Speech technology. Recognition of continuous speech for teapots on the example of IVR systems
Hello.
By the nature of my professional activity, I am engaged in the implementation of projects based on speech technologies. These are speech synthesis and recognition, voice biometrics and speech analysis.
Few people think about how these technologies are already present in our lives, although far from always - obviously.
I will try to popularly explain to you how it works and why it is needed at all.
I will start with speech recognition in detail. this is a closer to everyday life thing that many of us have met, and some already use it all the time.
But first, let's try to understand what speech technologies are and what they can be.
- Synthesis of speech (text-to-speech).
With this technology, we still face a little in real life. Or just do not notice it.
There are special "readers" for iOS and Android, capable of reading aloud the books that you download to your device. They read quite tolerably, after a day or two you no longer notice that the text is being read by a robot.
In many call centers, a synthesized voice voices dynamic information to subscribers, since it is rather difficult to record in advance all sound clips voiced by a person, especially if the information changes every 3 seconds
For example, in the Metropolitan of St. Petersburg, many informational messages at the stations are read by synthesis, but almost no one notices this, since The text sounds pretty good.
- Voice biometrics (search and confirmation of the person by voice).
Yes, yes - the human voice is as unique as a fingerprint or retina. The reliability of verification (comparison of two voice prints) reaches 98%. For this, 74 voice parameters are analyzed.
In everyday life, technology is still very rare. But trends suggest that soon it will be widespread, especially in call centers of financial companies. Their interest in this technology is very big.
Voice biometrics has 2 unique features:
- This is the only technology that allows you to verify your identity remotely, for example, by phone. And this does not require special scanning devices.
- this is the only technology that confirms human activity, i.e. what a live person is talking on the phone. I’ll say right away that the voice recorded on a quality voice recorder will not work - it’s proven. If somewhere such a record "passes", then the low threshold of "trust" is initially incorporated into the system.
')
- Speech analysis.
Few people know that a person’s mood, emotional state, gender, approximate weight, national identity, etc. can be determined by voice.
Of course, no car will be able to immediately say whether a person is sad or happy (it is quite possible that he always has such a state of life: for example, the average speech of Italian and Finn is very different in temperament), but by changing the voice during a conversation, it’s already is quite real.
- Speech recognition (speech to text).
This is the most common speech technology in our lives, and first of all - thanks to mobile devices, because Many manufacturers and developers believe that it is much more convenient for a person to say something in a smartphone than to type the same text on a small screen keyboard.
I suggest first to talk about this: where do we meet with speech recognition technology in life and how do we even know about it?
Most of us will immediately recall Siri (iPhone), Google Voice Search, sometimes - voice-activated IVR systems in some call centers, such as Russian Railways, Aeroflot, etc.
This is what lies on the surface, and what you can easily try for yourself.
There is speech recognition built into the car’s system (dialing a phone number, radio control), TVs, infomats (things like those that take money for mobile operators). But this is not very common and is practiced more as a "trick" of certain manufacturers. The point is not even in technical limitations and quality of work, but in the usability and habits of people. I have no idea about the person who’s flipping through programs on the TV with his voice when there is a remote control at hand.
So. Speech recognition technology. What are they like?
I want to say right away that almost all my work is connected with telephony, so many examples in the text below will be taken from there - from the practice of call centers.
Recognition by closed grammar.
Recognition of one word (voice command) from the list of words (base).
The concept of "closed grammar" means that the system contains a certain final database of words in which the system will search for the word or expression spoken by the subscriber.
In this case, the system should put the question to the subscriber in such a way that to get an unambiguous answer consisting of one word.
Example:
System question: “What day of the week are you interested in?”
Subscriber response: "Tuesday"
In this example, the question is posed so that the system expects a completely definite answer from the subscriber.
The base of words in the given example may consist of the following answers: “Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday”. The following answers should be foreseen and included in the database: “I do not know,” “not care”, “any”, etc. - these answers of the subscriber should also be provided for and processed by the system separately, according to the predefined scenario of the dialogue.
Built-in grammar.
This is a kind of closed grammars.
Recognition of frequently requested standard expressions and concepts.
The term “embedded grammar” means that the system already contains grammars (that is, it does not need to be separately trained) that can recognize specific subject phrases of the subscriber. When writing a dialogue script, you just need to refer to a specific built-in grammar.
Example:
The question of the system: "At what time the film interests you?"
Caller response: "At 15.30"
In the given example, time values are recognized. All the necessary time recognition grammar is already embedded in the system.
