Implementing a useful thread-based log
There are a lot of enthusiastic people among programmers. Show a sincere interest in your work, read special books and forums even in your free time in this environment, if not the rule, then definitely and not the exception. Then why as a result of so many poor-quality software? How is it that a student, with burning eyes, arguing about the shortcomings of whole programming languages and knowing at least a dozen design patterns, suddenly takes an active part in creating a poor-quality system? Not at the beginning of his career, but year after year.
Yes, you can refer to a large number of low-skilled staff, whose salary depends on the number of written lines of code or on the ability to look at the monitor for a long time without blinking. But such employees exist in almost all industries. Builders have lower qualifications than architects, but this does not prevent buildings, for the most part, from being suitable for high-grade use without additional patches.
In my opinion, there are two main reasons. From the first, nothing can be done. This time, or, as they say more often, constant changes. When developing a software product, even if it meets all customer requirements, further improvements will be required, often unexpected for the contractor. They are almost inevitable and do not always fit into the system architecture. Over time, the software complex becomes unusable. But time destroyed things and bigger - nothing to be surprised about.
')
The second reason is much more prosaic. Inattention to trivia. Especially at the beginning of the project. And the younger the team, the more catastrophic the effect. Of course, it is much more interesting to discuss the prospects for using multimethods [1] than to ensure that operators are separated by spaces. Yes, and to the final functionality of these little things are not particularly relevant. Isn't it better to first concentrate on top-priority requirements, because the project time and budget are limited ...
It turns out that as if not better. It is like a house without a foundation. The customer asked for spacious rooms, an elevator, a bathroom on each floor - he may not know about the foundation. But a quality foundation that can withstand the entire structure is necessary. And first of all the performers should take care of it - from architect to builder.
In order not to be further unfounded, I will give an example of a shadow, but fundamental and often necessary subsystem. This is journaling. Many systems include the ability to display diagnostic messages. However, it is usually not the main functionality, and therefore does not receive proper attention.
At the same time, a well-designed logging subsystem helps to avoid a number of annoying errors from the very beginning of the project, significantly reducing the period between the moment the defect is introduced and its detection. After all, each mistake missed at the beginning of the work at the time of the project is turned into a huge snowball, which tries to bury the system and all its creators.
To begin with, I will formulate how I see the module of diagnostic messages output that is not deprived of attention.
Full interface. The logging module should represent a complete set of operations from the very beginning of development. The interface may not be fully implemented, but it must be. So it is very convenient to be able to share diagnostic messages according to the degree of criticality (error, warning, information). You can not do one kind of message first, and then introduce a division - part of the system will already be developed with this generalized conclusion, even if you force people to dig up everything done, the developers are unlikely to do this work as correctly as they would have done right away.
Often a week later you look at your code as someone else’s. It is clear that after several months a number of implementation nuances (in particular, what is a critical problem, and what is just an insignificant emergency situation) will be lost forever.
Cross platform The logging subsystem must initially support all the platforms used. This is especially important when there is no opportunity to fully and constantly test the application on all operating systems. What worked perfectly on iOS may behave strangely on an Android device and vice versa. Of course, the message output system does not replace automatic tests. But they are quite complex, implementation and support requires considerable labor costs and, morally or not, they are often forgotten about tests. Therefore, I believe that it is better to start with a fully functioning minimum than to do nothing, dreaming about the ideal. Although in any case, ideally, there should be tests and a convenient logging subsystem.
Outputting messages to the IDE console. Please note that the list of basic requirements does not include “Displaying messages to the permanent storage (file or database)”. Although usually this is just what many expect from the log. There is a need in the log file when at least a working system is given to testing for future users or a special department. But at the initial stages it is much more useful to inform programmers about problems, than testers.
Because the user interface can be very late for functionality - all this time, developers will “stew in their own juice.” There is a big difference, you saw the problem a few seconds or weeks after you created it.
