A little bit on the development of web archives
A web archive is a system that periodically saves a site (or part of a site) in its original form. Most often this is done for the descendants, so that they can "play around, cry out and feel nostalgic ."
The basic requirement for a web archive sounds simple and comprehensive.
')
For us developers, the expression “fully functional offline version” sounds very, very suspicious. You can even say - it sounds seditious. After all, a modern website without scripts does not happen, and scripts always generate uncertainty in behavior. But, as one character used to say: “You don’t need to rush to conclusions, otherwise the conclusions will pounce on you”.
Honestly, in open sources of information read not reread. You can start with an article in wikipedia . Unfortunately, the implementation there is not very much, but more is said about the organizational and legal problems.
For those interested - I recommend to read. For the rest I will give a few terms for common development.
Web archive . For example, the most important archive of the Internet is archive.org . It scares its volume and complexity of use .
Web crawler is a program that can scroll through the pages of a steyt, following links. Currently, there are a lot of them. Perhaps the most famous robot whose visits are so welcome - Google Bot. For POC, we used ABot .
Building a system entirely requires storage, interfaces, and so on. But, unfortunately, everything will not fit in one article. Therefore, here I will tell only about the most difficult part - the algorithm for crawling the site and storing data.
How to solve the problem of archiving, I think, obviously. Sites are made for users. What is the user doing? Opens the page, remembers the necessary information, follows the link to the next page.
Let's try to make a virtual user - a robot - and automate the task a bit.
The “story” (hello, edgyle) of the robot’s work looks like this
It looks very brief and very abstract. The first step in designing is always abstract, which is why it is the first. Now I will detail it.
First you need to determine for yourself what will be the basic “indivisible” entity in our data model. Let it be called "Resource". I define it like this:
That is, its main properties are the presence of a link (URI) and content that the server returns. For completeness, you need to supplement the description of the resource with metadata (type, link, last modified time, etc.). By the way, a resource may contain links to other resources.
Based on this concept, I define the general algorithm of the crawler.
In general, it looks logical. You can detail further.
So, the robot is at the beginning of the process: it has only a link to the entry point to the site, the so-called index page. At this step, the robot creates a queue, and puts in it a link to the entry point.
Speaking abstractly, the queue is the source of tasks for the robot. Now the queue with its only element looks like this.

(Note: the processing queue for small sites can be stored in memory, but for large sites it is better to keep it in the database. In case the process stops somewhere in the middle).
Select a resource from the queue for processing. (At the first iteration, this is the entry point). Download the page and find out what resources it refers to.

Here, in general, everything is simple. The page is located at site . The robot downloads it and analyzes the html content for links. (For types of links, see "Types of resources" below.) Several links are shown in the example: robots.txt (its robot ignores :), the “About Us” link is about.html, links to CSS and Javascript files, a link to Youtube video.
Filter unnecessary resources. To do this, the robot must provide a very flexible configuration interface (most of the existing ones do). For example, a robot should be able to filter files by type, extension, size, update time. For outbound links you also need to check the depth of nesting. Obviously, if a resource for some link has already been processed, then you should not touch it.
For the remaining, necessary resources - create a description structure and put in a queue. It is important to note that the structures at this stage are not completely filled: they contain only original (online) links. (That is, just like the original entry point at the zero step).
