Archive Recursive. 7z: some file and archive Recursive. 7z
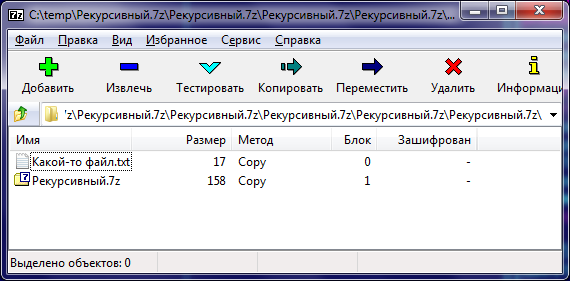 The format of 7-Zip archives is quite flexible and allows, for example, to include the entire archive as one of the files inside the archive itself, only a little reading. Let us analyze the format with an example: we will create an archive with the name “Recursive. 7z”, containing two files: “Some file.txt” with the contents “Hello, Habrahabr!” And “Recursive. 7z”, a copy of itself.
The format of 7-Zip archives is quite flexible and allows, for example, to include the entire archive as one of the files inside the archive itself, only a little reading. Let us analyze the format with an example: we will create an archive with the name “Recursive. 7z”, containing two files: “Some file.txt” with the contents “Hello, Habrahabr!” And “Recursive. 7z”, a copy of itself.Brief format documentation is included in the LZMA SDK . The archive begins with the following structure of 32 bytes. All positions within the archive are encoded as offsets relative to the end of this structure.
, 6 : { '7', 'z', 0xBC, 0xAF, 0x27, 0x1C }; , { Major, Minor }, 7-Zip 9.20 { 0, 3 }; CRC , 4 ; , 8 ; , 8 ; CRC , 4 . This is followed by the data files without any information about the files themselves and the boundaries of the data. The main title, which describes the entire contents of the archive, is placed at the end of the archive.
The main header can be packaged by itself (as well as encrypted). Since it contains structured data (such as file names), the compression ratio is quite good. It is for the possibility of such compression that all information about files in 7z is collected in one header and completely separated from the compressed data files. A sign of compaction is the first byte of the main header: it must be equal to 1 for an unpacked header and 0x17 for a packed one. To create an archive manually, we will not compress anything.
')
The general scheme (unpacked) of the main header from the documentation:
{ ArchiveProperties AdditionalStreams { PackInfo { PackPos NumPackStreams Sizes[NumPackStreams] CRCs[NumPackStreams] } CodersInfo { NumFolders Folders[NumFolders] { NumCoders CodersInfo[NumCoders] { ID NumInStreams; NumOutStreams; PropertiesSize Properties[PropertiesSize] } NumBindPairs BindPairsInfo[NumBindPairs] { InIndex; OutIndex; } PackedIndices } UnPackSize[Folders][Folders.NumOutstreams] CRCs[NumFolders] } SubStreamsInfo { NumUnPackStreamsInFolders[NumFolders]; UnPackSizes[] CRCs[] } } MainStreams { (Same as in AdditionalStreams) } FilesInfo { NumFiles Properties[] { ID Size Data } } } Let's sort things out in order, forming the right title along the way. We fill the first 32 bytes last (we need a ready-made main header for them), the following bytes are data that we will not compress for simplicity:
00000020: 48 65 6C 6C 6F 2C 20 48 61 62 72 61 68 61 62 72 | Hello, Habrahabr 00000030: 21 | ! Write the first byte of the main header:
00000030: 01 ArchiveProperties - properties for possible expansion, are not used now, 7-Zip never creates them and silently skips when reading.
AdditionalStreams and MainStreams describe the structure of the compressed data. The first byte in AdditionalStreams is 0x03, the first byte in MainStreams is 0x04, otherwise their structure is identical (by the way, the packed main header after the first byte 0x17 has the same structure).
MainStreams describe the data files. AdditionalStreams allows you to bring out some data (for example, the names of the files collected together) separately and compress, regardless of the main title; 7-Zip does not use this feature when writing (in the actual archives there are no AdditionalStreams), but it is able to process them when reading.