Convenience and ease of use. Programmer being lazy. Suppose you need to report a problem: an image with a size of 100 by 120 is received, while the current settings of the application set a limit for the minimum size of 128 by 128. If the ability to output only a simple line is implemented, the developer will need to produce an adequate output
Even if the language provides means of outputting to a formatted string (for example, sprintf [2] and stringstream [3]), you will need to create various intermediate variables, waste time, blur the main logic ... In general, you shouldn't be surprised if the result is that something like “invalid image size”. The meaning of the word "unacceptable", so understandable now, in a couple of weeks will be lost almost completely. As a result, the designer, instead of correcting the problem picture, will have to contact the programmer for clarification.
Therefore, the logging subsystem should provide a means of conveniently formatting the output strings without forcing the developer to manually lead to string at least basic types. Here in C ++ two directions are possible.
The first is a legacy from C. Formatting a string by a pattern. Those. The logging function should have an interface and functionality similar to sprintf. This is a matter of taste, for me personally this option is deeply unsympathetic. First of all, it pushes away the need to work with a variable number of different types of function parameters. Those. the ability to verify the input data is almost none. In addition, although simplified, the need for manual type casting is present. For example, you need to remember that to output an unsigned number you should use the% u formatting code instead of% i - you don’t want to remember this at all when your head is busy solving another task. Plus, problems that are elusive at the compilation stage are possible, when the number (order, type) of formatting codes and the parameters actually passed do not match.
The second option is output streams. It is devoid of all the shortcomings of the previous solution: there is no dependency on the parameters, if an object is transferred that does not support the output operator - there will be a compilation error, not all sorts of surprises, there is no need to manually allocate buffers, cast types, etc. And the main thing is that the output of a message string with the inclusion of variables of different types can actually be written in one line. Yes, and with the implementation of special difficulties is not expected - the standard library already contains a stream of stringstream [3], which suggests the presence of ready-made stream output algorithms in the string.
Means of attracting the attention of the developer. The programmer is busy. He may not notice the error even in the IDE output console. The problem can easily get lost among the clouds of informational messages. Therefore, first of all, the log must support setting the output level. For example, “display only errors and warnings”. This is necessary, but it is not enough - the setting is required from time to time. And the programmer is busy.
Here comes the special macro assert [4]. It allows you to interrupt the execution of the program at the problem site. The result is different - Visual Studio gives you the opportunity to continue running after the window is displayed and the sound is frightening, XCode does not sound scary, but does not allow it to continue. In general, attention is guaranteed. At the same time, the diagnostic message itself will appear at the time of the interruption at the end of the IDE output console, often completely eliminating the need to look at the call stack in search of the reason for the shutdown.
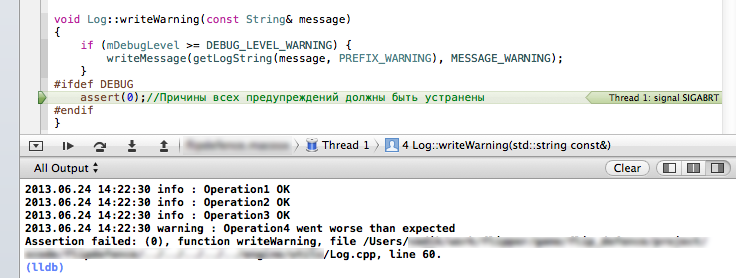
Figure 1. Program interruption on warning
At the end of the article I will give an example of implementation. Just to show that it does not require much effort, and the effect is difficult to overestimate — as a result, a subsystem will be obtained that not only encourages the developer to create detailed problem reports, but also significantly reduces the time interval between the problem and its detection.
First, consider the basic interface of the logging class.
First of all, we enter four levels of log details (in the order of declaration):
Accordingly, we add three more identifiers of permissible types of messages: informational message, warning and error.
The following method is for creating an instance of a class. Direct creation is prohibited by placing the constructor in a protected area.
The last available public method is designed to set the log level. Everything else is closing. This is a preliminary log interface - in the following we will show how to actually display messages.
The protected area is opened by the promised closed constructor.
The only pure virtual method is for platform-specific output of the IDE console.
The following three methods will serve to directly output each type of alert. So that the programmer does not accidentally use them, they are hidden in a private area of the class.
Output method to file. Here its implementation will not be given, since it has no direct relation to the topic of the article.
Well, you will need a service function to generate a debug message. Usually a timestamp and a sign of the level of importance of the line are added to each message.
