Kate Matsudeira: Scalable Web Architecture and Distributed Systems
 Six months ago , the question about the text for my diploma translation came out sharply. The result of collective intelligence was the decision to translate the chapter Scalable Web Architecture and Distributed Systems by Kate Matsudaira . It should be noted that this is my first translation of this volume and complexity. The text was relatively successfully translated by me, although I would set 6-7 out of 10 for the quality of the translation. So that my efforts are not lost in vain, I publish the result of my works.
Six months ago , the question about the text for my diploma translation came out sharply. The result of collective intelligence was the decision to translate the chapter Scalable Web Architecture and Distributed Systems by Kate Matsudaira . It should be noted that this is my first translation of this volume and complexity. The text was relatively successfully translated by me, although I would set 6-7 out of 10 for the quality of the translation. So that my efforts are not lost in vain, I publish the result of my works.At the request of Habr's readers , now the full version is in the form of a topic.

Scalable web architecture and distributed systems
Kate Matsudeira
Translation: jedi-to-be .
Correction: Anastasiaf15 , sunshine_lass , Amaliya , fireball , Goudron .
')
Open source software has become the main building block for creating some of the largest websites. With the growth of these websites, best practices and guidelines for their architecture have emerged. This chapter aims to cover some of the key issues that should be considered when designing large websites, as well as some of the basic components used to achieve these goals.
This chapter focuses on the analysis of web systems, although some of the material can be extrapolated to other distributed systems.
1.1 Principles of building distributed web systems
What exactly does creating and managing a scalable website or application? At a primitive level, it is simply the connection of users to remote resources via the Internet. And resources or access to these resources, which are dispersed on a variety of servers and are a link to ensure the scalability of the website.
Like most things in life, the time spent in advance on planning to build a web service can help further; Understanding some of the considerations and trade-offs behind large websites can be rewarded with smarter solutions for creating smaller websites. Below are some key principles affecting the design of large-scale web systems:
- Accessibility: The length of time that a website is operational is critical to the reputation and functionality of many companies. For some of the larger online retailers, unavailability even for a few minutes can result in thousands or millions of dollars in lost revenue. Thus, the development of their constantly accessible and resilient systems is also a fundamental business and technological requirement. High availability in distributed systems requires careful consideration of redundancy for key components, fast recovery from partial system failures, and a smooth reduction in capabilities when problems arise.
- Performance: Website performance has become an important indicator for most sites. Website speed and user satisfaction, as well as ranking by search engines, are factors that directly affect audience retention and revenue. As a result, the key is to create a system that is optimized for fast responses and low latency.
- Reliability: the system must be reliable, so that a particular request for data will consistently return certain data. In the event of a data change or update, the same query must return new data. Users need to know if something is recorded in the system or stored in it, then you can be sure that it will remain in place to be able to extract data later.
- Scalability: When it comes to any large distributed system, the size is just one item from a list that needs to be considered. Equally important are efforts to increase throughput to handle large volumes of workload, which is commonly referred to as system scalability. Scalability can relate to various parameters of the system: the amount of additional traffic with which it can handle, how easy it is to increase the storage capacity of the storage device, or how much more other transactions can be processed.
- Manageability: Designing a system that is easy to operate is another important factor. The manageability of the system is equal to the scalability of the “maintenance” and “upgrade” operations. To ensure the controllability, it is necessary to consider the issues of simplicity of diagnostics and understanding of emerging problems, ease of updating or modifying, whimsicalness of the system in operation. exceptions?)
- Cost: Cost is an important factor. It can obviously include hardware and software costs, but it is also important to consider other aspects necessary to deploy and maintain the system. The amount of developer time required to build the system, the amount of operational effort required to start the system, and even a sufficient level of training should all be provided. Cost is the total cost of ownership.
Each of these principles is the basis for decision making in designing a distributed web architecture. However, they may also be in conflict with each other, because achieving the goals of one is due to the neglect of others. A simple example: the choice of simply adding multiple servers as a performance solution (scalability) can increase the cost of manageability (you must operate an additional server) and the purchase of servers.
When developing any kind of web application, it is important to consider these key principles, even if it is to confirm that a project can donate one or more of them.
1.2 Basics
When considering the architecture of the system there are several issues that need to be addressed, for example: which components should be used, how they are combined with each other, and which compromises can be made. Investing money in scaling without the obvious need for it can not be considered a reasonable business decision. However, some forethought in planning can significantly save time and resources in the future.
This section focuses on some of the basic factors that are crucial for almost all large web applications: services ,
redundancy , segmentation , and fault handling . Each of these factors implies choice and compromise, especially in the context of the principles described in the previous section. For clarification, we give an example.
Example: image hosting application
You probably have already posted images on the web. For large sites that provide storage and delivery of multiple images, there are problems in creating a cost-effective, highly reliable architecture that is characterized by low latency responses (fast retrieval).
