The art of understanding with a half-word. Query expansion in Yandex
Today we will talk about the mechanism that allows Yandex search to find exactly what the user had in mind, no matter how briefly and carelessly he formulated his query.
In the search world, such a mechanism is called a search query extension . The term is quite broad, includes reformulations, synonyms, transliteration, and even cognates (the latter are sometimes mistakenly called morphology support).
What parts does this mechanism consist of? What helps him to guess? And why on each of his rare mistakes there are thousands of requests, on which he greatly helped?
')


Why not just take and expand the query.
Using primitive search implementations in a small online store or on a local forum, it is often necessary to reformulate the initial query manually - to replace words with synonyms, to vary cases, tenses of verbs, and so on.
Noticing this many years ago, search engine developers decided that it is possible to greatly simplify the life of the user, if you immediately, automatically, search not only for a given query, but also for its various variations and reformulations. Now no one is surprised by the exact search results in the hands of the user, not experienced in the intricacies of the search query - however, the struggle to save time and increase freedom in formulating a query continues.
Today we consider only the query expansion mechanisms, that is, the addition of the original query in other words. We will try to tell you about ways to change the query (correcting typos in the word "classmates" and the inflection of Bric-Mulla, Bric-Mulloy ).
We divide extensions into several types, each of which has parallels in linguistics, but also differs in its own way from its prototype:
Expanding abbreviations is perhaps the most deceptive type of extensions - it seems at first glance accurate and unambiguous (“obviously”, “MSU” is “Moscow State University”), but it quickly turns out that there are “Mordovian” and “Mariupol”, and "International Humanitarian", and others.
We distinguish between several types of abbreviations:
Unlike abbreviations, the intuition turns out to be right: transliteration accounts for several tens of percent of all the benefits of extensions. She has good accuracy and fullness; It helps well in any context.
Users do not like to switch the keyboard layout, and when searching for a foreign surname or locality, it is easier to type them in Russian (“Demonzho” instead of “Demongeot” and “Cologne” instead of “Cologne”) than to remember the correct spelling in the original. The opposite situation is also frequent: residents of Russian-speaking diasporas abroad are more accustomed to chatting in forums in Russian, but with the use of transliteration. Search for such forums is also needed for Cyrillic queries. Transliteration comes in handy and when the query word is contained in the address of the found site.
In practice, we need not even transliteration, but the so-called practical transcription is the most close transmission of the original sound by means of another language. Otherwise, for example, French words will be distorted beyond recognition.
Orfarifariate are words that have identical meaning, but they can be written this way and that, and both spellings are considered literate.
Firstly, these are foreign words that are recorded by the ear and often do not have a single canonical spelling (“ike i ” / “ike a ”; “ interpret n” / “sense and n”).
Unlike transliteration, here we are dealing with pairs in the same language. A few words that with the help of transcription can lead to one Latin spelling are called orthophants.
Secondly, Russian words that admit different spellings (“ bild rd” → “bill iard rd”, “birthday and i” → “birthday i ”)
What is interesting orfovariant?
The types of extensions described above (abbreviations, transliteration, inflection, or hyphenation) tried to reflect the exact words of the query in all possible ways, considering the meaning to be inviolable. But it quickly became clear that it was necessary to more boldly allow semantic additions to the original request. Thus, the extensions were supplemented by word formation (“Moscow subway” → “Moscow subway station”) and synonyms (“hippo” → “hippo”).
The idea of expanding on the principle of word formation is to add cognate words to the query, including even other parts of speech (“Moscow metro” → “Moscow Metro”).
The mechanism of word formation is often called simply morphology, although this is not quite true: in addition to the word education , morphology also includes the word change (the very same “Bric-Mulloy”). The word change rarely adds new semantic shades to the request, it usually looks for the original word of the request in all forms (as they say, “the whole paradigm ”), so in this post we will not touch it.
Word-formation, on the contrary, may add semantically distant variants — contrary to general considerations, words with one root need not be close in meaning. Only a small number of types of word formation is in practice a good search engine extensions, so you need to be careful.
Is it possible to base academic synonyms from traditional dictionaries, and just load them into the search? Indeed, in the dictionaries collected extensive rows of reliable synonyms.
Therefore, we have gone from a purely vocabulary, linguistic understanding of synonyms, the statistical search for equivalents works much better. Any options are collected that may not be synonymous in an academic sense, but help to find what the user is looking for. This is the main criterion of quality - the usefulness of extensions for ranking (and not their dictionary affinity by meaning).
But collections of statistically collected synonyms in the traditional sense (as words with identical meaning) are few. For narrowly specific queries, on which there is very little information on the Internet, it is useful to replace some words of the query with more general concepts ( “hyper-names” ).
