Useful multithreading idioms C ++

Introduction
This article is a continuation of a series of articles: Using the Singleton Pattern [1] , Singleton and Object Lifetime [2] , Dependency Relation and Generating Design Patterns [3] , Implementing Singleton in a Multi-threaded Application [4] . Now I would like to talk about multithreading. This topic is so voluminous and multifaceted that it is not possible to cover it all. Here I will focus on some practical things that will make it possible not to think about multithreading at all, or to think about it in an extremely minimal amount. If to speak more precisely, then think about it only at the design stage, but not implementation. Those. questions about how to make correct constructions without headaches automatically will be considered. This approach, in turn, can significantly reduce the problems caused by race conditions (race condition, see Race condition [5] ) and interlocks (deadlock, see Mutual lock [6] ). This fact in itself is of considerable value. We will also consider an approach that allows you to have access to an object from several threads at the same time without using any locks and atomic operations!Most articles are limited to only a certain set of primitives, which, although it is convenient to use, but do not solve common problems that arise in a multithreaded environment. The following is a list that is commonly used in these types of approaches. At the same time, I will assume that the reader is already familiar with such approaches, so I will not focus on this.
Entities to use:
Description of the mutex interface: |
RAII primitive (exception-safe): |
Class for bullying as a simple example: |
Example 1. Primitive approach: C-style |
Example 2. Advanced approach: RAII-style |
Example 3. Almost ideal: lock encapsulation |
Invariant
We begin the consideration of multithreaded questions, oddly enough, with the verification of the object invariant. However, the developed mechanism for the invariant will be used in the future.')
For those who are not familiar with the concept of "invariant", this paragraph is devoted. The rest can safely skip it and go straight to the implementation. So, in the PLO, we work, oddly enough, with objects. Each object has its own state, which when calling non-constant functions changes it. So, as a rule, for each class there is a certain invariant that must be satisfied with each change of state. For example, if an object is a counter of elements, then it is obvious that for any moment of program execution time the value of this counter should not be negative, i.e. in this case, the invariant is a non-negative counter value. Thus, the preservation of the invariant gives some guarantee that the state of the object is consistent.
Imagine that our class has an
isValid method that returns true if the invariant is saved, and false if the invariant is broken. Consider the following “non-negative” counter: struct Counter { Counter() : count(0) {} bool isValid() const { return count >= 0; } int get() const { return count; } void set(int newCount) { count = newCount; } void inc() { ++ count; } void dec() { -- count; } private: int count; }; Using:
Counter c; c.set(5); assert(c.isValid()); // true c.set(-3); assert(c.isValid()); // false assert Now I want to somehow automate the invariant check, so as not to call the
isValid method after each change of the value. The obvious way to do this is to include this call in the set method. However, in the case of the presence of a large number of non-constant class methods, it is necessary to insert this check inside each such method. And you want to achieve automaticity, to write less, and get more. So let's get started.Here we will use the tools developed in previous cycles of articles: Singleton pattern usage [1] , Singleton and object lifetime [2] , Dependency handling and generating design patterns [3] , Singleton implementation in multi-threaded application [4] . Below is a reference for implementation that will be parted:
An.hpp
#ifndef AN_HPP #define AN_HPP #include <memory> #include <stdexcept> #include <string> // , . [1] #define PROTO_IFACE(D_iface, D_an) \ template<> void anFill<D_iface>(An<D_iface>& D_an) #define DECLARE_IMPL(D_iface) \ PROTO_IFACE(D_iface, a); #define BIND_TO_IMPL(D_iface, D_impl) \ PROTO_IFACE(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF(D_impl) \ BIND_TO_IMPL(D_impl, D_impl) // , DIP - dependency inversion principle template<typename T> struct An { template<typename U> friend struct An; An() {} template<typename U> explicit An(const An<U>& a) : data(a.data) {} template<typename U> explicit An(An<U>&& a) : data(std::move(a.data)) {} T* operator->() { return get0(); } const T* operator->() const { return get0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } private: // // // anFill, // // T T* get0() const { // const_cast<An*>(this)->init(); return data.get(); } std::shared_ptr<T> data; }; // , . [1] // // , // , // . . [3] template<typename T> void anFill(An<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } #endif In order to be able to check consistency, modify access to the object (private method
get0 ) as follows: template<typename T> struct An { // ... T* get0() const { const_cast<An*>(this)->init(); assert(data->isValid()); // assert return data.get(); } // ... }; All is well, check is in progress. But the trouble is: it happens not after a change, but before. Thus, an object can be in a non-consistent state, and only the next call will do its job:
c->set(2); c->set(-2); // assert c->set(1); // , ! It would be desirable, that check happened after change, but not before. For this, we will use a proxy object, in the destructor of which the necessary check will occur:
template<typename T> struct An { // ... struct Access { Access(T& ref_) : ref(ref_) {} ~Access() { assert(ref.isValid()); } T* operator->() { return &ref; } private: T& ref; }; // , ( , .. ): Access operator->() { return *get0(); } // ... }; Using:
An<Counter> c; c->set(2); c->set(-2); // assert c->set(1); What was required.