From the data of the class we need to store the level of log detail and its instance.
Consider the implementation of some methods
The message output functions are of the same type, so we limit ourselves to considering the source code of the error message as the most complete.
So, first of all, it is checked that the level of detail permits error output, then the service method writeMessage is called, to which the message and the type of the message are transmitted. As a result, something like this will be displayed.
error: [message]
To attract the attention of the developer, even if the error output is disabled, the assert macro is called. In addition, at the end of the subroutine, the application terminates. Such a solution can hardly be called universal, but in our application, an error indicates a problem that is incompatible with further work.
The output of the warning is implemented in the same way, only without abnormal termination of the application. The informational message method also does not contain the assert interrupt.
In turn, writeMessage looks like this.
Its role is to remove line-breaks from the message so that each message of the log is guaranteed to be single-line, to call the write method to the file and, if the debug mode is on, output to the IDE console.
Debug mode is defined by the _DEBUG macro, which is usually automatically defined in Visual Studio. In other development environments, you will most likely need to add it manually. In any case, it does not cause much difficulty.
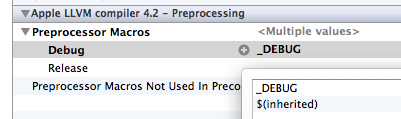
Figure 2. Macro debug definition for Xcode
Further, for each platform, you need to define your own log class, inherited from the base class with overriding the writeIDEDebugString method. I will give examples of its implementation for some platforms.
void Log_Android :: writeIDEDebugString (const String & message, MessageType type)
As you can see, in the case of Android, we get additional visibility: it is possible to display messages in different colors. The problem, displayed in red, has little chance of escaping attention, even without assert.
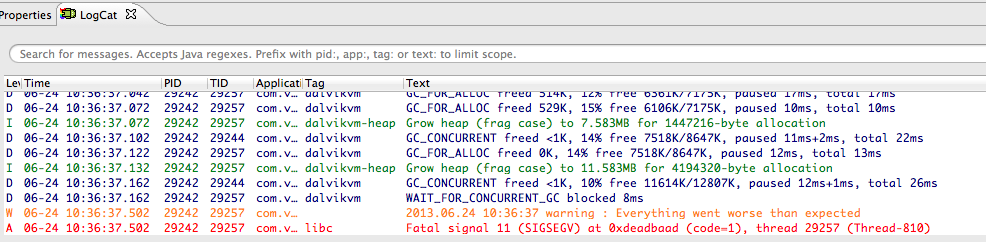
Figure 3. Color highlighting messages depending on the type in Eclipse
With a direct conclusion figured out, the question remains, how to properly pack it into streams. After all, we have closed all methods of withdrawal.
To begin, we define the desired record. C ++ streams can receive output parameters in the same way that they are passed data. For example, the message will be displayed in capital letters.
Here, of course, as anyone, but personally I could not accept the mixing of the output information and output parameters. Therefore, in the example the output will be implemented as follows.
Those. The message type information will be contained in the stream object itself. Of course, the standard parameters of streams like std :: uppercase can still be used. All thread functionality is inherited from the standard library classes.
For each type of flow will be its object, so the constructors take the parameter MessageType. We inherit the output class itself from std :: ostream [5], the nested class StringBuffer, which in turn inherits from std :: stringbuf [6], will be responsible for forming the string. Each time a user reports the completion of a message, the sync method will be automatically called, in which we will execute an immediate output. You can report the completion of the output in standard ways for buffered threads: by calling the flush method
or simply adding std :: endl to the stream
You also need to associate the output stream with a string buffer. This is done in the constructor.
Accordingly, when destroying, the buffer must be independently destroyed.
In the constructor of the buffer, it is enough to remember the type of the displayed message.
When destroying, just in case, we call its synchronization - this will prevent the message from “disappearing” if the programmer forgets to call flush or endl.
In order for the stream to have access to the main interface of the Log class that is closed to the outside world, we will put it inside
message warning and error are stream instances for each type of message. The message type is passed to them in the constructor.
And finally, consider the implementation of the synchronization function of the string buffer of the stream.