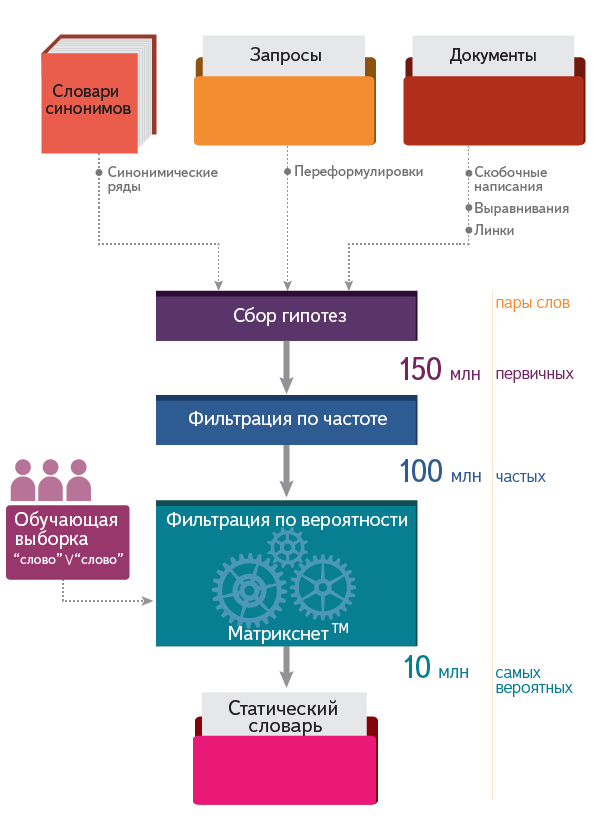
In the next section, the most interesting is how extensions are used in the search, but first let's look at how we prepare extension hypotheses.
From the above, it is easy to guess that the options for possible extensions for our needs can be built only through the analysis of real data that exists “in the wild” on the Internet. It is necessary to respond to a user's request quickly, so we prepare such options (the so-called "extension dictionary") in advance — and at the time of the search, we simply select all the pairs for the query words from the ready dictionary.
For the Russian language, this gives about 150 million pairs of extension hypotheses.
Couples that are found too rarely both in queries and in texts on the Internet are not a very reliable source, therefore, after collecting hypotheses, we limit them by frequency of occurrence.
It makes little sense to somehow take into account the form (case, declension) in which the word came together with one or another couple (at least for the Russian language). Therefore, we leave the only form of the word (as a rule, the initial one).
As a result, this usually results in about 100 million pairs.
But 100 million raw hypotheses are ore, which cannot simply be given to the request processing stage.
As a result of this selection, we get 10 million extensions - and this “dictionary” is used in processing requests. This is discussed in the next section.
When we receive a search query from a user, we select extensions from the dictionary that are suitable for the context.
For example, [mgu] has expanded in [mgu ^ mgu ^ msu ^ "Moscow State University"].
And already by the advanced query, the search finds documents with different variants of the wording, including the original (“exact form”). A number of factors are involved in document ranking, taking into account both the original word and the extensions. Other things being equal, the coincidence of the exact form (“MGU”) takes precedence over the occurrence of an extension (even full writing, like the “Moscow State University”) - although other factors may turn out to be stronger than an exact match.
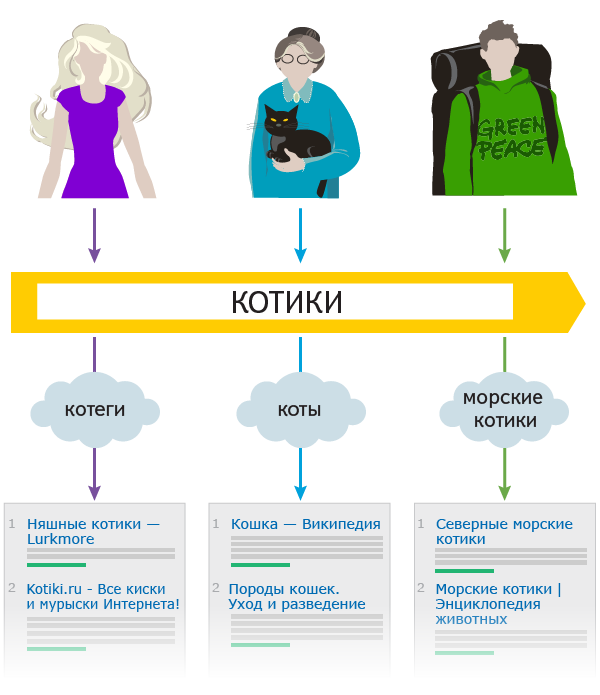
We try to highlight in the snippet not only the words of the request, but all the synonyms used, which helps the user to understand why he sees a particular document.
How to determine which extensions are relevant for a given request, and which are not; what exactly, in what cases and in what volume to add? The more types of extensions, the harder it is to build an algorithm for mixing them. , — . , : , . , 20% . « ».
, , 27% , .
, :
, , . , , . , .
, , . : , .
. , «» «», «Google» «», «» «Facebook» . , : «», « », «», «», «». (, ..), — .
, «» → «» , . , . For example:
( — )
, , : , .
, . , , ? . , [' ] [ ], .
— : ; , .
, : . , - , .
— . , , .
— . , . , «war k raft» — ( «War c raft»), - — ( [ ]) «» → «war k raft» , .
, «», «» «», .
