NETMAP (by Luigi Rizzo). Simple and convenient opensource framework for processing traffic at speeds of 10Gbit / s or 14 Mpps
The bandwidth of communication channels is continuously increasing, if a couple of years ago a server with a 10Gbit / s channel was a privilege of only a few, now there are offers on the market that are available for small and medium-sized companies. At the same time, the TCP / IP protocol stack was developed at a time when speeds of the order of 10Gbit / s could only be dreamed of. As a result, in the code of most modern general-purpose operating systems there are many overheads, wasting resources. Under these conditions, the importance of high-performance processing of network streams is increasing.
The article is based on my report on Highload ++ 2012 and is intended for a quick introduction to a convenient and very effective opensource framework, which is included in the HEAD / STABLE FreeBSD, called NETMAP and allows you to work with packages at speeds of 1-10Gbit / s without using specialized hardware * nix operating systems.
Netmap uses well-known performance enhancement techniques, such as mapping network card buffers, I / O batch processing and using receive and transmit ring memory buffers corresponding to hardware buffers in a network card, which allows you to generate and receive traffic up to 14 million packets per second (which corresponds to the theoretical maximum for 10Gbit / s).
')
The article contains key fragments of NETMAP author publications - Luigi Rizzo, discusses the architecture and key features of the internal implementation of the netmap framework, which encapsulates critical functions when working with the OS kernel and network card, providing a simple and intuitive API to userland.
Under the cat, the main primitives of using the framework for developing applications related to processing packets at 14Mpps are considered, practical experience of using the netmap framework in developing the DDOS protection component responsible for the L3 level is considered. Separately, comparative characteristics of netmap performance on channels 1 / 10Gbit / s, single / multiple processor cores, large and short packets are considered, performance comparisons with FreeBSD / Linux OS stacks.
Modern general-purpose operating systems provide rich and flexible possibilities for processing packets at a low level in network monitoring programs, traffic generation, program switches, routers, firewalls, and attack recognition systems. Software interfaces such as: raw sockets, the Berkley Packet Filter (BPF), the AF_PACKET interface, and the like are currently being used to develop most of these programs. The high packet processing speed required for these applications was apparently not the main goal in the development of the above mechanisms, since in each of the implementations there are significant overhead costs (further overhead).
At the same time, the greatly increased throughput of the transmission medium, network cards and network devices implies the need for such an interface for low-level packet processing that would allow processing at data transmission speeds (wire speed), i.e. millions of packets per second. For better performance, some systems work directly in the operating system kernel or will get access directly to the network card structures (hereinafter referred to as NIC) bypassing the TCP / IP stack and the network card driver. The effectiveness of these systems is determined by taking into account the specific features of the network card hardware, which provide direct access to the NIC data structures.
NETMAP framework successfully combines and expands the ideas implemented in direct access solutions to the NIC. In addition to a dramatic increase in performance, NETMAP provides the userland hardware independent interface for high-performance packet processing. I will give here only one metric in order for you to be able to estimate the speed of packet processing: sending a packet from the transmission medium (cable) to the userspace takes less than 70 CPU cycles. In other words, using NETMAP only on one processor core with a frequency of 900MHz, it is possible to perform fast forwarding at 14.88 million packets per second (Mpps), which corresponds to the maximum transmission rate of Ethernet frames in a 10Gbit / s channel.
Another important feature of NETMAP is that it provides a hardware independent interface for accessing registers and NIC data structures. These structures, as well as critical areas of kernel memory, are inaccessible to the user program, which increases the reliability of work, since from userspace it is difficult to insert an invalid pointer to a memory area and cause a crash in the OS kernel. At the same time, NETMAP uses a very efficient data model that allows zero-copy packet forwarding, i.e. forwarding packages without having to copy memory, which allows you to get tremendous performance.
The article focuses on the architecture and capabilities that NETMAP provides, as well as on the performance indicators that can be obtained with it on regular hardware.
This part of the article will be especially interesting for developers who make such applications as software switches, routers, firewalls, traffic analyzers, attack recognition systems or traffic generators. General-purpose operating systems, as a rule, do not provide efficient mechanisms for accessing raw packets at high speeds. In this section of the article, we will focus on analyzing the TCP / IP stack in the OS, consider where the overheads come from and understand the cost of processing a packet at different stages of its passing through the OS stack.
Network adapters (NICs) for processing incoming and outgoing packets use ring queues (rings) of memory buffer descriptors, as shown in Figure 1.

“Figure №1. NIC data structures and their relationship with OS data structures
Each slot in the ring queue (rings) contains the length and physical address of the buffer. Available (addressable) for the CPU registers NIC contain information about the queues for receiving and transmitting packets.
When a packet arrives on the network card, it is placed in the current memory buffer, its size and status are written to the slot, and information that new incoming data has appeared for processing is written to the corresponding NIC register. The network card initiates an interrupt to inform the CPU of the arrival of new data.
In the case when a packet is sent to the network, the NIC assumes that the OS fills the current buffer, places information about the size of the transmitted data in the slot, writes the number of slots for transmission in the corresponding NIC register, which triggers the sending of packets to the network.
In the case of high rates of reception and transmission of packets, a large number of interruptions can lead to the inability to perform any useful work ("receive live-lock"). To solve these problems, the OS uses the mechanism of polling or interrupt throttling. Some high-performance NICs use multiple queues for receiving / transmitting packets, which allows you to distribute the load on the processor across multiple cores or split a network card into several devices for use in virtual systems working with such a network card.
The OS copies the NIC data structures to the queue of memory buffers, which is specific to each OS. For FreeBSD, these are mbufs equivalent to sk_buffs and NdisPackets. In essence, these memory buffers are containers that contain a large amount of metadata about each packet: the size, the interface with / to which the packet arrived, various attributes and flags defining the processing order of the memory buffer data in the NIC and / or OS.
