Development of IntelliJ IDEA plugin. Part 4
Finally we got to the very pulp, in this part - lexical and syntactic analysis, PSI (Program Structure Interface), stubs (Stubs). Previous parts: 1 , 2 , 3
IntelliJ IDEA is not only a Java IDE, but also a powerful platform for building development tools for any language. Most IDEA functions consist of two parts: language independent and language-specific. Therefore, the support of features of any language does not require much effort - it is necessary to implement only a specific part, and language independent is provided by the platform. In addition, IDEA provides a powerful framework that allows you to implement your own functions that are required when developing a toolkit.
File Type Registration
The first step in developing a specific language plug-in is to register the associated file type. Typically, IDEA defines a file type according to its name (extension).
The file type of a specific language is a class inherited from LanguageFileType, which passes an instance of the Language class to the parent constructor. To register a file type, you must provide an implementation of the FileTypeFactory interface, registered at the extension point com.intellij.fileTypeFactory:
<extensions defaultExtensionNs="com.intellij"> … <fileTypeFactory implementation="com.intellij.lang.properties.PropertiesFileTypeFactory"/> … </extensions> An example implementation of the LanguageFileType class in the Properties plugin.
To verify the registration is correct, you should make sure that the icon displayed next to the files with the extension associated with the user-defined file type matches the icon defined in the getIcon () method.
')
Implementing a lexical analyzer
A lexer (lexical analyzer) determines how the contents of a file will be divided into a sequence of tokens. Lexer serves as the foundation for almost all functions of language plug-ins, starting with syntax highlighting and ending with code analysis functions. The lexer API is defined in the Lexer interface.
IDEA calls the lexer in three main contexts and the plugin must provide an implementation for each of them:
- syntax highlighting - the lexer must be returned by the implementation of the SyntaxHighlighterFactory interface registered at the expansion point com.intellij.lang.syntaxHighlighterFactory;
- building an abstract syntax tree — the lexer must be returned from the ParserDefinition.createLexer () method, the implementation of the ParserDefinition interface must be defined at the com.intellij.lang.parserDefinition extension point;
- building an index of the words contained in the file — if the scanner implementation is used based on the user lexer, it is passed as an argument to the constructor of the DefaultWordsScanner class.
The lexer used for syntax highlighting may be called incrementally, to process only the changed part of the file. In other cases, lexers are invoked to process a file as a whole, or a complete language construct embedded in a file of another type.
The incrementally called lexer must return its current state, i.e. context corresponding to each position in the file. An important requirement for syntax highlighting is the representation of the state by a regular number (returned from the Lexer.getState () method). This state will be passed to the Lexer.start () method along with the starting fragment offset for processing when it is necessary to continue the lexical parsing in the middle of the file. Lexers in other contexts can simply return 0.
To simplify the creation of a lexical analyzer of a specific programming language, you can use a lexer generator, such as JFlex. IDEA includes adapter classes (FlexLexer and FlexAdapter) that adapt JFlex lexers to the IDEA lexical API. The Intellij IDEA Community Edition source codes contain a modified version of JFlex 1.4.1 and a lexer procurement file that can be used in the development of FlexAdapter compatible lexers. A modified version of JFlex provides a new command line option
--charat , which modifies the generated code so that it works with IDEA (which requires CharSequence instead of an array of characters).To facilitate the development of lexers using JFlex, there is a plugin that provides syntax highlighting and other useful features.
Example: lexer from the Properties plugin.
It must be remembered that lexers, including those based on JFlex, must parse the entire file, without any gaps between tokens, i.e. in case of detection of invalid characters, they should be assigned the type of token reserved for such cases -
TokenType.BAD_CHARACTER . And, moreover, the lexer should not interrupt its work until the end of the parsing.The types of tokens in IDEA are defined as instances of the IElementType class. Some types of tokens common to most languages are defined in the TokenType interface. Custom plugins should reuse them in their lexer implementations. The remaining types of tokens should be associated with self-created objects of the IElementType class. The same IElementType instances must be returned each time the lexer parses the corresponding token.
Example: types of tokens used in the Properties language.
An important feature that can be implemented at the lexer level is the mixing of languages within a file (for example, embedded Java code fragments in a file with a template). If the language supports embedding of fragments, they should be defined as “chameleon” tokens, different for different types of fragments, and the type of token should implement the ILazyParseableElementType interface. To parse a fragment, IDEA will call the parser of the corresponding language by calling the ILazyParseableElementType.parseContents () method.
Parsing and PSI
Parsing in IntelliJ IDEA takes place in two steps. The first one builds an abstract syntax tree, which defines the structure of the program. The AST nodes, represented by instances of the ASTNode class, are created by IDEA itself. Each node has an associated element type (as an object of type IElementType), which is determined by the plugin. The top-level AST node representing the file must have a special element type that implements the IFileElementType interface.
