Cache secrets, or how to spend 1000 cycles for 10 teams
Much has been written about the processor cache, including on Habré , but more and more in general terms. I offer you a specific example of how the cache works in real life.
As an example, I will take a simple system on a chip, based on a 32-bit Harvard RISC processor with a single-level cache and without a MMU (something like ARM Cortex-R). The processor is connected to an external memory controller via a 32-bit AMBA AHB bus operating at processor frequency.
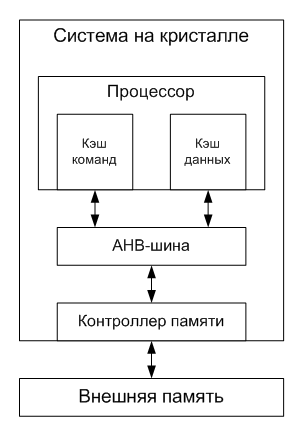
Caches of commands and data are separate, direct display, 16 kilobytes each. The cache line length is 32 bytes, that is, each cache contains 512 lines. Let me remind you that the offset determines the ordinal number of the byte within the cache line, and the index is the number of the cache line in the cache. Since the cache is a direct mapping, then it can not simultaneously contain several lines with the same index, even if they have different tags.
')

The easiest way to understand how it all works is to figure out what the processor does right after powering on. Suppose that the caches are enabled by default and are invalid (i.e. empty), and somehow the external memory somehow contains such a program that adds two numbers:
After switching on, the processor starts to execute commands from the address corresponding to the address of the interrupt vector table. This address is usually hardwired in the processor. In general, it can be equal to anything, but for simplicity, we assume that it is zero.
Thus, the first command of our program, “jump_start”, is located at 0x0, and the processor knows its address a priori.
Step 1. The processor searches the command cache for a line containing the command with the address 0x0. Since the cache is empty, the cache controller inside the processor signals a miss and immediately stops the processor, simultaneously initiating a so-called “read burst”, that is, a request to read a data packet from external memory. Data is never loaded into the cache word by word - only by packets, otherwise there is no point in the cache at all! The size of the data packet is equal to the length of the cache line. Thus, the request takes 8 clock cycles, because in our system the AHB bus can transmit no more than 32 bits of data per clock. In the ideal case, the query will need one clock to reach the memory controller (if the bus is busy processing another request, then it will take more clock cycles). Depending on the type of external memory, the controller may begin to transmit the read data either immediately after the arrival of the request (if the memory is SSRAM) or after several tens of cycles (in the case of SDRAM) - this time is called memory latency. One more clock cycle will be required by the read data to go back from the memory controller to the processor. Below are the timing diagrams for reading a cache line from external memory with a latency of four clocks.

Step 2. The cache controller writes the words coming from the memory into a line buffer (“line buffer”), the size of which is equal to the length of the cache line. When the string buffer is filled, its contents will be stored in the zero line of the instruction cache (since the index at the address 0x0 is 0). However, the processor can execute commands from the buffer directly, so as soon as the command that caused the miss is written to the buffer, the cache controller immediately unlocks the processor. Since the processor is pipelined, it will have to select the second instruction from the memory even before the first is decoded. To achieve this, the address of the second command will be predicted, and, most likely, will be predicted incorrectly, as a result of which the processor will continue to select commands from the address 0x4. Since the second command (“jump _handler1”) will also be in the buffer at this point, there will not be a slip, and the processor will begin to select the third command (“jump _handler2”). This will continue until the processor realizes that it was wrong with the prediction and the second command should have been selected at the address 0x1234.
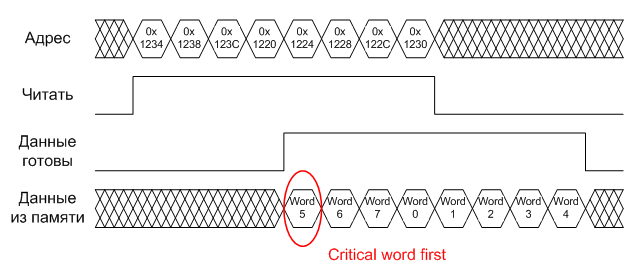
Step 3. As soon as the processor begins to see clearly (and in a processor with, say, a seven-step pipeline of commands, it takes about seven cycles), it will immediately issue another cache miss, this time caused by the lack of a line in the cache containing the command at 0x1234 (“move R0, 0x10000000 "), and will send a new" read burst ", which upon return will be saved in the 145th cache line (since the index at the address 0x1220 is 0x91 = 145). Depending on the implementation, the processor can start loading data into the cache either from the beginning of the line (ie, first the word at 0x1220, then 0x1224, 0x1228, and so on up to 0x123C), or from the word that caused a miss (the so-called “Critical word first” - the word is first read at 0x1234, then 0x1238, 0x123C, 0x1220, 0x1224, etc.) In both cases, the line is fully loaded in any case, but in the first case, the processor will spend five extra cycles to wait. It should be noted that many microcontrollers still do not support “critical word first”, so with proper luck the programmer can achieve a significant drop in performance.