Smart mutex
We now turn to our multithreaded problems. We write a new implementation of the mutex and call it “smart” by analogy with a smart pointer. The idea of a smart mutext is that it takes on all the “dirty” work on working with an object, and we only have the most delicious part.To make it, we need a “regular” mutex (just as a smart pointer requires a regular pointer):
// noncopyable struct Mutex { // void lock(); void unlock(); private: // ... }; Now we will improve the practices used earlier when checking the invariant. For this, we will use not only the destructor of the proxy class, but also the constructor:
template<typename T> struct AnLock { // ... template<typename U> struct Access { // Access(const An& ref_) : ref(ref_) { ref.mutex->lock(); } // ~Access() { ref.mutex->unlock(); } U* operator->() const { return ref.get0(); } private: const An& ref; }; // Access<T> operator->() { return *this; } Access<const T> operator->() const { return *this; } // template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new Mutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<Mutex> mutex; }; Using:
AnLock<Counter> c; c->set(2); // std::cout << "Extracted value: " << c->get() << std::endl; It should be noted that when using a constant link, changing the value will result in a compilation error (as opposed to directly using
shared_ptr ): const AnLock<Counter>& cc = c; cc->set(3); // Consider what we did. Adding screen output for the
Counter and Mutex class methods, we get the following screen output when the value changes:Mutex :: lock Counter :: set: 2 Mutex :: unlock
Sequence of actions at display:
Mutex :: lock Counter :: get: 2 Extracted value: 2 Mutex :: unlock
The convenience is obvious: instead of explicitly calling a mutex, we simply work with the object as if there is no mutex, and everything that is needed is going on inside.
You can ask: what to do if I need, for example, to call
inc 2 times, and do it atomically? No problems! First we AnLock couple typedef to our AnLock class for convenience: template<typename T> struct AnLock { // ... typedef Access<T> WAccess; // typedef Access<const T> RAccess; // // ... }; And then we use the following construction:
{ AnLock<Counter>::WAccess a = c; a->inc(); a->inc(); } Which, in turn, gives the following conclusion:
Mutex :: lock Counter :: inc: 1 Counter :: inc: 2 Mutex :: unlock
Something like a transaction, is not it?
Smart RW Mutex
So, now we can try to implement a somewhat more complex construction called read-write mutex (see Readers – writer lock [7] ). The essence of use is quite simple: to allow the ability to read object data from multiple threads, while simultaneous reading and writing or writing and writing should be prohibited.Suppose we already have an implementation of
RWMutex with this interface: // noncopyable struct RWMutex { // // void rlock(); void runlock(); // void wlock(); void wunlock(); private: // ... }; It would seem that all that needs to be done is to slightly change the implementation so that our proxy types
RAccess and WAccess use different functions: template<typename T> struct AnRWLock { // ... // struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; // struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; WAccess operator->() { return *this; } RAccess operator->() const { return *this; } // ... // template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; }; Using:
AnRWLock<Counter> c; c->set(2); Result:
RWMutex :: wlock Counter :: set: 2 RWMutex :: wunlock
So far so good! But the following code:
std::cout << "Extracted value: " << c->get() << std::endl; Gives:
RWMutex :: wlock Counter :: get: 2 Extracted value: 2 RWMutex :: wunlock
For some, this will not come as a surprise, and for the rest of it I will explain why it does not work here as expected. After all, we used the constant method, so the idea was to use the constant
operator-> method. However, the compiler does not think so. And this is due to the fact that operations are applied sequentially: first, an operation -> applied -> to a non-constant object, and then the constant method Counter::get is called, but the train has left, because non-constant operator-> has already been called.As a trivial solution, you can offer a variant with type conversion to a constant one before accessing the object:
const AnRWLock<Counter>& cc = c; std::cout << "Extracted value: " << cc->get() << std::endl; With the result:
RWMutex :: rlock Counter :: get: 2 Extracted value: 2 RWMutex :: runlock
But this solution looks, to put it mildly, not very attractive. I would like to write simply and briefly, and not to use bulky constructions with each reference to constant methods.