AST nodes have a direct mapping to the text ranges of the underlying document (the leaf tokens are mapped to specific tokens returned by the lexer, higher-level nodes contain fragments of several tokens).
Operations performed on AST nodes (insert, delete, reorder, etc.) are immediately reflected as changes to the text of the underlying document.
In the second step, PSI (Program Structure Interface) is created on the basis of an abstract syntax tree, adding semantics and methods for manipulating specific language constructs. PSI nodes are represented by classes that implement the PsiElement interface; they are created using the ParserDefinition.createElement () method. The root node of the PSI tree must implement the PsiFile interface and be created in the ParserDefinition.createFile () method.
Example: ParserDefinition for the Properties plugin.
The base classes for implementing PSI elements (PsiFileBase, based on PsiFile, ASTWrapperPsiElement, based on PsiElement) are provided by IntelliJ IDEA itself, i.e. contained in the internal implementation. Therefore, when developing plugins for version 10.5 and earlier, you need to make sure that idea.jar is in the classpath. In newer versions (starting from 11.0) it is added to the classpath automatically.
Parser implementation
IntelliJ IDEA does not provide the ability to use ready-made grammars of programming languages (such as ANTLR) to create syntax analyzers in custom plugins. But the parser and PSI classes can be generated using the Grammar-Kit plugin. In addition to generating code, it provides other options for editing grammars: syntax highlighting, navigation, refactoring, and more.
The createParser () method of the ParserDefinition class in the language plugin should provide a parser that implements the PsiParser interface. The parser gets an instance of the PsiBuilder class, which is used to get a stream of tokens from the lexer and create an intermediate representation of AST. The parser is required to process each token to the end of the sequence (until PsiBuilder.getTokenType () returns null), even if the tokens do not match the syntax of the language.
During the work, the parser installs pairs of markers (objects of the PsiBuilder.Marker class) and tokens received from the lexer. Each pair of markers defines a range of tokens related to each node of an abstract syntax tree. If a pair of markers is nested in another pair, it becomes a child of the outer pair.
The element type for the marker pair (and for the AST node created on the basis of it) is determined when the end marker is set (the PsiBuilder.Marker.done () method was called). It is also possible to reset the initial marker, before setting the final one. The drop () method only resets one initial marker and does not affect the rest set later. The rollbackTo () method resets the initial marker and all set after it, returning the position of the lexer to the beginning of the starting marker. These methods can be used to implement a lookahead on parsing.
The PsiBuilder.marker.precede () method is useful for parsing from the right to the left, when it is unknown how many markers you need to a certain position before reading the next token. For example, the binary expression a + b + c should be parsed as ((a + b) + c). Thus, two starting markers are needed at the position of the token “a”, but this is unknown until the “c” token is read. When the parser reaches the “+” token following “b”, it can call precede () to duplicate the start marker in position “a” and then place the final marker in position behind “c”.
Another important feature of PsiBuilder is the preservation of whitespace and comments. The types of tokens that are treated as spaces and comments are defined in the getWhitespaceTokens () and getCommentTokens () methods in the ParserDefinition class. PsiBuilder automatically skips tokens of spaces and comments in the sequence, which is transmitted to PsiParser and adjusts the token ranges in the AST nodes so that the starting and ending spaces do not fall into the node.
The set of tokens returned by the ParserDefinition.getCommentTokens () method is also used to find TO DO items.
In order to better understand the process of building the PSI tree, for a simple expression, you can refer to the following diagram in the figure below.