The NIC driver and the operating system TCP / IP stack (hereinafter referred to as the host stack), as a rule, assume that the packets can be broken into an arbitrary number of fragments, hence the driver and the host stack should be ready to handle packet fragmentation. The corresponding API exported to userspace assumes that various subsystems can leave packets for delayed processing, hence memory buffers and metadata cannot simply be passed by reference during call processing, but they must be copied or processed by reference counting mechanism. All this is a high overhead fee for flexibility and convenience.
The design of the above API was developed quite a long time ago and today is too expensive for modern systems. The cost of allocating memory, managing, and passing through chains of buffers often goes beyond linear dependence on payload data transmitted in packets.
The standard API for input / output of raw packets in a user program requires at least memory allocation for copying data and metadata between the OS kernel and userspace and one system call for each packet (in some cases, for a sequence of packets).
Consider the overheads arising in OS FreeBSD when sending a UDP packet from userlevel using the sendto () function. In this example, userspace, the program sends a UDP packet in a loop. Table 2 illustrates the average time spent processing a package in userspace and various kernel functions. The Time field contains the average time in nanoseconds to process a packet, the value is recorded when the function returns. The delta field indicates the time elapsed before the next function in the chain of execution of the system call starts. For example, 8 nanoseconds takes execution in the context of userspace, 96 nanoseconds takes entry into the context of the OS kernel.
For tests, we use the following macros working in OS FreeBSD:
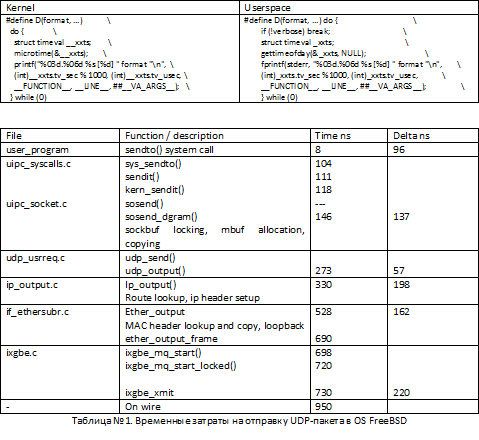
The test was performed on a computer running OS FreeBSD HEAD 64bit, i7-870 2.93GHz (TurboBoost), Intel 10Gbit NIC, ixgbe driver. The values are averaged over several dozens of 5 second tests.
As can be seen from Table 1, there are several functions that consume a critically large amount of time at all levels of packet processing in the OS stack. Any network input / water API, be it TCP, RAW_SOCKET, BPF will be forced to send a packet through some very expensive levels. Using this standard API, there is no way to bypass the memory allocation and copying mechanisms in mbufs, check the correct routes, prepare and construct TCP / UDP / IP / MAC headers and at the end of this processing chain, convert mbuf structures and metadata to NIC format for transmission package in the network. Even in the case of local optimization, for example, caching routes and headers instead of building them from scratch, does not give a radical increase in the speed that is required for processing packets on 10 Gbit / s interfaces.
Since the problem of high-speed packet processing has been relatively long over time, various techniques for increasing productivity have been developed and are being used to qualitatively increase the processing speed.
Berkley Packet Filter (hereinafter referred to as BPF) is the most popular mechanism for accessing raw packages. BPF connects to the network card driver and sends a copy of each received or sent packet to a file descriptor from which the user program can receive / send it. Linux has a similar mechanism called the AF_PACKET socket family. BPF works together with the TCP / IP stack, although in most cases it puts the network card into a “transparent” (promiscuous) mode, which leads to a large flow of extraneous traffic that enters the core and is immediately removed there.
Netgraph (FreeBSD), Netfilter (Linux), Ndis Miniport drivers (MS Windows) are built into the kernel mechanisms that are used when copying packages is not required and an application, such as a firewall, must be built into the packet chain. These mechanisms accept traffic from the network card driver and transmit it to processing modules without additional copying. Obviously, all the mechanisms mentioned in this clause rely on the presentation of packages in the form of mbuf / sk_buff.
One simple way to avoid additional copying in the process of transferring a package from the kernel space to the user space and vice versa is the ability to allow an application direct access to NIC structures. As a rule, this requires that the application runs in the OS kernel. Examples include the Click software router project or the traffic mode kernel mode pkt-gen. Along with ease of access, the kernel space is a very fragile environment, errors in which can lead to a system crash, so a more correct mechanism is to export packet buffers to userspace. Examples of this approach are PF_RING and Linux PACKET_MMAP, which export a shared memory area containing pre-allocated areas for network packets. The operating system kernel copies data between sk_buff'er and packet buffers in shared memory. This allows batch processing of packages, but there are still overheads associated with copying and managing the sk_buff chain.
Even better performance can be achieved if access to the NIC is allowed directly from the userspace. This approach requires special NIC drivers and increases some of the risks, since The NIC DMA engine will be able to write data to any memory address and an incorrectly written client may accidentally “kill” the system by erasing critical data somewhere in the kernel. It is fair to note that a large number of modern network cards have an IOMMU block that restricts the recording of a NIC DMA engine to memory. An example of this approach in accelerating performance are PF_RING_DNA and some commercial solutions.
In the previous article, various mechanisms were considered to increase packet processing performance at high speeds. The costly operations in data processing were analyzed, such as: copying data, managing metadata, and other overheads that occur when a packet passes from userspace through a TCP / IP stack to the network.
The framework presented in the report, called NETMAP, is a system that gives userspace applications very fast access to network packets, both for receiving and sending, both when communicating with the network and when working with the TCP / IP OS stack (host stack). At the same time, efficiency is not sacrificed for risks arising from the full opening of data structures and network card registers in userspace. The framework independently manages the network card, the operating system, at the same time, performs memory protection.
Also, a distinctive feature of NETMAP is tight integration with existing OS mechanisms and the lack of dependence on the hardware features of specific network cards. To achieve the desired high performance characteristics, NETMAP uses several well-known techniques:
• Compact and lightweight package metadata structures. Simple to use, they hide hardware-specific mechanisms, providing a convenient and easy way to work with packages. In addition, the NETMAP metadata is designed to handle many different packets for a single system call, thus reducing the overhead of packet transmission.
