Belt conveyor for linear data
Five years ago I happened to design one program that processes text with control commands. The number of processing steps was quite significant - 6-7 processors could consistently pass through quite large amounts of data, as sometimes happens in Unix pipelines. To accurately accomplish the task, I developed a general method that can be useful in other places. The idea behind this article is really very similar to Unix pipelines, but there are a few significant differences:
It's no secret that in this case there is no need to store data entirely in memory. It is much more efficient to read the file in chunks, which immediately go through all stages of the conversion, without lingering in memory.
Converters are arranged in the form of a “pipeline”, each following receives data from the previous one. The converter can also change the type of data, for example, in the lexer the letters at the input, at the output - the token.
I do not have the implementation of these algorithms worthy of publication, so I will limit myself to a general idea and scheme of implementation. Approximate schemes are given in C ++, they use virtual and multiple inheritance, as well as templates.
')
Let's consider a possible implementation of the converter software interface. In the simplest version, three types of transducers are possible:
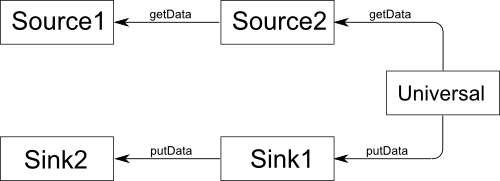
Figure 1. A simple implementation of the pipeline.
Here is a trivial example of such a pipeline, an "adder" (it reads numbers from std :: cin, adds them in pairs, prints to std :: cout, this is a working program in C ++):
The source converter provides an interface that allows the next converter in the pipeline to get a piece of data from it. In contrast, the Sink converter (absorber) can receive a signal from the previous converter that the data is ready. Source gives the data “on demand”, but takes care of its receipt itself, while Sink can give the data to the next element, but receives it only when the previous one likes. Only a universal converter has complete freedom: it can get data from the previous one and pass it on to the next one when it pleases. We note several simple, forced rules of such a simplified “pipeline”, based on the limitations of the converter capabilities:
Using Source and Sink imposes restrictions on the implementation of procedures, as well as on their effectiveness. The programmer would be more comfortable if the pipeline looked like this: Universal, ..., Universal. You can bring this desire to life by adding what the conveyor really lacks: a “belt”. Our tape will be a memory area that stores data “between” the converters. Once the transducer produces data, it is placed on the tape, from where the next transducer can read it. The conveyor is now complicated and can not be controlled by itself, as it was before, so a special “conveyor manager” is required to monitor the tape and the converters. Converters will now be built in the form of heirs from base classes with an interface. Here is their simplified view:
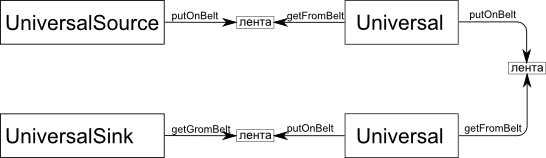
Fig 2. Scheme of the improved implementation of the pipeline.
The process function is implemented in each specific converter in its own way, and fulfills the essence of its purpose. Its task is to produce a certain amount of data and transfer it to the pipeline manager for placement on the tape. For this process calls the function putOnBelt defined in the base class. It is important to understand that the process of each converter can be called several times, it must produce some reasonable amount of data (for example, one unit) and complete. As soon as the process implementation requires input, it accesses the manager by calling getFromBelt .
Here is an example of the same adder, but implemented using the new concept of the pipeline. Now this is not a full-fledged program, it lacks the implementation of the pipeline manager.
It uses functions and classes that were not previously mentioned:
The problem of determining the end of data can be solved as follows: the virtual function bool UniversalSource :: hasData () is defined, the implementation of which by default is based on the rule - we assume that the data is finished if process did not issue anything as an iteration.
The process function is called by the pipeline manager. Differences between different implementations of the pipeline manager can be in the order in which to call the process functions of different converters. It is desirable that the tape does not accumulate an excess of data, as this will increase memory consumption, and also, it is desirable to avoid too deep call stacks.
The getFromBelt function reads data from a tape, if it is on it, and otherwise, it starts the process from the previous converter until it issues some piece of data to the tape. putOnBelt simply puts data on tape. It can call the process of the next converter, so that it immediately processes them, but this is not necessary, and creates difficulties, about which - a little later.
Thus, the call stack in the simple case takes the form:
In order to ensure the normal operation of the pipeline, which is necessary for the functioning of most ordinary applications, it is necessary to fulfill only one axiom:
Here are two possible manager implementations:
The article provides a simplified scheme for the implementation of the pipeline. Its improvements can be implemented:
Also, compared with “implementations in the forehead,” a big advantage is: the independence of the individual parts of the program from each other (each converter knows only the types of its input and output data, may not know anything about the converters to which it is connected by input and output), the ability to safely switch on new converters and change their order.