Step 4. Regardless of whether “critical word first” is supported or not, three correct commands will be loaded into the cache at once (up to “move R1, 0x10010000” inclusive). When the queue reaches the “load R10, [R0]” command, the processor will detect the data cache miss (the data cache is empty - all previous manipulations have occurred with the instruction cache) and send another “read burst”, which will be written to the zero line (since the index at the address 0x10000000 is 0). If the processor is smart and smart enough (and most processors that are slightly more complex than student crafts are smart enough for this), he will understand that the command following the “load R10, [R0]” does not depend on it and can be executed simultaneously with copying data to the cache. After that, the processor will want to select the command at 0x1240 and we will get another “read burst” that will “hang”, since the bus will still be occupied by the previous request from the data cache. Of course, sooner or later the “load R11, [R1]” command will get into the instruction cache, and the processor will immediately detect a new data cache miss, which in addition will force out the previously loaded string with the tag 0x04000 (since the addresses 0x10000000 and 0x1000000 differ only tags - 0x04000 and 0x04800, respectively, and the index for both is zero).
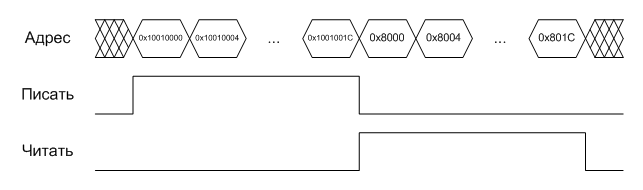
Step 5. In the end, the processor will execute the “store R2, [R3]” command, which will cause another data cache miss and, as a result, another “read burst”, and in addition force out the line with the tag 0x04800 from the cache, replacing it with line with tag 0x08000. In addition, you need to remember that this command will not write anything in external memory, because the recording will be made only in the cache! No “write burst” will not be until the programmer clearly takes care of “merging” the updated cache line back into memory (i.e., cache line flush), or until the line is preempted from the cache by another line. For example, if instead of the “halt” command there was a “load r4, [0x8000]” command, the reading process would look like this:
Finally, I would like to say this: errors related to improper use of caches can be searched for months. Compilers, caching volatiles, and memory, which, contrary to the precepts of comrade von Neumann, changes itself, are witnesses. “Transparency” of caches is a myth, which is suitable only for spherical programmers on PHP vacuum. Therefore, if your processor has a cache - turn it off from harm's way!
As an example, I will take a simple system on a chip, based on a 32-bit Harvard RISC processor with a single-level cache and without a MMU (something like ARM Cortex-R). The processor is connected to an external memory controller via a 32-bit AMBA AHB bus operating at processor frequency.
Caches of commands and data are separate, direct display, 16 kilobytes each. The cache line length is 32 bytes, that is, each cache contains 512 lines. Let me remind you that the offset determines the ordinal number of the byte within the cache line, and the index is the number of the cache line in the cache. Since the cache is a direct mapping, then it can not simultaneously contain several lines with the same index, even if they have different tags.
')
The easiest way to understand how it all works is to figure out what the processor does right after powering on. Suppose that the caches are enabled by default and are invalid (i.e. empty), and somehow the external memory somehow contains such a program that adds two numbers:
# table of interrupt vectors located at address 0x0
_reset_vector:
0x0000: jump _start
_interrupt1:
0x0004: jump _handler1
_interrupt2:
0x0008: jump _handler2
...
# The main program code is located at 0x1234
_start:
# load the first operand from memory into register R10
0x1234: moveh R0, 0x1000 # load 0x1000 into R0 [31:16]
0x1238: load R10, [R0] # load into R10 the value from 0x10000000
# load the second operand from memory into register R11
0x123C: moveh R1, 0x1001 # load 0x1001 into R1 [31:16]
0x1240: load R11, [R1] # load into R11 a value from 0x10010000
# add operands and write the result to memory
0x1244: add R2, R0, R1
0x1248: moveh R3, 0x2000 # load 0x2000 into R3 [31:16]
0x124C: store R2, [R3] # store R2 at the address from R3
# stop the processor
0x1250: halt After switching on, the processor starts to execute commands from the address corresponding to the address of the interrupt vector table. This address is usually hardwired in the processor. In general, it can be equal to anything, but for simplicity, we assume that it is zero.
Thus, the first command of our program, “jump_start”, is located at 0x0, and the processor knows its address a priori.