• Linear preallocated buffers, fixed sizes. Allows you to reduce the overhead of memory management.
• Zero copy operations for forwarding packets between interfaces, as well as between interfaces and host stack.
• Support for useful hardware features of network cards, such as multiple hardware queues.
In NETMAP, each subsystem does exactly what it is intended for: the NIC transfers data between the network and RAM, the OS kernel performs memory protection, provides multitasking and synchronization.
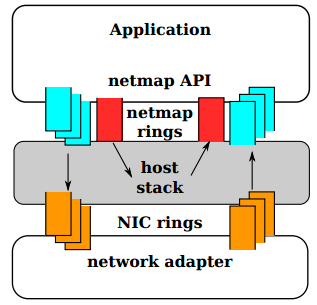
Fig. №2. In NETMAP mode, the NIC queues are disconnected from the TCP / IP OS stack. The exchange between the network and the host stack is carried out only through the NETMAP API
At the topmost level, when an application through the NETMAP API puts the network card into NETMAP mode, the NIC queues are disconnected from the host stack. In this way, the program is able to control the exchange of packets between the network and the OS stack, using circular buffers called “netmap rings”. Netmap rings, in turn, are implemented in shared memory. To synchronize the queues in the NIC and the OS stack, the usual OS system calls are used: select () / poll (). Despite the disconnection of the TCP / IP stack from the network card, the operating system continues to operate and execute its operations.
The key data structures of NETMAP are depicted in Fig. Number 3. Structures were developed taking into account the following tasks:
• Reduced overheads when processing packets
• Increased efficiency in packet transfer between interfaces, and between interfaces and stack
• Support for hardware multiple queues in network cards

Fig. Number 3. Structures exported NETMAP to userspace
NETMAP contains three types of objects visible from userspace:
• packet buffers
• Ring buffers queues (netmap rings)
• Interface descriptor (netmap_if)
All objects of all netmap enabled system interfaces are in the same non-paged shared memory area, which is allocated by the kernel and is accessible between processes from user space. The use of such a dedicated memory segment allows convenient zero-copy exchange of packets between all interfaces and the stack. However, NETMAP supports the separation of interfaces or queues in such a way as to isolate the memory areas provided by different processes from each other.
Since different user processes work in different virtual addresses, all references in the exported NETMAP data structures are relative, i.e. are offsets.
Packet buffers have a fixed size (2K currently) and are used simultaneously by NIC and user processes. Each buffer is identified by a unique index, its virtual address can be easily calculated by the user process, and its physical address can be easily calculated by the NIC DMA engine.
All netmap buffers are allocated at the moment when the network card is switched to NETMAP mode. Metadata describing the buffer, such as index, size, and some flags, is stored in slots, which are the main cell of the netmap ring, which will be described below. Each buffer is bound to the netmap ring and the corresponding queue in the network card (hardware ring).
"Netmap ring" is an abstraction of hardware ring bursts of a network card. Netmap ring is characterized by the following parameters:
• ring_size, the number of slots in the queue (netmap ring)
• cur, the current slot for writing / reading in the queue
• avail, number of available slots: in the case of TX, these are empty slots through which data can be sent, in the case of RX, these are slots filled with a NIC DMA engine where the data came
• buf_ofs, offset between the beginning of the queue and the beginning of the array of fixed-size packet buffers (netmap buffers)
• slots [], an array consisting of ring_size quantities of fixed-size metadata. Each slot contains an index of the packet buffer containing the received data (or data to send), the packet size, some flags used when processing the packet
Finally, netmap_if contains readonly information describing the netmap interface. This information includes: the number of queues (netmap rings) associated with the network card and the offset to obtain a pointer to each of the associated queues with the NIC
As mentioned above, the NETMAP data structures are shared between the kernel and user programs. In NETMAP, the “access rights” and the owners of each of the structures are strictly defined in such a way as to protect the data. In particular, netmap rings are always controlled from the user program, except when a system call is made. During the system call, the code from the kernel space updates the netmap rings, but does so in the context of the user process. Interrupt handlers and other kernel threads never touch netmap rings.
Batch buffers between cur and cur + avail - 1 are also controlled by the user program, while the remaining buffers are processed by code from the kernel. In reality, only the NIC accesses the packet buffers. The boundaries between these two regions are updated during the system call.
In order to put the network card into netmap mode, the program should open the file descriptor on a special device / dev / netmap and execute
Ioctl (..., NIOCREGIF, arg)
Arguments of this system call include: the name of the interface and (optionally) which of the netmap rings we want to open using the just-opened file descriptor. If successful, the size of the shared memory area will be returned, in which all the NETMAP exported data structures and the offset to the netmap_if memory area, through which we receive pointers to these structures, are located.
After the network card is placed in netmap mode, the following two system calls are used to force receiving or sending packets:
• ioctl (..., NIOCTXSYNC) - synchronization of queues (netmap rings) to send with the corresponding queues of the network card, which is equivalent to sending packets to the network, synchronization starts from the cur position
• ioctl (..., NIOCRXSYNC) - synchronization of network card queues with the corresponding netmap rings queues to receive packets received from the network. Recording is done starting from the cur position.
Both of the above system calls are non-blocking, do not perform unnecessary copying of data, with the exception of copying from the network card into netmap rings and vice versa, and work with both one and many packets for one system call. This feature is key and gives a dramatic reduction in overheads when processing packets. The nuclear part of the NETMAP handler performs the following actions during the specified system calls:
• checks the cur / avail queue fields and the contents of slots involved in processing (sizes and indices of packet buffers in netmap rings and hardware rings (network card queues)
• synchronizes the contents of the packet slots involved in processing between the netmap rings and the hardware rings, issues a command to the network card to send packets, or reports the presence of new free buffers for receiving data
• updates the avail field in netmap rings
As you can see, the nuclear handler NETMAP does a minimum of work and includes checking user input to prevent system crashes.
