SMS filtering of spam using a naive Bayes classifier (R code)
 Hey. In this post, we will look at a simple spam filtering model using a naive Bayes classifier with blur according to Laplace , write a few lines of code in R , and finally test it on an English-language sms spam database . Generally, on Habré, I found two articles on this topic, but none of them had a vivid example, so that you could download the code and see the result. There was also no mention of blur, which significantly increases the quality of the model, without much effort, unlike, say, a complex text preprocessing. But in general, the next post about naive bayes made me feel that I was writing a training manual for students with R code examples, so I decided to share the info.
Hey. In this post, we will look at a simple spam filtering model using a naive Bayes classifier with blur according to Laplace , write a few lines of code in R , and finally test it on an English-language sms spam database . Generally, on Habré, I found two articles on this topic, but none of them had a vivid example, so that you could download the code and see the result. There was also no mention of blur, which significantly increases the quality of the model, without much effort, unlike, say, a complex text preprocessing. But in general, the next post about naive bayes made me feel that I was writing a training manual for students with R code examples, so I decided to share the info.Naive Bayes Classifier
')
Consider the set of some objects D = {dq, d2, ..., dm} , each of which has a certain set of features from the set of all features F = {f1, f2, ..., fq} , as well as one label from the set of tags C = {c1, c2, ..., cr} . Our task is to calculate the most probable class / label of an incoming object d, based on the set of its attributes Fd = {fd1, fd2, ..., fdn} . In other words, we need to calculate such a value of the random variable C , at which the a posteriori maximum (MAP) is reached.

- 2.1 - in fact, this is our goal
- 2.2 - decomposed by the Bayes theorem
- 2.3 - given that we are looking for an argument that maximizes the likelihood function, and the fact that the denominator does not depend on this argument and is a constant in this case, we can safely delete the value of the total probability P (d)
- 2.4 - since the logarithm monotonously increases for any x> 0 , the maximum of any function f (x) will be identical to the maximum ln (f (x)) ; this is necessary so that in the future, during programming, not to operate with numbers close to zero
The model of the naive Bayes classifier makes two assumptions, from which it is so naive:
- the order of the signs of the object does not matter;
- probabilities of attributes are independent of each other for a given class:
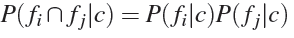 .
.
Given the above assumptions, we continue to derive formulas.

- 2.6-2.7 - this is just a consequence of the application of assumptions.
- 2.8 - here, just, the remarkable logarithm property is used, which allows us to avoid loss of accuracy when operating with very small values
We can depict a graphical model of a naive Bayes classifier as follows:

Spam classifier
Now, from the more general classification task, we dive into the specific task of classifying spam. So, the coupon D consists of SMS messages. Each message is marked with a label from the set C = {ham, spam} . In order to formulate the concept of signs, we will use the model of representation bag of words , we illustrate this with an example. Suppose we have only two ham sms messages in the database
hi how are youhow old are youThen we can build a table
| Word | Frequency |
|---|---|
| hi | one |
| how | 2 |
| are | 2 |
| you | 2 |
| old | one |
There are only 8 words in the body of non-spam messages, then after rationing we get the a posteriori probability of the word using maximum likelihood estimation . For example, the probability of the word "how", provided that the message is not spam, will be:
P (fi = "how" | C = ham) = 2/8 = 1/4
Or we can write this method in general:
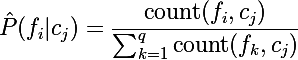 where q is the total number of unique words in the dictionary.
where q is the total number of unique words in the dictionary.Laplace Blur
At this point, it's time to pay attention to the following problem. Recall our base of two ham messages, and, let's say, a message came to us for classification: " hi bro ", and, let's say, the a priori probability of non-spam P (ham) = 1/2 . Calculate the probabilities of words:
- P ("hi" | ham) = 1/8
- P ("bro" | ham) = 0/8 = 0
Recall formula 2.8 and calculate the expression under argmax with c = ham :
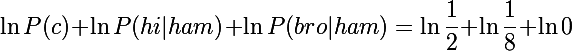
Obviously, we get either an error or a negative infinity, because the logarithm at zero does not exist. If we did not use logarithmization, then we would simply get 0, i.e. the probability of this message would be zero, which in principle gives us great benefit.
This can be avoided by Laplace blur or k-additive smoothing - this method allows you to blur when calculating the probabilities of categorical data. In our case, it will look like this:
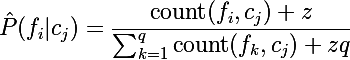 , where z> = 0 is the blur coefficient, and q is the number of values that a random variable can take, in our case it is the number of words in the class; and q is the total number of words that were used in teaching the model.