, , . — . , , . 30% , 15% — .
In the search world, such a mechanism is called a search query extension . The term is quite broad, includes reformulations, synonyms, transliteration, and even cognates (the latter are sometimes mistakenly called morphology support).
What parts does this mechanism consist of? What helps him to guess? And why on each of his rare mistakes there are thousands of requests, on which he greatly helped?
')
Why not just take and expand the query.
Using primitive search implementations in a small online store or on a local forum, it is often necessary to reformulate the initial query manually - to replace words with synonyms, to vary cases, tenses of verbs, and so on.
Noticing this many years ago, search engine developers decided that it is possible to greatly simplify the life of the user, if you immediately, automatically, search not only for a given query, but also for its various variations and reformulations. Now no one is surprised by the exact search results in the hands of the user, not experienced in the intricacies of the search query - however, the struggle to save time and increase freedom in formulating a query continues.
Today we consider only the query expansion mechanisms, that is, the addition of the original query in other words. We will try to tell you about ways to change the query (correcting typos in the word "classmates" and the inflection of Bric-Mulla, Bric-Mulloy ).
We divide extensions into several types, each of which has parallels in linguistics, but also differs in its own way from its prototype:
Abbreviations (Russian Federation → Russian Federation)
Expanding abbreviations is perhaps the most deceptive type of extensions - it seems at first glance accurate and unambiguous (“obviously”, “MSU” is “Moscow State University”), but it quickly turns out that there are “Mordovian” and “Mariupol”, and "International Humanitarian", and others.
We distinguish between several types of abbreviations:
- Acronyms ("MSU", "OSAGO") - consist of the first letters of the words that form them. Acronyms, especially 2-3 letter letters, have the most options for decoding. The greater the ambiguity of the acronym, the less weight we give it when ranking.
- Composite ("matmeh", "agricultural") - are parts of words, usually roots. Sometimes the roots are connected by an additional letter (as " benzo about saw " = " benz and new saw ")
- Punctuation ("city", "second-hand", "district") - when the punctuation mark is included in the abbreviation.
- The separation of prefixes, each of which is reduced to the initial letter: “auto-”, “motorcycle”, “all-”, “heat-”. For example, this is how “thermal power plants” = " t heat electric center "
How to consider regionality; how to cut off false hypotheses
In addition to the ambiguity, in this kind of extensions, the consideration of regionality is interesting, because in each region the abbreviation may have its own decoding. Users from “Mordovia” who have their own “MSU” ( named after Ogarev ) are interested in its Moscow namesake no less than residents of other regions of Russia. But regional data may not be enough, you have to find a balance between a local object and its more famous counterpart from another region - so that it is easy to find one and the other.
When collecting options for extensions, there are quite a few false hypotheses that we struggle with with different heuristics:
When collecting options for extensions, there are quite a few false hypotheses that we struggle with with different heuristics:
- "Photo" = " photo b oma" (when abbreviated, all the words of the phrase should be reduced to parts of approximately the same length)
- “ good and give ” = “ good about give ”, “mother” = “ mother and any ” (one vowel cannot disappear, at least a whole syllable)
- "Chemical technology of natural energy sources" = "htn" (the first letter of the word with a separable prefix, "e", must also be present in the abbreviation)
- "Burned out" = " with Korea, all the time it is no longer under the monte" (many omissions, the first letters are outside the abbreviation)
- “Naza” = “importunate” (the abbreviation of one word is not translated into such a long word)
Transliteration (Peugeot → Peugeot)
Unlike abbreviations, the intuition turns out to be right: transliteration accounts for several tens of percent of all the benefits of extensions. She has good accuracy and fullness; It helps well in any context.
Users do not like to switch the keyboard layout, and when searching for a foreign surname or locality, it is easier to type them in Russian (“Demonzho” instead of “Demongeot” and “Cologne” instead of “Cologne”) than to remember the correct spelling in the original. The opposite situation is also frequent: residents of Russian-speaking diasporas abroad are more accustomed to chatting in forums in Russian, but with the use of transliteration. Search for such forums is also needed for Cyrillic queries. Transliteration comes in handy and when the query word is contained in the address of the found site.
In practice, we need not even transliteration, but the so-called practical transcription is the most close transmission of the original sound by means of another language. Otherwise, for example, French words will be distorted beyond recognition.
Realization: by letters, by syllables, by chains (segments) of vowels-consonants
We confine ourselves to a superficial review, leaving the nuances for an independent post. The most famous and easiest way is transliteration using letter- by- letter rules . There are several standards for the translation between Latin and Cyrillic, most are one-to-one (completely or for almost all letters). Unfortunately, this method gives a very poor quality for the names - even Renault and Pegueot will never become Renault and Peugeot.
A more advanced way is by syllables . The translation of each syllable, regardless of context, works fairly accurately. But there are difficulties:
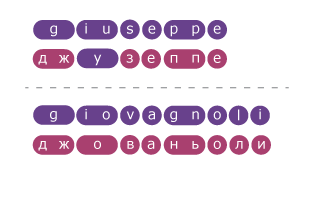
We have chosen the third path, the partitioning method. A segment is a group of consecutive vowels / consonants. We need to find a large number of examples of pairs of words, when we reliably know that one is a transcription of the other. And by these examples, using machine learning, build rules for converting some segments into others.