Built-in grammars serve to simplify the design of voice menus, when standard universal blocks can be used.
Recognition by open grammar.
Recognition of the entire phrase uttered by the subscriber.
This allows the system to ask the subscriber an open question and get an answer formulated in a free form.
The term "open grammar" means that the system expects to hear from the subscriber not a specific word / command, but the entire semantic sentence, in which every word will interest the system.
Example:
System question: “What are you interested in?”
Subscriber response: "What documents are needed for a loan?"
In this example, each word is recognized in the subscriber’s response and the general meaning of what was said is revealed. Based on the recognized keywords and concepts in the proposal, a request is made to the database and the answer is “collected” by the subscriber - reference information is provided.
Recognition of continuous speech gives the system many more opportunities to automate the process of dialogue with the subscriber. Plus, this increases the speed and convenience of using the system by the subscriber. But such systems are more difficult to implement. If the solution of the problem may involve one-step answers of the subscriber, then it is better to use closed grammars.
They work more reliably, such systems are simple to implement and more common for subscribers who are used to using DTMF dialing (navigation using dialing numbers in tone mode).
But the future, of course, for the combined recognition of speech. Gradually, users will get used to this and will not “hang” for 5-10 seconds when the system invites them to enter into an open dialogue with it.
How does IVR system with continuous speech recognition work?
On the example of VoiceNavigator software - the synthesis and recognition of Russian speech for the IVR system.
! Caution. Further there will be a more complex text to understand.
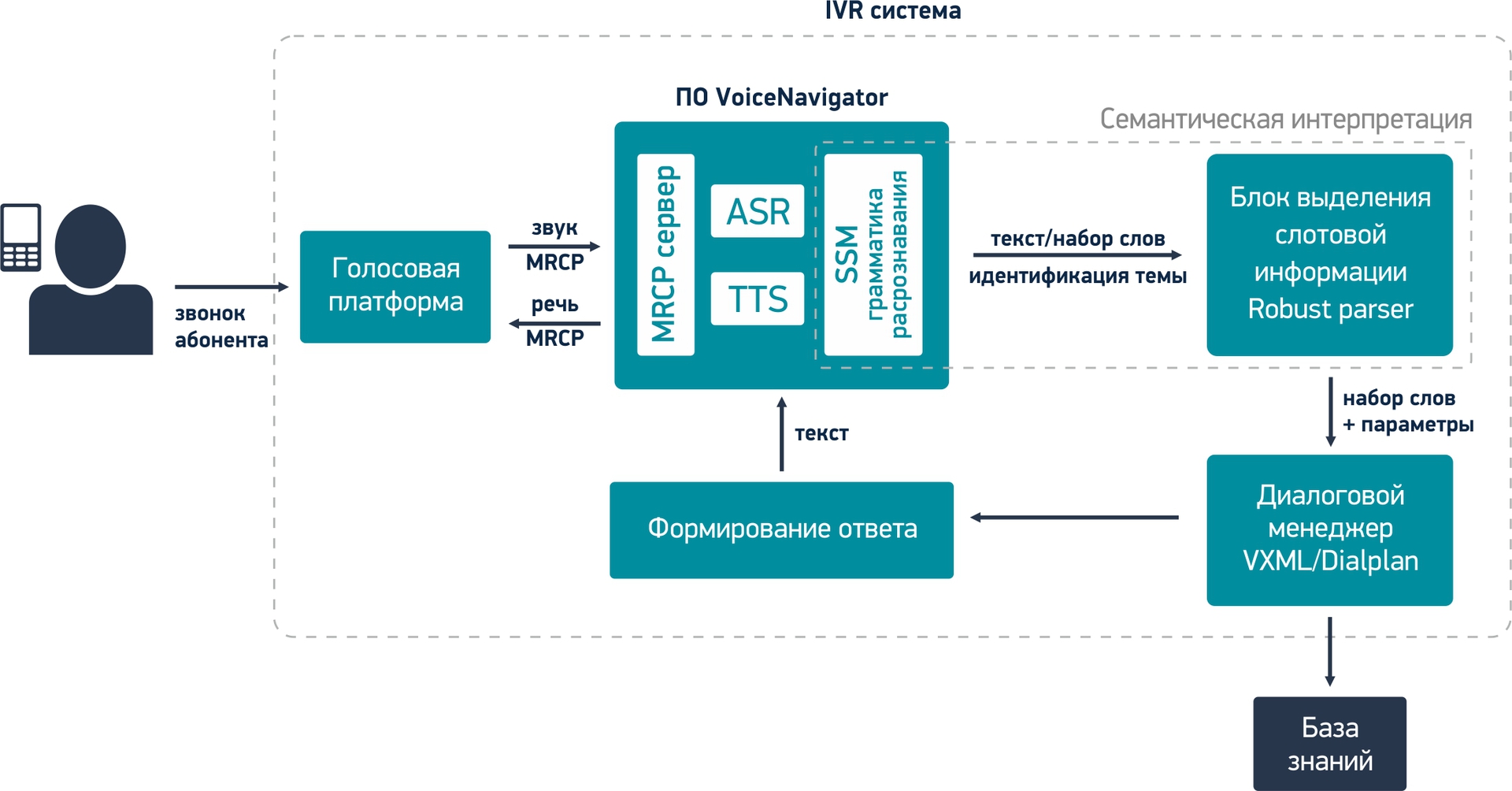
1. Immediately dwell on the fact that the call came to the call center and was transferred to a voice platform. The voice platform is software that is engaged in working out all the logic of the subscriber’s dialogue with the system, i.e. On the voice platform, the IVR menu works. The most popular voice platforms are Avaya, Genesys, Cisco, and Asterisk.