Imagine a system where users have the opportunity to upload their images to a central server, and at the same time images can be requested via a link to a website or API, similar to Flickr or Picasa. To simplify the description, let's assume that this application has two main tasks: the ability to upload (write) images to the server and request images. Of course, effective download is an important criterion, however, the priority will be fast delivery on request from users (for example, images can be requested to be displayed on a web page or another application). This functionality is similar to what a Web server or Content Delivery Network (CDN) can provide. A CDN server typically stores data objects in many locations, so their geographic / physical location is closer to the users, resulting in increased performance.
Other important aspects of the system:
- The number of stored images can be limitless, so storage scalability needs to be considered from this point of view.
- There should be a low latency for image upload / request.
- If a user uploads an image to the server, his data should always remain complete and accessible.
- The system should be easy to maintain (manageability).
- Since the hosting of images does not bring much profit, the system should be cost-effective.
Figure 1.1 is a simplified diagram of the functionality.
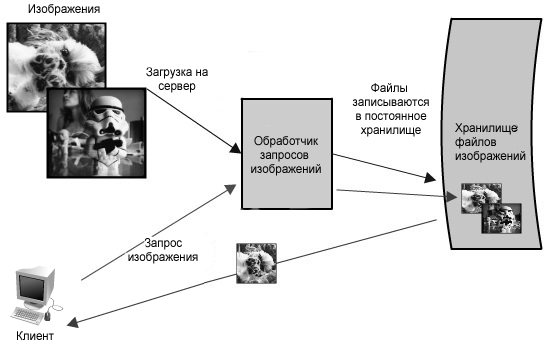
Figure 1.1: Simplified architecture diagram for an image hosting application
In this example of image hosting, the system should be noticeably fast, its data is securely stored, and all these attributes are well scalable. Creating a small version of this application would be a standard task, and a single server would be enough to host it. However, such a situation would not be of interest to this chapter. Let's assume that we need to create something as large as Flickr.
Services
When considering the design of a scalable system, it is useful to separate the functionality and think of each part of the system as a separate service with a well-defined interface. In practice, it is believed that systems designed in this way have a Service-Oriented Architecture (SOA). For these types of systems, each service has its own distinct functional context, and interaction with something outside of that context occurs through an abstract interface, usually the public API of another service.
Deconstructing the system into a series of complementary services isolates the work of some parts from others. This abstraction helps establish a clear relationship between the service, its underlying environment, and the consumers of the service. Creating a clear outline can help locate problems, but also allows each part to scale independently. This type of service-oriented design of systems for serving a wide range of requests is similar to the object-oriented approach to programming.
In our example, all requests for loading and receiving images are processed by the same server; however, since the system must scale, it is advisable to separate these two functions into their own services.
Suppose the service is in intensive use in the future; such a script helps to better track how longer recordings affect the time to read an image (since the two functions will compete for shared resources). Depending on the architecture, this effect can be significant. Even if the upload and receive speeds are the same (which is not typical of most IP networks, since they are designed to take at least 3: 1 ratio of receive speed to speed), readable files will usually be retrieved from the cache, and records should ultimately get on the disk (and possibly be re-recorded in similar situations). Even if all data is in memory or read from disks (such as SSDs), writing to the database will almost always be slower than reading from it. (Pole Position, an open source benchmarking tool for databases, http://polepos.org/ and the results of http://polepos.sourceforge.net/results/PolePositionClientServer.pdf .).
Another potential problem with this design is that a web server, such as Apache or lighttpd, usually has an upper limit on the number of simultaneous connections it can handle (the default value is approximately 500, but it can be much higher) and with high traffic, recordings can quickly consume this limit. Since reads can be asynchronous or take advantage of other performance optimizations like gzip or dividing, the web server can switch read feeds faster and switch between clients, serving far more requests than the maximum number of connections (with Apache and the maximum number of connections set to 500 is quite realistic to serve several thousand read requests per second). Records, on the other hand, tend to maintain an open connection throughout the load. Since transferring a 1MB file to a server could take more than 1 second in most home networks, as a result, the web server can process only 500 such simultaneous entries.
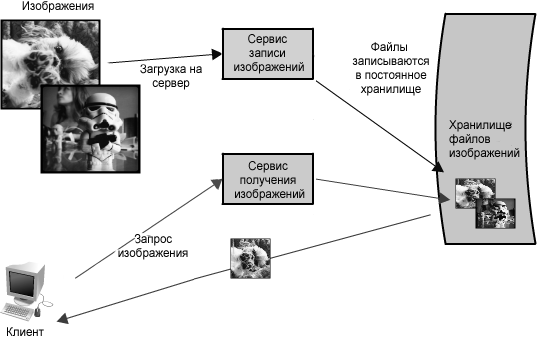
Figure 1.2: Separation of reading and writing
Anticipation of such a potential problem indicates the need to separate the reading and writing of images into independent services, shown in Figure 1.2 . This will allow not only to scale each of them separately (as it is likely that we will always do more readings than records), but also to be aware of what happens in each service. Finally, it will distinguish between problems that may arise in the future, which will simplify the diagnosis and assessment of the problem of slow reading access.