Blocked I / O is supported using select () / poll () system calls with the file descriptor / dev / netmap. The result is either an early return of control with the parameter avail> 0. Before returning control from the kernel context, the system will perform the same actions as in ioctl calls (... NIOC ** SYNC). Using this technique, the user program can, without loading the CPU, check the queue status in a loop, using only one system call per pass.
NETMAP allows you to configure powerful network cards with multiple queues in two ways, depending on how many queues you need to monitor the program. In the default mode, a single file descriptor / dev / netmap controls all netmap rings, but if the ring_id field is specified when opening a file descriptor, the file descriptor is associated with a single pair of netmap rings RX / TX. Using this technique allows you to bind handlers of various netmap queues to specific processor cores via setaffinity () and perform processing independently and without the need for synchronization.
The example shown in Figure 5 is a prototype of the simplest traffic generator based on the NETMAP API. The example is intended to illustrate the ease of use of the NETMAP API. The example uses the NETMAP_XXX macros that make it easier to understand the code, allowing you to calculate pointers to the corresponding NETMAP data structures. To use the NETMAP API there is no need to use any libraries. The API was designed in such a way that the code was obtained as simple and clear as possible.
Prototype traffic generator.
Even when the network card is in netmap mode, the OS network stack still continues to manage the network interface and does not “know” anything about disconnecting from the network card. The user can use ifconfig and / or generate / wait for packets from the network interface. This traffic received or routed to the OS network stack can be processed using a special pair of netmap rings associated with the file descriptor of the / dev / netmap device.
In the case where NIOCTXSYNC is running on this netmap ring, the nuclear netmap handler encapsulates the packet buffers in the mbuf structures of the OS network stack, sending packets to the stack in this way. Accordingly, packets coming from the OS stack are placed in a special netmap ring and become available to the user program via a call to NIOCRXSYNC. Thus, all responsibility when transferring a packet between the netmap rings associated with the host stack and the netmap rings associated with the NIC lies with the user program.
A process using NETMAP, even if it does something wrong, does not have the ability to make a system crash, unlike some other systems, such as UIO-IXGBE, PF_RING_DNA. In fact, the memory area exported by NETMAP to the user space does not contain critical areas, all indexes and sizes of packet and other buffers are easily checked for validity by the OS kernel before use.
The presence of all buffers for all network cards in the same shared memory area allows for very fast (zero copy) transfer of packets from one interface to another or to host stack. To do this, you just need to exchange indices for packet buffers in the netmap rings associated with the incoming and outgoing interfaces, update the packet size, slot flags and set the current position values in the netmap ring (cur), and update the netmap values ring / avail, which signals the appearance of a new package for receiving and sending.
Due to the combination of extremely high performance and convenient mechanisms for accessing the contents of packets, controlling the routing of packets between interfaces and the network stack, NETMAP is a very convenient framework for systems that process network packets at high speeds. Examples of such systems are traffic monitoring applications, IDS / IPS systems, firewalls, routers and, in particular, traffic clearing systems, which are a key component of DDOS protection systems.
The main requirements for the traffic clearing subsystem in the DDOS protection system are the possibility of packet filtering at extreme speeds and the packet processing capabilities in the filter system that implement various currently known techniques for countering DDOS attacks.
Since it is assumed that the prototype of the traffic clearing subsystem will analyze and modify the contents of the packets, as well as manage its own lists and data structures necessary to perform DDOS protection, it is necessary to redistribute CPU resources as much as possible to perform the DDOS module operations, respectively, leaving the to work at full speed minimum. For these purposes, several CPU cores are supposed to be associated with “their own” netmap rings.
In case we plan to exchange packets with the OS network stack, you need to open the netmap rings couple responsible for interacting with the stack.
As a result, after running all threads, the system leaves max_threads + 1 independent threads, each of which works with its netmap ring without the need to synchronize with each other. Synchronization is only required when sharing with a network stack.
The wait and packet loop thus works in rx_thread ().
Thus, after receiving a signal that incoming packets were received in one of the netmap_ring after the system call poll (), control is passed to the process_incoming () function to process the packets in the filters.
After transferring control to process_incoming, you need to access the contents of the packets for analysis and processing by various DDOS recognition techniques.
The considered code examples reveal the basic techniques for working with NETMAP, ranging from transferring a network card to NETMAP mode and ending with accessing the contents of the packets as the packet passes through a chain of filters.
When performing performance evaluation tests, it is always necessary to first determine the testing metrics. A number of subsystems are involved in packet processing: CPU, caches, data bus, etc. The report discusses the CPU usage parameter, since This parameter may be most dependent on the proper implementation of the framework performing the packet processing.
CPU load is usually measured on the basis of two approaches: depending on the size of the transmitted data (per-byte costs) and depending on the number of processed packets (per-packet cost). In the case of NETMAP, due to the fact that zero copy packet forwarding is performed, measuring CPU load based on per-byte is not so interesting compared to per-packet costs, since there is no copying of memory and therefore when transferring large volumes, the load on the CPU will be minimal. At the same time, when measuring on the basis of per-packet costs, NETMAP performs relatively many actions when processing each packet, and therefore, the performance measurement in this approach is of particular interest. So, the measurements were carried out on the basis of the shortest packets, 64 bytes in size (60 bytes + 4 bytes of CRC).
For the measurements, two programs were used: a NETMAP-based traffic generator and a traffic receiver, which performed exclusively incoming packet counts. The traffic generator takes as parameters: the number of cores, the size of the transmitted packet, the number of packets transmitted per system call (batch size).
The i7-870 4-core 2.93GHz CPU (3.2 GHz in turbo-boost mode) was used as a test hardware, the RAM ran at 1.33GHz, a dual-port network card based on the Intel 82599 chipset was installed in the system. As an operating system used by FreeBSD HEAD / amd64.