So, the voice platform transmits sound from the subscriber’s phone microphone to VoiceNavigator.
2. Sound enters the speech recognition module (ASR), which converts a person's speech into text as a sequence of separately composed words. The resulting words have no meaning for the system yet.
An example of the voice phrase of the subscriber on the topic of train schedules:

3. Further, the text gets into the SSM module of the recognition grammar (I will not stop here, who will want to delve into the subject, he can find it himself. This will also apply to the rest of the terms below), where the resulting words are analyzed for subjects of statements (what topic is recognized phrase). In our example, the recognized phrase relates to the topic: “Long-distance trains” and has its own unique identifier.
4. Then the text along with the theme identifier is transmitted to the slot information allocation module (robust parser), in which certain concepts and expressions that are important for the given subject area are highlighted (meaning of the user's statement). In this module, the system “understands” what the subscriber said and analyzes whether this information is enough to form a request to the knowledge base or clarifying questions are required.

The slot information selection module forms certain parameters that are passed on to the dialog manager along with the recognized words.
5. The Dialogue Manager is engaged in processing the entire logic (algorithm) of the dialogue of the IVR system with the subscriber. Based on the transmitted parameters, the dialog manager can send a request to the knowledge base (the subscriber’s speech contains all the information) to form a response to the subscriber or request additional information from the subscriber, specify the request (not all the information is contained in the subscriber’s speech).
6. To form a response to the subscriber, the dialogue manager contacts the knowledge base. It contains all the information on the subject area.
7. Next, the system generates a response to the subscriber based on information from the knowledge base and in accordance with the dialogue scenario from the dialogue manager.
8. After giving the answer to the subscriber, the IVR system is ready to continue working.
How to start when creating an IVR system based on speech recognition?
Learning speech recognition system.
1. The basis of continuous speech recognition is statistics. Therefore, any project on the introduction of IVR systems using continuous speech recognition begins with the collection of statistics. You need to know what subscribers are interested in, how they formulate questions, what kind of information they initially possess, what they expect to hear in response, etc.
The collection of information begins with listening to and analyzing the real recordings of conversations of subscribers with CC operators. Based on this information, statistical tables are built, from which it becomes clear which voice calls of subscribers need to be automated, and how this can be done.
2. This information becomes sufficient to create a simplified prototype of the future IVR menu. Such a prototype is necessary for collecting and analyzing more relevant answers of subscribers to the IVR menu questions, since the manner of communication of subscribers with CC operators and with voice IVR menu is very different.
The prototype IVR menu created is placed on the incoming phone number to the company. It can be simplified as much as possible, or not at all work out the functionality, since its main task is to accumulate statistical material (various subscriber answers), which will be the basis for the formation of a statistical language model (SLM) aimed at a specific subject. The flexibility of the language model for a particular subject area allows for improved recognition quality.
An example implementation of the IVR prototype menu:
System question: “What service are you interested in?”
Subscriber response: "I would like to take a loan"
System response: "The call will be transferred to the contact center operator"
System Action: Transfer to the KC operator for any answer from the subscriber.
Using the IVR prototype menu, the developer creates an emulation of the system and collects real recordings of subscribers' answers (phonogram collection), which the system will later be trained on.