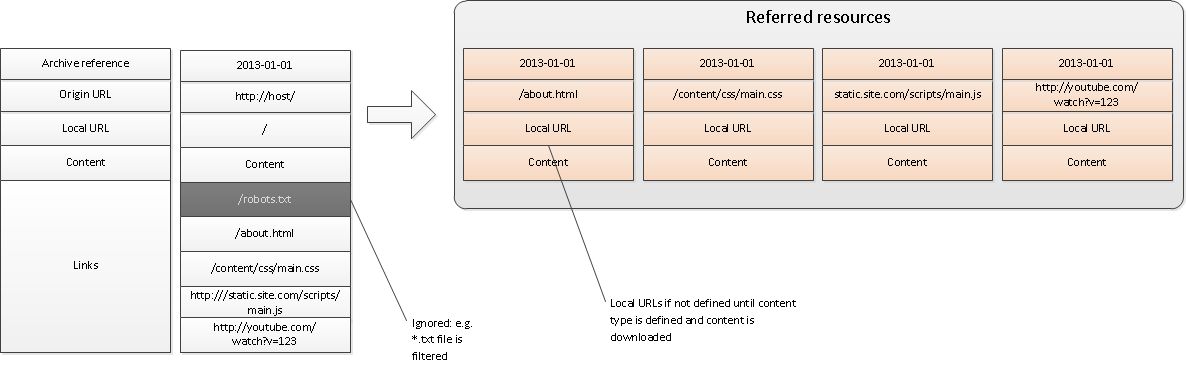
Important: at this stage, the content of the “Index page” page still contains original links, which means it cannot be used as an offline version. In order to complete the processing completely, you need to replace the links: they must point to saved offline versions of the resources. Using a queue is not difficult to implement: you need to put the task of updating the “Index page” links at the end of the queue. Thus it is guaranteed that by the beginning of the execution of this task all the referred resources will be processed.

In general, this is the first step, only for each resources. (That is, the implementation of the algorithm will be simpler. Here the steps of the cycle are deployed to simplify the picture). At this step, the robot retrieves the next task from the queue ( download tasks added in the previous step).
It then finds out what transformations the resource needs to be exposed for offline use. In this example, all resources are simply downloaded, except for the “embedded” video: it is downloaded in a special way via youtube and saved as an avi file locally.
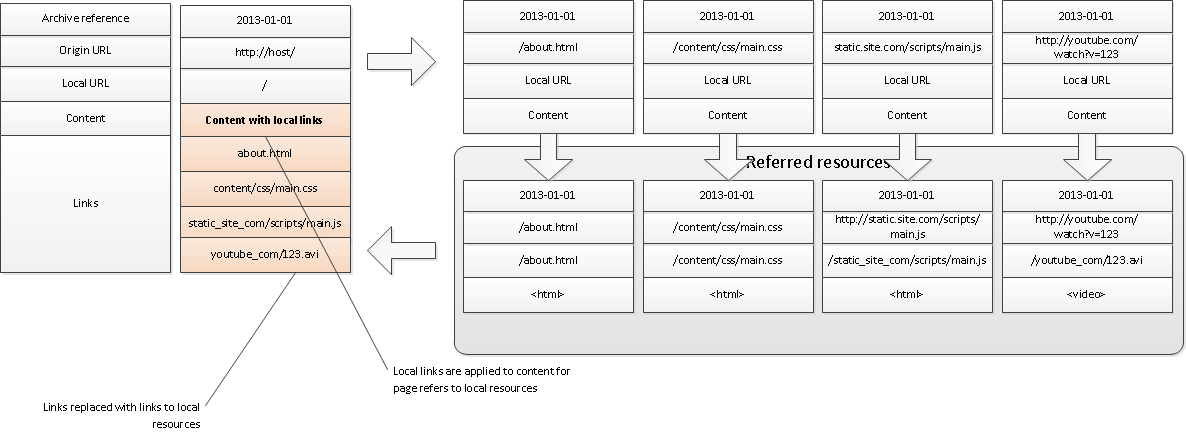
After that, local (offline) links for the referred resources are generated.
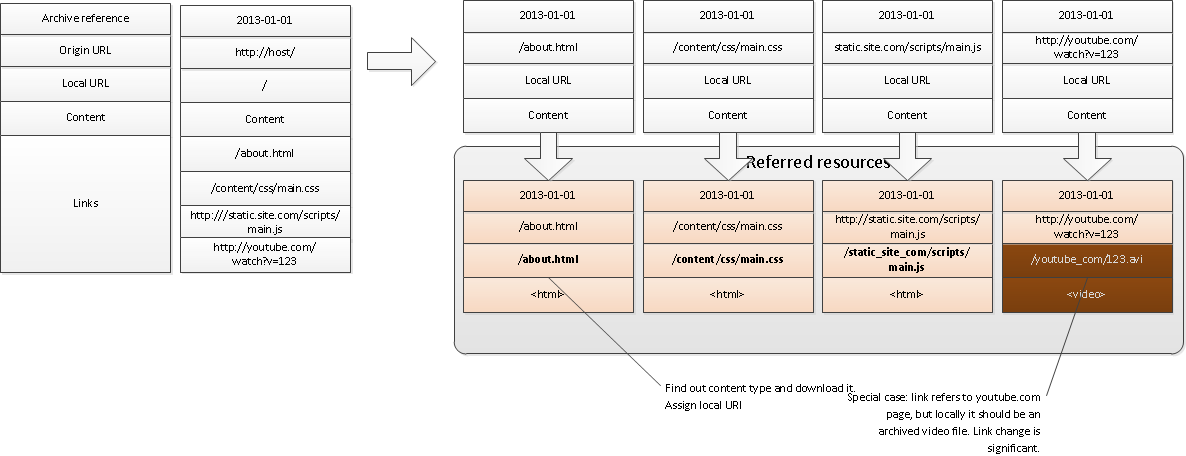
Important: just as in the first step, for each of their resources it is necessary to identify outgoing links and put them - correctly - in a queue.