All measurements were performed on two identical systems connected by cable directly to each other. The obtained results are well correlated, the maximum deviation from the average is about 2%.
The first test results showed that NETMAP is very efficient and completely fills the 10GBit / s channel with the maximum number of packets. Therefore, to perform the experiments, a decrease in the frequency of the processor was performed in order to determine the effectiveness of changes made by the NETMAP code and to obtain various dependencies. The base clock for the Core i7 CPU is 133 MHz, respectively, using the CPU multiplier (max x21) it is possible to run the system on a set of discrete values up to 3GHz.
The first test is to perform traffic generation at different processor frequencies, using different numbers of cores, sending multiple packets in one system call (batch mode).
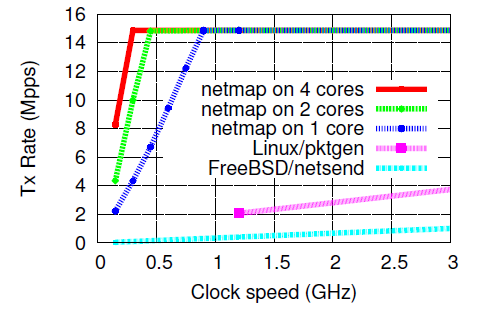
When transmitting 64-byte packets, it allows you to instantly completely fill the 10GBit / s channel on one core and a frequency of 900Mz. Simple calculations show that about 60-65 processor cycles are spent on processing one packet. Obviously, this test only affects the costs that the NETMAP package handling brings. No analysis of the package contents and other actions for the useful processing of the package.
A further increase in the number of cores and the frequency of the processor leads to the fact that the CPU is idle, until the network card is engaged in sending packets and does not inform it of the appearance of new free slots for sending packets.
With an increase in the frequency, the following indicators can be observed for CPU usage on one core:

The previous test shows performance on the shortest packets, which are the most expensive in terms of per-packet costs. This test measures the performance of NETMAP depending on the size of the transmitted packet.
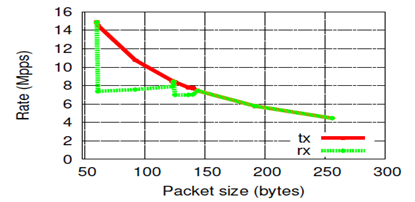
As can be seen from the figure, the speed of sending packets by almost the formula 1 / size decreases with increasing packet size. At the same time, as a surprise, we see that the speed of receiving packets varies in an unusual way. When sending packets of 65 to 127 bytes in size, the speed drops to 7.5 Mpps. This feature is tested in several network cards, including 1Gbit / s.
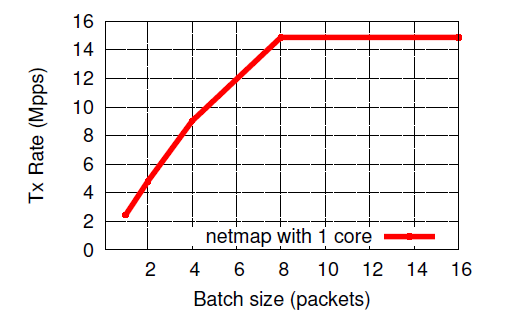
Obviously, working with a large number of packages simultaneously reduces overheads and reduces the cost of processing a single package. Since not all applications can afford to work in this way, it is of interest to measure the processing speed of packets depending on the number of packets processed in one system call.
The author of NETMAP (Luigi Rizzo) managed to achieve a dramatic increase in productivity by eliminating from the process of processing overhead packages that occur when a packet passes through the OS network stack. The speed that NETMAP allows you to receive is limited only by the bandwidth of the channel. NETMAP combines the best techniques for increasing productivity in the processing of network packets, and the concept embedded in the NETMAP API offers a new, healthy approach to developing high-performance applications for processing network traffic.
Currently, the effectiveness of NETMAP is evaluated by the FreeBSD community, NETMAP is included in the HEAD version of OS FreeBSD, as well as in the stable / 9, stable / 8 branches.
The article is based on my report on Highload ++ 2012 and is intended for a quick introduction to a convenient and very effective opensource framework, which is included in the HEAD / STABLE FreeBSD, called NETMAP and allows you to work with packages at speeds of 1-10Gbit / s without using specialized hardware * nix operating systems.
Netmap uses well-known performance enhancement techniques, such as mapping network card buffers, I / O batch processing and using receive and transmit ring memory buffers corresponding to hardware buffers in a network card, which allows you to generate and receive traffic up to 14 million packets per second (which corresponds to the theoretical maximum for 10Gbit / s).
')
The article contains key fragments of NETMAP author publications - Luigi Rizzo, discusses the architecture and key features of the internal implementation of the netmap framework, which encapsulates critical functions when working with the OS kernel and network card, providing a simple and intuitive API to userland.
Under the cat, the main primitives of using the framework for developing applications related to processing packets at 14Mpps are considered, practical experience of using the netmap framework in developing the DDOS protection component responsible for the L3 level is considered. Separately, comparative characteristics of netmap performance on channels 1 / 10Gbit / s, single / multiple processor cores, large and short packets are considered, performance comparisons with FreeBSD / Linux OS stacks.
1. Introduction
Modern general-purpose operating systems provide rich and flexible possibilities for processing packets at a low level in network monitoring programs, traffic generation, program switches, routers, firewalls, and attack recognition systems. Software interfaces such as: raw sockets, the Berkley Packet Filter (BPF), the AF_PACKET interface, and the like are currently being used to develop most of these programs. The high packet processing speed required for these applications was apparently not the main goal in the development of the above mechanisms, since in each of the implementations there are significant overhead costs (further overhead).