The advantage of this approach is that we are able to solve problems independently of each other - without having to think about the need to record and receive new images in the same context. Both of these services still use the global image corpus, but when using methods appropriate to a particular service, they are able to optimize their own performance (for example, placing requests in a queue, or caching popular images - more on this later in this article). Both in terms of service and cost, each service can be scaled independently as needed. And this is a positive factor, since their combination and mixing could inadvertently affect their performance, as in the scenario described above.
Of course, the operation of the aforementioned model will be optimal if there are two different endpoints (in fact, this is very similar to several implementations of cloud storage providers and Content Delivery Networks). There are many ways to solve such problems, and in each case a compromise can be found.
For example, Flickr solves this read-write problem by distributing users between different modules, so that each module can serve only a limited number of specific users, and when the number of users increases, more modules are added to the cluster (see the Flickr scaling presentation,
http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html ). In the first example, it is easier to scale the hardware based on the actual usage load (the number of reads and records in the entire system), whereas the Flickr scaling is based on the user base (however, the assumption of uniform use among different users is used here, so power needs to be planned with stock). In the past, inaccessibility or a problem with one of the services rendered the whole system functionality inoperative (for example, no one can write files), then the inaccessibility of one of the Flickr modules will only affect users belonging to it. In the first example, it is easier to perform operations on a whole set of data — for example, updating the recording service to include new metadata, or performing a search on all image metadata — whereas with the Flickr architecture each module had to be updated or searched (or the search service should created to sort the metadata that is actually intended for this).
As for these systems, there is no panacea, but one should always proceed from the principles described at the beginning of this chapter: determine system needs (load with “read” or “write” operations or all at once, level of parallelism, queries on data sets, ranges, sorting, etc.), conduct comparative benchmarking of various alternatives, understand the conditions of a potential system failure, and develop a comprehensive plan in case of failure.
Redundancy
To cope elegantly with a failure, the web architecture must have the redundancy of its services and data. For example, if there is only one copy of a file stored on a single server, the loss of this server would mean the loss of the file. It is unlikely that such a situation can be positively characterized, and it can usually be avoided by creating multiple or backup copies.
This same principle applies to services. It is possible to protect against the failure of a single node if one envisages an integral part of the functionality for the application, which guarantees the simultaneous operation of its multiple copies or versions.
Creating redundancy in the system allows you to get rid of weak points and provide backup or redundant functionality in case of an emergency. For example, in the event that there are two instances of the same service working in “production”, and one of them fails completely or partially, the system can overcome the failure by switching to a working instance .
Switching can occur automatically or require manual intervention.
Another key role of service redundancy is creating an architecture that does not involve resource sharing . With this architecture, each node is able to work independently and, moreover, in the absence of a central “brain” controlling states or coordinating the actions of other nodes. It promotes scalability, since the addition of new nodes does not require special conditions or knowledge. And most importantly, there is no critical point of failure in these systems, which makes them much more resilient to failure.
.For example, in our image server application, all images would have redundant copies somewhere in another piece of hardware (ideally with a different geographic location in the event of a disaster such as an earthquake or fire in the data center) and image access services will be redundant, despite the fact that all of them will potentially serve requests. (See Figure 1.3 .)
Looking ahead, load balancers are a great way to make this possible, but more on that below.
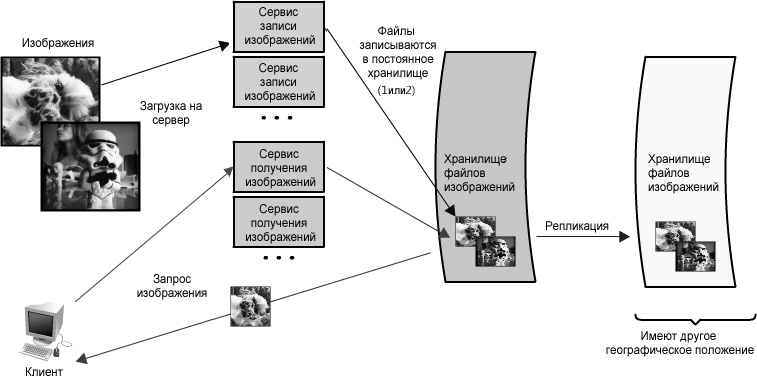
Figure 1.3: Redundancy Image Hosting Application
Segmentation
Data sets can be so large that they cannot be placed on a single server. It may also happen that computational operations will require too much computer resources, reducing performance and making it necessary to increase power. In any case, you have two options: vertical or horizontal scaling.