Here is how it works. For each pair of the training sample, the words are divided into segments. For each example of correct transcription between the segments of the original word and its transcription, a correspondence is established - it turns out that in almost all cases the number of segments in the Russian and foreign words is equal.
Further, the transcription segments with the corresponding segments of the original enter the training sample: both by themselves and with the surrounding context (neighboring segments). As a result, machine learning determines the probabilities of different transcription variants of each segment:
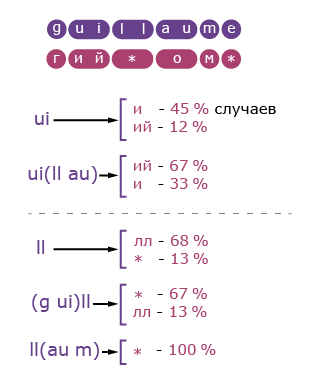
In our experience, the segment method gives the best accuracy. It works well for all common languages - including such as complex as Chinese and Vietnamese (of course, in their letter writing). And even allows with acceptable accuracy to restore from the Russian writing in the original language. The method does not require the definition of the language of the word.
On test collections of names, surnames, place names, popular brands and names of musical groups, the method shows accuracy up to 99%. If, however, we evaluate the accuracy of the entire set of hypotheses that are expanded according to real queries and the search index, it falls as we increase the dictionary with less and less accurate hypotheses. Now users have access to about 3 million extensions based on transliteration, their accuracy is about 90%.
Implementation options
We confine ourselves to a superficial review, leaving the nuances for an independent post. The most famous and easiest way is transliteration using letter- by- letter rules . There are several standards for the translation between Latin and Cyrillic, most are one-to-one (completely or for almost all letters). Unfortunately, this method gives a very poor quality for the names - even Renault and Pegueot will never become Renault and Peugeot.A more advanced way is by syllables . The translation of each syllable, regardless of context, works fairly accurately. But there are difficulties:
- Each language has its own rules for dividing into syllables, and their implementation with sufficiently high accuracy is non-trivial.
- The same syllables are also pronounced differently in different languages, therefore for each language it is necessary to thoroughly describe the rules.
- For these reasons, it is especially important to accurately determine the language.
Segment method
We have chosen the third path, the partitioning method. A segment is a group of consecutive vowels / consonants. We need to find a large number of examples of pairs of words, when we reliably know that one is a transcription of the other. And by these examples, using machine learning, build rules for converting some segments into others.
Here is how it works. For each pair of the training sample, the words are divided into segments. For each example of correct transcription between the segments of the original word and its transcription, a correspondence is established - it turns out that in almost all cases the number of segments in the Russian and foreign words is equal.
Further, the transcription segments with the corresponding segments of the original enter the training sample: both by themselves and with the surrounding context (neighboring segments). As a result, machine learning determines the probabilities of different transcription variants of each segment:
About segment ambiguity There are a couple of tricks, because of which the segments may not be one-to-one. The first is simple: some words begin with unpronounceable consonants, like “L'Humanite”> “L'Humanite”. Such segments are converted to empty. The second is more complicated: in the middle of the word there are “quick” vowels (as in “stat e ment” the highlighted “e” is not read) or consonants (as in the “guillaume” above). Aligning to segments with fluent letters with the help of Lowenstein's algorithm helps: first we establish letter-by-letter correspondence, and then we glue adjacent letters into segments, taking into account the differences in word splitting in another language.
From this example, it is clear that the “d” is more correctly considered a vowel. We consider consonants “”, “”, hyphen and apostrophe - because they break the sound.
There are a couple of tricks, because of which the segments may not be one-to-one. The first is simple: some words begin with unpronounceable consonants, like “L'Humanite”> “L'Humanite”. Such segments are converted to empty. The second is more complicated: in the middle of the word there are “quick” vowels (as in “stat e ment” the highlighted “e” is not read) or consonants (as in the “guillaume” above). Aligning to segments with fluent letters with the help of Lowenstein's algorithm helps: first we establish letter-by-letter correspondence, and then we glue adjacent letters into segments, taking into account the differences in word splitting in another language.From this example, it is clear that the “d” is more correctly considered a vowel. We consider consonants “”, “”, hyphen and apostrophe - because they break the sound.
About quality
In our experience, the segment method gives the best accuracy. It works well for all common languages - including such as complex as Chinese and Vietnamese (of course, in their letter writing). And even allows with acceptable accuracy to restore from the Russian writing in the original language. The method does not require the definition of the language of the word.
On test collections of names, surnames, place names, popular brands and names of musical groups, the method shows accuracy up to 99%. If, however, we evaluate the accuracy of the entire set of hypotheses that are expanded according to real queries and the search index, it falls as we increase the dictionary with less and less accurate hypotheses. Now users have access to about 3 million extensions based on transliteration, their accuracy is about 90%.
