New look at site search

Introducing the project indexisto.com - search for sites and mobile applications.
Project in alpha, please treat with understanding (press gently). Test delivery now on the English content of musical subjects. We also really need early adopters, if you are interested in the search, write LS.
Chronicles
The story began a couple of years ago when I moved from Windows to Ubuntu, and then continued with the move to Mac. Such a move could give rise to a dozen stories, but I had one - I suddenly began to use the search on the operating system as the main navigation tool.
')
In both systems, the search is deeply integrated, categorized (files, programs ..), works very quickly and has a number of nice features, such as the inclusion of previously entered queries in the results of the issue. Over time, the search learned to understand me from the first letter entered.
I also began to notice many other scenarios, when the search saves a lot of time. Search for “settings” in Chrome, search for contacts on Skype, go to a person through a search on Facebook, hint the URL in the address bar of Firefox, taking into account the frequency of visits to sites ...
At the same time, the search situation on sites in 99% of cases is depressing. One gets the feeling that no one takes the search string seriously and does not spend time thinking. Yes, yes, and on Habré too.
From this all started)
Training
Putting together a team of like-minded people, we decided that the situation with the “dead” search line on sites can be radically changed)
We started by looking for examples of good and bad search. By accessing the new site, we first looked at how the search works. As a result, somewhere in half a year, requirements for the search line began to emerge, which were influenced by Windows 8 (pleasant feeling), new.myspace.com (boldness), Vkontakte (speed and local searches throughout the service) and many other smaller ones.
An example of a "revolutionary" search with the overlap of the main screen on new.myspace.com

User requirements
There are requirements that you need to search the user:
- performance, talking about tens of milliseconds from query to result
- minimum of extra clicks, instant search and switching to the desired one immediately from the drop-down results
- convenience. If a person got to the search line, do not clamp it in the closest way 100px wide.
- the ability to quickly set up two search lines on the page - one global across the site, the second for the current section
- additional parameters when searching: categories, facets (tags), sorting
- smart search. It must be remembered that the person was looking for earlier, where other people click in the output, etc.
- very smart search. The possibility of "semi-semantic" requests, for example, "big red sofas"
With the first points we think we did, with the last two we think that in the process)
Requirements from the programmer / administrator:
It is necessary to take into account that the majority of site owners treat search without much enthusiasm, and allocate time for programmers according to the residual principle.
- integration like google site search - pasted js and works. Despite the presence of high-level search servers such as Solr, Sphinx, even the simplest setup will take time, not to mention the many fine parameters with the names dis_max, tie_breaker, cutoff_frequency, slop, etc.
- less to climb into the console, read the logs, catch slow queries.
- if the manager asks “what are people looking for us” would not have to do samopisny statistics in panic
- Avoid double work if the task comes in a couple more searches.
Here, not on all points we managed to achieve the desired, in particular, our search is more complicated than Google Site Search, but simpler than Solr, Sphinx
As a result, http://indexisto.com was born
What is indexisto?
- This is a full-text search in the cloud. The project was made using Lucene and Elastic Search technologies and is written entirely in Java.
- No need to install, configure and monitor the full-text search server like Sphinx, Solr
- Import data directly from the database. For this purpose, for example, a PHP agent is put, which, according to our push, performs queries such as SELECT title, body FROM posts ... In the database, you must create a user with read-only rights and only to certain tables. The request is signed with a secret key.
- Ready-made quick search JS string with many features (widgets, facets, histograms, sorting). Asynchronous insert, 50kb.
- Pictures are pumped out and cling to the machine. Then they can be inserted into the issue template.
- Convenient admin where requests for data retrieval are specified, string is configured, queries
- Search reports, logs, import reports
Administo Indexisto:
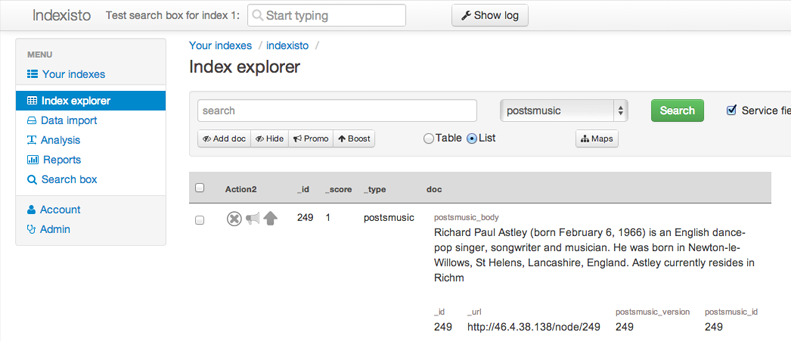
Now Indexisto is a full-text search, in the cloud with a comfortable admin panel. In the process, we solved many tasks that make life easier for the administrator. For example, you can set up and experiment with search results for a long time in the admin panel, but on the website these changes will appear only after you click the Activate search box. This is very useful for any changes.
You can easily clone the index settings and make another issue, for example, by subsection. There are invisible but complex problems that we solved. For example, in Elastic Search, you cannot just take and change the String field to the Int field in an already indexed document type within one index, the mappings will be incompatible. We have solved this problem opaquely for the admin, a new index will be created, with a different internal name, and the external name will remain the same and all settings will be saved.
Moving toward smart search
Already, we count the clicks in the results of the issue, and in the near future it will be possible to adjust the output boost by user behavior and search by previously found.
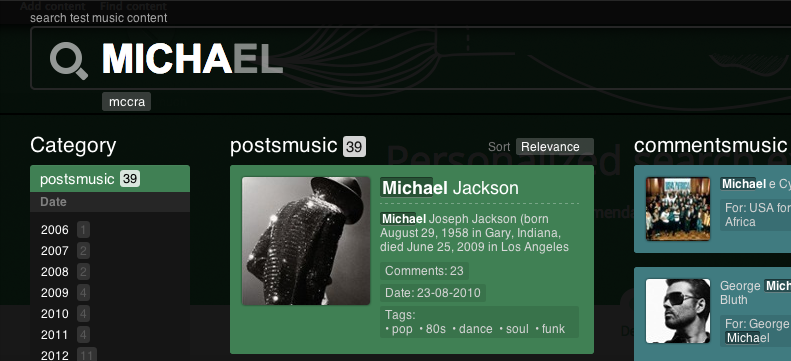
Another interesting feature is the “semi-semantic search”. Since we are taking data directly from the database, you can do some pretty interesting things. For example, index tags into text fields. On the example of our issue, try dialing DISCO 80. You will see the relevant groups that played disco in the 80s:

This is certainly not rocket science, but you can do more interesting things, for example, when indexing a product:
- Product Name: Sofa "Svetlana 5" t
- product type: sofa
- price: 7000 rub
- color: red
- length: 2400mm
You can write the rules:
- if length> 2000mm add synonyms: GREAT, HUGE, LONG
- if the price <10000rub add synonyms: CHEAP, DISCOUNT, SALE
this way we will get a “semi-semantic” search, we will have queries like:
- BIG CHEAP SOFA
- CHEAP RED SOFA
Moving towards even smarter search
I do not know how much they follow projects like Freebase, Dbpedia and other attempts to structure information, but there are some moves that can be freely used for your own benefit. If you do not go into details, you can extract structured information.
If you trade in operating systems and you have a Microsoft Windows product, you can enrich the description with a lot of additional data that can generally be found in the right column of Wikipedia:

Thus the request will work for you:
OS FOR ARM
Now the project is in active development, but we are ready to connect basic adopters for free to early adopters,
write to
Source: https://habr.com/ru/post/185966/
All Articles