To solve this problem, we introduce a new long arrow
---> operator that would write to the object, i.e. access to non-constant methods, and the usual (short) arrow -> leave for reading. The reasons for using a short arrow for reading and long for writing, and not vice versa, are as follows:- Visual . Immediately see where the operation is used.
- Semantic . Reading is like a superficial use of an object: I touched and let go. And the record is a deeper operation, a change, so to speak, of the entrails, therefore the arrow is longer.
- Pragmatic . When replacing a regular mutex with an RW mutex, you just need to correct the compilation errors, replacing the short arrow with the long one in these places, and everything will work in the most optimal way.
Here, probably, the attentive reader wondered: where can we get the same weed as the author of the article? After all

Let's look at the implementation:
// , : WAccess operator--(int) { return *this; } // , : RAccess operator->() const { return *this; } Using:
AnRWLock<Counter> c; // : c->set(2) c--->set(2); Sequencing:
RWMutex :: wlock Counter :: set: 2 RWMutex :: wunlock
Everything is as before, except for the use of a long arrow. Look further:
std::cout << "Extracted value: " << c->get() << std::endl; RWMutex :: rlock Counter :: get: 2 Extracted value: 2 RWMutex :: runlock
In my opinion, the use of a long arrow for a write operation is fully justified: our problem solves this, and in a very elegant way.
If the reader does not quite understand how it works
If the reader does not quite understand how it works, then I will give the following equivalent code for using the “long” arrow as a hint:
(c--)->set(2); Copy-on-write
Next, consider the following interesting and useful idiom: copy-on-write ( COW ), or Copy on write [8] . As the name implies, the basic idea is that immediately before changing the data of a certain object, it first copies to a new place in memory, and only then changes to the new address.Although the COW approach is not directly related to multithreading, however, using this approach in conjunction with others greatly improves usability and adds a number of irreplaceable elements. That is why the implementation of COW is given below. Moreover, the developed tricks are easily and naturally transferred to the implementation of this idiom.
So, as with the RW mutex, we need to distinguish read operations from write operations. When reading anything special should not happen, but when writing, if the object has more than one owner, then this object must first be copied.
template<typename T> struct AnCow { // ... // T* operator--(int) { return getW0(); } // const T* operator->() const { return getR0(); } // ( !) void clone() { data.reset(new T(*data)); } // ... private: T* getR0() const { const_cast<An*>(this)->init(); return data.get(); } T* getW0() { init(); // “” if (!data.unique()) clone(); return data.get(); } It should be noted that the use of polymorphic objects is not considered here (i.e., we never create heirs of the template class
T ), since this is beyond the scope of this article. In the next article I will try to give a detailed solution to this issue, while the implementation will be quite unusual.We proceed to use:
| Code | Console output |
|---|---|
| Counter :: set: 2 |
| Counter :: get: 2 Extracted value: 2 |
| Counter :: get: 2 Extracted value: 2 |
| Counter copy ctor: 2 Counter :: inc: 3 |
| Counter :: dec: 1 |
2 . Next, the value of the new variable is assigned, and the object data is used the same. When outputting d->get() , the same object is used.Then, when
d--->inc() is called, the most interesting thing happens: first the object is copied, and then the resulting value is increased to 3. When you call c--->dec() later, copying does not occur, because the owner is now only one and we have two different copies of the object. I think this example clearly illustrates the work of COW .Key-value storage in memory