Spelling options (ike i → ike a )
Orfarifariate are words that have identical meaning, but they can be written this way and that, and both spellings are considered literate.
Firstly, these are foreign words that are recorded by the ear and often do not have a single canonical spelling (“ike i ” / “ike a ”; “ interpret n” / “sense and n”).
35 ways to write Scarlett Johansson
"Scarlett Johansson"
Scarlett Johanson
Scarlett Johansson
"Scarlett Johansson"
"Scarlett Johansson"
"Scarlett Johanson"
"Scarlett Johonson"
"Scarlett Johanson"
"Scarlett Johannson"
Scarelt Johansson
"Scarlett Johansson"
"Scarlett Yohhanson"
"Scarlett Johansen"
Scarlett Yohansson
"Scarlett Johannson"
"Scarlett Johansan"
"Scarlett Johanson"
Scarlett Johanson
Scartlett Johansson
Scarlett Johansson
"Scarlett Johasson"
"Scarlett Johansen"
"Scarlet Oahsen"
"Scarlet Öhsensen"
"Scarlett Johanson"
"Scarlett Yohansan"
"Scarlett Johansson"
"Scarlett Johansson"
Scarlet Johansson
"Scarlet Yohnson"
"Scarlet Ehanson"
Scarlet Ohansan
Scarlett Johansson
Scarlett Johanson
Scarlett Johansson
Scarlett Johanson
Scarlett Johansson
"Scarlett Johansson"
"Scarlett Johansson"
"Scarlett Johanson"
"Scarlett Johonson"
"Scarlett Johanson"
"Scarlett Johannson"
Scarelt Johansson
"Scarlett Johansson"
"Scarlett Yohhanson"
"Scarlett Johansen"
Scarlett Yohansson
"Scarlett Johannson"
"Scarlett Johansan"
"Scarlett Johanson"
Scarlett Johanson
Scartlett Johansson
Scarlett Johansson
"Scarlett Johasson"
"Scarlett Johansen"
"Scarlet Oahsen"
"Scarlet Öhsensen"
"Scarlett Johanson"
"Scarlett Yohansan"
"Scarlett Johansson"
"Scarlett Johansson"
Scarlet Johansson
"Scarlet Yohnson"
"Scarlet Ehanson"
Scarlet Ohansan
Scarlett Johansson
Scarlett Johanson
Scarlett Johansson
Unlike transliteration, here we are dealing with pairs in the same language. A few words that with the help of transcription can lead to one Latin spelling are called orthophants.
Secondly, Russian words that admit different spellings (“ bild rd” → “bill iard rd”, “birthday and i” → “birthday i ”)
What is interesting orfovariant?
It is necessary to distinguish them from typos and padonkaffsky slang. And there is also an outdated spelling.
Fortunately, the slang has a rather specific context of use, it helps to distinguish it from orphars.
The third type stands out by itself - an outdated spelling : “great-power”, “pious” (for example, “king”). Thanks to the extensions, there are both original Old Russian texts with a parallel translation into the modern language, and the translations themselves without the original - the latter is easier for the unprepared reader to print and read.
- It is necessary to clearly separate them with typos:
- for typos, the user is used to seeing the explicit message: “A typo was corrected in the request” and be able to switch to the search for the original request. For orfovariant such a warning would be inappropriate, because all possible spellings are valid.
- when we are sure that the user is sealed, we simply replace the request with the correct one. For orfovariant can not do so, we will lose most of the useful documents with a different spelling ("birth" instead of "birth"). But to expand other spellings will be correct. Unlike typos - there are illiterate documents can upset the user who asked the request without errors.
- It is important to be able to distinguish orthophyrians from Internet slang ( “padonkaffsky / olbansky yezig” ) and memes (“kotegi”; “kote”). Slang and common spellings cannot be extended with each other:
- when requested with a meme, documents with commonly used spelling cannot be shown, they will interfere with the meme interested;
- and vice versa, if you add his analogue memes to the commonly used spelling, it will worsen the issue on requests for “universal” topics.
Fortunately, the slang has a rather specific context of use, it helps to distinguish it from orphars.
The third type stands out by itself - an outdated spelling : “great-power”, “pious” (for example, “king”). Thanks to the extensions, there are both original Old Russian texts with a parallel translation into the modern language, and the translations themselves without the original - the latter is easier for the unprepared reader to print and read.
Word Formation (Moscow-Moscow)
The types of extensions described above (abbreviations, transliteration, inflection, or hyphenation) tried to reflect the exact words of the query in all possible ways, considering the meaning to be inviolable. But it quickly became clear that it was necessary to more boldly allow semantic additions to the original request. Thus, the extensions were supplemented by word formation (“Moscow subway” → “Moscow subway station”) and synonyms (“hippo” → “hippo”).
The idea of expanding on the principle of word formation is to add cognate words to the query, including even other parts of speech (“Moscow metro” → “Moscow Metro”).