As a nested class Log :: Streamer :: Buffer has access to the private area of the Log . Only the str () function needs clarification. This is a rather strange method of class std :: stringbuf, which simultaneously allows you to get and set the value of the buffer. In both of its incarnations, it is used - first, using this function, we get a string from the buffer, and then clear the buffer with a call to str ("") .
Everything, now the Streamer class becomes the “official” Log interface. To display the composite message “i (6) should be in range [1..5]”, it is enough for a programmer to write
It's almost as easy as getting a much more vague "wrong i"
Thus, an example was given of a fairly simple event logging class, which can be easily implemented at the very beginning of even the shortest deadline (when there is no time to either write tests, or persuade programmers, or effectively control them, or breathe, or sleep) of the project, significantly improving its quality.
[1] en.wikipedia.org/wiki/Multiple_dispatch
[2] www.cplusplus.com/reference/cstdio/sprintf
[3] www.cplusplus.com/reference/sstream/stringstream
[4] www.cplusplus.com/reference/cassert/assert
[5] www.cplusplus.com/reference/ostream/ostream
[6] www.cplusplus.com/reference/sstream/stringbuf
Yes, you can refer to a large number of low-skilled staff, whose salary depends on the number of written lines of code or on the ability to look at the monitor for a long time without blinking. But such employees exist in almost all industries. Builders have lower qualifications than architects, but this does not prevent buildings, for the most part, from being suitable for high-grade use without additional patches.
In my opinion, there are two main reasons. From the first, nothing can be done. This time, or, as they say more often, constant changes. When developing a software product, even if it meets all customer requirements, further improvements will be required, often unexpected for the contractor. They are almost inevitable and do not always fit into the system architecture. Over time, the software complex becomes unusable. But time destroyed things and bigger - nothing to be surprised about.
')
The second reason is much more prosaic. Inattention to trivia. Especially at the beginning of the project. And the younger the team, the more catastrophic the effect. Of course, it is much more interesting to discuss the prospects for using multimethods [1] than to ensure that operators are separated by spaces. Yes, and to the final functionality of these little things are not particularly relevant. Isn't it better to first concentrate on top-priority requirements, because the project time and budget are limited ...
It turns out that as if not better. It is like a house without a foundation. The customer asked for spacious rooms, an elevator, a bathroom on each floor - he may not know about the foundation. But a quality foundation that can withstand the entire structure is necessary. And first of all the performers should take care of it - from architect to builder.
In order not to be further unfounded, I will give an example of a shadow, but fundamental and often necessary subsystem. This is journaling. Many systems include the ability to display diagnostic messages. However, it is usually not the main functionality, and therefore does not receive proper attention.
At the same time, a well-designed logging subsystem helps to avoid a number of annoying errors from the very beginning of the project, significantly reducing the period between the moment the defect is introduced and its detection. After all, each mistake missed at the beginning of the work at the time of the project is turned into a huge snowball, which tries to bury the system and all its creators.
To begin with, I will formulate how I see the module of diagnostic messages output that is not deprived of attention.
- Full interface
- Cross platform
- Outputting messages to the IDE console
- Convenience and ease of use
- Means of attracting the attention of the developer
Full interface. The logging module should represent a complete set of operations from the very beginning of development. The interface may not be fully implemented, but it must be. So it is very convenient to be able to share diagnostic messages according to the degree of criticality (error, warning, information). You can not do one kind of message first, and then introduce a division - part of the system will already be developed with this generalized conclusion, even if you force people to dig up everything done, the developers are unlikely to do this work as correctly as they would have done right away.
Often a week later you look at your code as someone else’s. It is clear that after several months a number of implementation nuances (in particular, what is a critical problem, and what is just an insignificant emergency situation) will be lost forever.
Cross platform The logging subsystem must initially support all the platforms used. This is especially important when there is no opportunity to fully and constantly test the application on all operating systems. What worked perfectly on iOS may behave strangely on an Android device and vice versa. Of course, the message output system does not replace automatic tests. But they are quite complex, implementation and support requires considerable labor costs and, morally or not, they are often forgotten about tests. Therefore, I believe that it is better to start with a fully functioning minimum than to do nothing, dreaming about the ideal. Although in any case, ideally, there should be tests and a convenient logging subsystem.