(In this example, the CSS file refers to image.png).
The next task in the queue after removing the resources from there (and, of course, image.png) is to update the links on the index page. Here, perhaps, for html-pages will have to change and structure. For example, an offline version of the video "embed" through some kind of player.
The queue-based algorithm suffers from one drawback: resources are processed sequentially, and therefore, not as fast as it can be on a modern server.
Therefore, it is necessary to provide for the possibility of parallel processing. There are two options for parallelism:
The micro level raises blocking issues. If you recall, the task "update links" is placed at the end of the queue just for consistency. We expect that by the time of the launch of this task, all related resources have already received local links and are processed. In parallel, this condition is violated, and you will need to enter the synchronization point. For example, a simple option: run tasks to download asynchronously. When a task for updating links appears, wait until the active download tasks (the so-called Barrier) are completed. A difficult option is to introduce dependencies between tasks in an explicit form through semaphores. Maybe there are more options, not analyzed deeply.
Obviously, it is impossible to foresee all kinds of resources with which such a crawler has to deal. But we will try, at least in order to know what difficulties we will have to face.
The robot asks me a question: “But still - what have we decided about dynamic pages, scripts, and so on.”? The answer is: it turns out to check that not all pages are equally “dynamic”. I define the following levels of “dynamic” pages:
The greater the level of dynamism, the more difficult it is to save offline content:
The basic requirement for a web archive sounds simple and comprehensive.
Offline version of the site must be fully functional. All original images, flash animation, embedded video, scripts, and so on should be visible in it. Ideally, it should not differ from the original.
')
For us developers, the expression “fully functional offline version” sounds very, very suspicious. You can even say - it sounds seditious. After all, a modern website without scripts does not happen, and scripts always generate uncertainty in behavior. But, as one character used to say: “You don’t need to rush to conclusions, otherwise the conclusions will pounce on you”.
Materiel
Honestly, in open sources of information read not reread. You can start with an article in wikipedia . Unfortunately, the implementation there is not very much, but more is said about the organizational and legal problems.
For those interested - I recommend to read. For the rest I will give a few terms for common development.
Web archive . For example, the most important archive of the Internet is archive.org . It scares its volume and complexity of use .
Web crawler is a program that can scroll through the pages of a steyt, following links. Currently, there are a lot of them. Perhaps the most famous robot whose visits are so welcome - Google Bot. For POC, we used ABot .
Building a system entirely requires storage, interfaces, and so on. But, unfortunately, everything will not fit in one article. Therefore, here I will tell only about the most difficult part - the algorithm for crawling the site and storing data.
Solution approach
How to solve the problem of archiving, I think, obviously. Sites are made for users. What is the user doing? Opens the page, remembers the necessary information, follows the link to the next page.
Let's try to make a virtual user - a robot - and automate the task a bit.
The “story” (hello, edgyle) of the robot’s work looks like this
the robot goes from page to page by reference (as a user). After the transition saves the page. Compiles a list of links that can be accessed from the page. Already passed links ignored. Unreleased - saves, and so on.
It looks very brief and very abstract. The first step in designing is always abstract, which is why it is the first. Now I will detail it.
Detail number 1
First you need to determine for yourself what will be the basic “indivisible” entity in our data model. Let it be called "Resource". I define it like this:
A resource is any content that we can download by reference.