Vertical scaling involves adding more resources to a single server. So, for a very large data set, this would mean adding more (or more) hard drives, and thus the entire data set could fit on a single server. In the case of computational operations, this would mean moving the computation to a larger server with faster CPUs or more memory. In any case, the vertical scaling is performed in order to make a separate resource of the computing system capable of additional data processing.
Horizontal scaling, on the other hand, involves adding more nodes. In the case of a large data set, this would mean adding a second server to store part of the total data, and for a computational resource, this would mean sharing work or loading through some additional nodes. To take full advantage of the potential of horizontal scaling, it must be implemented as an internal principle of the development of the system architecture. Otherwise, changing and highlighting the context needed for horizontal scaling can be problematic.
The most common method of horizontal scaling is the division of services into segments or modules. They can be distributed in such a way that each logical set of functionality will work separately. This can be done by geographic boundaries, or other criteria such as paying and not paying users. The advantage of these schemes is that they provide a service or data warehouse with enhanced functionality.
In our example of an image server, it is possible that a single file server used to store an image can be replaced by multiple file servers, each one containing its own unique set of images. (See Figure 1.4 .) This architecture will allow the system to fill each file server with images, adding additional servers, as the disk space becomes full. The design will require a naming scheme that associates the name of the image file with the server containing it. The image name can be formed from a consistent hashing scheme associated with servers. Or alternatively, each image may have an incremental identifier, which allows the delivery service, when requesting an image, to process only the range of identifiers associated with each server (as an index).

Figure 1.4: Image Redundancy and Segmentation Hosting Application
Of course, there are difficulties in distributing data or functionality to multiple servers. One of the key issues is the location of the data ; in distributed systems, the closer the data is to the location of operations or the point of calculation, the better the system performance. Consequently, the distribution of data on multiple servers is potentially problematic, since at any time when this data may be needed, there is a risk that it may not be available at the place of demand, the server will have to perform costly sampling of necessary information over the network.
Another potential problem occurs in the form
inconsistency (inconsistency) . When different services read and write to a shared resource, potentially another service or data store, there is the possibility of a “race” condition - where some data is considered updated to the current state, but in reality they are read until the moment of update. - and in this case, the data are inconsistent. For example, in an image hosting scenario, a race condition might occur if one client sent a dog image update request with the “Dog” title changed to “Guizmo” while another client was reading the image. In such a situation it is unclear which particular title, “Dog” or “Gizmo”, would be received by the second client.
There are, of course, some obstacles associated with data segmentation, but segmentation makes it possible to isolate each of the problems from the others: by data, by loading, by usage patterns, etc. in managed blocks. This can help with scalability and manageability, but the risk is still present. There are many ways to reduce risk and handle disruptions; however, in the interest of brevity, they are not covered in this chapter. , - .
1.3.
, — .
-, , LAMP, 1.5 .

1.5: -
: . - , . . ; .
.
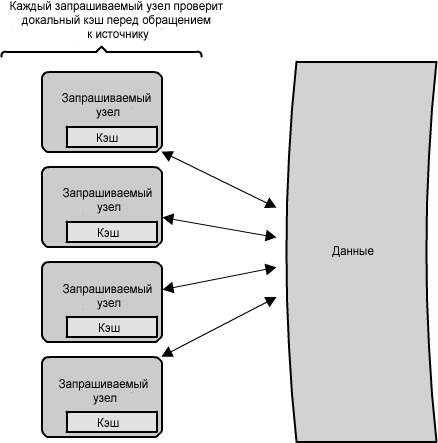
1.6: -
1.6 ,
. , , , . , : .
, () , . (. 1.7 .)
- .

1.7:
, -. — , , , . ; 6 , , 100,000 — (. « », http://queue.acm.org/detail.cfm?id=1563874). ). , , , .
, , — , , . , , .
: . : , , -, - . : , , , , . , , , .
API? , . ,
1.8 .

1.8:
. , , , , . , . ( ), (, ).
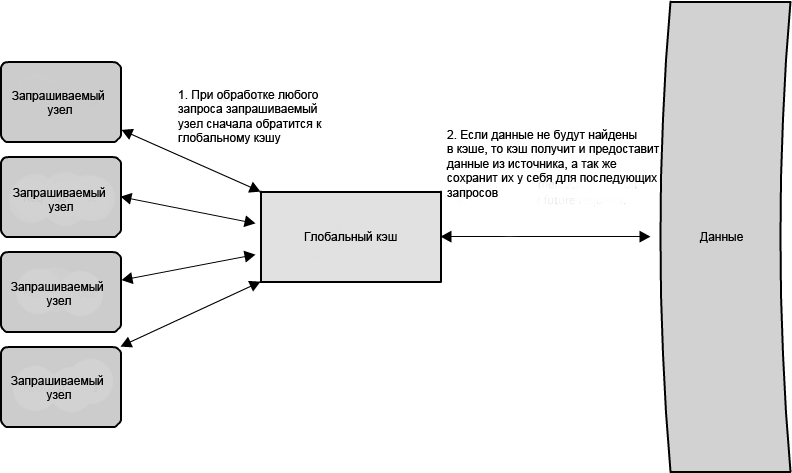
1.9:
, ? 1.9 , , , . , , , . .
