov QWORD PTR [r11+rcx*8+0x10],r8 ; OopMap{r11=Oop r13=Oop off=127} ;*goto ; - SArray$MThread::run@27 (line 17) 0x00000000021e059f: test DWORD PTR [rip+0xfffffffffe24fa5b],eax # 0x0000000000430000 ;*goto ; - SArray$MThread::run@27 (line 17) ; {poll} 0x00000000021e05a5: cmp rbx,r10 0x00000000021e05a8: jl 0x00000000021e0592 ;*ifge In real life, when the computational method is not trivial, such optimization may not happen.
In this case, volatile is used solely to confuse the optimizer. A record of the volatile long [] array type means that the volatile semantics refers to a pointer to an array, and not to its elements.
Create a new project in VTune Amplifier:
Hidden text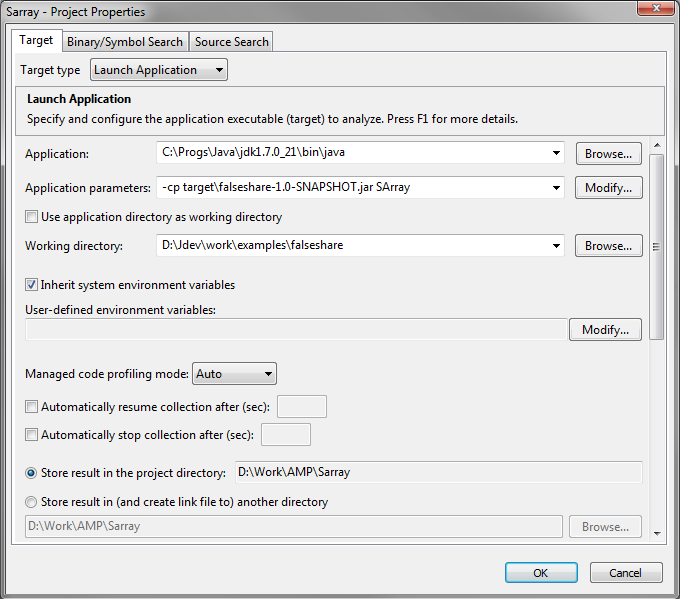
We create and run Generic Exploration analysis. In summary we see:
Hidden text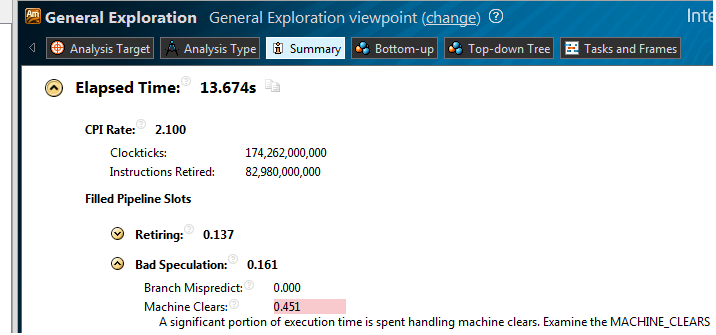
CPI - 2.100, with normal for settlement tasks 1 and less. Go to the view Hardware issues:
Hidden text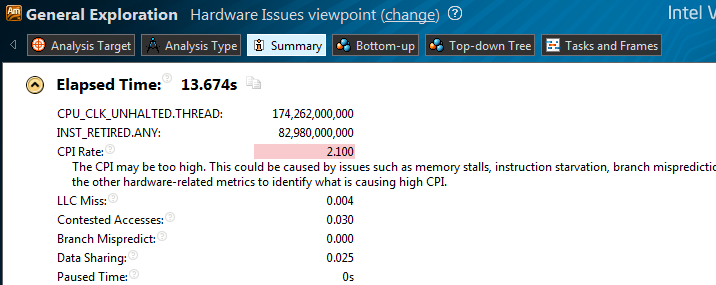
There is Contested access, meaning that the data written by one stream is read by another thread and at the same time the threads run on different cores / CPUs.
That is, the cells of the globalArray array fall into one cache line.
In order to avoid this situation, we will space the cells in memory by the cache line value. On the Intel i5, the cache line size is 64 bytes. Change the line
threads[i] = new Thread(new MThread(ITERATIONS, i)); on
threads[i] = new Thread(new MThread(ITERATIONS, (i + 1) * 8)); Why not i * 8? Because in the case of arrays, the first element after the title of the object is the length (field length). For element access operations, jvm can read this field to check the validity of the index.
We launch the repeated analysis in Vtune:
Hidden text
CPI - 0.586, Contested access is gone, In proportion to CPI, the operating time has changed, from 13.7 to 4.5 seconds.
Testing was conducted on a single-processor machine, in the case of a multiprocessor configuration, the overhead of synchronizing the cache memory will be even greater.
Naturally, the same problem may arise when accessing the fields of objects. But since the minimum size of the object (c one field) in the hostpot jvm is 16 bytes, the problem will be less common. The way to avoid false sharing for objects using inheritance can be viewed in the jmh source, in the BlackHole implementation. As one of the options - not to create bulk objects for all threads, but to spread this process over time.
Testing was conducted on a machine with an Intel Core i5 3.3 GHz processor, 64bit JDK 1.7.0_21, Intel Vtune Amplifier XE 2013 Update 11 (build 300544) Evaluation license, Windows 7 64bit.
Ps. Do not take the performance figures given in the article literally. The results will depend to a large extent on external factors, for example, on how the OS, together with jvm, distributes the threads among the processor cores (s). But if something is created high-performance, then such features of target platforms should be taken into account.
Source: https://habr.com/ru/post/187752/
All Articles