It does not matter what the subscriber says to the question of the system, in any case the call will be transferred to the contact center operator. Thus, the subscriber will be served without causing inconvenience to him, and the IVR menu developers will receive a base of all possible answers on this topic using the example of a real dialogue.
The required number of phonograms for the implementation of the project can reach several thousand, and the time to collect phonograms can take several months. It all depends on the complexity of the project.
3. Then the collected recordings of conversations are transcribed. Each entry is listened by a specialist and translated into text. Transcribed phrases must not contain punctuation marks and special characters. Also, all words and abbreviations must be spelled out completely, as the client pronounces them. This work takes a lot of time, but does not require specific knowledge, therefore, many employees are usually involved at the same time.
4. Transcribed files are used to build a training file (dictionary of words and expressions, configuration parameters), which is an XML document. The longer the training file for the subject area is, the better the recognition will be.
The training file allows you to create a language model (SLM), which is the basis of continuous speech recognition.
For this, the training file is loaded into a special utility developed by the MDG company (it is the author of the VoiceNavigator software) - ASR Constructor, which builds the language model. The language model is then loaded into the VoiceNavigator software.
At this stage of work on the construction of a speech IVR menu, the system is able to recognize the subscriber's speech in the form of separately composed words that are not connected with each other.

5. Then, in the recognized list of words, it is necessary to identify the subject of the subscriber’s address (SSM recognition grammar) and select slot information (Robust parser). This requires additional training system using the appropriate training files.
Training files can be created on the basis of previously transcribed files. But in contrast to the task of obtaining a language model, transcribed files must be appropriately modified to suit them for SSM grammar and Robust parser.
Well, the beginning of the article was easy enough to understand those who are not familiar with speech technology at all. And then I plunged into the subtleties of creating real voice self-service systems. I apologize for such metamorphosis.
Who is interested in this topic, and he wants to learn more about the creation of IVR systems with voice control, I want to recommend to visit a special wiki site - www.vxml.ru
It is dedicated to the development of IVR systems in the VoiceXML conversational language, which is central to this work.
Thank.
By the nature of my professional activity, I am engaged in the implementation of projects based on speech technologies. These are speech synthesis and recognition, voice biometrics and speech analysis.
Few people think about how these technologies are already present in our lives, although far from always - obviously.
I will try to popularly explain to you how it works and why it is needed at all.
I will start with speech recognition in detail. this is a closer to everyday life thing that many of us have met, and some already use it all the time.
But first, let's try to understand what speech technologies are and what they can be.
- Synthesis of speech (text-to-speech).
With this technology, we still face a little in real life. Or just do not notice it.
There are special "readers" for iOS and Android, capable of reading aloud the books that you download to your device. They read quite tolerably, after a day or two you no longer notice that the text is being read by a robot.
In many call centers, a synthesized voice voices dynamic information to subscribers, since it is rather difficult to record in advance all sound clips voiced by a person, especially if the information changes every 3 seconds
For example, in the Metropolitan of St. Petersburg, many informational messages at the stations are read by synthesis, but almost no one notices this, since The text sounds pretty good.
- Voice biometrics (search and confirmation of the person by voice).
Yes, yes - the human voice is as unique as a fingerprint or retina. The reliability of verification (comparison of two voice prints) reaches 98%. For this, 74 voice parameters are analyzed.
In everyday life, technology is still very rare. But trends suggest that soon it will be widespread, especially in call centers of financial companies. Their interest in this technology is very big.
Voice biometrics has 2 unique features:
- This is the only technology that allows you to verify your identity remotely, for example, by phone. And this does not require special scanning devices.
- this is the only technology that confirms human activity, i.e. what a live person is talking on the phone. I’ll say right away that the voice recorded on a quality voice recorder will not work - it’s proven. If somewhere such a record "passes", then the low threshold of "trust" is initially incorporated into the system.
')
- Speech analysis.
Few people know that a person’s mood, emotional state, gender, approximate weight, national identity, etc. can be determined by voice.
Of course, no car will be able to immediately say whether a person is sad or happy (it is quite possible that he always has such a state of life: for example, the average speech of Italian and Finn is very different in temperament), but by changing the voice during a conversation, it’s already is quite real.
- Speech recognition (speech to text).
This is the most common speech technology in our lives, and first of all - thanks to mobile devices, because Many manufacturers and developers believe that it is much more convenient for a person to say something in a smartphone than to type the same text on a small screen keyboard.
I suggest first to talk about this: where do we meet with speech recognition technology in life and how do we even know about it?