: . , , , . , . , , . ( , , , ).
1.10: ,
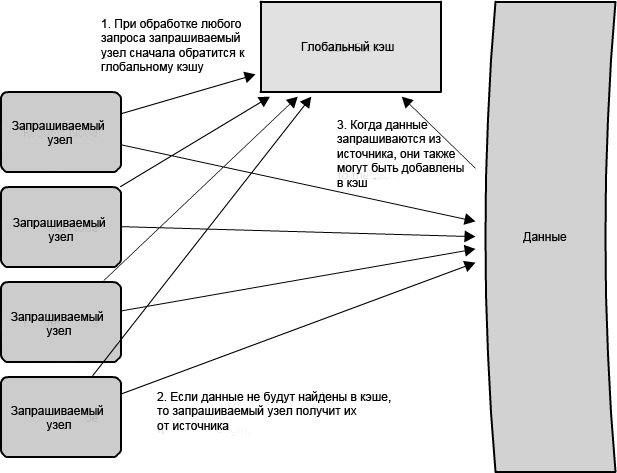
1.11: ,
, , , , . , , . , , ; ( ) . — , , , . ( - — , — , .)
( 1.12 ), , , — , , . -. , , , , . , . , — , .
— . , ; , , , . — , , — !
1.12: .
(, !) . , . , , .
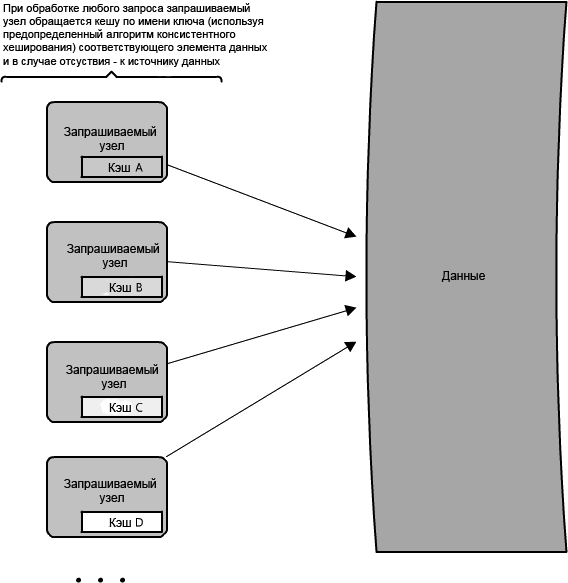
Memcached (), , ); , ( ).
Memcached -, , , - , (O(1)) .
Facebook uses several different types of caching to achieve high performance of its site (see, “Facebook: caching and performance” ). They use $GLOBALS and APC, which are cached at the language level (represented in PHP by calling a function), which speeds up intermediate function calls and results. (Most languages are equipped with these types of libraries to improve webpage performance, and they should almost always be used.) In addition, Facebook uses a global cache that is distributed to multiple servers (see “ Scaling memcached on Facebook” ), so that one a function call that accesses the cache could simultaneously execute multiple requests for data stored on various Memcached servers. This approach allows to achieve much higher performance and bandwidth for user profile data, and create a centralized data refresh architecture. This is important because, with thousands of servers, the cache reversal and consistency functions can be difficult.
The following discussion focuses on the algorithm of actions in the absence of data in the cache.
Proxy
At a basic level, a proxy server is an intermediate piece of hardware / software that receives requests from clients and sends them to the backend source servers. As a rule, proxies are used to filter requests, log requests, or sometimes convert requests (by adding / removing headers, encrypting / decrypting or compressing).

Figure 1.13 Proxy server
Proxies are also very useful in coordinating requests from a large number of servers, which makes it possible to optimize request traffic across the entire system. One of the ways to use a proxy to speed up data access is to combine the same or similar requests and send a single response to the request clients. This term is called collapsed forwarding.
Imagine that requests for identical data come from several nodes (let's call them littleB), but in the cache some of this data is missing. If this request is sent through a proxy, then all requests can be combined into one, and as a result of this optimization littleB will be read from disk only once. (See figure 1.14 ) In this case, you will have to sacrifice a bit of speed, since the processing of requests and their combination lead to somewhat longer delays. However, under high load, on the contrary, this will lead to improved performance, especially in the case of multiple requests for the same data. The proxy operation strategy is similar to the cache, but instead of storing data, it optimizes requests or calls to documents.