The mechanism of word formation is often called simply morphology, although this is not quite true: in addition to the word education , morphology also includes the word change (the very same “Bric-Mulloy”). The word change rarely adds new semantic shades to the request, it usually looks for the original word of the request in all forms (as they say, “the whole paradigm ”), so in this post we will not touch it.
Word-formation, on the contrary, may add semantically distant variants — contrary to general considerations, words with one root need not be close in meaning. Only a small number of types of word formation is in practice a good search engine extensions, so you need to be careful.
A few examples Among the useful types are <noun> → <single-root adjective>, for example, “Moscow” → “Moscow”: “mayor of Moscow” → “Moscow mayor”. But even here there are subtleties, primarily related to named entities:
Couples <noun> → <name of the figure> (“bicycle” → “cyclist”) - strongly lead away from the meaning of the initial request. If <noun> → <adjective> “bicycle” → “cycling” is useful (for example, [buying a bicycle] → [bicycle shop]), then “cycling” → “cyclist” will make the search worse, because on request [buying a bicycle] extradition will be added, for example, documents about the "landing of the cyclist", about the "injuries of the cyclist", etc.
Similarly, there are a lot of bad examples for the change of gender. Take the “worker” → “worker”: if the request [agreement with the worker] gives a wide class of documents about any items of agreement, expanding it with the word “worker”, undesirable documents get into the issue, for example, about the regulatory framework for going on maternity leave (which in general, about any employee, most likely, will not help).
Thus, the similarity of words in form is often deceptive, and from the point of view of search, the content varies greatly even with the most seemingly innocent transformations.
Among the useful types are <noun> → <single-root adjective>, for example, “Moscow” → “Moscow”: “mayor of Moscow” → “Moscow mayor”. But even here there are subtleties, primarily related to named entities:- Names of organizations: [Moscow Department Store] ≠ [Moscow Department Store], these are two different stores in Moscow, both very well-known
- surnames of people: an official who works in the government may have the surname “Moscow” - and this will affect the query [Moscow government]
- geographical names: in Moscow there is a city "Moscow" - for him the query [Moscow mayor] means not the same as [mayor of Moscow]
Couples <noun> → <name of the figure> (“bicycle” → “cyclist”) - strongly lead away from the meaning of the initial request. If <noun> → <adjective> “bicycle” → “cycling” is useful (for example, [buying a bicycle] → [bicycle shop]), then “cycling” → “cyclist” will make the search worse, because on request [buying a bicycle] extradition will be added, for example, documents about the "landing of the cyclist", about the "injuries of the cyclist", etc.
- [drawing class]: good to expand with the word “draw”, but bad “draftsman”
- [deputy commander for rear]: good "rear", bad "rear man"
- [order floss in Ukraine]: good "order", bad "customer"
Similarly, there are a lot of bad examples for the change of gender. Take the “worker” → “worker”: if the request [agreement with the worker] gives a wide class of documents about any items of agreement, expanding it with the word “worker”, undesirable documents get into the issue, for example, about the regulatory framework for going on maternity leave (which in general, about any employee, most likely, will not help).
Thus, the similarity of words in form is often deceptive, and from the point of view of search, the content varies greatly even with the most seemingly innocent transformations.
In other languages, everything is different
It is curious that the Russian language is far from always the most difficult from the point of view of word formation. For example, in Turkish, single-root words with a formally different meaning are simply part of one vocabulary paradigm:
And if in Russian we can safely use all the forms of the word for which we prepared the extension, then in Turkish we have to calculate contextual proximity not between different words, but between the forms of the same word. And limit the use of distant forms of the same word to prevent distortion of meaning.
- "Yüz" - one hundred, "yüzde" - percent,
- “Top” - a ball / core, “topçu” - a footballer / gunner.
And if in Russian we can safely use all the forms of the word for which we prepared the extension, then in Turkish we have to calculate contextual proximity not between different words, but between the forms of the same word. And limit the use of distant forms of the same word to prevent distortion of meaning.
Synonyms (mobile → cellular)
Is it possible to base academic synonyms from traditional dictionaries, and just load them into the search? Indeed, in the dictionaries collected extensive rows of reliable synonyms.
It turns out that the search language is completely different from the standard written language. Often dictionaries give exact synonyms, but supply them with stylistic mark: arch. rass , scientific the poet And some words, even being modern and, formally, commonly used, are used in written language only in some senses or genres:
Often dictionaries give exact synonyms, but supply them with stylistic mark: arch. rass , scientific the poet And some words, even being modern and, formally, commonly used, are used in written language only in some senses or genres:- "Magician" → "sorcerer": the second is used mainly in folklore texts, and only in a negative way
- “Entrance” → “front door”: the second one is not used in official addresses; limits the range of documents to the Petersburg region - by origin or place of action.
- "Doctor" → "doctor": the second is used primarily for the profile of education, but not to denote the profession or type of service
- "Trainer" → "tamer": the second deals only with dangerous animals
As a result, a person will receive documents with a pronounced stylistics (archaic / scientific / dialectal ...) than he wanted - which will not always be useful in solving his problems.