Finally, we consider some variations of the implementation of key-value storage in memory when working in a multi-threaded environment using the developed techniques.We will use the following implementation for our repositories:
template<typename T_key, typename T_value> struct KeyValueStorageImpl { // void set(T_key key, T_value value) { storage.emplace(std::move(key), std::move(value)); } // T_value get(const T_key& key) const { return storage.at(key); } // void del(const T_key& key) { storage.erase(key); } private: std::unordered_map<T_key, T_value> storage; }; Let's tie the repository to a singleton to simplify further manipulations (see Using the Singleton Pattern [1] ):
template<typename T_key, typename T_value> void anFill(AnRWLock<KeyValueStorageImpl<T_key, T_value>>& D_an) { D_an = anSingleRWLock<KeyValueStorageImpl<T_key, T_value>>(); } Thus, when creating an
AnRWLock<KeyValueStorageImpl<T,V>> instance, the object retrieved from the singleton will be “flooded”, i.e. AnRWLock<KeyValueStorageImpl<T,V>> will always point to a single instance.For reference, I will give the used infrastructure:
AnRWLock.hpp
#ifndef AN_RWLOCK_HPP #define AN_RWLOCK_HPP #include <memory> #include <stdexcept> #include <string> #include "Mutex.hpp" // fill #define PROTO_IFACE_RWLOCK(D_iface, D_an) \ template<> void anFill<D_iface>(AnRWLock<D_iface>& D_an) #define DECLARE_IMPL_RWLOCK(D_iface) \ PROTO_IFACE_RWLOCK(D_iface, a); #define BIND_TO_IMPL_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_RWLOCK(D_impl) \ BIND_TO_IMPL_RWLOCK(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a = anSingleRWLock<D_impl>(); } #define BIND_TO_SELF_SINGLE_RWLOCK(D_impl) \ BIND_TO_IMPL_SINGLE_RWLOCK(D_impl, D_impl) template<typename T> struct AnRWLock { template<typename U> friend struct AnRWLock; struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; AnRWLock() {} template<typename U> explicit AnRWLock(const AnRWLock<U>& a) : data(a.data) {} template<typename U> explicit AnRWLock(AnRWLock<U>&& a) : data(std::move(a.data)) {} WAccess operator--(int) { return *this; } RAccess operator->() const { return *this; } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: T* get0() const { const_cast<AnRWLock*>(this)->init(); return data.get(); } std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; }; template<typename T> void anFill(AnRWLock<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnRWLockAutoCreate : AnRWLock<T> { AnRWLockAutoCreate() { this->create(); } }; template<typename T> AnRWLock<T> anSingleRWLock() { return single<AnRWLockAutoCreate<T>>(); } #endif AnCow.hpp
#ifndef AN_COW_HPP #define AN_COW_HPP #include <memory> #include <stdexcept> #include <string> // fill #define PROTO_IFACE_COW(D_iface, D_an) \ template<> void anFill<D_iface>(AnCow<D_iface>& D_an) #define DECLARE_IMPL_COW(D_iface) \ PROTO_IFACE_COW(D_iface, a); #define BIND_TO_IMPL_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_COW(D_impl) \ BIND_TO_IMPL_COW(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a = anSingleCow<D_impl>(); } #define BIND_TO_SELF_SINGLE_COW(D_impl) \ BIND_TO_IMPL_SINGLE_COW(D_impl, D_impl) template<typename T> struct AnCow { template<typename U> friend struct AnCow; AnCow() {} template<typename U> explicit AnCow(const AnCow<U>& a) : data(a.data) {} template<typename U> explicit AnCow(AnCow<U>&& a) : data(std::move(a.data)) {} T* operator--(int) { return getW0(); } const T* operator->() const { return getR0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } // TODO: update clone functionality on creating derived instances void clone() { data.reset(new T(*data)); } private: T* getR0() const { const_cast<AnCow*>(this)->init(); return data.get(); } T* getW0() { init(); if (!data.unique()) clone(); return data.get(); } std::shared_ptr<T> data; }; template<typename T> void anFill(AnCow<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnCowAutoCreate : AnCow<T> { AnCowAutoCreate() { this->create(); } }; template<typename T> AnCow<T> anSingleCow() { return single<AnCowAutoCreate<T>>(); } #endif Further, various ways of using this repository, from simple to complex, will be discussed.
Example 1. The simplest use.