In a LAN proxy, for example, clients do not need their own IP address to connect to the Internet. Proxy combines requests from clients for the same content. However, this creates ambiguity, since many proxies are also caches (since they are a logical place to put the cache), but not all caches work as proxies.
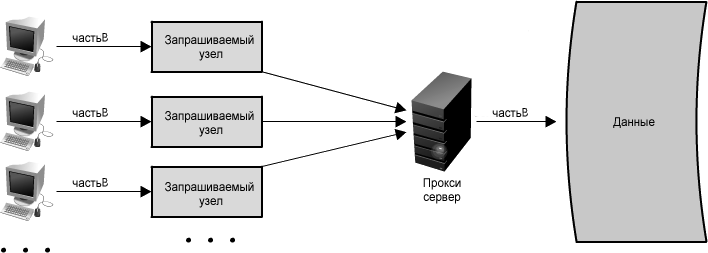
Figure 1.14: Using a proxy server to combine requests
Another great way to use a proxy is not just to combine queries for the same data, but also for pieces of data that are spatially close to each other in the source repository (sequentially on disk). Using such a strategy maximizes the locality of the data for queries, which can reduce the delay in the query. For example, if a node set requests parts B: part-B1, part-B2, etc., we can configure our proxy to recognize the spatial location of individual requests, combining them into a single request and returning only bigB, significantly minimizing reads from the data source. (See figure 1.15 ) In the case of accessing the entire terabyte of data in an arbitrary order, the time for the implementation of the request can vary greatly. Since proxies can essentially group several requests into one, they are especially useful in situations of high load or limited caching capabilities.
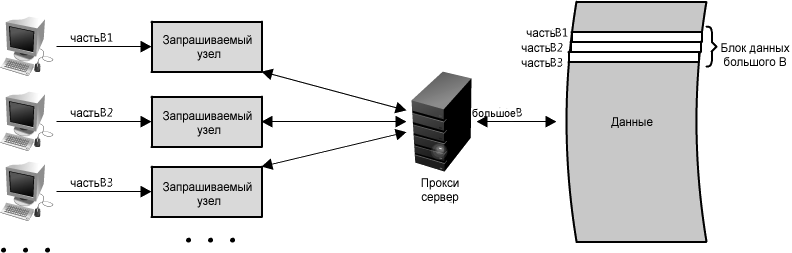
Figure 1.15: Using a proxy to combine requests for data that are spatially close to each other
It is worth noting that you can use proxies and caches together, but it is usually better to place the cache in front of the proxy for the same reason that it is better to allow faster runners to start in a marathon with more participants. This is because the cache uses data from memory, which is very fast, and this does not contradict repeated requests for the same result. But if the cache was located on the other side of the proxy server, there would be an additional delay for each request before the cache, which could reduce performance.
If you are considering adding proxies to your systems, then you have many options to choose from;
Squid and
Varnish has passed the test of time and is widely used in many productive websites. These proxy solutions offer many optimization options to get the most out of client-server data exchange. Installing one of them in the reverse proxy mode (described below in the section on load balancing) at the web server level can significantly improve the performance of the web server, reducing the amount of work required to process incoming client requests.
Indices
Using an index to get quick access to your data is a well-known strategy for effectively optimizing data access. Indexing is most widely used in databases. The index makes reciprocal concessions by using the costs of data storage volumes and reducing the speed of “write” operations (since you have to both write data and update the index at the same time), allowing you to gain in the form of faster “read” operations.
You can also apply this concept to larger data stores, just as you can to relational datasets. The trick with the indexes is a clear understanding of how users access your data. In the event that data set volumes are measured in many terabytes, and there is very little useful information in them (for example, 1 Kbyte), the use of indices is a necessity to optimize data access. Finding a small amount of useful information in such a large data set can be a real problem, since you just can’t consistently search through such a large amount of data in any reasonable time. In addition, it is very likely that such a large data set is distributed among several (or many!) Physical devices, and this means that you need to somehow find the correct physical location of the necessary data. Indexes are the best way to do this.

Figure 1.16: Indices
The index can be used as a table of contents that directs you to the location of your data. For example, let's say you are looking for a piece of data, part 2 of the section “B” - how do you know where to find it? If you have an index sorted by data type - let's call the data “A”, “B”, “C” - it will tell you the location of the data “B” in the source. Then you just have to find this location and count the part “B” that you need. (See figure 1.16)
These indexes are often stored in memory or somewhere very locally with respect to an incoming client request. Berkeley DB (BDB) and tree data structures, which are commonly used to store data in ordered lists, are ideal for access with an index.
