Process memory organization
Memory management is a central aspect of operating systems. It has a fundamental influence on the scope of programming and system administration. In several subsequent posts I will touch on issues related to the work of memory. Emphasis will be placed on practical aspects, however, we will not ignore the details of the internal structure. The concepts discussed are fairly general, but are illustrated mainly with the example of Linux and Windows running on an x86-32 computer. The first post describes the organization of the memory of user processes.
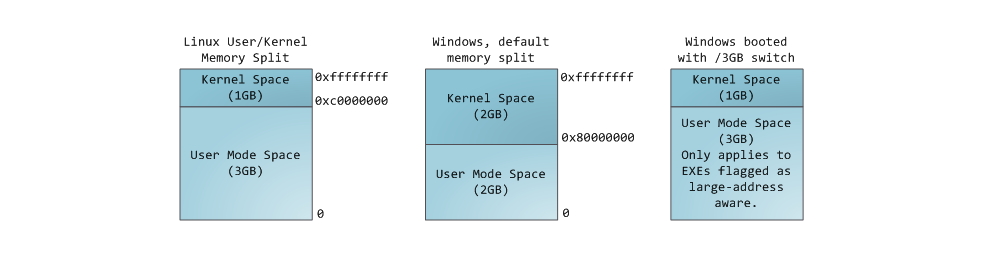
Each process in a multitasking OS is performed in its own sandbox. This sandbox is a virtual address space , which in 32-bit protected mode always has a size of 4 gigabytes . The correspondence between virtual space and physical memory is described using the page table (page table) . The kernel creates and populates the tables, and the processor accesses them if necessary to perform address translation. Each process works with its own set of tables. There is one important point - the concept of virtual addressing applies to all running software , including the kernel itself . For this reason, a part of the virtual address space (the so-called kernel space) is reserved for it.
This of course does not mean that the kernel occupies all this space, it’s just that a given address range can be used to map any part of the physical address space chosen by the kernel. Memory pages corresponding to the kernel space are marked in the page tables as available exclusively for privileged code (ring 2 or more privileged). When you try to access these pages from the user mode code, the page fault is generated. In the case of Linux, the kernel space is always present in the memory of the process, and different processes map the kernel to the same area of physical memory. Thus, the code and kernel data are always available if necessary to handle an interrupt or system call. In contrast, RAM, mapped in the user mode space, changes with each context switch.

')
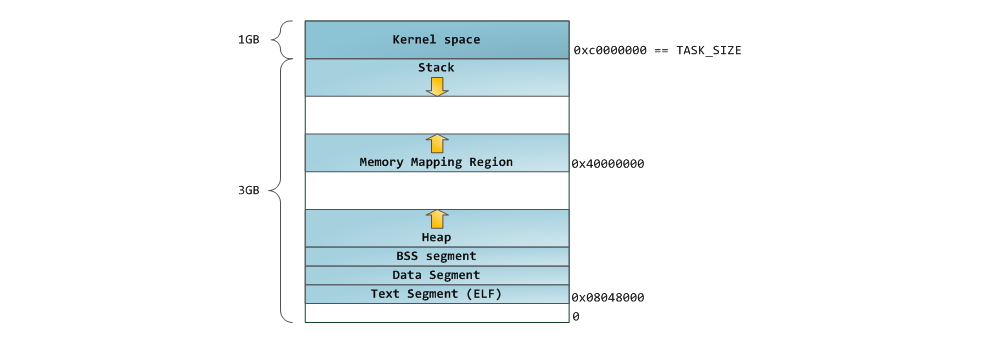
The blue color in the figure indicates the areas of the virtual address space that are assigned to the areas of physical memory; white color - not yet used areas. As you can see, Firefox used most of its virtual address space. We all know about the legendary voracity of this program in relation to RAM. The blue bars in the figure are the program's memory segments , such as heap, stack, and so on. Note that in this case, by segments, we simply mean continuous address ranges. These are not the segments that we are talking about when describing segmentation in Intel processors . Anyway, here is the standard Linux memory layout for the process:

Long ago, when computer hardware was still in its infancy, the initial virtual addresses of the segments were exactly the same for almost all the processes performed by the machine. Because of this, remote exploitation of vulnerabilities was greatly simplified. An exploit often needs to access memory at absolute addresses, for example, at some address on the stack, at the address of a library function, and so on. A hacker who expects to carry out a remote attack must choose addresses to go to the blind in the hope that the placement of program segments in memory on different machines will be identical. And when it is truly identical, it happens that people hack. For this reason, the mechanism of randomizing the arrangement of segments in the address space of a process has gained popularity. Linux randomizes the layout of the stack , the segment for the memory mapping , and the heaps — their starting address is calculated by adding an offset. Unfortunately, the 32-bit space is not very large, and the effectiveness of randomization is leveled to a certain extent .