Most of us will immediately recall Siri (iPhone), Google Voice Search, sometimes - voice-activated IVR systems in some call centers, such as Russian Railways, Aeroflot, etc.
This is what lies on the surface, and what you can easily try for yourself.
There is speech recognition built into the car’s system (dialing a phone number, radio control), TVs, infomats (things like those that take money for mobile operators). But this is not very common and is practiced more as a "trick" of certain manufacturers. The point is not even in technical limitations and quality of work, but in the usability and habits of people. I have no idea about the person who’s flipping through programs on the TV with his voice when there is a remote control at hand.
So. Speech recognition technology. What are they like?
I want to say right away that almost all my work is connected with telephony, so many examples in the text below will be taken from there - from the practice of call centers.
Recognition by closed grammar.
Recognition of one word (voice command) from the list of words (base).
The concept of "closed grammar" means that the system contains a certain final database of words in which the system will search for the word or expression spoken by the subscriber.
In this case, the system should put the question to the subscriber in such a way that to get an unambiguous answer consisting of one word.
Example:
System question: “What day of the week are you interested in?”
Subscriber response: "Tuesday"
In this example, the question is posed so that the system expects a completely definite answer from the subscriber.
The base of words in the given example may consist of the following answers: “Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday”. The following answers should be foreseen and included in the database: “I do not know,” “not care”, “any”, etc. - these answers of the subscriber should also be provided for and processed by the system separately, according to the predefined scenario of the dialogue.
Built-in grammar.
This is a kind of closed grammars.
Recognition of frequently requested standard expressions and concepts.
The term “embedded grammar” means that the system already contains grammars (that is, it does not need to be separately trained) that can recognize specific subject phrases of the subscriber. When writing a dialogue script, you just need to refer to a specific built-in grammar.
Example:
The question of the system: "At what time the film interests you?"
Caller response: "At 15.30"
In the given example, time values are recognized. All the necessary time recognition grammar is already embedded in the system.
Built-in grammars serve to simplify the design of voice menus, when standard universal blocks can be used.
Recognition by open grammar.
Recognition of the entire phrase uttered by the subscriber.
This allows the system to ask the subscriber an open question and get an answer formulated in a free form.
The term "open grammar" means that the system expects to hear from the subscriber not a specific word / command, but the entire semantic sentence, in which every word will interest the system.
Example:
System question: “What are you interested in?”
Subscriber response: "What documents are needed for a loan?"
In this example, each word is recognized in the subscriber’s response and the general meaning of what was said is revealed. Based on the recognized keywords and concepts in the proposal, a request is made to the database and the answer is “collected” by the subscriber - reference information is provided.
Recognition of continuous speech gives the system many more opportunities to automate the process of dialogue with the subscriber. Plus, this increases the speed and convenience of using the system by the subscriber. But such systems are more difficult to implement. If the solution of the problem may involve one-step answers of the subscriber, then it is better to use closed grammars.
They work more reliably, such systems are simple to implement and more common for subscribers who are used to using DTMF dialing (navigation using dialing numbers in tone mode).
But the future, of course, for the combined recognition of speech. Gradually, users will get used to this and will not “hang” for 5-10 seconds when the system invites them to enter into an open dialogue with it.
How does IVR system with continuous speech recognition work?
On the example of VoiceNavigator software - the synthesis and recognition of Russian speech for the IVR system.
! Caution. Further there will be a more complex text to understand.
1. Immediately dwell on the fact that the call came to the call center and was transferred to a voice platform. The voice platform is software that is engaged in working out all the logic of the subscriber’s dialogue with the system, i.e. On the voice platform, the IVR menu works. The most popular voice platforms are Avaya, Genesys, Cisco, and Asterisk.
So, the voice platform transmits sound from the subscriber’s phone microphone to VoiceNavigator.
2. Sound enters the speech recognition module (ASR), which converts a person's speech into text as a sequence of separately composed words. The resulting words have no meaning for the system yet.
An example of the voice phrase of the subscriber on the topic of train schedules:
3. Further, the text gets into the SSM module of the recognition grammar (I will not stop here, who will want to delve into the subject, he can find it himself. This will also apply to the rest of the terms below), where the resulting words are analyzed for subjects of statements (what topic is recognized phrase). In our example, the recognized phrase relates to the topic: “Long-distance trains” and has its own unique identifier.
4. Then the text along with the theme identifier is transmitted to the slot information allocation module (robust parser), in which certain concepts and expressions that are important for the given subject area are highlighted (meaning of the user's statement). In this module, the system “understands” what the subscriber said and analyzes whether this information is enough to form a request to the knowledge base or clarifying questions are required.