We will directly use the storage without additional frills: // template<typename T_key, typename T_value> struct KeyValueStorage : AnRWLock<KeyValueStorageImpl<T_key, T_value>> { typedef T_value ValueType; }; Usage example:
| Code | Console output |
|---|---|
| RWMutex :: wlock Key-value: inserting key: Peter RWMutex :: wunlock |
| RWMutex :: wlock Key-value: inserting key: Nick RWMutex :: wunlock |
| RWMutex :: rlock Key-value: extracting key: Peter Peter age: 28 RWMutex :: runlock |
kv object, into which a single copy of the repository is poured, using a singleton (see the anFill function).Next, the entries Peter and Nick are added, and then the age of Peter is displayed.I think it’s clear from the output that write-lock is automatically taken when writing, and read-lock is taken automatically when reading.
Example 2. Nested RW Mutexes.
Consider a slightly more complex example. Suppose now that we want to have named countersCounterand use them from several threads. No problems: // , AnRWLock template<typename T_key, typename T_value> struct KeyValueStorageRW : KeyValueStorage<T_key, AnRWLock<T_value>> { }; // typedef KeyValueStorageRW<std::string, Counter> KVRWType; Usage example:
| Code | Console output |
|---|---|
| RWMutex :: wlock Key-value: inserting key: users RWMutex :: wunlock |
| RWMutex :: wlock Key-value: inserting key: sessions RWMutex :: wunlock |
| RWMutex :: rlock Key-value: extracting key: users RWMutex :: wlock Counter :: inc: 1 RWMutex :: wunlock RWMutex :: runlock |
| RWMutex :: rlock Key-value: extracting key: sessions RWMutex :: wlock Counter :: inc: 1 RWMutex :: wunlock RWMutex :: runlock |
| RWMutex :: rlock Key-value: extracting key: sessions RWMutex :: wlock Counter :: dec: 0 RWMutex :: wunlock RWMutex :: runlock |
Example 3. Access optimization.
Although I would like to talk about some optimizations in the next article, I will describe here, in my opinion, quite an important optimization.Below are the different uses for comparison.
Option 1: normal
| Code | Console output |
|---|---|
| RWMutex :: rlock Key-value: extracting key: users RWMutex :: wlock Counter :: inc: 2 RWMutex :: wunlock RWMutex :: runlock |
Option 2: optimal
| Code | Console output |
|---|---|
| RWMutex :: rlock Key-value: extracting key: users RWMutex :: runlock |
| RWMutex :: wlock Counter :: inc: 3 RWMutex :: wunlock |
Counteris taken only after the first one, which controls the key-value storage, is released. This implementation provides a more optimal use of mutexes, although we end up with a longer record. This optimization is worth keeping in mind when using nested mutexes.Example 4. Support atomic changes.
Suppose that we need to atomically increase one of the counters by 100, for example, “users”. Of course, for this you can call for 100 times the operationinc(), but you can do this:| Code | Console output |
|---|---|
| RWMutex :: rlock Key-value: extracting key: users RWMutex :: runlock |
| RWMutex :: wlock Counter :: get: 4 Counter :: set: 104 RWMutex :: wunlock |
WAccessfurther, all operations come with the usual “short” arrow, since access to the object to write already received. Also pay attention to the fact that the operations getand setare under the same mutex, which is what we wanted to achieve. This is very similar to the fact that we seem to have opened a transaction when acting on an object.The same trick can be used in conjunction with the optimization described above to access the counters directly.
Option 1: normal
| Code | Console output |
|---|---|
| RWMutex :: rlock Key-value: extracting key: users RWMutex :: wlock Counter :: inc: 4 RWMutex :: wunlock RWMutex :: runlock |
| RWMutex :: rlock Key-value: extracting key: sessions RWMutex :: wlock Counter :: dec: -1 RWMutex :: wunlock RWMutex :: runlock |
Option 2: optimal
| Code | Console output |
|---|---|
| RWMutex :: rlock Key-value: extracting key: users Key-value: extracting key: sessions RWMutex :: runlock |
| RWMutex :: wlock Counter :: inc: 5 RWMutex :: wunlock |
| RWMutex :: wlock Counter :: dec: -2 RWMutex :: wunlock |
Example 5. COW.