That is, its main properties are the presence of a link (URI) and content that the server returns. For completeness, you need to supplement the description of the resource with metadata (type, link, last modified time, etc.). By the way, a resource may contain links to other resources.
Based on this concept, I define the general algorithm of the crawler.
- Preparation: Put the entry point URI in the processing queue
- Main loop: Select link from queue
- Download the resource at the specified link
- Do something useful with the resource
- Find out which resources the resource refers to (resources)
- Put them in a queue
- Go to the beginning of the cycle
In general, it looks logical. You can detail further.
Detailing number 2
Step zero. Training.
So, the robot is at the beginning of the process: it has only a link to the entry point to the site, the so-called index page. At this step, the robot creates a queue, and puts in it a link to the entry point.
Speaking abstractly, the queue is the source of tasks for the robot. Now the queue with its only element looks like this.
(Note: the processing queue for small sites can be stored in memory, but for large sites it is better to keep it in the database. In case the process stops somewhere in the middle).
Step one. Content analysis.
Select a resource from the queue for processing. (At the first iteration, this is the entry point). Download the page and find out what resources it refers to.
Here, in general, everything is simple. The page is located at site . The robot downloads it and analyzes the html content for links. (For types of links, see "Types of resources" below.) Several links are shown in the example: robots.txt (its robot ignores :), the “About Us” link is about.html, links to CSS and Javascript files, a link to Youtube video.
Step two
Filter unnecessary resources. To do this, the robot must provide a very flexible configuration interface (most of the existing ones do). For example, a robot should be able to filter files by type, extension, size, update time. For outbound links you also need to check the depth of nesting. Obviously, if a resource for some link has already been processed, then you should not touch it.
For the remaining, necessary resources - create a description structure and put in a queue. It is important to note that the structures at this stage are not completely filled: they contain only original (online) links. (That is, just like the original entry point at the zero step).
Important: at this stage, the content of the “Index page” page still contains original links, which means it cannot be used as an offline version. In order to complete the processing completely, you need to replace the links: they must point to saved offline versions of the resources. Using a queue is not difficult to implement: you need to put the task of updating the “Index page” links at the end of the queue. Thus it is guaranteed that by the beginning of the execution of this task all the referred resources will be processed.
Step Three
In general, this is the first step, only for each resources. (That is, the implementation of the algorithm will be simpler. Here the steps of the cycle are deployed to simplify the picture). At this step, the robot retrieves the next task from the queue ( download tasks added in the previous step).
It then finds out what transformations the resource needs to be exposed for offline use. In this example, all resources are simply downloaded, except for the “embedded” video: it is downloaded in a special way via youtube and saved as an avi file locally.
After that, local (offline) links for the referred resources are generated.
Important: just as in the first step, for each of their resources it is necessary to identify outgoing links and put them - correctly - in a queue.
(In this example, the CSS file refers to image.png).
Step Four
The next task in the queue after removing the resources from there (and, of course, image.png) is to update the links on the index page. Here, perhaps, for html-pages will have to change and structure. For example, an offline version of the video "embed" through some kind of player.
Step five
Go to the first step and continue until the queue is empty.Scalability
The queue-based algorithm suffers from one drawback: resources are processed sequentially, and therefore, not as fast as it can be on a modern server.
Therefore, it is necessary to provide for the possibility of parallel processing. There are two options for parallelism:
- Macro level: several crawlers will work in parallel on different sites
- Micro level: one crawler will handle resources in parallel
The micro level raises blocking issues. If you recall, the task "update links" is placed at the end of the queue just for consistency. We expect that by the time of the launch of this task, all related resources have already received local links and are processed. In parallel, this condition is violated, and you will need to enter the synchronization point. For example, a simple option: run tasks to download asynchronously. When a task for updating links appears, wait until the active download tasks (the so-called Barrier) are completed. A difficult option is to introduce dependencies between tasks in an explicit form through semaphores. Maybe there are more options, not analyzed deeply.
Types of resources
Obviously, it is impossible to foresee all kinds of resources with which such a crawler has to deal. But we will try, at least in order to know what difficulties we will have to face.