Often there are many levels of indices that serve as a map, moving you from one location to another, etc., until you get the part of the data you need. (See figure 1.17 )
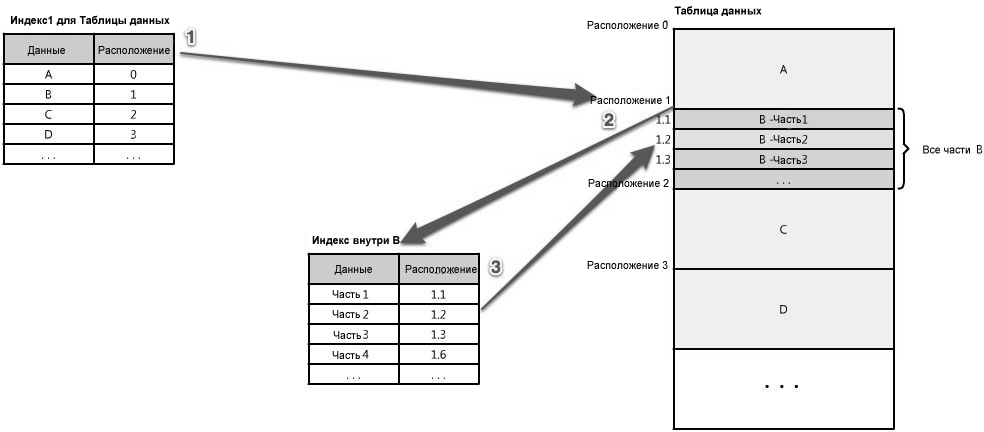
Figure 1.17: Multi-Level Indexes
Indexes can also be used to create several different views of the same data. For large data sets, this is a great way to define different filters and views without having to create many additional copies of the data.
For example, suppose that the image hosting system mentioned above actually places the images of book pages, and the service allows client requests for text in these images, searching all text content for a given topic as well as search engines let you search for HTML content. In this case, all these book images use so many servers to store files, and finding one page to present to the user can be quite complicated. Initially, reverse indexes for querying arbitrary words and word sets should be easily accessible; then there is the task of moving to the exact page and place in this book and retrieving the correct image for the search results. Thus, in this case, the inverted index would be displayed on the location (such as book B), and then B may contain an index with all the words, locations and number of occurrences in each part.
An inverted index that can display Index1 in the diagram above will look something like this: each word or set of words serves as an index for those books that contain them.
| Word (s) | Book (s) |
|---|---|
| being amazing | Book B, Book C, Book D |
| is always | Book C, Book F |
| believe | Book b |
The intermediate index will look similar, but will contain only words, location and information for Book B. This multi-level architecture allows each index to take up less space than if all this information were stored in one large inverted index.
And this is a key point in large-scale systems, because even when compressed, these indices can be quite large and costly to store. Suppose we have many books from all over the world on this system, 100,000,000 (see the “Inside Google Books” blog entry) - and that each book consists of only 10 pages (in order to simplify calculations) with 250 words on one page : this gives us a total of 250 billion words. If we take the average number of characters in a word for 5, and encode each character with 8 bits (or 1 byte, even though some characters actually take 2 bytes), thus spending 5 bytes per word, then the index containing each word only once, will require a storage capacity of more than 1 terabyte. Thus, you can see that indexes that also contain other information, such as word sets, data location and number of uses, can grow in volumes very quickly.
Creating such intermediate indexes and presenting data in smaller portions makes the “big data” problem easier to solve. Data can be distributed across multiple servers and at the same time be quickly accessible. Indices are the cornerstone of information retrieval and the basis for today's modern search engines. Of course, this section only generally concerns the topic of indexing, and a lot of research has been done on how to make indices smaller, faster, containing more information (for example, relevance), and freely updated. (There are some problems with the manageability of competing conditions, as well as the number of updates required to add new data or change existing data, especially when relevance or evaluation is involved).
The ability to quickly and easily find your data is very important, and indexes are the easiest and most effective tool for achieving this goal.
Load balancers
Finally, another critical part of any distributed system is a load balancer. Load balancers are the main part of any architecture, since their role is to distribute the load among the nodes responsible for servicing requests. This allows multiple nodes to transparently serve the same function in the system. (See Figure 1.18 .) Their main goal is to process many simultaneous connections and route these connections to one of the requested nodes, allowing the system to scale up by simply adding nodes to serve more requests.
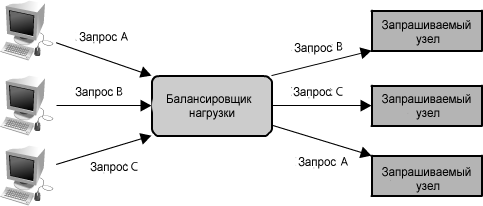
Figure 1.18: Load Balancer
There are many different algorithms for servicing requests, including the selection of a random node, a cyclic algorithm, or even a selection of a node based on certain criteria, such as CPU utilization or RAM. Load balancers can be implemented as hardware or software. Among load balancers on open source software, HAProxy is the most widely distributed.