Suppose we have employees with the following information: struct User { std::string name; int age; double salary; // ... }; Our task: to conduct various operations on selected users, for example, to calculate the balance sheet. The situation is complicated by the fact that the operation is long. At the same time, when calculating, a change in employee information is unacceptable, since different indicators should be consistent, and if any data changes, the balance may not converge. At the same time, it would be desirable that during the operation, information about employees could be changed without waiting for the end of long-term operations. To implement the calculation, it is necessary to snapshot the data for a certain point in time. Of course, the data may become irrelevant, but for balance it is more important to have self-consistent results.
Let's see how this can be done using COW. Preparatory stage:
Using COW when creating an instanceUser |
We declare a new class that can store objects with AnCow |
Our storage ad: int- user id, User- user |
Adding information about the user Peter |
Adding information about the user George |
Changing employee age information |
Getting the right users |
Calculation of the required parameters. All data will be self-consistent and will remain unchanged until the end of operations. |
In general, one could of course use the copying of all elements before the calculation. However, if there is a sufficiently large amount of information, this will be a rather lengthy operation. Therefore, it is delayed in the indicated approach until it is really necessary to copy the data, i.e. only when used simultaneously in the calculations and changes.
Analysis and synthesis
Below is an analysis of examples. The most interesting, above all, is the last example from COW , since there are unexpected surprises.Detail in
Consider the sequence of operations of the last example. Below is a general scheme when retrieving a value from a container:
Here
Datais the Userexample described above, and shared_ptr<Data>this is the contents of the object AnCow. Sequence of operations:| N | Description | |
|---|---|---|
| one | lock | Lock storage is done automatically when you call operator-> |
| 2 | copy | Copy shared_ptr<Data>, i.e. in fact, there is a simple increase in counters ( use_countand weak_countinside the object shared_ptr<Data>) |
| 3 | unlock | Unlocking a temporary object destructor storage |
What happens when writing data to an object? We look:
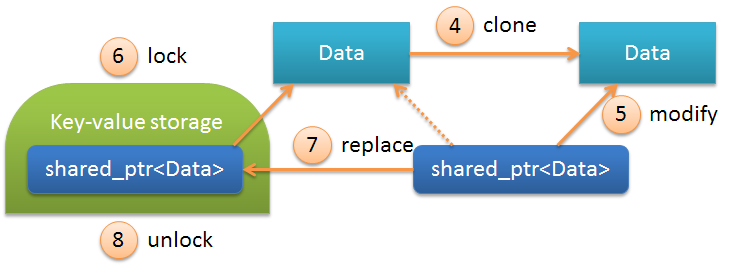
The sequence of operations is as follows:
| N | Description | |
|---|---|---|
| four | clone | Object cloning, the object's copy constructor is called Data, i.e. copy all its fields to a new memory area. After this operation shared_ptrbegins to look at the newly created object. |
| five | modify | . , .. . |
| 6 | lock | . |
| 7 | replace | shared_ptr<Data> , 5- . |
| eight | unlock | . |
int. The essential difference is that with COW, data can be used from the same memory area in several threads simultaneously.It should be noted that most of the above operations occur automatically, i.e. There is no need to perform all operations explicitly.
COW number optimization
As shown above, when a COW object changes , all its fields are copied. This is not a big problem with a small amount of data. But what to do if we have a large number of parameters in the class? In this case, you can use multi-level COW- objects. For example, one could introduce the following classUserInfo: struct UserInfo { AnCow<AccountingInfo> accounting; AnCow<CommonInfo> common; AnCow<WorkInfo> work; }; struct AccountingInfo { AnCow<IncomingInfo> incoming; AnCow<OutcomingInfo> outcoming; AnCow<BalanceInfo> balance; }; struct CommonInfo { // .. }; // .. By entering COW objects at each level , you can significantly reduce the number of copies. At the same time, the copy operation itself will consist only in the atomic increase of the counters. And only the change object itself will be copied using the copy constructor. It can easily be shown that the minimum number of copies is achieved when the number of objects at each level is 3 m .
Generalized schema
Having considered in more detail the operations with COW , taking into account the nesting, we can now safely proceed to the generalization of the use of the considered idioms. But for this, we first consider the schemes used in the examples.In the first example, the nested
AnRWLockobjects were used: The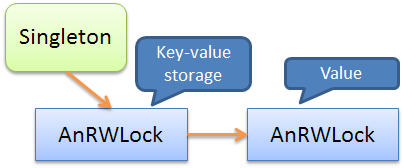
key-value storage in the specified example was put in a singleton and wrapped in a “smart” mutex from above. The values were also wrapped in a “smart” mutex.
