Building drbd mirrors on Proxmox-3.0
 In this article I want to describe how-to create drbd mirroring on Proxmox 3.0 host machines. Combining machines in the proxmox cluster makes sense to these operations - although in general there is no difference.
In this article I want to describe how-to create drbd mirroring on Proxmox 3.0 host machines. Combining machines in the proxmox cluster makes sense to these operations - although in general there is no difference.The main difference of this material from many, spread out on the Internet, is that we are doing a drbd partition not on the second physical disk connected second, but on the lvm partition within the only available disk.
The question of the expediency of such actions is rather controversial - whether drbd will be faster on a “raw” disk or not, but in any case, this is a 100% tested version. In the piggy bank so to speak. And working with a “raw” disk is just a special case of this manual.
Actually, when installing Proxmox 3.0 (just like its predecessor 2.0), it does not bother with partitioning issues and it breaks everything up itself considering only the overall disk size and memory size. We get a partition / pve / data that takes up most of the disk and is visible in Proxmox as local storage. That is due to him and will be actions.
1. We update packages to current
#aptitude update && aptitude full-upgrade2. Install the necessary packages
#aptitude install drbd8-utils3. Free up space for a new section.
Unmount / dev / pve / data (also known as / var / lib / vz). All the following actions of step 3 can be done only on the unmounted resource - accordingly, before this we extinguish all the VMs that use the local storage on this node. The rest can not touch if very necessary.
#umount /dev/pve/data3.1. Decrease / dev / pve / data.
In principle, several of the following steps can be replaced with commands.
#lvresize -L 55G /dev/mapper/pve-data#mkfs.ext3 /dev/pve/dataWell, or a little more detailed. And in my opinion a little more correctly.
#lvremove /dev/pve/data#lvcreate -n data -l 55G pve#mkfs.ext3 /dev/pve/dataBut at the same time we lose everything that is in the local storage. If Proxmox is freshly installed (which is generally recommended for such kind of manipulations), then we go to step 4. If there is a question to save the data in the local repository, then we act differently.
')
3.2. Decrease / dev / pve / data without losing information.
I assume that local is less than 50G. If you have a different situation, simply change the "new size" in the teams.
#umount /dev/pve/dataMandatory check, without it resize2fs will not work
#e2fsck -f /dev/mapper/pve-datae2fsck 1.42.5 (29-Jul-2012)Pass 1: Checking inodes, blocks, and sizesPass 2: Checking directory structurePass 3: Checking directory connectivityPass 4: Checking reference countsPass 5: Checking group summary information/dev/mapper/pve-data: 20/53223424 files (0.0% non-contiguous), 3390724/212865024 blocksCompress the file system to 50G. If this step is skipped, then with a probability of 90% after lvresize we will get a broken system. Moreover, the number is intentionally a little smaller than the resulting section. With a margin.
#resize2fs /dev/mapper/pve-data 50Gresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 13107200 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 13107200 blocks long.#e2fsck -f /dev/mapper/pve-dataCompressing the / pve / data section directly to 55G
#lvresize -L 55G /dev/mapper/pve-dataWARNING: Reducing active logical volume to 55.00 GiBTHIS MAY DESTROY YOUR DATA (filesystem etc.)Do you really want to reduce data? [y/n]: yReducing logical volume data to 55.00 GiBLogical volume data successfully resizedWe occupy the system all the available space. In principle, if your “stock” at the previous step is not large, then this can be done. Why save on matches? ;)
#resize2fs /dev/mapper/pve-dataresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 14417920 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 14417920 blocks long.Return / dev / pve / data system.
#mount /dev/pve/data4. Creating a partition for drbd
Enjoying free space. We are convinced that all previous steps have given that which is not necessary. Ie free space on the / dev / sda2 section
#pvdisplay--- Physical volume ---PV Name /dev/sda2VG Name pvePV Size 931.01 GiB / not usable 0Allocatable yesPE Size 4.00 MiBTotal PE 238339Free PE 197891Allocated PE 40448PV UUID 6ukzQc-D8VO-xqEK-X15T-J2Wi-Adth-dCy9LDCreate a new partition for all free space.
#lvcreate -n drbd0 -l 100%FREE pveLogical volume "drbd" created5. Preparing drbd configuration file
#nano /etc/drbd.d/r0.resresource r0 {
startup {
wfc-timeout 120;
degr-wfc-timeout 60;
become-primary-on both;
}
net {
cram-hmac-alg sha1;
shared-secret "proxmox";
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
syncer {
rate 30M;
}
on p1 {
device / dev / drbd0;
disk / dev / pve / drbd;
address 10.1.1.1:7788;
meta-disk internal;
}
on p2 {
device / dev / drbd0;
disk / dev / pve / drbd;
address 10.1.1.2:7788;
meta-disk internal;
}
}
Some recommend setting the wfc-timeout parameter to 0. Its meaning is that if at the start we don’t see the drbd neighbor, it will reboot after wfc-timeout seconds for a second attempt. 0 - means to disable such an action.
Rate 30M - transfer limit between drbd hosts. The value corresponds to 1G connection. Recommended as 30% of the actual bandwidth between hosts. In the example below, on “test rabbits” the bandwidth on a 100M connection is about 11Mb / s, ie the rate should be reduced to 3M. With a 10G connection between the hosts, it obviously makes sense to increase.