In a distributed system, load balancers are often at the “front end” of the system, so all incoming requests pass directly through them. It is very likely that in a complex distributed system the request will have to go through several balancers, as shown in
figure 1.19 .
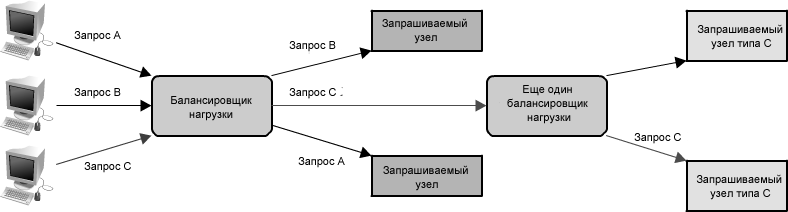
Figure 1.19: Multiple Load Balancers
Like the proxy, some load balancers may also send requests in different ways, depending on the type of request. They are also known as reverse proxies.
Managing data that is specific to a particular user session is one of the problems when using load balancers. On an e-commerce site, when you have only one customer, it is very simple to allow users to put things in their shopping cart and save its contents between visits (this is important, since the probability of selling goods increases significantly if the product returns to is in his basket). However, if the user is directed to one node for the first session, and then to another node during his next visit, inconsistencies may occur, since the new node may not have data regarding the contents of the user’s recycle bin. (Don't you get upset if you put the package of Mountain Dew drink in your basket, and when you return, it won't be there anymore?) One solution might be to make the sessions sticky, so that the user is always directed to the same node. However, taking advantage of certain reliability features, such as automatic fault tolerance, will be significantly more difficult. In this case, the user's basket will always have content, but if their sticky node becomes unavailable, a special approach will be needed, and the basket content assumption will no longer be true (although it is hoped that this assumption will not be embedded in the application). Of course, this problem can be solved with the help of other strategies and tools, as described in this chapter, such as services, and many others (such as browser caches, cookies and URL rewriting).
If the system has only a few nodes, then techniques such as a DNS carousel are likely to be more practical than load balancers, which can be expensive and increase the complexity of the system by adding an unnecessary level. Of course, in large systems there are all sorts of different algorithms for scheduling and load balancing, including both simple ones like random choices or carousel algorithms, as well as more complex mechanisms that take into account the performance features of the system usage model. All of these algorithms allow you to distribute traffic and requests, and can provide useful tools for reliability, such as automatic fault tolerance or automatic removal of a damaged node (for example, when it stops responding). However, these advanced features can make troubleshooting problems cumbersome. For example, in situations of high load, load balancers will remove nodes that may run slowly or exceed the waiting time (due to a flurry of requests), which will only aggravate the situation for other nodes. In these cases, extensive control is important because even if it seems that full system traffic and load are reduced (as the nodes serve fewer requests), individual nodes can be overloaded to the limit.
Load balancers are an easy way to increase system power. Like the other methods described in this article, it plays a significant role in the distributed system architecture. Load balancers also provide a critical function to check the health of the nodes. If, as a result of such a check, the node is not responding or overloaded, it can be removed from the query processing pool, and, due to the redundancy of your system, the load will be redistributed among the remaining working nodes.
Queues
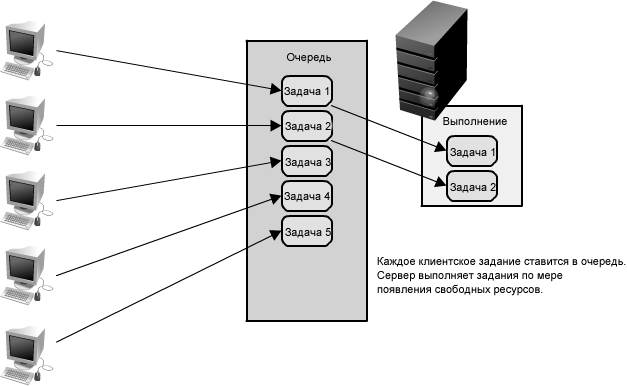
Until now, we have considered many ways to quickly read data. At the same time, another important part of data-level scaling is effective record management. , . , . , , , , , . , , . — .

1.20:
, . , . , ( ) , , . , , , , . — , 1.20 .
; , , . , , ; , . , ( ), , , . , .
1.21:
. : , , «» , . (. 1.21 .) - . , ; . , .
, . , , , . , , , , , , . , , , . — , .
. , , , - . , , , .
— , . RabbitMQ ,
ActiveMQ ,
BeanstalkD ,
Zookeeper , Redis .
1.4. Conclusion
, , . , — .
Creative Commons Attribution 3.0 . . .
To the top
The Architecture of Open Source Applications .
Source: https://habr.com/ru/post/185636/
All Articles