At the top of the user mode space is the stack segment. Most programming languages use it to store local variables and arguments passed to a function. Calling a function or method results in a so-called stack being placed on the stack. stack frame When the function returns, the stack frame is destroyed. The stack is arranged quite simply - data is processed in accordance with the principle “last arrived, first served” (LIFO) . For this reason, complex control structures are not needed to track the contents of the stack — just a pointer to the top of the stack is enough. Adding data to the stack and deleting it is a quick and well-defined operation. Moreover, the repeated use of the same areas of the stack segment causes them, as a rule, to be located in the processor's cache , which speeds up access even more. Each thread within the process works with its own stack.
It is possible that the space allotted for the stack segment cannot accommodate the data being added. As a result, a page fault will be generated, which in Linux is handled by the expand_stack () function. It, in turn, will call another function - acct_stack_growth () , which is responsible for checking whether the stack can be expanded. If the size of the stack segment is less than the value of the RLIMIT_STACK constant (usually 8 MB), then it grows and the program continues to run as if nothing had happened. This is the standard mechanism by which the size of a stack segment is increased according to need. However, if the maximum resolved size of the stack segment is reached, then stack overflow occurs, and the Segmentation Fault signal is sent to the program. The stack segment can grow if necessary, but never decreases, even if the stack structure contained in it itself becomes smaller. Like the federal budget, the stack segment can only grow.
Dynamic stack building is the only situation when accessing a “non-mapped” memory area can be regarded as a valid operation. Any other call causes the page fault to be generated, followed by a Segmentation Fault. Some used areas are marked read-only, and accessing them also results in a Segmentation Fault.
Under the stack is a segment for memory mapping. The kernel uses this segment to map (map to memory) the contents of files. Any application can use this functionality through the mmap () system call ( link to the description of the mmap call implementation ) or CreateFileMapping () / MapViewOfFile () in Windows. Mapping files to memory is a convenient and high-performance file I / O method, and it is used, for example, to load dynamic libraries. It is possible to perform anonymous memory mapping (anonymous memory mapping) , with the result that we will get an area in which no file is mapped, and which is instead used to host all sorts of data with which the program works. If Linux requests a large block of memory to be allocated using malloc () , then instead of allocating memory on the heap, the standard C library uses an anonymous mapping mechanism. The word “large” in this case means a value in bytes greater than the value of the MMAP_THRESHOLD constant. By default, this value is equal to 128 KB, and can be controlled by calling mallopt () .
Speaking of the heap. It goes next in our description of the process address space. Like a stack, a heap is used to allocate memory during program execution. Unlike the stack, the memory allocated on the heap will be saved after the function that caused the allocation of this memory is completed. Most languages provide heap memory management. Thus, the kernel and the language runtime together implement the dynamic allocation of additional memory. In C, the heap interface is the malloc () family of functions, while in languages with garbage collection support, like C #, the main interface is the new operator.