Step 1. The processor searches the command cache for a line containing the command with the address 0x0. Since the cache is empty, the cache controller inside the processor signals a miss and immediately stops the processor, simultaneously initiating a so-called “read burst”, that is, a request to read a data packet from external memory. Data is never loaded into the cache word by word - only by packets, otherwise there is no point in the cache at all! The size of the data packet is equal to the length of the cache line. Thus, the request takes 8 clock cycles, because in our system the AHB bus can transmit no more than 32 bits of data per clock. In the ideal case, the query will need one clock to reach the memory controller (if the bus is busy processing another request, then it will take more clock cycles). Depending on the type of external memory, the controller may begin to transmit the read data either immediately after the arrival of the request (if the memory is SSRAM) or after several tens of cycles (in the case of SDRAM) - this time is called memory latency. One more clock cycle will be required by the read data to go back from the memory controller to the processor. Below are the timing diagrams for reading a cache line from external memory with a latency of four clocks.
Step 2. The cache controller writes the words coming from the memory into a line buffer (“line buffer”), the size of which is equal to the length of the cache line. When the string buffer is filled, its contents will be stored in the zero line of the instruction cache (since the index at the address 0x0 is 0). However, the processor can execute commands from the buffer directly, so as soon as the command that caused the miss is written to the buffer, the cache controller immediately unlocks the processor. Since the processor is pipelined, it will have to select the second instruction from the memory even before the first is decoded. To achieve this, the address of the second command will be predicted, and, most likely, will be predicted incorrectly, as a result of which the processor will continue to select commands from the address 0x4. Since the second command (“jump _handler1”) will also be in the buffer at this point, there will not be a slip, and the processor will begin to select the third command (“jump _handler2”). This will continue until the processor realizes that it was wrong with the prediction and the second command should have been selected at the address 0x1234.
Step 3. As soon as the processor begins to see clearly (and in a processor with, say, a seven-step pipeline of commands, it takes about seven cycles), it will immediately issue another cache miss, this time caused by the lack of a line in the cache containing the command at 0x1234 (“move R0, 0x10000000 "), and will send a new" read burst ", which upon return will be saved in the 145th cache line (since the index at the address 0x1220 is 0x91 = 145). Depending on the implementation, the processor can start loading data into the cache either from the beginning of the line (ie, first the word at 0x1220, then 0x1224, 0x1228, and so on up to 0x123C), or from the word that caused a miss (the so-called “Critical word first” - the word is first read at 0x1234, then 0x1238, 0x123C, 0x1220, 0x1224, etc.) In both cases, the line is fully loaded in any case, but in the first case, the processor will spend five extra cycles to wait. It should be noted that many microcontrollers still do not support “critical word first”, so with proper luck the programmer can achieve a significant drop in performance.
Step 4. Regardless of whether “critical word first” is supported or not, three correct commands will be loaded into the cache at once (up to “move R1, 0x10010000” inclusive). When the queue reaches the “load R10, [R0]” command, the processor will detect the data cache miss (the data cache is empty - all previous manipulations have occurred with the instruction cache) and send another “read burst”, which will be written to the zero line (since the index at the address 0x10000000 is 0). If the processor is smart and smart enough (and most processors that are slightly more complex than student crafts are smart enough for this), he will understand that the command following the “load R10, [R0]” does not depend on it and can be executed simultaneously with copying data to the cache. After that, the processor will want to select the command at 0x1240 and we will get another “read burst” that will “hang”, since the bus will still be occupied by the previous request from the data cache. Of course, sooner or later the “load R11, [R1]” command will get into the instruction cache, and the processor will immediately detect a new data cache miss, which in addition will force out the previously loaded string with the tag 0x04000 (since the addresses 0x10000000 and 0x1000000 differ only tags - 0x04000 and 0x04800, respectively, and the index for both is zero).
Step 5. In the end, the processor will execute the “store R2, [R3]” command, which will cause another data cache miss and, as a result, another “read burst”, and in addition force out the line with the tag 0x04800 from the cache, replacing it with line with tag 0x08000. In addition, you need to remember that this command will not write anything in external memory, because the recording will be made only in the cache! No “write burst” will not be until the programmer clearly takes care of “merging” the updated cache line back into memory (i.e., cache line flush), or until the line is preempted from the cache by another line. For example, if instead of the “halt” command there was a “load r4, [0x8000]” command, the reading process would look like this:
Finally, I would like to say this: errors related to improper use of caches can be searched for months. Compilers, caching volatiles, and memory, which, contrary to the precepts of comrade von Neumann, changes itself, are witnesses. “Transparency” of caches is a myth, which is suitable only for spherical programmers on PHP vacuum. Therefore, if your processor has a cache - turn it off from harm's way!
Source: https://habr.com/ru/post/187654/
All Articles