We write the first byte of MainStreams and go inland:
00000030: 04 In 7-Zip, data encoders are involved in data conversion. Each encoder has some input streams, some output streams, its own identifier, and possibly some settings. Most encoders convert one input stream into one output stream: these are, for example, the copy encoder {00} (we need it), the LZMA packer {03, 01, 01}, the AES encoder {06, 01, xx} , BZip2-packer {04, 02, 02} (yes, the 7z format fully allows algorithms that traditionally use other archive formats). An example of an encoder with multiple output streams: BCJ2 {03, 03, 01, 1B}. The x86 and x86-64 machine codes are designed so that the procedure call commands (E8 xx xx xx xx) and jumps (E9 xx xx xx xx is long unconditional, 0F 8y xx xx xx xx is long conditional) encode the destination address as an offset from its own the end. Because of this, compression will simply not “notice” that different occurrences of E8 xx xx xx xx (with different xx due to relativity bias) are actually a call to the same procedure. BCJ2 converts call and jump assignments to absolute form and outputs 4 output streams: the first is normal data, the second is call assignments, the third is jump assignments, the fourth is a bit stream, which for each occurrence of E8 / E9 / 0F 8x tells whether there is a corresponding coded assignment or is it just a data byte.
The 7z format describes the most common situation: the input stream is encoded with an arbitrary number of some encoders, the outputs of which in turn can be the inputs of other encoders, and so on. The first PackInfo block in the stream information describes all final streams recorded in the archive (all encoder output streams not input to some other encoders): byte 0x06, the encoded beginning of the final streams in the file (as an offset from the end of the first header, streams follow one after another sequentially), coded number of streams, byte 0x09, sizes of all final streams (one coded number for each final stream), byte 0x00. Between the sizes of the streams and the end of the structure, there may be information on the CRC of the final streams, but it is usually not used, and the CRC is controlled by the unpacked data.
The integers in 7z are encoded as follows: the number of leading ones in the first byte determines the number of additional bytes, the other bits of the first byte are the high bits of the number, the additional bytes determine the lower bytes of the number in little-endian. Numbers less than 0x80 are encoded with one byte equal to the number itself. Numbers that occupy all 8 bytes are encoded by assigning 0xFF to the beginning of a byte.
We will have two streams. The first is for the file “Some file.txt”, starting at offset 0 relative to the end of the first header. The second is for the archive, starting from the beginning of the file. Since the streams follow one after another in succession, the size of the first stream will have to be made 0 - 0x20 = 0xFFFFFFFFFFFFFFE0. The size of the archive, we do not know yet, leave under it two bytes. So, we form the PackInfo block:
00000030: 06 00 02 09 FF E0 FF FF FF FF FF FF FF 00000040: ?? ?? 00 The second block, CodersInfo, describes all the encoders used with parameters and the links between them. Encoders are grouped into communication groups; there are no connections between groups. For example, one group may consist of one LZMA-packer, the second - of a bunch of BCJ2 + (several different LZMA). The CodersInfo block starts with bytes 0x07 0x0B, followed by the coded number of groups, zero bytes (non-zero would mean putting information about groups into a separate AdditionalStream), one Folder structure per group. Each group begins with the number of encoders in the group, followed by a description of each encoder. The first byte of the encoder description contains the size of the identifier in the lower 4 bits, the next bit is set only if the encoder has a number of input channels or the number of output channels is not one, the next bit is set if the encoder has parameters. This is followed by an identifier, then the number of output and input channels (if either one or the other is different from one), then the size of the parameters (if any) and the parameters themselves as an array of bytes. After all the coders, there is a description of the connections: the number of the output channel and the number of the input channel that need to be connected. Each input channel, except for one, must be the output of a decoder, so the number of links is equal to the total number of input channels in all encoders minus 1. Finally, if the number of output streams is more than one, the group description ends with a list of indices of unrelated output streams in that order in which they are recorded in the archive. After describing the folders, there is a byte 0xC and the sizes of all input channels, including connected ones, of all folders. Like PackInfo, the CodersInfo block ends with 0x00 byte. Between the sizes of the streams and the end of the structure there may be information on the CRC of the input data, which is usually used only for information about the flows of the packed header (CRC files are stored in the next block). The CRC, if present for all streams, is stored as follows: first, a nonzero byte (a sign that the CRC is defined for all streams; otherwise, a bitmap would go further indicating which CRC streams are defined for), then 4 bytes of CRC for each stream.