At the same time, the greatly increased throughput of the transmission medium, network cards and network devices implies the need for such an interface for low-level packet processing that would allow processing at data transmission speeds (wire speed), i.e. millions of packets per second. For better performance, some systems work directly in the operating system kernel or will get access directly to the network card structures (hereinafter referred to as NIC) bypassing the TCP / IP stack and the network card driver. The effectiveness of these systems is determined by taking into account the specific features of the network card hardware, which provide direct access to the NIC data structures.
NETMAP framework successfully combines and expands the ideas implemented in direct access solutions to the NIC. In addition to a dramatic increase in performance, NETMAP provides the userland hardware independent interface for high-performance packet processing. I will give here only one metric in order for you to be able to estimate the speed of packet processing: sending a packet from the transmission medium (cable) to the userspace takes less than 70 CPU cycles. In other words, using NETMAP only on one processor core with a frequency of 900MHz, it is possible to perform fast forwarding at 14.88 million packets per second (Mpps), which corresponds to the maximum transmission rate of Ethernet frames in a 10Gbit / s channel.
Another important feature of NETMAP is that it provides a hardware independent interface for accessing registers and NIC data structures. These structures, as well as critical areas of kernel memory, are inaccessible to the user program, which increases the reliability of work, since from userspace it is difficult to insert an invalid pointer to a memory area and cause a crash in the OS kernel. At the same time, NETMAP uses a very efficient data model that allows zero-copy packet forwarding, i.e. forwarding packages without having to copy memory, which allows you to get tremendous performance.
The article focuses on the architecture and capabilities that NETMAP provides, as well as on the performance indicators that can be obtained with it on regular hardware.
2. TCP / IP stack of modern OS
This part of the article will be especially interesting for developers who make such applications as software switches, routers, firewalls, traffic analyzers, attack recognition systems or traffic generators. General-purpose operating systems, as a rule, do not provide efficient mechanisms for accessing raw packets at high speeds. In this section of the article, we will focus on analyzing the TCP / IP stack in the OS, consider where the overheads come from and understand the cost of processing a packet at different stages of its passing through the OS stack.
2.1. NIC data structures and operations with them
Network adapters (NICs) for processing incoming and outgoing packets use ring queues (rings) of memory buffer descriptors, as shown in Figure 1.
“Figure №1. NIC data structures and their relationship with OS data structures
Each slot in the ring queue (rings) contains the length and physical address of the buffer. Available (addressable) for the CPU registers NIC contain information about the queues for receiving and transmitting packets.
When a packet arrives on the network card, it is placed in the current memory buffer, its size and status are written to the slot, and information that new incoming data has appeared for processing is written to the corresponding NIC register. The network card initiates an interrupt to inform the CPU of the arrival of new data.
In the case when a packet is sent to the network, the NIC assumes that the OS fills the current buffer, places information about the size of the transmitted data in the slot, writes the number of slots for transmission in the corresponding NIC register, which triggers the sending of packets to the network.
In the case of high rates of reception and transmission of packets, a large number of interruptions can lead to the inability to perform any useful work ("receive live-lock"). To solve these problems, the OS uses the mechanism of polling or interrupt throttling. Some high-performance NICs use multiple queues for receiving / transmitting packets, which allows you to distribute the load on the processor across multiple cores or split a network card into several devices for use in virtual systems working with such a network card.
2.2. Kernel and API for user
The OS copies the NIC data structures to the queue of memory buffers, which is specific to each OS. For FreeBSD, these are mbufs equivalent to sk_buffs and NdisPackets. In essence, these memory buffers are containers that contain a large amount of metadata about each packet: the size, the interface with / to which the packet arrived, various attributes and flags defining the processing order of the memory buffer data in the NIC and / or OS.
The NIC driver and the operating system TCP / IP stack (hereinafter referred to as the host stack), as a rule, assume that the packets can be broken into an arbitrary number of fragments, hence the driver and the host stack should be ready to handle packet fragmentation. The corresponding API exported to userspace assumes that various subsystems can leave packets for delayed processing, hence memory buffers and metadata cannot simply be passed by reference during call processing, but they must be copied or processed by reference counting mechanism. All this is a high overhead fee for flexibility and convenience.
The design of the above API was developed quite a long time ago and today is too expensive for modern systems. The cost of allocating memory, managing, and passing through chains of buffers often goes beyond linear dependence on payload data transmitted in packets.
The standard API for input / output of raw packets in a user program requires at least memory allocation for copying data and metadata between the OS kernel and userspace and one system call for each packet (in some cases, for a sequence of packets).
Consider the overheads arising in OS FreeBSD when sending a UDP packet from userlevel using the sendto () function. In this example, userspace, the program sends a UDP packet in a loop. Table 2 illustrates the average time spent processing a package in userspace and various kernel functions. The Time field contains the average time in nanoseconds to process a packet, the value is recorded when the function returns. The delta field indicates the time elapsed before the next function in the chain of execution of the system call starts. For example, 8 nanoseconds takes execution in the context of userspace, 96 nanoseconds takes entry into the context of the OS kernel.
For tests, we use the following macros working in OS FreeBSD:
The test was performed on a computer running OS FreeBSD HEAD 64bit, i7-870 2.93GHz (TurboBoost), Intel 10Gbit NIC, ixgbe driver. The values are averaged over several dozens of 5 second tests.
As can be seen from Table 1, there are several functions that consume a critically large amount of time at all levels of packet processing in the OS stack. Any network input / water API, be it TCP, RAW_SOCKET, BPF will be forced to send a packet through some very expensive levels. Using this standard API, there is no way to bypass the memory allocation and copying mechanisms in mbufs, check the correct routes, prepare and construct TCP / UDP / IP / MAC headers and at the end of this processing chain, convert mbuf structures and metadata to NIC format for transmission package in the network. Even in the case of local optimization, for example, caching routes and headers instead of building them from scratch, does not give a radical increase in the speed that is required for processing packets on 10 Gbit / s interfaces.
2.3. Modern technology to increase productivity in the processing of packets at high speeds
Since the problem of high-speed packet processing has been relatively long over time, various techniques for increasing productivity have been developed and are being used to qualitatively increase the processing speed.