The following diagram describes an example with COW :
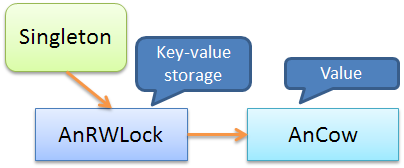
Here the value has been wrapped into an object
AnCowto implement the COW semantics .Accordingly, the generalized scheme can be represented as:
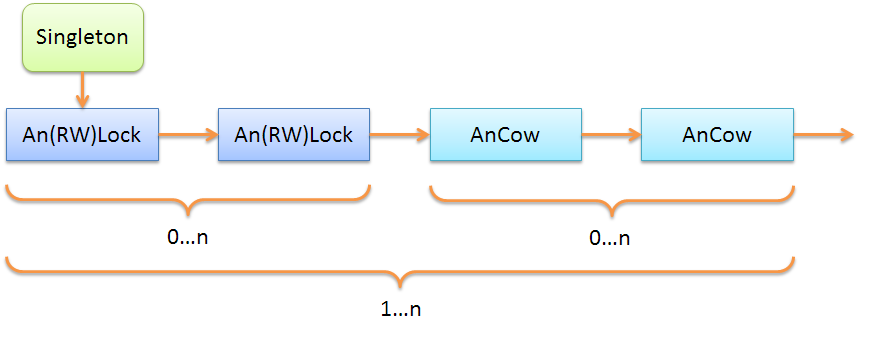
It is clear that the objects
AnLockandAn(RW)Lockinterchangeable: you can use one or the other. You can also chain repeated several times as showily in the example below: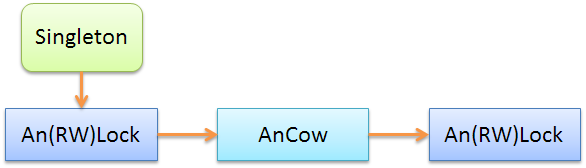
However, it should be remembered that the semantics of the objects
An(RW)Lockand AnCowis significantly different:| Property | Smart mutex | Cow |
|---|---|---|
| Access to object fields | Blocked during read / write | Not blocked |
| Modifying an object in a container | In-place change | After the change, you must put the new value back into the container. |
findings
So, the article examined some idioms that increase the efficiency of writing multi-threaded applications. It is worth noting the following benefits:- Simplicity . There is no need to explicitly use multi-thread primitives, everything happens automagically.
- . . ( ) .
- . , (race condition) (deadlock). . (fine-grained) , .
Such a universal approach has become possible due to the fact that in the implementation of
Anclasses, there is full control over the use of stored objects. Therefore, it is possible to add the necessary functionality, automatically calling the necessary methods on the access boundaries. This approach will be significantly deepened and expanded in the next article.The above material did not consider the use of polymorphic objects. In particular, the implementation
AnCowworks only with the same template class, since always call the copy constructor for the declared type T. The following article will provide an implementation for a more general case. There will also be a unification of objects and ways to use them, talked about various optimizations, multi-threaded links, and much more.Literature
[1] Habrahabr: Singleton pattern usage[2] Habrahabr: Singleton and object lifetime
[3] Habrahabr: Dependency treatment and generating design patterns
[4] Habrahabr: Singleton implementation in multi-threaded application
[5] Wikipedia: Race status
[6] Wikipedia : interlocking
[7] Wikipedia: Readers-writer lock
[8] Wikipedia: Copy-on-write
[9] Habrahabr: threading common data and mutexes
[10] Habrahabr: Cross-platform multithreaded applications
[11] Habrahabr: flows lock and conditional variables in C ++ 11 [Part 2]
[12] Habrahabr: Flows, locks and condition variables in C ++ 11 [Part 1]
[13] Habrahabr: Two simple rules for preventing deadlocks on mutexes
[14] DrDobbs: Enforcing Correct Mutex Usage with Synchronized Values
PS Solution of the problem about the number of copies
,
n , — k , — a . a = n^k , k = ln a/ln n . ln k = a/n .= n*k ( n ). Those. = n*ln a/ln n n/ln n , .. a — const. , n = e , 3.And finally - a poll. There are 2 issues on the agenda:
Source: https://habr.com/ru/post/184436/
All Articles