I apologize to:
I admit that these concepts, and perhaps much more convenient, are implemented in some popular library, such as Boost (if yes - it will be interesting to see). But for me, the content of this article seems to be a beautiful pattern, not only and not so much of practical significance with which I wanted to share.
- Unix pipeline works asynchronously, in different processes, while here it is required to implement processing within one program, and parallelization may be undesirable;
- transfer of any data is possible, not necessarily text, but which can be characterized by the term "linear".
- reading file bytes,
- decoding in UTF-8,
- preprocessor,
- lexical analysis
- parsing
It's no secret that in this case there is no need to store data entirely in memory. It is much more efficient to read the file in chunks, which immediately go through all stages of the conversion, without lingering in memory.
Converters are arranged in the form of a “pipeline”, each following receives data from the previous one. The converter can also change the type of data, for example, in the lexer the letters at the input, at the output - the token.
I do not have the implementation of these algorithms worthy of publication, so I will limit myself to a general idea and scheme of implementation. Approximate schemes are given in C ++, they use virtual and multiple inheritance, as well as templates.
')
What happens if you design the processing of linear data, especially without bothering
Let's consider a possible implementation of the converter software interface. In the simplest version, three types of transducers are possible:
class Source { … public: T getData(); … }; class Sink { … public: void putData(T); … }; class Universal { … public: void process(); }; Figure 1. A simple implementation of the pipeline.
Here is a trivial example of such a pipeline, an "adder" (it reads numbers from std :: cin, adds them in pairs, prints to std :: cout, this is a working program in C ++):
#include <iostream> // std::cin class IntSource { public: int getData() { int next; std::cin>>next; return next; } bool good() const { return std::cin.good(); } }; // std::cout class IntSink { public: void putData(int data) { std::cout<<data<<std::endl; } }; // IntSource IntSink class IntUniversal { IntSource source; IntSink sink; public: void process() { int i1 = source.getData(); int i2 = source.getData(); if( good() ) sink.putData(i1+i2); } bool good() const { return source.good(); } }; int main() { IntUniversal belt; while( belt.good() ) belt.process(); } The source converter provides an interface that allows the next converter in the pipeline to get a piece of data from it. In contrast, the Sink converter (absorber) can receive a signal from the previous converter that the data is ready. Source gives the data “on demand”, but takes care of its receipt itself, while Sink can give the data to the next element, but receives it only when the previous one likes. Only a universal converter has complete freedom: it can get data from the previous one and pass it on to the next one when it pleases. We note several simple, forced rules of such a simplified “pipeline”, based on the limitations of the converter capabilities:
- the first item in the pipeline is the Source;
- the last element is Sink;
- the Sink converter can directly precede only another Sink converter, the Source converter can directly follow only another Source converter;
- Universal converter must follow Source and precede Sink.
- Source k :: getData
- ...
- Source n :: getData
- Universal :: process,
- Sink l :: putData
- ...
- Sink 1 :: putData
- Universal :: process.
We improve the conveyor
Using Source and Sink imposes restrictions on the implementation of procedures, as well as on their effectiveness. The programmer would be more comfortable if the pipeline looked like this: Universal, ..., Universal. You can bring this desire to life by adding what the conveyor really lacks: a “belt”. Our tape will be a memory area that stores data “between” the converters. Once the transducer produces data, it is placed on the tape, from where the next transducer can read it. The conveyor is now complicated and can not be controlled by itself, as it was before, so a special “conveyor manager” is required to monitor the tape and the converters. Converters will now be built in the form of heirs from base classes with an interface. Here is their simplified view:
class UniversalBase { public: virtual void process()=0; }; template<class S> class UniversalSource; template<class T> class UniversalSink; // template <class S> class UniversalSource : public virtual UniversalBase { UniversalSink<S>* next; protected: void putOnBelt(const S&); }; // template <class T> class UniversalSink : public virtual UniversalBase { UniversalSource<T>* prev; protected: T getFromBelt(); }; // , T S template <class T, class S> class Universal : public UniversalSink<T>, public UniversalSource<S> { }; Fig 2. Scheme of the improved implementation of the pipeline.
The process function is implemented in each specific converter in its own way, and fulfills the essence of its purpose. Its task is to produce a certain amount of data and transfer it to the pipeline manager for placement on the tape. For this process calls the function putOnBelt defined in the base class. It is important to understand that the process of each converter can be called several times, it must produce some reasonable amount of data (for example, one unit) and complete. As soon as the process implementation requires input, it accesses the manager by calling getFromBelt .
Here is an example of the same adder, but implemented using the new concept of the pipeline. Now this is not a full-fledged program, it lacks the implementation of the pipeline manager.
