Rings, Privilege Levels, and Protection in x86
You probably intuitively guessed that applications running on Intel x86 computers are limited in their capabilities, and that some actions can only be performed by the operating system. But do you know how it really works? In this post, we look at the x86 privilege levels — a mechanism in which the OS and processor work together to limit what user mode applications can do.
Translation of the Gustavo Duarte article: CPU Rings, Privilege, and Protection
')
There are four privilege levels, they are numbered from 0 (the most privileged level), to 3 (the least privileged level), and three types of resources that are protected by the processor's protection mechanisms: memory, input / output ports, and the ability to execute certain instructions. At any time, the x86 processor runs at a certain privilege level, and it depends on what the code can and cannot do. Privilege levels are also often called protection rings, which are depicted as nested circles. The most privileged level corresponds to the circle with the highest degree of nesting. Most modern kernels for the x86 architecture use only two privilege levels - 0 and 3.
The execution of about 15 instructions (and only a few dozen of them) is possible only in ring 0. Other instructions have limitations associated with valid operands. If these restrictions did not exist, then it would be impossible to ensure the functioning of the protection mechanisms, since These instructions may bypass them or lead to other negative consequences. Restricted instructions can only be used in kernel code. Attempting to perform them outside the zero ring will result in the #GP (general-protection exception) exception. Exactly the same exception occurs, for example, when a program tries to access invalid memory addresses. Similarly, depending on the level of privileges, access to memory and input / output ports is restricted.
Before we turn to the protection mechanism, let's see how the processor monitors the current level of privileges. Segmental selectors (segment selectors), which we considered in a previous post, are directly related to this. Here they are:
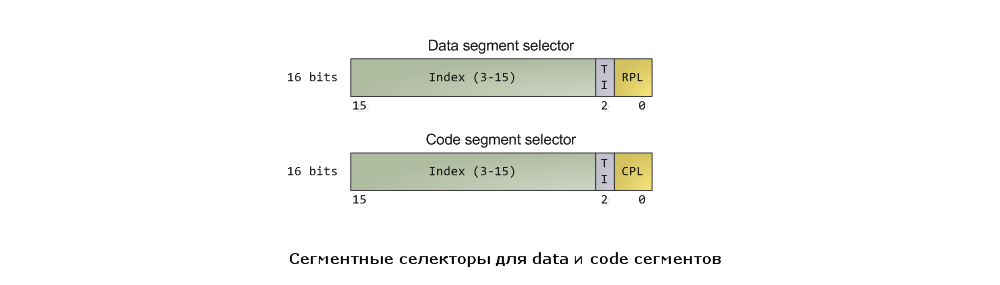
The programmer uses certain instructions to load the segment selector for the data segment into any of the segment registers for the data (for example, SS or DS). This loads the entire contents of the segment selector, including the Requested Privilege Level (RPL) field, the purpose of which will be described a little below. As for the CS register, here everything happens a little differently. First, you cannot directly use load instructions like mov in order to load a selector into this register. Instead, the contents of the register can change only as the result of executing an instruction that controls the flow of execution, for example, far call. Secondly, and this is very important for us, instead of the RPL field, the value of which is determined by the programmer, the selector in the CS register has the Current Privilege Level (CPL) field, the value of which is set and controlled by the processor itself. The two-bit CPL field in the CS register always reflects the current privilege level on which the processor is running. Intellectual docks, including those published on the Internet, may have discrepancies on this issue, however, this fact clearly reflects the essence of things. At any time, so that there does not occur in the processor itself, looking at the value of the CPL field in the CS register, we always find out the current level of privileges with which the code is executed.
Please note that the current level of privileges of the processor has nothing to do with the privileges of users of the operating system. It does not matter at all from which account you are working - root, Administrator, guest or regular user. The code of all user applications is executed in ring 3, while any code related to the kernel is executed in ring 0. Sometimes some typical tasks for the kernel can carry out in user space — for example, some drivers are implemented in Windows Vista, but this can be considered only as a special case when special processes just do some work for the kernel. Usually they can be killed without any serious consequences.
Due to the existing restrictions on access to memory and I / O ports, the program executed in user mode itself can in fact in no way affect the “surrounding world” and can do nothing without the assistance of the kernel. Such a program cannot open a file, send a network packet, display a line of text, or allocate memory for itself. We can say that user processes are performed in a kind of sandboxes with drastically reduced capabilities that were prepared for them by the “gods of the zero ring”. Thus, a memory leak, if one is caused by a process, cannot survive the process itself, just like the files opened during the life of the process will not remain open after its completion. All data structures used to control such things — allocated memory, open files — are not accessible to user code; as soon as the program completes execution, its sandbox is destroyed by the kernel. That is why modern servers can have up to 600 hours of uptime - if the hardware or the kernel is not running, everything can work forever. And this, by the way, is the reason why Windows 95/98 so often fell: no, it’s not because “M $ sucks”, just to ensure backward compatibility, some important data structures were left available for user mode applications. At that time, it was probably a reasonable compromise, but it cost a very high price.