, where z> = 0 is the blur coefficient, and q is the number of values that a random variable can take, in our case it is the number of words in the class; and q is the total number of words that were used in teaching the model.For example, when reading ham and spam messages, we found 10 unique words, then P ("hi" | ham) = (1 + 1) / (8 + 1 * 10) = 2/18 = 1/9 with a blur factor z = 1. And the zero probability ceases to be such: P ("bro" | ham) = (0 + 1) / (8 + 1 * 10) = 1/18 .
From the Bayesian point of view, this method corresponds to the mathematical expectation of the a posteriori distribution, using the Dirichlet distribution parameterized by the parameter z as the prior distribution.
Experiment and code
I use a database downloaded from the University of Campinas website, which contains 4827 normal SMS messages (ham) and 747 spam messages.
I did not do any serious preprocessing of the text, such as stemming , only a few simple operations:
- reduced the text to lower case letters
- removed all punctuation marks
- all numeric sequences replaced by one
Pretreatment code
PreprocessSentence <- function(s) { # Cut and make some preprocessing with input sentence words <- strsplit(gsub(pattern="[[:digit:]]+", replacement="1", x=tolower(s)), '[[:punct:][:blank:]]+') return(words) } LoadData <- function(fileName = "./Data/Spam/SMSSpamCollection") { # Read data from text file and makes simple preprocessing: # to lower case -> replace all digit strings with 1 -> split with punctuation and blank characters con <- file(fileName,"rt") lines <- readLines(con) close(con) df <- data.frame(lab = rep(NA, length(lines)), data = rep(NA, length(lines))) for(i in 1:length(lines)) { tmp <- unlist(strsplit(lines[i], '\t', fixed = T)) df$lab[i] <- tmp[1] df$data[i] <- PreprocessSentence(tmp[2]) } return(df) } The following function creates a partition of an array of data in appropriate proportions, thereby generating indices of the training, validation, and test data sets:
Separation date set
CreateDataSet <- function(dataSet, proportions = c(0.6, 0.2, 0.2)) { # Creates a list with indices of train, validation and test sets proportions <- proportions/sum(proportions) hamIdx <- which(df$lab == "ham") nham <- length(hamIdx) spamIdx <- which(df$lab == "spam") nspam <- length(spamIdx) hamTrainIdx <- sample(hamIdx, floor(proportions[1]*nham)) hamIdx <- setdiff(hamIdx, hamTrainIdx) spamTrainIdx <- sample(spamIdx, floor(proportions[1]*nspam)) spamIdx <- setdiff(spamIdx, spamTrainIdx) hamValidationIdx <- sample(hamIdx, floor(proportions[2]*nham)) hamIdx <- setdiff(hamIdx, hamValidationIdx) spamValidationIdx <- sample(spamIdx, floor(proportions[2]*nspam)) spamIdx <- setdiff(spamIdx, spamValidationIdx) ds <- list( train = sample(union(hamTrainIdx, spamTrainIdx)), validation = sample(union(hamValidationIdx, spamValidationIdx)), test = sample(union(hamIdx, spamIdx)) ) return(ds) } Then a model is created based on the input data array:
Creating a model
CreateModel <- function(data, laplaceFactor = 0) { # creates naive bayes spam classifier based on data m <- list(laplaceFactor = laplaceFactor) m[["total"]] <- length(data$lab) m[["ham"]] <- list() m[["spam"]] <- list() m[["hamLabelCount"]] <- sum(data$lab == "ham") m[["spamLabelCount"]] <- sum(data$lab == "spam") m[["hamWordCount"]] <- 0 m[["spamWordCount"]] <- 0 uniqueWordSet <- c() for(i in 1:length(data$lab)) { sentence <- unlist(data$data[i]) uniqueWordSet <- union(uniqueWordSet, sentence) for(j in 1:length(sentence)) { if(data$lab[i] == "ham") { if(is.null(m$ham[[sentence[j]]])) { m$ham[[sentence[j]]] <- 1 } else { m$ham[[sentence[j]]] <- m$ham[[sentence[j]]] + 1 } m[["hamWordCount"]] <- m[["hamWordCount"]] + 1 } else if(data$lab[i] == "spam") { if(is.null(m$spam[[sentence[j]]])) { m$spam[[sentence[j]]] <- 1 } else { m$spam[[sentence[j]]] <- m$spam[[sentence[j]]] + 1 } m[["spamWordCount"]] <- m[["spamWordCount"]] + 1 } } } m[["uniqueWordCount"]] <- length(uniqueWordSet) return(m) } The last function for the model classifies the incoming message using the trained model:
Message classification
ClassifySentense <- function(s, model, preprocess = T) { # calculate class of the input sentence based on the model GetCount <- function(w, ls) { if(is.null(ls[[w]])) { return(0) } return(ls[[w]]) } words <- unlist(s) if(preprocess) { words <- unlist(PreprocessSentence(s)) } ham <- log(model$hamLabelCount/(model$hamLabelCount + model$spamLabelCount)) spam <- log(model$spamLabelCount/(model$hamLabelCount + model$spamLabelCount)) for(i in 1:length(words)) { ham <- ham + log((GetCount(words[i], model$ham) + model$laplaceFactor) /(model$hamWordCount + model$laplaceFactor*model$uniqueWordCount)) spam <- spam + log((GetCount(words[i], model$spam) + model$laplaceFactor) /(model$spamWordCount + model$laplaceFactor*model$uniqueWordCount)) } if(ham >= spam) { return("ham") } return("spam") } To test the model on the set, use the following function:
Model testing
TestModel <- function(data, model) { # calculate percentage of errors errors <- 0 for(i in 1:length(data$lab)) { predictedLabel <- ClassifySentense(data$data[i], model, preprocess = F) if(predictedLabel != data$lab[i]) { errors <- errors + 1 } } return(errors/length(data$lab)) } To find the optimal blur ratio, cross-qualification on the corresponding set is used:
Cross-qualification model
CrossValidation <- function(trainData, validationData, laplaceFactorValues, showLog = F) { cvErrors <- rep(NA, length(laplaceFactorValues)) for(i in 1:length(laplaceFactorValues)) { model <- CreateModel(trainData, laplaceFactorValues[i]) cvErrors[i] <- TestModel(validationData, model) if(showLog) { print(paste(laplaceFactorValues[i], ": error is ", cvErrors[i], sep="")) } } return(cvErrors) } The following code reads the data, creates models for the blur parameter values from 0 to 10, selects the best result, tests the model on the previously unused test set, and then builds a graph of the error change on the cross-validation set from the blur parameter and the final error level on the test set:
rm(list = ls()) source("./Spam/spam.R") set.seed(14880) fileName <- "./Data/Spam/SMSSpamCollection" df <- LoadData() ds <- CreateDataSet(df, proportions = c(0.7, 0.2, 0.1)) laplaceFactorValues <- 1:10 cvErrors <- CrossValidation(df[ds$train, ], df[ds$validation, ], 0:10, showLog = T) bestLaplaceFactor <- laplaceFactorValues[which(cvErrors == min(cvErrors))] model <- CreateModel(data=df[ds$train, ], laplaceFactor=bestLaplaceFactor) testResult <- TestModel(df[ds$test, ], model) plot(cvErrors, type="l", col="blue", xlab="Laplace Factor", ylab="Error Value", ylim=c(0, max(cvErrors))) title("Cross validation and test error value") abline(h=testResult, col="red") legend(bestLaplaceFactor, max(cvErrors), c("cross validation values", "test value level"), cex=0.8, col=c("blue", "red"), lty=1) 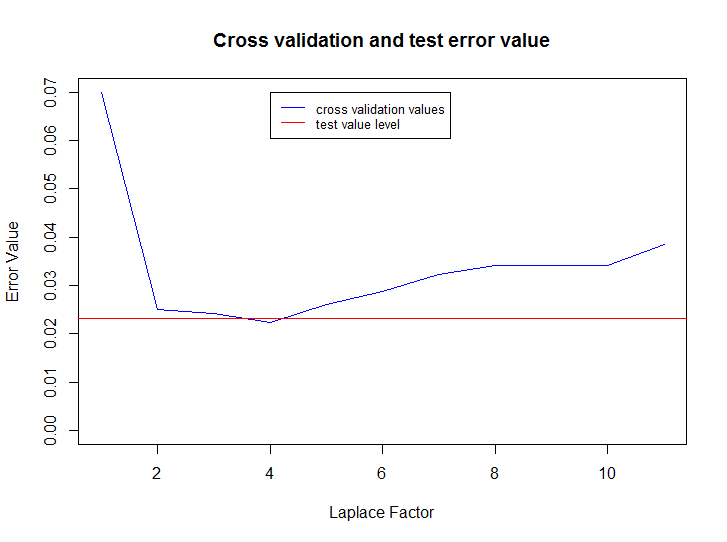
All code can be downloaded from github .
Conclusion
As you can see, this method is very effective even with simple preprocessing, the error rate on the test set (the ratio of incorrectly classified messages to the total number of messages) is only 2.32% . Where can you use this method? For example, there are a lot of comments on your site, you have recently entered a rating of comments from 1 to 5, and you have only a small part of it with the rating placed by people; then you can automatically arrange more or less relevant ratings for the remaining comments.
Source: https://habr.com/ru/post/184574/
All Articles