#include <iostream> #inlcude <belt.h> // std::cin class IntSource : public Belt::UniversalSource<int> { public: void process() { int data; if( std::cin>>data ) putOnBelt(data); } }; // std::cout class IntSink : public Belt::UniversalSink<int> { public: void process() { if(!hasData() ) return; std::cout<<getFromBelt()<<std::endl; } }; // class IntUniversal : public Belt::Universal<int,int> { public: void process() { int i1 = getFromBelt(); int i2 = getFromBelt(); if(!good() ) return; putOnBelt(i1+i2); } }; int main() { IntSource source; IntUniversal universal; IntSink sink; (source >> universal >> sink).process(); } It uses functions and classes that were not previously mentioned:
bool UniversalSink::hasData(void); bool UniversalSink::good(void); template<class T,class S> class UnboundedBelt : public Universal<T,S> {...}; template<class T> class RightBoundedBelt : public UniversalSink<T> {...}; template<class S> LeftBoundedBelt : public UniversalSource<S> {...}; class Belt : public UniversalBase {...}; template<class T, class R, class S> UnboundedBelt<T,S> operator >> (Universal<T,R>&,Universal<R,S>&); template<class R, class S> LeftBoundedBelt<S> operator >> (UniversalSource<R>&,Universal<R,S>&); template<class T, class R> RightBoundedBelt<T> operator >> (Universal<T,R>&,UniversalSink<R>&); template<class R> Belt operator >> (UniversalSource<R>&,UniversalSink<R>&); The problem of determining the end of data can be solved as follows: the virtual function bool UniversalSource :: hasData () is defined, the implementation of which by default is based on the rule - we assume that the data is finished if process did not issue anything as an iteration.
Approaches to the implementation of the pipeline manager
The process function is called by the pipeline manager. Differences between different implementations of the pipeline manager can be in the order in which to call the process functions of different converters. It is desirable that the tape does not accumulate an excess of data, as this will increase memory consumption, and also, it is desirable to avoid too deep call stacks.
The getFromBelt function reads data from a tape, if it is on it, and otherwise, it starts the process from the previous converter until it issues some piece of data to the tape. putOnBelt simply puts data on tape. It can call the process of the next converter, so that it immediately processes them, but this is not necessary, and creates difficulties, about which - a little later.
Thus, the call stack in the simple case takes the form:
- ...
- pipeline manager
- UniversalSink :: getFromBelt ()
- Converter n 2 :: process ()
- pipeline manager
- UniversalSink :: getFromBelt ()
- Converter n 1 :: process ()
- pipeline manager
In order to ensure the normal operation of the pipeline, which is necessary for the functioning of most ordinary applications, it is necessary to fulfill only one axiom:
- the pipeline manager has no right to call the process function of the converter if the process function of the same converter is already on the call stack. (A)
- the pipeline manager does not have the right to call the process function of the converter if the process function of the leftmost converter is on the call stack.
Here are two possible manager implementations:
- Recursive It calls the process directly only on the last converter, the rest is run recursively if necessary.
- Consistent . Calls the process in turn (from left to right), “accumulating” data on the tape. As soon as it decides that there is enough data, it moves to one converter to the right. For this option, it is desirable to have an estimate of how much data a particular converter “consumes” during one iteration of the process.
Possible buns
The article provides a simplified scheme for the implementation of the pipeline. Its improvements can be implemented:
- “forward looking” operation: the converter reads the data, but in fact it is not removed from the tape, and returned upon its request;
- “Candy boxes”: the delivery of data in chunks, which improves efficiency when working with a large number of small data, such as characters. A “box” is transmitted along the conveyor at once, instead of a “one candy” transfer, which makes it possible to avoid function calls per data unit;
- “Smart” memory allocator (allocator), which will allow you to avoid permanent allocations / deletions of dynamic memory, when the pipeline is working, and can even save you from unnecessary copying operations;
- execution in multiple threads. In the case of a pipeline, this is always possible, and effective, if each of the converters is single-threaded.
Also, compared with “implementations in the forehead,” a big advantage is: the independence of the individual parts of the program from each other (each converter knows only the types of its input and output data, may not know anything about the converters to which it is connected by input and output), the ability to safely switch on new converters and change their order.
Conclusion
I apologize to:
- who have studied the topic, read the literature on this topic, horrified by the terminology or concept;
- knowledgeable English, terrifying precedents for the use of English words in identifiers;
- numerous adherents of coding styles different from my (and no doubt more correct);
- C ++ haters or multiple inheritance;
- programmers not familiar with used C ++ constructs.
I admit that these concepts, and perhaps much more convenient, are implemented in some popular library, such as Boost (if yes - it will be interesting to see). But for me, the content of this article seems to be a beautiful pattern, not only and not so much of practical significance with which I wanted to share.
Source: https://habr.com/ru/post/183998/
All Articles