Socket API
Berkley Packet Filter (hereinafter referred to as BPF) is the most popular mechanism for accessing raw packages. BPF connects to the network card driver and sends a copy of each received or sent packet to a file descriptor from which the user program can receive / send it. Linux has a similar mechanism called the AF_PACKET socket family. BPF works together with the TCP / IP stack, although in most cases it puts the network card into a “transparent” (promiscuous) mode, which leads to a large flow of extraneous traffic that enters the core and is immediately removed there.
Packet filter hooks
Netgraph (FreeBSD), Netfilter (Linux), Ndis Miniport drivers (MS Windows) are built into the kernel mechanisms that are used when copying packages is not required and an application, such as a firewall, must be built into the packet chain. These mechanisms accept traffic from the network card driver and transmit it to processing modules without additional copying. Obviously, all the mechanisms mentioned in this clause rely on the presentation of packages in the form of mbuf / sk_buff.
Direct buffer access
One simple way to avoid additional copying in the process of transferring a package from the kernel space to the user space and vice versa is the ability to allow an application direct access to NIC structures. As a rule, this requires that the application runs in the OS kernel. Examples include the Click software router project or the traffic mode kernel mode pkt-gen. Along with ease of access, the kernel space is a very fragile environment, errors in which can lead to a system crash, so a more correct mechanism is to export packet buffers to userspace. Examples of this approach are PF_RING and Linux PACKET_MMAP, which export a shared memory area containing pre-allocated areas for network packets. The operating system kernel copies data between sk_buff'er and packet buffers in shared memory. This allows batch processing of packages, but there are still overheads associated with copying and managing the sk_buff chain.
Even better performance can be achieved if access to the NIC is allowed directly from the userspace. This approach requires special NIC drivers and increases some of the risks, since The NIC DMA engine will be able to write data to any memory address and an incorrectly written client may accidentally “kill” the system by erasing critical data somewhere in the kernel. It is fair to note that a large number of modern network cards have an IOMMU block that restricts the recording of a NIC DMA engine to memory. An example of this approach in accelerating performance are PF_RING_DNA and some commercial solutions.
3. NETMAP Architecture
3.1. Key Features
In the previous article, various mechanisms were considered to increase packet processing performance at high speeds. The costly operations in data processing were analyzed, such as: copying data, managing metadata, and other overheads that occur when a packet passes from userspace through a TCP / IP stack to the network.
The framework presented in the report, called NETMAP, is a system that gives userspace applications very fast access to network packets, both for receiving and sending, both when communicating with the network and when working with the TCP / IP OS stack (host stack). At the same time, efficiency is not sacrificed for risks arising from the full opening of data structures and network card registers in userspace. The framework independently manages the network card, the operating system, at the same time, performs memory protection.
Also, a distinctive feature of NETMAP is tight integration with existing OS mechanisms and the lack of dependence on the hardware features of specific network cards. To achieve the desired high performance characteristics, NETMAP uses several well-known techniques:
• Compact and lightweight package metadata structures. Simple to use, they hide hardware-specific mechanisms, providing a convenient and easy way to work with packages. In addition, the NETMAP metadata is designed to handle many different packets for a single system call, thus reducing the overhead of packet transmission.
• Linear preallocated buffers, fixed sizes. Allows you to reduce the overhead of memory management.
• Zero copy operations for forwarding packets between interfaces, as well as between interfaces and host stack.
• Support for useful hardware features of network cards, such as multiple hardware queues.
In NETMAP, each subsystem does exactly what it is intended for: the NIC transfers data between the network and RAM, the OS kernel performs memory protection, provides multitasking and synchronization.
Fig. №2. In NETMAP mode, the NIC queues are disconnected from the TCP / IP OS stack. The exchange between the network and the host stack is carried out only through the NETMAP API
At the topmost level, when an application through the NETMAP API puts the network card into NETMAP mode, the NIC queues are disconnected from the host stack. In this way, the program is able to control the exchange of packets between the network and the OS stack, using circular buffers called “netmap rings”. Netmap rings, in turn, are implemented in shared memory. To synchronize the queues in the NIC and the OS stack, the usual OS system calls are used: select () / poll (). Despite the disconnection of the TCP / IP stack from the network card, the operating system continues to operate and execute its operations.
3.2. Data structures
The key data structures of NETMAP are depicted in Fig. Number 3. Structures were developed taking into account the following tasks:
• Reduced overheads when processing packets
• Increased efficiency in packet transfer between interfaces, and between interfaces and stack
• Support for hardware multiple queues in network cards
Fig. Number 3. Structures exported NETMAP to userspace
NETMAP contains three types of objects visible from userspace:
• packet buffers
• Ring buffers queues (netmap rings)
• Interface descriptor (netmap_if)
All objects of all netmap enabled system interfaces are in the same non-paged shared memory area, which is allocated by the kernel and is accessible between processes from user space. The use of such a dedicated memory segment allows convenient zero-copy exchange of packets between all interfaces and the stack. However, NETMAP supports the separation of interfaces or queues in such a way as to isolate the memory areas provided by different processes from each other.
Since different user processes work in different virtual addresses, all references in the exported NETMAP data structures are relative, i.e. are offsets.
Packet buffers have a fixed size (2K currently) and are used simultaneously by NIC and user processes. Each buffer is identified by a unique index, its virtual address can be easily calculated by the user process, and its physical address can be easily calculated by the NIC DMA engine.
All netmap buffers are allocated at the moment when the network card is switched to NETMAP mode. Metadata describing the buffer, such as index, size, and some flags, is stored in slots, which are the main cell of the netmap ring, which will be described below. Each buffer is bound to the netmap ring and the corresponding queue in the network card (hardware ring).