If the current heap size allows you to allocate the requested amount of memory, the allocation can be done by means of the runtime alone, without involving the kernel. Otherwise, the malloc () function uses the brk () system call for the required heap increase ( refer to the description of the brk call implementation ). Heap memory management is a non - trivial task , for solving which complex algorithms are used. These algorithms strive to achieve high speed and efficiency in conditions of unpredictable and chaotic memory allocation patterns in our programs. The time spent on each heap memory request can be dramatically different. To solve this problem, real-time systems use specialized memory allocators . The heap is also subject to fragmentation , which, for example, is shown in the figure:

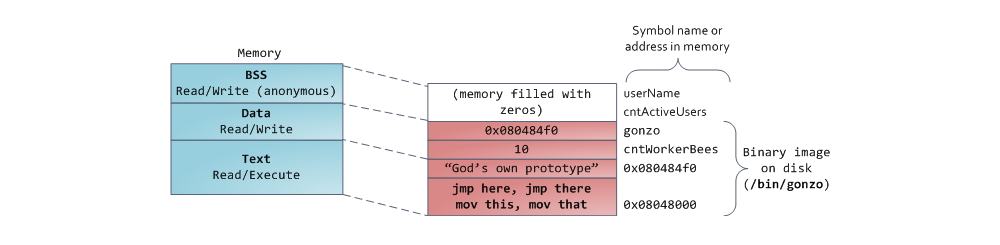
Finally, we got to the segments located in the lower part of the process address space: BSS, data segment (data segment) and code segment (text segment). The BSS and data segment store data that corresponds to static variables in the source code in C. The difference is that the BSS stores data corresponding to uninitialized variables, whose values are not explicitly indicated in the source code ( in fact, there are objects that are created when the declaration of the variable either explicitly indicates a zero value, or the value is not initially indicated, and the linked files do not contain the same common characters, with a non-zero value . Anonymous mapping is used for the BSS segment, i.e. no file is mapped to this segment. If you use int cntActiveUsers in the C source file, then the space for the corresponding object will be allocated in the BSS.
Unlike BSS, the data segment stores objects that correspond to the source code in which they declare static variables initialized with a non-zero value. This memory segment is not anonymous - part of the program image is mapped to it. Thus, if we use static int cntWorkerBees = 10 , then the space for the corresponding object will be allocated in the data segment, and it will store the value 10. Although the data segment displays the file, this is the so-called “Private memory mapping” . This means that changes to the data in this segment will not affect the content of the corresponding file. So it should be, otherwise the assignment of values to global variables would lead to a change in the contents of the file stored on disk. In this case, it is not necessary at all!
With pointers everything is a little more complicated. In the example from our diagrams, the contents of the object corresponding to the variable gonzo — this is a 4-byte address — is placed in the data segment. But the string referenced by the pointer does not fall into the data segment. The string will be in a code segment that is read-only and stores all your code and such trifles as, for example, string literals ( in fact, the string is stored in the .rodata section, which, together with other sections containing executable code, is treated as a segment that is loaded into memory with rights to execute code / read data - note. translation. ). A part of the executable file is also mapped to the code segment. If your program attempts to write to the text segment, then Segmentation Fault will work. This allows you to deal with "bazhnymi" pointers, although the best way to deal with them is not to use C at all. Below is a diagram depicting the segments and variables of our examples:
We can see how the process memory is used by reading the contents of the / proc / pid_of_process / maps file. Please note that the contents of the segment itself may consist of different areas. For example, each dynamic library segment mapped into memory mapping is assigned its own area, and in it you can select areas for the BSS and data library segments. In the next post we explain what exactly is meant by the word "region". Consider that sometimes people say “data segment”, meaning data + BSS + heap.
You can use the nm and objdump utilities to view the contents of binary executable images: characters, their addresses, segments, etc. Finally, what is described in this post is the so-called “flexible” organization of process memory (flexible memory layout), which has been used by default in Linux for several years. This scheme assumes that we have defined the value of the constant RLIMIT_STACK. When this is not the case, Linux uses a so-called. classic organization, which is shown:
Well that's all. This concludes our discussion of the organization of the memory process. In the next post we will look at how the kernel tracks the sizes of the described memory areas. We will also touch upon the question of mapping, what does reading and writing files have to do with it, and what the numbers describing memory usage mean.
Material prepared by employees of the company Smart-Soft
smart-soft.ru
Source: https://habr.com/ru/post/185226/
All Articles