The slot information selection module forms certain parameters that are passed on to the dialog manager along with the recognized words.
5. The Dialogue Manager is engaged in processing the entire logic (algorithm) of the dialogue of the IVR system with the subscriber. Based on the transmitted parameters, the dialog manager can send a request to the knowledge base (the subscriber’s speech contains all the information) to form a response to the subscriber or request additional information from the subscriber, specify the request (not all the information is contained in the subscriber’s speech).
6. To form a response to the subscriber, the dialogue manager contacts the knowledge base. It contains all the information on the subject area.
7. Next, the system generates a response to the subscriber based on information from the knowledge base and in accordance with the dialogue scenario from the dialogue manager.
8. After giving the answer to the subscriber, the IVR system is ready to continue working.
How to start when creating an IVR system based on speech recognition?
Learning speech recognition system.
1. The basis of continuous speech recognition is statistics. Therefore, any project on the introduction of IVR systems using continuous speech recognition begins with the collection of statistics. You need to know what subscribers are interested in, how they formulate questions, what kind of information they initially possess, what they expect to hear in response, etc.
The collection of information begins with listening to and analyzing the real recordings of conversations of subscribers with CC operators. Based on this information, statistical tables are built, from which it becomes clear which voice calls of subscribers need to be automated, and how this can be done.
2. This information becomes sufficient to create a simplified prototype of the future IVR menu. Such a prototype is necessary for collecting and analyzing more relevant answers of subscribers to the IVR menu questions, since the manner of communication of subscribers with CC operators and with voice IVR menu is very different.
The prototype IVR menu created is placed on the incoming phone number to the company. It can be simplified as much as possible, or not at all work out the functionality, since its main task is to accumulate statistical material (various subscriber answers), which will be the basis for the formation of a statistical language model (SLM) aimed at a specific subject. The flexibility of the language model for a particular subject area allows for improved recognition quality.
An example implementation of the IVR prototype menu:
System question: “What service are you interested in?”
Subscriber response: "I would like to take a loan"
System response: "The call will be transferred to the contact center operator"
System Action: Transfer to the KC operator for any answer from the subscriber.
Using the IVR prototype menu, the developer creates an emulation of the system and collects real recordings of subscribers' answers (phonogram collection), which the system will later be trained on.
It does not matter what the subscriber says to the question of the system, in any case the call will be transferred to the contact center operator. Thus, the subscriber will be served without causing inconvenience to him, and the IVR menu developers will receive a base of all possible answers on this topic using the example of a real dialogue.
The required number of phonograms for the implementation of the project can reach several thousand, and the time to collect phonograms can take several months. It all depends on the complexity of the project.
3. Then the collected recordings of conversations are transcribed. Each entry is listened by a specialist and translated into text. Transcribed phrases must not contain punctuation marks and special characters. Also, all words and abbreviations must be spelled out completely, as the client pronounces them. This work takes a lot of time, but does not require specific knowledge, therefore, many employees are usually involved at the same time.
4. Transcribed files are used to build a training file (dictionary of words and expressions, configuration parameters), which is an XML document. The longer the training file for the subject area is, the better the recognition will be.
The training file allows you to create a language model (SLM), which is the basis of continuous speech recognition.
For this, the training file is loaded into a special utility developed by the MDG company (it is the author of the VoiceNavigator software) - ASR Constructor, which builds the language model. The language model is then loaded into the VoiceNavigator software.
At this stage of work on the construction of a speech IVR menu, the system is able to recognize the subscriber's speech in the form of separately composed words that are not connected with each other.
5. Then, in the recognized list of words, it is necessary to identify the subject of the subscriber’s address (SSM recognition grammar) and select slot information (Robust parser). This requires additional training system using the appropriate training files.
Training files can be created on the basis of previously transcribed files. But in contrast to the task of obtaining a language model, transcribed files must be appropriately modified to suit them for SSM grammar and Robust parser.
Well, the beginning of the article was easy enough to understand those who are not familiar with speech technology at all. And then I plunged into the subtleties of creating real voice self-service systems. I apologize for such metamorphosis.
Who is interested in this topic, and he wants to learn more about the creation of IVR systems with voice control, I want to recommend to visit a special wiki site - www.vxml.ru
It is dedicated to the development of IVR systems in the VoiceXML conversational language, which is central to this work.
Thank.
Source: https://habr.com/ru/post/184832/
All Articles