- Html pages. The most common type of resources. Pretty easy to handle (in .net using HtmlAgilityPack and CsQuery). Can refer to resources of this type:
- Other pages or files via <a>
- Images <img>
- CSS styles <link rel = "stylesheet">
- Scripts <script>
- Flash animations <object>
- Embedded video <object>, <embed> or <iframe>
- Pay attention : the system should be flexible enough so that the components for new types of links and their processing are added without changing the basic code (the well-known Open-Close principle)
- CSS styles. Download as is. Can refer to other resources (css & images) through the function "url"
- Scripts Download as is. Finding direct links from non-scripts is not possible (see below about dynamic pages for details)
- Video. Download using special approaches, which differ depending on the provider. No link to anywhere
- Flash animation. It is downloaded as a swf file. It can refer to other resources and download other flash files, but we will not determine from it.
- Dynamic links. The first type: arises as a consequence of the DOM manipulation, requiring the loading of additional files (images, scripts). The second type: XHR requests.
Dynamic pages
The robot asks me a question: “But still - what have we decided about dynamic pages, scripts, and so on.”? The answer is: it turns out to check that not all pages are equally “dynamic”. I define the following levels of “dynamic” pages:
- Level 1. Good old html-pages . Static html-content with CSS-styles.
- Level 2. Html-content, enhanced script . Here the script does not make ajax-requests, but manipulates only the content that came from the server. For example, a table sorter, or expander.
- Level 3. Onload-downloader . After the page loads, the script starts working and uploads some additional content.
- Level 4. Client application . The user interface is modified by user actions. The script loads data non-deterministic. So one-page applications work, "endless" lists, smart expanders
The greater the level of dynamism, the more difficult it is to save offline content:
- Levels 1 and 2 - Perfectly saved, works great offline.
- Level 3 - there is only one way to properly handle such a page. To do this, you need to start the browser (programmatically, of course), and wait until the main page and all the additional content load:
- We instantiate the built-in browser and load the page into it.
- After the original HTML styles, scripts, images are loaded.
- Scripts do their black deeds (modify DOM, make XHR requests).
- The system keeps track of all requests that occur during page loading. (A simple example is what Firebug does).
- All requests are considered links to resources. The response from the server is recorded in the database, and is processed according to the algorithm from the last part.
For POC, I used Webkit.Net (git@github.com: webkitdotnet / webkitdotnet.git), which had to be finished a little.
It works like Firebug, with the difference that it’s from .Net. - Level 4. Single-page application. Not at our level of technology. And why, I ask, do I need to save the offline version of such an application? SPAs usually show very subjective content, which depends on the user and other numerous parameters. My personal opinion is that this is not necessary, and it is extremely difficult - how to fly faster than light. Anyway, no one will see and appreciate.
But to offer a solution is my duty. I carry out. I even have two options.
Option with the operator.- The operator installs a special browser extension (or uses our browser entirely).
- After the initial loading of the page is a snapshot of her home. I do not know how in Russian. The "snapshot" sounds strange. (They suggest another "cast").
- The user begins to work with the application, “clicks and taps.”
- For any change in DOM it is determined what has changed, and we save the next “frame” of DOM.
- The result is a kind of home animation. We save in any convenient format.
- The archived version will be read-only, but the functionality of the original page will be transferred.
Option with machine learning or script. In general, it is similar to the first option, but the operator’s steps are explicitly or implicitly remembered for further automated reproduction. You can apply automatic classifiers and even neural networks: for researchers there is an immense field of opportunity. Unfortunately, we are not researchers, but developers. The complexity, to be honest, I will not undertake to evaluate.
Conclusion
In addition to the robot, the repository, indexing and interface must be present in the web archive system - I deliberately excluded them from consideration. First, these components are fairly simple both in integration and configuration compared to a robot. Secondly, just to not distract.
A web archiving system can be built in a reasonable time, but it will have limitations due to the dynamic nature of modern sites. Dynamic pages up to the third level are amenable to acceptable archiving. For the fourth level will take quite a lot of effort.
In general, there are two ways to develop robots. The first - with the use of artificial intelligence. It is necessary to develop a crawler so that it “understands” what it is doing. The second is technological. It is necessary to create a platform for sites, something like a smart CMS. The sites operating on it could display content to robots in a simple form for archiving.
Source: https://habr.com/ru/post/185816/
All Articles