The processor protects the memory at two strategic points: at the moment when an attempt is made to load the segment selector into the register, and also when the memory page is accessed. The protection mechanism thus reflects the main stages of the targeted broadcast, where segmentation and paging are also involved. An attempt to load a segment selector is accompanied by the following check:
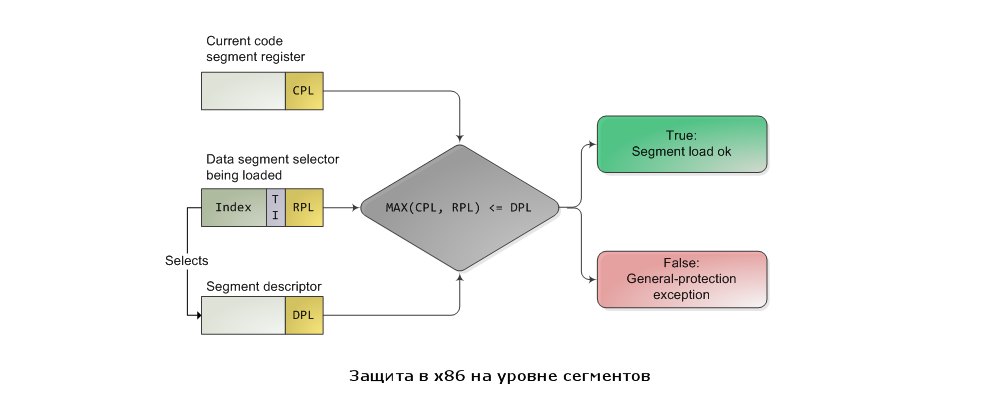
The larger the number, the lower the level of privilege it denotes. Thus, the MAX () function selects the value that expresses the lowest level of privileges (be it CPL or RPL), which is then compared to the level of privileges of the target descriptor (DPL). If the DPL is greater than or equal to, access is allowed. The whole point of using the RPL in this formula is that it allows the kernel to access a segment with a deliberately low level of privileges, if necessary. For example, you can use a selector in which RPL is set to 3 in order to limit some operation to the ability to work only with user mode data segments. Check when loading the selector in the SS register is different, here for its successful passage all three values of CPL, RPL and DPL must match.
In fact, protection at the segment level does not play a special role, since modern kernels use a “flat” model of memory organization, in which the user mode segment covers the entire available physical address space. Some useful memory protection is implemented in the paging unit when converting a linear address to a physical one. Each page of memory is a sequence of bytes, which is described by writing to the page table. In this entry, two fields are related to the protection mechanisms, namely the supervisor flag and the read / write flag. The supervisor flag is the primary defense mechanism used by modern kernels. When this flag is cleared, the page cannot be accessed from ring 3. Although the read / write flag does not play any role in checking privileges, it still finds an interesting use. When a program is loaded into memory for execution, the pages of memory storing the executable image of the program are marked as read-only. This allows you to catch some errors when working with pointers, if using them to attempt to write to these pages. The read / write flag is also used to implement the copy on write mechanism when creating a child process using the fork () system call on Unix-like operating systems. When a fork is made, the memory pages of the parent process are marked as read-only. The child process will initially use the same pages of memory as the parent process. If any of them tries to write to the memory page, the processor initiates a fault, and the kernel will work it out as follows - it creates its own copy of the page for the process that tried to write, and also puts read / write rights on this page.
Go ahead. We need a mechanism that would allow the CPU to switch between different levels of privileges. If the code running in ring 3 could transfer control to arbitrary locations in the kernel, it would be easy to bypass the operating system protection mechanisms simply by jmping at the wrong (or correct?) Address. To prevent this, we need a mechanism that provides a controlled transfer of the flow of execution. It is based on the so-called. gate descriptors or sysenter instructions. Gate descriptor is a segment descriptor of the type “system”. There are four varieties of it: call-gate, interrupt-gate, trap-gate and task-gate descriptors. Through the all-gate descriptor, the kernel can provide an entry point that can be used with the usual instructions like far call and far jump. Call-gate descriptors are used infrequently, so we will not talk about them. Task-gate descriptors are of little interest to us (in Linux they are used only when processing double faults, which usually happen because of problems with the kernel or hardware).