Therefore, we have gone from a purely vocabulary, linguistic understanding of synonyms, the statistical search for equivalents works much better. Any options are collected that may not be synonymous in an academic sense, but help to find what the user is looking for. This is the main criterion of quality - the usefulness of extensions for ranking (and not their dictionary affinity by meaning).
But collections of statistically collected synonyms in the traditional sense (as words with identical meaning) are few. For narrowly specific queries, on which there is very little information on the Internet, it is useful to replace some words of the query with more general concepts ( “hyper-names” ).
An example of a common replacement; why it is impossible to replace the general with the private For example, the query [conjunctivitis in miniature schnauzers]: the word "miniature schnauzer" has a very precise synonym for "miniature", but adding it will not greatly improve the output. But if you add his generalization as an extension, [conjunctivitis in dogs], there are many useful things, because the care and treatment procedures are similar for different breeds of dogs.
And in the opposite direction, from the general to the particular, to expand is risky. By requesting [clothes for children], different users are looking for stores for different ages, so it would be more correct to show the most versatile sites covering the whole possible range of different situations of the user. If we try to expand the request with more specific concepts of “schoolchild” or “infant”, this may complicate the user to solve his problem.
For example, the query [conjunctivitis in miniature schnauzers]: the word "miniature schnauzer" has a very precise synonym for "miniature", but adding it will not greatly improve the output. But if you add his generalization as an extension, [conjunctivitis in dogs], there are many useful things, because the care and treatment procedures are similar for different breeds of dogs.And in the opposite direction, from the general to the particular, to expand is risky. By requesting [clothes for children], different users are looking for stores for different ages, so it would be more correct to show the most versatile sites covering the whole possible range of different situations of the user. If we try to expand the request with more specific concepts of “schoolchild” or “infant”, this may complicate the user to solve his problem.
How to build extension options
In the next section, the most interesting is how extensions are used in the search, but first let's look at how we prepare extension hypotheses.
From the above, it is easy to guess that the options for possible extensions for our needs can be built only through the analysis of real data that exists “in the wild” on the Internet. It is necessary to respond to a user's request quickly, so we prepare such options (the so-called "extension dictionary") in advance — and at the time of the search, we simply select all the pairs for the query words from the ready dictionary.
Collecting hypotheses
To compile a dictionary, we use a number of sources:
- brackets in documents: “Scarlett Johansson (Scarlett Johansson)”
- the occurrence of both words in the same contexts ( N-grams - chains of N consecutive words: "... theater tickets": "price" → "cost") - separately in the texts, separately in the queries. It is sometimes called “interchangeability statistics”.
- reference - when several links leading to the same page are called differently: “bike shop → bicycle shop”
- parallel texts (marked up with machine alignment)
Our machine translation service is trained in so-called parallel texts - “text and its translation” pairs, between which the correspondence of sentences, phrases, and words meaning the same is marked by statistical methods. We consider such a transition of one word to another as a good hypothesis for expanding a query. - user statistics - how often the user tries to reformulate the query using this replacement, and documents with which synonyms to the query word prefers
- traditional synonym dictionaries, other dictionary sources
- Wikipedia: For what term is redirection to another term?
For the Russian language, this gives about 150 million pairs of extension hypotheses.
Frequency filtering
Couples that are found too rarely both in queries and in texts on the Internet are not a very reliable source, therefore, after collecting hypotheses, we limit them by frequency of occurrence.
It makes little sense to somehow take into account the form (case, declension) in which the word came together with one or another couple (at least for the Russian language). Therefore, we leave the only form of the word (as a rule, the initial one).
As a result, this usually results in about 100 million pairs.
Selection of the most likely extensions
But 100 million raw hypotheses are ore, which cannot simply be given to the request processing stage.
There is no point in helping high-frequency queries; it is necessary to exclude distant substitutions
Like so much more in this topic, the degree of closeness is calculated by machine learning.
On the one hand, for each hypothesis of extension (A, B) we calculate about 60 factors, which somehow correlate with the fact that the hypothesis is a useful extension. Among these factors is contextual proximity, built on N-grams; user selection of the same documents for different requests; Levenshtein distance (for example, for orfovariant).
On the other hand, special experts ( assessors ) prepare a training sample of characteristic examples “which word B is a good extension of the word A, and which pairs cannot be considered synonymous."
Preparing a training set is a difficult task, the quality of the final dictionary directly depends on its solution. Even experienced assessors often differ in evaluating extensions. Assessors have to think not only about the closeness of words in terms of language, but also to predict how a particular pair will affect the usefulness of issuing requests in the whole segment.
- We select extensions that are most helpful to the user. The value of extensions directly depends on the frequency of the request. For high-frequency queries we have a lot of different data, and adding even a large number of extensions practically does not change the ranking. And in the case of rare requests or those formulated with an error, the contribution of extensions to improving the issue is very noticeable - we are trying to expand them first of all.
- Even for non-frequency requests, you need to balance the quality and speed of response to a request. Ideally, you need to expand any request with the widest possible cloud of extensions - and the ranking stage will choose exactly what really improves the issue relevance. In practice, the size of the cloud has to be limited for the sake of speed of response - by removing options that are far in meaning from the original.