We form the CodersInfo block, taking into account that we have one copying encoder in each of the two groups for two streams, and still leaving two bytes for the as-yet unknown archive size:
00000040: 07 0B 02 00 01 01 00 01 01 00 0C 11 ?? 00000050: ?? 00 The third block SubStreamsInfo describes the files. It is not in the information about the packed header streams, but in the information about the file streams it should be, possibly, without data. 7-Zip does not compress individual files, but blocks from several files (continuous archives; you can set limits on the block size and on the number of files in the block up to one file, which actually turns off continuous archives, but by default, continuity is on). The input streams in the description above merge several files. The SubStreamsInfo block describes the sizes of (non-empty) files in one block. It starts with byte 0x08. Further, it may be followed by byte 0x0D and the number of files in each group; if not, then it is considered that there is one file in each group. Then, perhaps, the byte 0x09 and the sizes of the individual files follow (except for the last one in each group - it is calculated by the size of the input stream of the group). Further, it may be followed by byte 0x0A and CRC of individual files stored similarly to the CodersInfo block. The SubStreamsInfo block ends, like the others, byte 0x00. We have two files in the archive are stored in different streams. For simplicity, we will not record the CRC in our archive (this is easy to do for a text file, you need to adjust the archive so that the CRC calculated from the data including the CRC itself would converge - you would have to allocate unused bytes and fit them). Therefore, the SubStreamsInfo block with us does not contain data:
00000050: 08 00 We terminate the stream information with a zero byte and return to the level above:
00000050: 00 FilesInfo, as you might guess, contains information about the files inside the archive: names, creation / modification / access dates, file attributes. FilesInfo begins with byte 0x05, followed by an encoded integer indicating the number of files, followed by a property (in some quantity). Each property starts with a non-zero byte identifier, followed by the size of the property (so that 7-Zip can skip unknown properties). Zero byte ends FilesInfo. The file names are encoded as a property with the type 0x11, the first byte of the content is zero (a non-zero byte means that all further property contents are rendered into a separate AdditionalStream, whose index in the common array is encoded further), then the names themselves go to UTF-16 with terminating zero.
For simplicity, we will not fill in the dates and attributes, but the names are needed. Fill the FilesInfo block:
00000050: 05 02 11 43 00 1A 04 30 04 3A 04 | .....<<< 00000060: 3E 04 39 04 2D 00 42 04 3E 04 20 00 44 04 30 04 | <<-<<< <<< 00000070: 39 04 3B 04 2E 00 74 00 78 00 74 00 00 00 20 04 | <<.<t<x<t<..< 00000080: 35 04 3A 04 43 04 40 04 41 04 38 04 32 04 3D 04 | <<<<<<<< 00000090: 4B 04 39 04 2E 00 37 00 7A 00 00 00 00 | <<.<7<z<... It remains only to complete the entire header with the already familiar zero byte:
00000090: 00 So, the size of the entire file is 0x9E bytes, now we can go back and write bytes 80 9E, encoding the number 0x9E, in place of the questions. It remains to form the first heading. The main header starts at position 0x11 relative to the end of the first header and occupies 0x9E - 0x31 = 0x6D bytes.
Now we need to calculate two CRCs. Manually counting CRC of 0x6D bytes is quite troublesome, so we will resort to using programs here. The first CRC we need to calculate is the main header: bytes from 0x31 to the end, its CRC is 0x3F5E2977. The second CRC is counted in the three last fields of the first header, including the first CRC: 11 00 00 00 00 00 00 00 6D 00 00 00 00 00 00 77 29 5E 3F. It is 0x6FA3DEA5. Finally, let's put everything together and get this " Recursive . 7z ":
00000000: 37 7a bc af 27 1c 00 03 a5 de a3 6f 11 00 00 00 |7z..'......o....| 00000010: 00 00 00 00 6d 00 00 00 00 00 00 00 77 29 5e 3f |....m.......w)^?| 00000020: 48 65 6c 6c 6f 2c 20 48 61 62 72 61 68 61 62 72 |Hello, Habrahabr| 00000030: 21 01 04 06 00 02 09 ff e0 ff ff ff ff ff ff ff |!...............| 00000040: 80 9e 00 07 0b 02 00 01 01 00 01 01 00 0c 11 80 |................| 00000050: 9e 00 08 00 00 05 02 11 43 00 1a 04 30 04 3a 04 |........C.<<<| 00000060: 3e 04 39 04 2d 00 42 04 3e 04 20 00 44 04 30 04 |<<-<<< <<<| 00000070: 39 04 3b 04 2e 00 74 00 78 00 74 00 00 00 20 04 |<<.<t<x<t<..<| 00000080: 35 04 3a 04 43 04 40 04 41 04 38 04 32 04 3d 04 |<<<<<<<<| 00000090: 4b 04 39 04 2e 00 37 00 7a 00 00 00 00 00 |<<.<7<z<....| Source: https://habr.com/ru/post/185884/
All Articles