Find similar projects on github
Hello friends!
GitHab is a great site. But imagine that you have found project A, and you want to find out what other similar projects exist. How to be?
It was with such inspiration that I sat down to disassemble the GitHub API. After a couple of weeks of free time, this is what happened:
')
For most projects there are a couple of really interesting offers. Here are some examples: angular.js , front end bookmarks , three.js
The main idea for building recommendations is “The developers who put an asterisk to this project, also put an asterisk ...”. And the details of the idea, its shortcomings and the link to the code - below.
Perhaps I should admit that I am not an expert in machine learning or building recommender systems. All that is described below - the result of experimental spear and great curiosity.
Idea to start
Let's analyze all project A followers, see what other projects they follow, and choose the most frequently repeated projects? Alas, this approach failed miserably: among the search results for recommendations, the most popular projects often come out on top, but not necessarily relevant to the current one. The whole GitHub is in love with Bootstrap - the most popular project for today.
How much does a total star weigh?
For example:
Project A - just 100 stars
Project B - just 200 stars
Project C - only 1000 stars
Suppose a hundred of the same developers put an asterisk on project A and B, and a hundred of the same developers put on an asterisk to project A and C. Which project B or C will be closer to project A? Obviously - B. Half of his followers follow Project A. Only 10% of C followers noticed Project A.
How can one generalize three variables into one similarity formula? I thought slowly and the idea to consider the percentage of total stars from the total number of stars of both projects did not come immediately:
The formula gives very good recommendations. As I found out later from Cameron Davidson , this formula was derived in 1946 by two nerds (this is not an attempt to offend anyone, they really were experts in botany): Sorensen and Dies .
API issues
Unfortunately, GitHub doesn’t have a bulk API that allows you to retrieve information about all project followers with a single request. To all inconveniences, a limit of 5,000 requests per hour makes project analysis unbearably long. Addi Osmani offered to limit his analysis to only a few hundred followers. Experimentally, if you choose a random 500 followers of the project - the result of the recommendations will not worsen.
The project similarity metric for random N followers of project A was rewritten as follows:
Such a formulation makes projects with approximately the same number of stars closer to each other and well eliminates noise from popular projects.
Unfortunately, even with N = 500, it takes about seven minutes to build an analysis of one project.
And what if all similar projects are calculated in advance?
The recommendation works well for projects with 200+ stars. But how many such projects on GitHub'e? As it turned out, a little more than seven thousand (at the time of writing the code was about 7 300).
Having written a spider to search for nicknames of all followers of popular repositories, I found about 457,115 unique users :). Now for each user you need to get his favorite projects. But how long can it take? Even with a very pessimistic estimate of 300 stars per follower, given the limit of 5,000 requests per hour, one would have to “dig” the github for 11 days without stopping.
11 days is not so much for a hobby, right? The task is well distributed, because if you have a good friend who is ready to share his token on the githaba, then you can cope in a week! That same evening, a spider appeared to collect favorite projects of followers.
Having fun rustling the net,from time to time often stumbling over bugs, two spiders gathered the necessary data for ... 4 days. As it turned out, on average, one github user gives 22 asterisks. Only 0.02% of users gave more than 600 stars. Therefore, if spiders work flawlessly, it would be possible to build the entire necessary base in a couple of days.
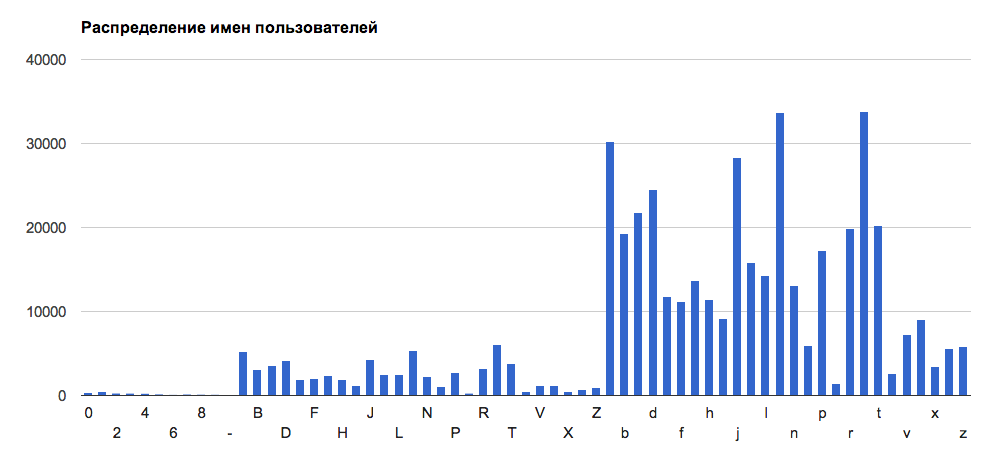
Useless fact
On GtHub, the most nicknames begin with the letter 's'. They are followed by users on 'm' and on 'a'. Nicknames on the capital 'Q' are less common than nicknames on the number 2:
Into the cloud
I uploaded the result of the spiders to S3 . All modern browsers recognize CORS, because with the usual ajax request you can get the necessary js file with recommendations. If the calculated recommendations for the project does not exist in the cloud, the site will go to the online construction of recommendations. Authenticate to get a larger quota. Intermediate data is stored in the local IndexedDB, so you can resume indexing even after the page is closed.