Outputting messages to the IDE console. Please note that the list of basic requirements does not include “Displaying messages to the permanent storage (file or database)”. Although usually this is just what many expect from the log. There is a need in the log file when at least a working system is given to testing for future users or a special department. But at the initial stages it is much more useful to inform programmers about problems, than testers.
Because the user interface can be very late for functionality - all this time, developers will “stew in their own juice.” There is a big difference, you saw the problem a few seconds or weeks after you created it.
Convenience and ease of use. Programmer being lazy. Suppose you need to report a problem: an image with a size of 100 by 120 is received, while the current settings of the application set a limit for the minimum size of 128 by 128. If the ability to output only a simple line is implemented, the developer will need to produce an adequate output
- Cast four numbers to string type
- From the received parts to make a line
- Pass string to log
Even if the language provides means of outputting to a formatted string (for example, sprintf [2] and stringstream [3]), you will need to create various intermediate variables, waste time, blur the main logic ... In general, you shouldn't be surprised if the result is that something like “invalid image size”. The meaning of the word "unacceptable", so understandable now, in a couple of weeks will be lost almost completely. As a result, the designer, instead of correcting the problem picture, will have to contact the programmer for clarification.
Therefore, the logging subsystem should provide a means of conveniently formatting the output strings without forcing the developer to manually lead to string at least basic types. Here in C ++ two directions are possible.
The first is a legacy from C. Formatting a string by a pattern. Those. The logging function should have an interface and functionality similar to sprintf. This is a matter of taste, for me personally this option is deeply unsympathetic. First of all, it pushes away the need to work with a variable number of different types of function parameters. Those. the ability to verify the input data is almost none. In addition, although simplified, the need for manual type casting is present. For example, you need to remember that to output an unsigned number you should use the% u formatting code instead of% i - you don’t want to remember this at all when your head is busy solving another task. Plus, problems that are elusive at the compilation stage are possible, when the number (order, type) of formatting codes and the parameters actually passed do not match.
The second option is output streams. It is devoid of all the shortcomings of the previous solution: there is no dependency on the parameters, if an object is transferred that does not support the output operator - there will be a compilation error, not all sorts of surprises, there is no need to manually allocate buffers, cast types, etc. And the main thing is that the output of a message string with the inclusion of variables of different types can actually be written in one line. Yes, and with the implementation of special difficulties is not expected - the standard library already contains a stream of stringstream [3], which suggests the presence of ready-made stream output algorithms in the string.
Means of attracting the attention of the developer. The programmer is busy. He may not notice the error even in the IDE output console. The problem can easily get lost among the clouds of informational messages. Therefore, first of all, the log must support setting the output level. For example, “display only errors and warnings”. This is necessary, but it is not enough - the setting is required from time to time. And the programmer is busy.
Here comes the special macro assert [4]. It allows you to interrupt the execution of the program at the problem site. The result is different - Visual Studio gives you the opportunity to continue running after the window is displayed and the sound is frightening, XCode does not sound scary, but does not allow it to continue. In general, attention is guaranteed. At the same time, the diagnostic message itself will appear at the time of the interruption at the end of the IDE output console, often completely eliminating the need to look at the call stack in search of the reason for the shutdown.
Figure 1. Program interruption on warning
At the end of the article I will give an example of implementation. Just to show that it does not require much effort, and the effect is difficult to overestimate — as a result, a subsystem will be obtained that not only encourages the developer to create detailed problem reports, but also significantly reduces the time interval between the problem and its detection.
First, consider the basic interface of the logging class.
class Log { public: First of all, we enter four levels of log details (in the order of declaration):
- Complete log off
- Only error output
- Display warnings and errors
- Display all kinds of messages
enum DebugLevel { DEBUG_LEVEL_DISABLED = 0, DEBUG_LEVEL_ERROR = 1, DEBUG_LEVEL_WARNING = 2, DEBUG_LEVEL_MESSAGE = 3, }; Accordingly, we add three more identifiers of permissible types of messages: informational message, warning and error.
enum MessageType { MESSAGE_INFO, MESSAGE_WARNING, MESSAGE_ERROR, }; The following method is for creating an instance of a class. Direct creation is prohibited by placing the constructor in a protected area.
static void createInstance(); The last available public method is designed to set the log level. Everything else is closing. This is a preliminary log interface - in the following we will show how to actually display messages.
void setDebugLevel(DebugLevel level); protected: The protected area is opened by the promised closed constructor.