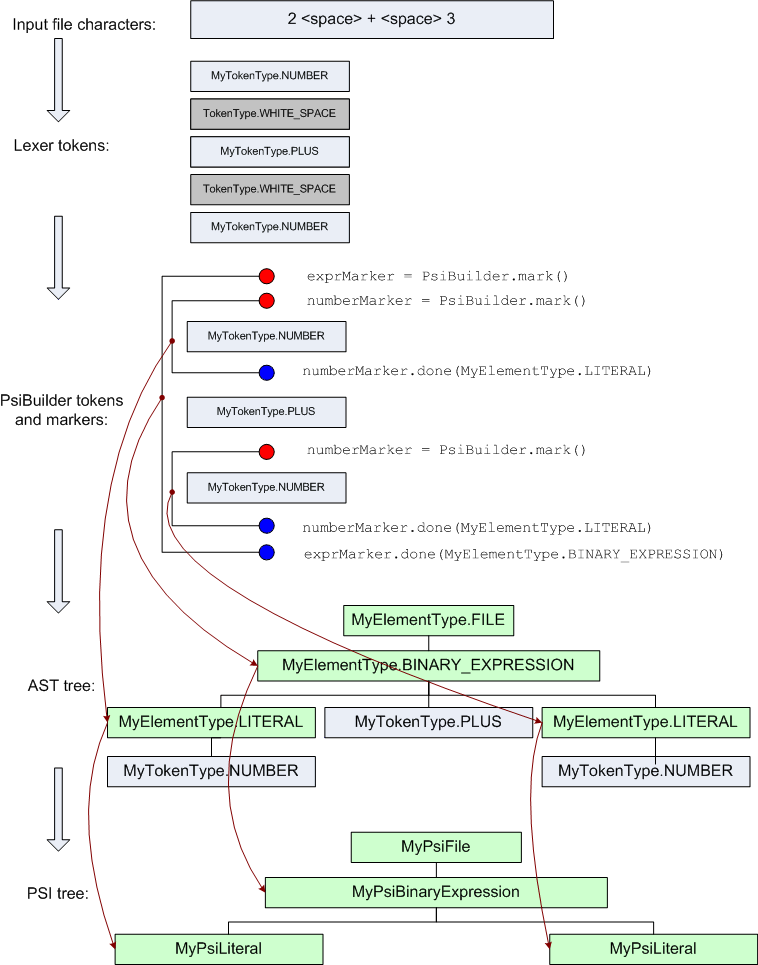
There is no single correct way to implement PSI in a user plugin, i.e. You can choose the PSI structure and a set of methods that are most convenient for the implementation of language features (error analysis, refactoring, etc.). However, there is one basic interface that must be used in the language plugin in order to implement support for functions such as renaming and searching for uses. Each element that can be renamed or have links (for example, the definition of a class, method, etc.) must implement the PsiNamedElement interface, with the methods setName (), getName ().
A number of functions that can be used to implement and use PSI can be found in the com.intellij.psi.util package, in particular the classes PsiUtil, PsiTreeUtil.
One of the extremely useful tools for debugging a PSI implementation is the PsiViewer plugin. He is able to show the PSI structure built by the user plugin, the properties of each element and the highlighting of text ranges associated with PSI elements.
Indexing and stubs
The IntelliJ IDEA Indexing Framework provides a way to quickly search for specific elements (for example, files containing certain words or methods with a given name) in extensive code bases. Developers can use existing indexes built into IDEA itself, as well as their own.
IDEA supports two main types of indices: file-based and stub indexes. File indices are built on top of the contents of the files, and stub indexes are built on the basis of serialized stub trees. The stub tree for a source file is a subset of its PSI tree, which contains only externally visible definitions, serialized in a compact binary format. By requesting file indices, the plugin receives a set consisting of files that fall under a given condition, in turn, stub indexes work directly with PSI elements. Therefore, language plugin developers should prefer stub indexes.
File Indexes
File indices in IntelliJ IDEA are based on the map / reduce architecture. Each index has certain types of keys and values. Keys are used in extracting data from an index, for example, in a word index, the key is a string containing a word. The key value in the index can be any information, for example, in the index of words it can be a mask that defines the context in which the word is located (code, literal, comment). In the simplest case (when you only need to determine which file contains the data), the value is of type void and is not stored in the index.
After indexing the file, the index returns a table of keys and their associated values. When accessing an index using a specific key, it returns a list of files and data associated with that key.
File Index Implementation
For better understanding, let us give an example of a fairly simple implementation of a file index, namely the index of the form boundaries used in the UI Designer.
Each specific index implementation inherits the FileBasedIndexExtension class and must be registered at the extension point.
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().. :
getIndexer() - , /, ; getKeyDescriptor() - , . - EnumeratorStringDescriptor ( ); getValueExternalizer() - , ; getInputFilter() - ; getVersion() - . , .
, ScalarIndexExtension.
, , DataIndexer.map() , , - . , , .
FileBasedIndex, :
getAllKeys() processAllKeys() - , , . , , , . getValues() - , ( , ); getContainingFiles() - , ; processValues() - , .
, IDEA . , . , PsiSearchHelper. - FilenameIndex, . FileTypeIndex - .
, PSI-, .
PSI- AST (.. ), stub- ( ), .
Stub- ( , , ). , , , PSI- AST.
Bean- , PSI- (, , ..). .
, PSI- . , , , .
, , :
, StubElement (); (); , PSI- StubBasedPsiElement (); , PSI- StubBasedPsiElementBase (). : ASTNode, - ; , IStubElementType PSI- (). createPsi() createStub(), serialize() deserialize() ; , IStubElementType (); , PSI- , PSI- (: Property.getKey()).
, :
( ParserDefinition.getFileNodeType()) , IStubFileElementType; plugin.xml, , IElementType, ().
Source: https://habr.com/ru/post/187224/
All Articles