How Yandeks.Pochta began to understand what you need
What exactly did we do
What if the mail starts doing the routine work for you regarding the content of the letter? For example, it will help not to forget about an important event, will remind you of the upcoming departure to the sea, will give the necessary links and useful information. My colleagues from the linguistics department used a very special technology that we hope will change the idea of what e-mail is.
This technology allows you to automatically apply special algorithms to the content of the letter and extract certain facts from it in the form of a structure understandable to the computer. Thanks to her, Yandex.Mail can now provide you with more contextual information related to your letter.
')
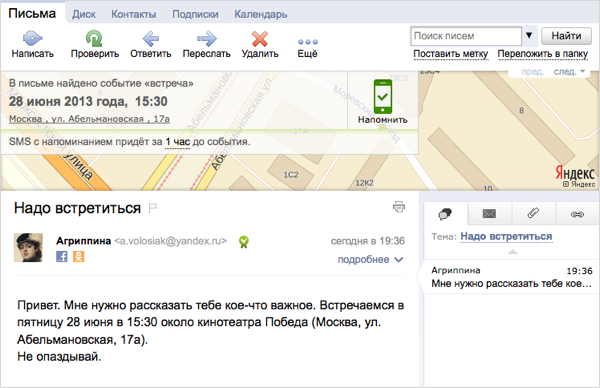
For example, if the letter contains invitations to any event and indicates exactly where it will take place, we will show this place on the map and help you not to get lost.
What technologies are behind the scenes
So, you have received a letter from a friend, where he is calling you to an interesting conference or to the cinema. From a computer point of view, this text is nothing more than a set of bytes. But a person can highlight key objects and images in the text.
The processing of a letter in Yandex.Mail begins at the moment it is received and saved (we call this process “laying”). Spam Defense uses heuristic algorithms for checking and determines which type it may be: an electronic ticket for a plane, a letter from a social network, a letter from a person, or so on.
Depending on which type the letter will be assigned to, the text at the time of viewing - in terms of extracting facts, it is called a document - is sent for retrieval to a particular processor. Factors are simple and fast (for example, simple regular expressions) and quite complex.
Many methods that allow a machine to understand a text in natural language and algorithms implementing this possibility are part of a more general task of extracting information. Yandex.Mail retrieves event invitations using the Tomita parser , which is based on the Masaru Tomita algorithm. Access to it was open at the end of 2012.
Tomita's parser itself is a tool for writing context-free grammars. With its help, any person can describe a set of templates by which text will be structured. The parser works on the basis of keywords dictionaries and rules written by linguists. Dictionaries can be quite large.
How events are recognized in the letter
Consider the work of the parser by example. You receive a letter containing the following text:
"On November 21, 2013, the Tenth Conference on Typology and Grammar for Young Researchers will be held at the Institute of Linguistic Studies of the Russian Academy of Sciences (St. Petersburg)."
In Tomita there is evidence of which words may be the “peaks” of the invitation. For example, the verb "invite", "pass", "take place" - here there is a form of the verb "pass." The "top" has a set of components that must be filled. To get an event, the sentence, in addition to the verb itself, must contain the name of the event and its date. In the case of the verb "pass", the name of the event must be the subject, in other contexts it can be expressed by other syntactic roles. For example, the verb “invite” requires that an event be expressed by an addition (to invite to a conference, invite to visit).
In addition to the date and title, the event may contain a place and time. Organizations and addresses are distinguished by grammar in internal structure and in dictionaries. For example, if the title contains the keyword “institution, bank, hotel”, then these keywords with dependent words will be extracted as a company. In the example above, the “Institute of Linguistic Studies of the RAS” is extracted.
The block with information about the event is displayed in the Yandex.Mail interface at the moment of opening the letter in the noticeable top of the page. With this arrangement, the time to extract the facts is critical - it is impossible to significantly increase the waiting time of the user. It must be admitted that it was not at the first attempt that we managed to achieve sufficient performance. The volume of the parser’s own knowledge of the Russian language together with dictionaries takes about 1 GB. Every second about 1000 letters are shown in Yandex.Mail, and for each of them it is necessary to select facts and transfer them to the frontend for display. Despite the active use of client side caching, the number of retrieval requests remained too large to be able to meet the agreed time.
Algorithms Tomits process the text sequentially. Therefore, the larger the document itself, the more time is needed to process it. Therefore, in order to speed it up, we split the text into several parts and each of them is processed separately in a parallel stream. Moreover, we break the text along the boundaries of sentences - thus the probability of losing important information is reduced. The response rate has grown, but the computing resources of the existing cluster were not enough to handle this data flow.
Of course, it was possible to increase the number of machines involved in extracting the facts, but we decided to put a preliminary filter in front of Tomita, which determines whether there can be an event in the document or not. In the latter case, the text does not need to be sent to a full extract. Moreover, we deliberately picked up such a regexp, which gives probably more false positives. The number of requests to the parser decreased by half, and we were able to unload the machines and free up resources for other tasks.
Events are contained in 3.5% of letters and every day we extract information from more than a million events. Now in our case there are about 500 templates, another 3,500 are on the way, which will help us to drastically improve the accuracy of work.
How to parry e-tickets
Some time after the retrieval of events was launched, we thought that we could help Yandex.Mail users and in a special way show the information that is in each electronic ticket. For example, you can report destinations without going into a letter, additionally highlight an electronic ticket in the list of letters, or, for example, show the weather in the city of arrival.
For tickets consisting of simple text, we used the same Tomita parser, but most of the letters from booking systems and airlines contain html markup and almost do not contain natural language. Tomita works poorly in such conditions, so we took the technology as the basis, which showed itself remarkably well in Yandex.Market. We use the html markup of the document as an xml tree of tags and build templates for different senders. Before parsing the tree, we additionally process the document and bring it to a correct xml view.
For these patterns, which are mainly composed of regular expressions and xpath, we select the necessary information and form the answer. It is not always possible to isolate an element of the tree so that it contains only the necessary part of the information — about a third of the cases, the element contains a sentence with key information. So we remembered Tomita again and created a set of grammars to parse such sentences.
After extracting the basic information about the ticket from the letter, we update it in Yandex. Schedules, which always contain the most current information about flights. Based on this information, we supplement the ticket with data from other services: weather, exchange rates, links to the airport and electronic check-in.
And what about privacy?
Habr's audience like no other knows that in every mail every letter is parsed by dozens of different scripts. Spam defense is so arranged - its job is to automatically analyze the letters and make decisions about whether or not the message is moved to spam.
The same is with Tomita. We have provided several levels of protection so you can be calm: the text is analyzed only by the machine - without any human intervention. Only statistical information about the request is saved in the system logs: the runtime, the type and number of facts found, as well as the number of fields that could be determined. The text of the letter itself is transmitted to extract the facts in an impersonal form - without technical headings, without specifying the sender and recipient.
In the initial training of the system and the preparation of grammars, human participation is indispensable - this is a painstaking process in which linguists are engaged. For him, we use texts from open sources, for example, comments on LiveJournal or social networks. If there are not enough examples, we ask our employees to send examples of suitable letters for training and writing grammars. So we did in the case of air tickets. In addition, we have compiled the top 30 air ticket makers and trained Mail to work with them. You can look at how innovations in the Post look like here .
Source: https://habr.com/ru/post/184788/
All Articles