Log(); The only pure virtual method is for platform-specific output of the IDE console.
virtual void writeIDEDebugString(const std::string& message, MessageType type) = 0; private: The following three methods will serve to directly output each type of alert. So that the programmer does not accidentally use them, they are hidden in a private area of the class.
void writeMessage(const std::string& message); void writeWarning(const std::string& message); void writeError(const std::string& message); Output method to file. Here its implementation will not be given, since it has no direct relation to the topic of the article.
void appendToFile(const std::string& message); Well, you will need a service function to generate a debug message. Usually a timestamp and a sign of the level of importance of the line are added to each message.
void writeMessage(const std::string& message, MessageType type); From the data of the class we need to store the level of log detail and its instance.
DebugLevel mDebugLevel; static Log* sInstance; }; Consider the implementation of some methods
The message output functions are of the same type, so we limit ourselves to considering the source code of the error message as the most complete.
void Log::writeError(const std::string& message) { if (mDebugLevel >= DEBUG_LEVEL_ERROR) { writeMessage(getLogString(message, "error"), MESSAGE_ERROR); } #ifdef _DEBUG assert(0); #endif exit(EXIT_FAILURE); } So, first of all, it is checked that the level of detail permits error output, then the service method writeMessage is called, to which the message and the type of the message are transmitted. As a result, something like this will be displayed.
error: [message]
To attract the attention of the developer, even if the error output is disabled, the assert macro is called. In addition, at the end of the subroutine, the application terminates. Such a solution can hardly be called universal, but in our application, an error indicates a problem that is incompatible with further work.
The output of the warning is implemented in the same way, only without abnormal termination of the application. The informational message method also does not contain the assert interrupt.
In turn, writeMessage looks like this.
void Log::writeMessage(const std::string& message, MessageType type) { std::string text(message); std::replace(text.begin(), text.end(), '\n', ' '); appendToFile(text); #ifdef _DEBUG writeIDEDebugString(text, type); #endif } Its role is to remove line-breaks from the message so that each message of the log is guaranteed to be single-line, to call the write method to the file and, if the debug mode is on, output to the IDE console.
Debug mode is defined by the _DEBUG macro, which is usually automatically defined in Visual Studio. In other development environments, you will most likely need to add it manually. In any case, it does not cause much difficulty.
Figure 2. Macro debug definition for Xcode
Further, for each platform, you need to define your own log class, inherited from the base class with overriding the writeIDEDebugString method. I will give examples of its implementation for some platforms.
Windows (Visual Studio)
void Log_Windows::writeIDEDebugString(const std::string& message, MessageType type) { OutputDebugStringA(message.c_str()); OutputDebugStringA("\n"); } Android (Eclipse)
void Log_Android :: writeIDEDebugString (const String & message, MessageType type)
{ switch(type){ case MESSAGE_INFO: __android_log_print(ANDROID_LOG_INFO, "", message.c_str()); break; case MESSAGE_WARNING: __android_log_print(ANDROID_LOG_WARN, "", message.c_str()); break; case MESSAGE_ERROR: __android_log_print(ANDROID_LOG_ERROR, "", message.c_str()); break; } } As you can see, in the case of Android, we get additional visibility: it is possible to display messages in different colors. The problem, displayed in red, has little chance of escaping attention, even without assert.
Figure 3. Color highlighting messages depending on the type in Eclipse
MacOS and iOS (Xcode)
void Log_Mac::writeIDEDebugString(const std::string& message, MessageType type) { NSLog(@"%s", message.c_str()); } With a direct conclusion figured out, the question remains, how to properly pack it into streams. After all, we have closed all methods of withdrawal.
To begin, we define the desired record. C ++ streams can receive output parameters in the same way that they are passed data. For example, the message will be displayed in capital letters.
std::cout << std::uppercase << "test" << '\n'; Here, of course, as anyone, but personally I could not accept the mixing of the output information and output parameters. Therefore, in the example the output will be implemented as follows.