6. Creating meta data and launching drbd partition.
#modprobe drbd#drbdadm create-md r0md_offset 830015008768al_offset 830014976000bm_offset 829989642240Found some data==> This might destroy existing data! <==Do you want to proceed?[need to type 'yes' to confirm] yesWriting meta data...initializing activity logNOT initialized bitmapNew drbd meta data block successfully created.Success#drbdadm up r0You can see the result like this:
#cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:8105367607. Prepare the second host
Steps 1-6 indulge in a second host machine. An important point (!). The size of the drbd partition should be identical on both hosts.
8. Synchronization.
Take one of the hosts (it does not matter which one). Call it before complete synchronization primary. The second, respectively, secondary. After full synchronization, they will become equivalent - this is the mode we set.
#drbdadm -- --overwrite-data-of-peer primary r0# cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:664 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760then on both hosts
#drbdadm down r0#service drbd startOn primary, the result will look like this:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 18]:.On secondary:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 14]:0: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 11.Errors \ delays are related to the fact that we restarted everything at the same time. In a normal situation, the launch looks simple:
#service drbd startStarting DRBD resources:[ d(r0) s(r0) n(r0) ].# cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:SyncSource ro:Primary/Primary ds:UpToDate/Inconsistent C r-----ns:199172 nr:0 dw:0 dr:207920 al:0 bm:11 lo:1 pe:24 ua:65 ap:0 ep:1 wo:b oos:810340664[>....................] sync'ed: 0.1% (791348/791536)Mfinish: 19:29:01 speed: 11,532 (11,532) K/sechere we see that disk synchronization has begun.
Let's start monitoring this process and go for a walk. Depending on the size of the disk and the connection speed between the hosts, we can walk from a couple of hours to days ...
#watch –n 1 “cat /proc/drbd”And we are waiting for the cherished 100%
cs:SyncSource ro:Primary/Primary ds:UpToDate/ UpToDate9. Creating lvm volume group
The process is long, so let's continue on the primary host.
#vgcreate drbd-0 /dev/drbd0No physical volume label read from /dev/drbd0Writing physical volume data to disk "/dev/drbd0"Physical volume "/dev/drbd0" successfully createdVolume group "drbd-0" successfully created10. Connecting a group in Proxmox
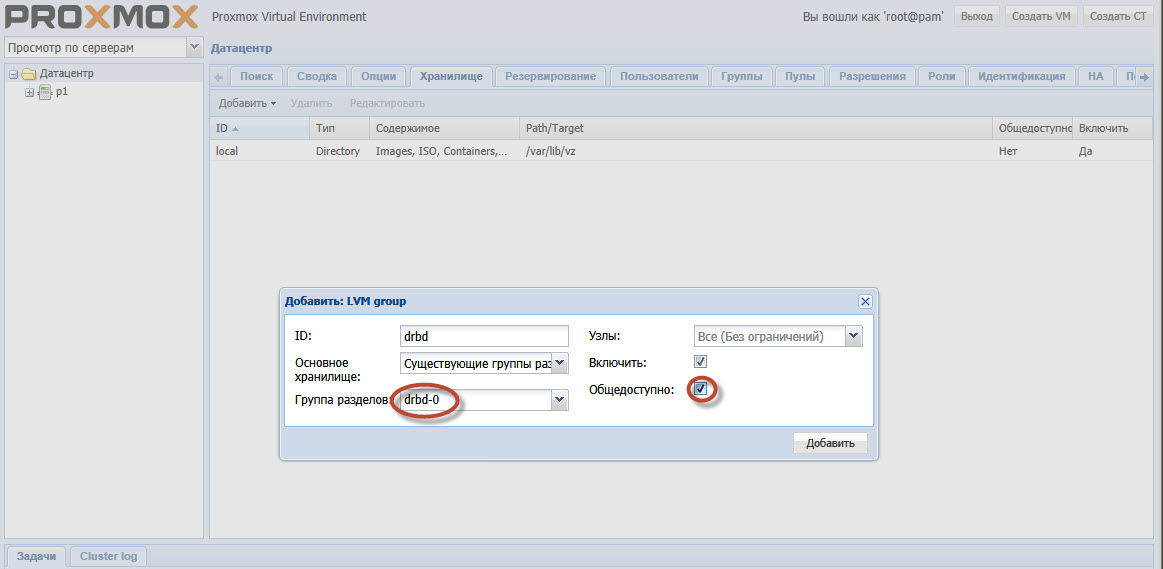
Select the Data Center Storage section in the Proxmox GUI. Add. Type - LVM, arbitrary ID is just a name. The partition group drbd-0, + enable, + is publicly available.
Pay attention to the highlights. drbd-0 is the group created in step 9.
Well, public access is set so that Proxmox does not try to copy the images of the host machine disks during the migration process.
11. Everything.
After waiting for the synchronization to finish, you can create machines by selecting drbd as the image-disk storage, transfer them from the host to the host in the cluster without losing contact with the virtual machine to service the host machine. In general, everything is ready to build a High Availability Cluster - Proxmox
Source: https://habr.com/ru/post/187660/
All Articles