Code
If you, dear habrachitel, you know how to improve the recommendations - I am very pleased! The site code is available here: anvaka / gazer .
Put asterisks to the projects that you like - this makes it pleasant not only for the authors of the repositories, but also can help other developers to find the necessary projects :).
Thank you so much for reading to the end :)!
GitHab is a great site. But imagine that you have found project A, and you want to find out what other similar projects exist. How to be?
It was with such inspiration that I sat down to disassemble the GitHub API. After a couple of weeks of free time, this is what happened:
')
For most projects there are a couple of really interesting offers. Here are some examples: angular.js , front end bookmarks , three.js
The main idea for building recommendations is “The developers who put an asterisk to this project, also put an asterisk ...”. And the details of the idea, its shortcomings and the link to the code - below.
Perhaps I should admit that I am not an expert in machine learning or building recommender systems. All that is described below - the result of experimental spear and great curiosity.
Idea to start
Let's analyze all project A followers, see what other projects they follow, and choose the most frequently repeated projects? Alas, this approach failed miserably: among the search results for recommendations, the most popular projects often come out on top, but not necessarily relevant to the current one. The whole GitHub is in love with Bootstrap - the most popular project for today.
How much does a total star weigh?
For example:
Project A - just 100 stars
Project B - just 200 stars
Project C - only 1000 stars
Suppose a hundred of the same developers put an asterisk on project A and B, and a hundred of the same developers put on an asterisk to project A and C. Which project B or C will be closer to project A? Obviously - B. Half of his followers follow Project A. Only 10% of C followers noticed Project A.
How can one generalize three variables into one similarity formula? I thought slowly and the idea to consider the percentage of total stars from the total number of stars of both projects did not come immediately:
similarity = 2 * shared_stars_count / (project_a_stars + project_b_stars)The formula gives very good recommendations. As I found out later from Cameron Davidson , this formula was derived in 1946 by two nerds (this is not an attempt to offend anyone, they really were experts in botany): Sorensen and Dies .
API issues
Unfortunately, GitHub doesn’t have a bulk API that allows you to retrieve information about all project followers with a single request. To all inconveniences, a limit of 5,000 requests per hour makes project analysis unbearably long. Addi Osmani offered to limit his analysis to only a few hundred followers. Experimentally, if you choose a random 500 followers of the project - the result of the recommendations will not worsen.
The project similarity metric for random N followers of project A was rewritten as follows:
alpha = N/project_a_starssimilarity = 2 * N / (alpha * (N + project_b_stars))Such a formulation makes projects with approximately the same number of stars closer to each other and well eliminates noise from popular projects.
Unfortunately, even with N = 500, it takes about seven minutes to build an analysis of one project.
And what if all similar projects are calculated in advance?
The recommendation works well for projects with 200+ stars. But how many such projects on GitHub'e? As it turned out, a little more than seven thousand (at the time of writing the code was about 7 300).
Having written a spider to search for nicknames of all followers of popular repositories, I found about 457,115 unique users :). Now for each user you need to get his favorite projects. But how long can it take? Even with a very pessimistic estimate of 300 stars per follower, given the limit of 5,000 requests per hour, one would have to “dig” the github for 11 days without stopping.
11 days is not so much for a hobby, right? The task is well distributed, because if you have a good friend who is ready to share his token on the githaba, then you can cope in a week! That same evening, a spider appeared to collect favorite projects of followers.
Having fun rustling the net,
Useless fact
On GtHub, the most nicknames begin with the letter 's'. They are followed by users on 'm' and on 'a'. Nicknames on the capital 'Q' are less common than nicknames on the number 2:
Into the cloud
I uploaded the result of the spiders to S3 . All modern browsers recognize CORS, because with the usual ajax request you can get the necessary js file with recommendations. If the calculated recommendations for the project does not exist in the cloud, the site will go to the online construction of recommendations. Authenticate to get a larger quota. Intermediate data is stored in the local IndexedDB, so you can resume indexing even after the page is closed.
Code
If you, dear habrachitel, you know how to improve the recommendations - I am very pleased! The site code is available here: anvaka / gazer .
Put asterisks to the projects that you like - this makes it pleasant not only for the authors of the repositories, but also can help other developers to find the necessary projects :).
Thank you so much for reading to the end :)!
Source: https://habr.com/ru/post/185932/
All Articles