Like so much more in this topic, the degree of closeness is calculated by machine learning.
On the one hand, for each hypothesis of extension (A, B) we calculate about 60 factors, which somehow correlate with the fact that the hypothesis is a useful extension. Among these factors is contextual proximity, built on N-grams; user selection of the same documents for different requests; Levenshtein distance (for example, for orfovariant).
On the other hand, special experts ( assessors ) prepare a training sample of characteristic examples “which word B is a good extension of the word A, and which pairs cannot be considered synonymous."
Preparing a training set is a difficult task, the quality of the final dictionary directly depends on its solution. Even experienced assessors often differ in evaluating extensions. Assessors have to think not only about the closeness of words in terms of language, but also to predict how a particular pair will affect the usefulness of issuing requests in the whole segment.
As a result of this selection, we get 10 million extensions - and this “dictionary” is used in processing requests. This is discussed in the next section.
How extensions are involved in the search
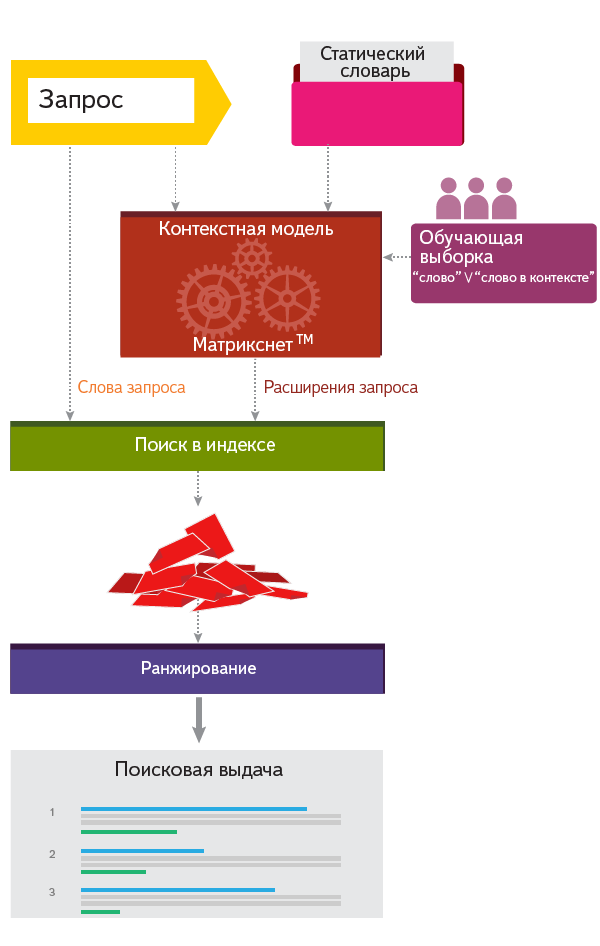
When we receive a search query from a user, we select extensions from the dictionary that are suitable for the context.
For example, [mgu] has expanded in [mgu ^ mgu ^ msu ^ "Moscow State University"].
And already by the advanced query, the search finds documents with different variants of the wording, including the original (“exact form”). A number of factors are involved in document ranking, taking into account both the original word and the extensions. Other things being equal, the coincidence of the exact form (“MGU”) takes precedence over the occurrence of an extension (even full writing, like the “Moscow State University”) - although other factors may turn out to be stronger than an exact match.
We try to highlight in the snippet not only the words of the request, but all the synonyms used, which helps the user to understand why he sees a particular document.
How to determine which extensions are relevant for a given request, and which are not; what exactly, in what cases and in what volume to add? The more types of extensions, the harder it is to build an algorithm for mixing them. , — . , : , . , 20% . « ».
, , 27% , .
, :
; ;
, , . , , . , .
, , . : , .
. , «» «», «Google» «», «» «Facebook» . , : «», « », «», «», «». (, ..), — .
, «» → «» , . , . For example:
( — )
, , : , .
, (, - «» → «» «» → « »), . , , . : , , .
, . , , ? . , [' ] [ ], .
— : ; , .
, : . , - , .
— . , , .
— . , . , «war k raft» — ( «War c raft»), - — ( [ ]) «» → «war k raft» , .
, «», «» «», .
,
, , . , - , ́ , , . , .
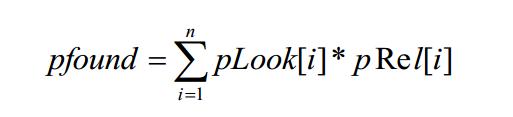
, , . — . , , . 30% , 15% — .
Literature
- , . , 2010 ().
- Voorhees, Query Expansion using Lexical-Semantic Relations — TREC WordNet.
- Jones et al. Generating Query Suggestions — Yahoo! .
- Dang, Xue, Croft. Context-based Quasi-Synonym Extraction — N- (, ).
- Dang, Croft. Query Reformulation Using Anchor Text — Microsoft Research.
- R.S. , .. . . ., , 1985 — .
Source: https://habr.com/ru/post/187404/
All Articles