There are two other much more interesting types of descriptors: interrupt-gate and trap-gate, which are used to handle hardware interrupts (keyboard, timers, disks) and exceptions (page faults, division by zero). Both of these types of mechanisms I will conditionally call “interruptions”. This type of descriptor is stored in the Interrupt Descriptor Table (IDT). Each interrupt is assigned an identification number from 0 to 255, called a vector. When it is necessary to determine which descriptor to use to handle an interrupt, the processor uses the vector as a pointer to the descriptor in the IDT. The interrupt-gate and trap-gate descriptor formats are virtually identical. This format, as well as the privilege check, which is performed when an interrupt occurs, is shown in the figure. I filled in some of the descriptor fields with the values commonly used by the Linux kernel to add specifics:
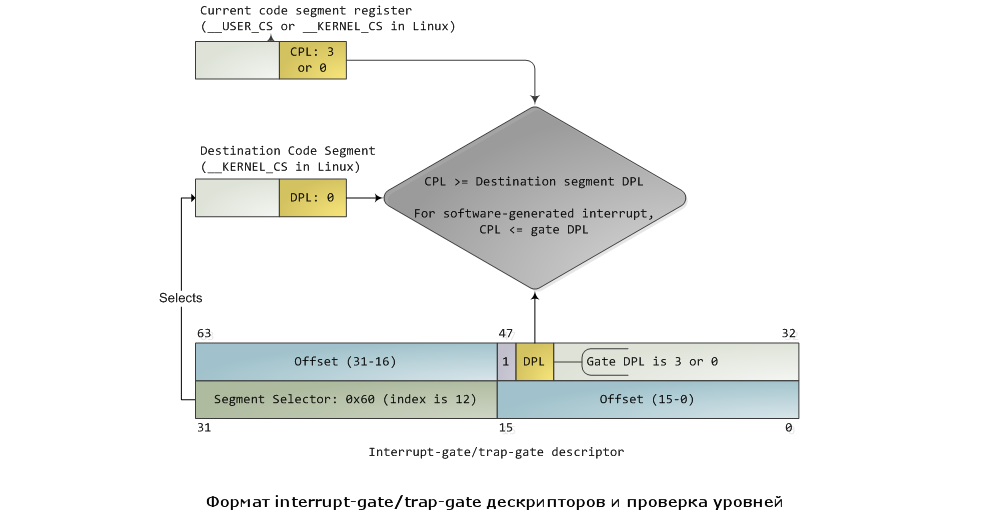
Access is controlled on the basis of the current PL and DPL of the target segment, and the entry point is determined on the basis of the selector and the Offset field in the gate descriptor. In modern kernels, the segment selector contained in the corresponding field of the gate-descriptor usually selects the code segment of the kernel. The interrupt mechanism is designed so that it cannot be used to transfer control from a more privileged ring to a less privileged ring. The privilege level must either remain at the same level or increase (this happens when, for example, the user mode of the application is interrupted). In any case, the new CPL value will be equal to the DPL of the target code of the segment. In a situation where the CPL changes, the stack segment is also automatically switched. If the interrupt is software (caused by the execution of an INT n instruction, for example), another check is additionally performed: the gate DPL must be equal to or greater than the original CPL. This check is designed to make a call to some interrupt handlers unavailable for custom code. In Linux, all interrupt handlers are executed in ring 0.
During initialization, the Linux kernel setup_idt () function creates an IDT table without specifying specific entry points in the descriptors. Then the descriptors will be filled with data in accordance with the contents of the include / asm-x86 / desc.h and arch / x86 / kernel / traps_32.c files. In Linux terminology, a descriptor that has the word “system” in its name is available for use by the user mode code, and the gate DPL is set to 3 for it. The “system gate” is an Intelly trap-gate available for use by the user mode code. In addition, there are no more differences in terminology. Hardware interrupts are not configured here, but in the appropriate drivers.
Three gates are available for use in user mode: vectors 3 and 4 are used for debugging and checking for numeric overflows, respectively. Then comes the system gate, which has an ID equal to the value of the constant SYSCALL_VECTOR - for x86 architecture it is 0x80. Previously, it was the main mechanism for transferring control to the kernel when making a system call. There was a time when, and I wanted to myself a thug number with the characters “int 0x80” Starting with the Pentium Pro, a new sysenter instruction has been added, designed to make a system call faster. This instruction uses special registers that store information about the code segment, entry point, etc. When the sysenter instruction is executed, the privilege level check is not performed, the processor immediately switches to CPL 0 and loads the corresponding values into registers related to the code and the stack (CS, EIP, SS and ESP). Loading values into registers used by the sysenter instruction is possible only from the 0 ring and is performed by the function enable_sep_cpu ().
Finally, when it is time to return to ring 3, the kernel uses an IRET or SYSEXIT instruction to return control after processing an interrupt or system call, respectively. As a result, we leave the ring 0, and the user mode of the code is renewed with a CPL of 3. Vim tells me that the number of words is already close to 1900, so we’ll leave the topic of I / O ports for later. Thank you all for your attention!
Source: https://habr.com/ru/post/184174/
All Articles