Log::error<<"text"<<std::endl; Log::warning<<"text"<<std::endl; Log::message<<"text"<<std::endl; Those. The message type information will be contained in the stream object itself. Of course, the standard parameters of streams like std :: uppercase can still be used. All thread functionality is inherited from the standard library classes.
class Streamer : public std::ostream { public: Streamer(MessageType messageType); ~Streamer(); private: class StringBuffer : public std::stringbuf { public: Buffer(MessageType messageType); ~Buffer(); virtual int sync(); private: MessageType mMessageType; }; }; For each type of flow will be its object, so the constructors take the parameter MessageType. We inherit the output class itself from std :: ostream [5], the nested class StringBuffer, which in turn inherits from std :: stringbuf [6], will be responsible for forming the string. Each time a user reports the completion of a message, the sync method will be automatically called, in which we will execute an immediate output. You can report the completion of the output in standard ways for buffered threads: by calling the flush method
Log::message<<"text"; Log::message.flush(); or simply adding std :: endl to the stream
Log::message<<"text"<<std::endl; You also need to associate the output stream with a string buffer. This is done in the constructor.
Log::Streamer::Streamer(Log::MessageType messageType) : std::ostream(new StringBuffer(messageType)) { } Accordingly, when destroying, the buffer must be independently destroyed.
Log::Streamer::~Streamer() { delete rdbuf(); } In the constructor of the buffer, it is enough to remember the type of the displayed message.
Log::Streamer::StringBuffer:: StringBuffer(Log::MessageType messageType) : mMessageType(messageType) { } When destroying, just in case, we call its synchronization - this will prevent the message from “disappearing” if the programmer forgets to call flush or endl.
Log::Streamer::Buffer::~Buffer() { pubsync(); } In order for the stream to have access to the main interface of the Log class that is closed to the outside world, we will put it inside
class Log { public: ... class Streamer : public std::ostream { ... }; static Streamer message; static Streamer warning; static Streamer error; ... message warning and error are stream instances for each type of message. The message type is passed to them in the constructor.
Log::Streamer Log::message(Log::MESSAGE_INFO); Log::Streamer Log::warning(Log::MESSAGE_WARNING); Log::Streamer Log::error(Log::MESSAGE_ERROR); And finally, consider the implementation of the synchronization function of the string buffer of the stream.
int Log::Streamer::StringBuffer::sync() { if (Log::sInstance == NULL) { return 0; } std::string text(str()); if (text.empty()) { return 0; } str(""); switch (mMessageType) { case MESSAGE_INFO: Log::sInstance->writeMessage(text); break; case MESSAGE_WARNING: Log::sInstance->writeWarning(text); break; case MESSAGE_ERROR: Log::sInstance->writeError(text); break; } return 0; } As a nested class Log :: Streamer :: Buffer has access to the private area of the Log . Only the str () function needs clarification. This is a rather strange method of class std :: stringbuf, which simultaneously allows you to get and set the value of the buffer. In both of its incarnations, it is used - first, using this function, we get a string from the buffer, and then clear the buffer with a call to str ("") .
Everything, now the Streamer class becomes the “official” Log interface. To display the composite message “i (6) should be in range [1..5]”, it is enough for a programmer to write
Log::warning << "i (" << i << ") should be in range [" << I_MIN << ".." << I_MAX << "]" << std::endl; It's almost as easy as getting a much more vague "wrong i"
Thus, an example was given of a fairly simple event logging class, which can be easily implemented at the very beginning of even the shortest deadline (when there is no time to either write tests, or persuade programmers, or effectively control them, or breathe, or sleep) of the project, significantly improving its quality.
[1] en.wikipedia.org/wiki/Multiple_dispatch
[2] www.cplusplus.com/reference/cstdio/sprintf
[3] www.cplusplus.com/reference/sstream/stringstream
[4] www.cplusplus.com/reference/cassert/assert
[5] www.cplusplus.com/reference/ostream/ostream
[6] www.cplusplus.com/reference/sstream/stringbuf
Source: https://habr.com/ru/post/184486/
All Articles