"Netmap ring" is an abstraction of hardware ring bursts of a network card. Netmap ring is characterized by the following parameters:
• ring_size, the number of slots in the queue (netmap ring)
• cur, the current slot for writing / reading in the queue
• avail, number of available slots: in the case of TX, these are empty slots through which data can be sent, in the case of RX, these are slots filled with a NIC DMA engine where the data came
• buf_ofs, offset between the beginning of the queue and the beginning of the array of fixed-size packet buffers (netmap buffers)
• slots [], an array consisting of ring_size quantities of fixed-size metadata. Each slot contains an index of the packet buffer containing the received data (or data to send), the packet size, some flags used when processing the packet
Finally, netmap_if contains readonly information describing the netmap interface. This information includes: the number of queues (netmap rings) associated with the network card and the offset to obtain a pointer to each of the associated queues with the NIC
3.3. Data processing contexts
As mentioned above, the NETMAP data structures are shared between the kernel and user programs. In NETMAP, the “access rights” and the owners of each of the structures are strictly defined in such a way as to protect the data. In particular, netmap rings are always controlled from the user program, except when a system call is made. During the system call, the code from the kernel space updates the netmap rings, but does so in the context of the user process. Interrupt handlers and other kernel threads never touch netmap rings.
Batch buffers between cur and cur + avail - 1 are also controlled by the user program, while the remaining buffers are processed by code from the kernel. In reality, only the NIC accesses the packet buffers. The boundaries between these two regions are updated during the system call.
4. Basic operations in NETMAP
4.1. Netmap API
In order to put the network card into netmap mode, the program should open the file descriptor on a special device / dev / netmap and execute
Ioctl (..., NIOCREGIF, arg)
Arguments of this system call include: the name of the interface and (optionally) which of the netmap rings we want to open using the just-opened file descriptor. If successful, the size of the shared memory area will be returned, in which all the NETMAP exported data structures and the offset to the netmap_if memory area, through which we receive pointers to these structures, are located.
After the network card is placed in netmap mode, the following two system calls are used to force receiving or sending packets:
• ioctl (..., NIOCTXSYNC) - synchronization of queues (netmap rings) to send with the corresponding queues of the network card, which is equivalent to sending packets to the network, synchronization starts from the cur position
• ioctl (..., NIOCRXSYNC) - synchronization of network card queues with the corresponding netmap rings queues to receive packets received from the network. Recording is done starting from the cur position.
Both of the above system calls are non-blocking, do not perform unnecessary copying of data, with the exception of copying from the network card into netmap rings and vice versa, and work with both one and many packets for one system call. This feature is key and gives a dramatic reduction in overheads when processing packets. The nuclear part of the NETMAP handler performs the following actions during the specified system calls:
• checks the cur / avail queue fields and the contents of slots involved in processing (sizes and indices of packet buffers in netmap rings and hardware rings (network card queues)
• synchronizes the contents of the packet slots involved in processing between the netmap rings and the hardware rings, issues a command to the network card to send packets, or reports the presence of new free buffers for receiving data
• updates the avail field in netmap rings
As you can see, the nuclear handler NETMAP does a minimum of work and includes checking user input to prevent system crashes.
4.2. Blocking primitives
Blocked I / O is supported using select () / poll () system calls with the file descriptor / dev / netmap. The result is either an early return of control with the parameter avail> 0. Before returning control from the kernel context, the system will perform the same actions as in ioctl calls (... NIOC ** SYNC). Using this technique, the user program can, without loading the CPU, check the queue status in a loop, using only one system call per pass.
4.3. Multiple Queue Interface
NETMAP allows you to configure powerful network cards with multiple queues in two ways, depending on how many queues you need to monitor the program. In the default mode, a single file descriptor / dev / netmap controls all netmap rings, but if the ring_id field is specified when opening a file descriptor, the file descriptor is associated with a single pair of netmap rings RX / TX. Using this technique allows you to bind handlers of various netmap queues to specific processor cores via setaffinity () and perform processing independently and without the need for synchronization.
4.4. Usage example
The example shown in Figure 5 is a prototype of the simplest traffic generator based on the NETMAP API. The example is intended to illustrate the ease of use of the NETMAP API. The example uses the NETMAP_XXX macros that make it easier to understand the code, allowing you to calculate pointers to the corresponding NETMAP data structures. To use the NETMAP API there is no need to use any libraries. The API was designed in such a way that the code was obtained as simple and clear as possible.
fds.fd = open("/dev/netmap", O_RDWR); strcpy(nmr.nm_name, "ix0"); ioctl(fds.fd, NIOCREG, &nmr); p = mmap(0, nmr.memsize, fds.fd); nifp = NETMAP_IF(p, nmr.offset); fds.events = POLLOUT; for (;;) { poll(fds, 1, -1); for (r = 0; r < nmr.num_queues; r++) { ring = NETMAP_TXRING(nifp, r); while (ring->avail-- > 0) { i = ring->cur; buf = NETMAP_BUF(ring, ring->slot[i].buf_index); //... store the payload into buf ... ring->slot[i].len = ... // set packet length ring->cur = NETMAP_NEXT(ring, i); } } } Prototype traffic generator.
4.5. Sending / receiving packets to / from host stack
Even when the network card is in netmap mode, the OS network stack still continues to manage the network interface and does not “know” anything about disconnecting from the network card. The user can use ifconfig and / or generate / wait for packets from the network interface. This traffic received or routed to the OS network stack can be processed using a special pair of netmap rings associated with the file descriptor of the / dev / netmap device.
In the case where NIOCTXSYNC is running on this netmap ring, the nuclear netmap handler encapsulates the packet buffers in the mbuf structures of the OS network stack, sending packets to the stack in this way. Accordingly, packets coming from the OS stack are placed in a special netmap ring and become available to the user program via a call to NIOCRXSYNC. Thus, all responsibility when transferring a packet between the netmap rings associated with the host stack and the netmap rings associated with the NIC lies with the user program.
4.6. Safety considerations
A process using NETMAP, even if it does something wrong, does not have the ability to make a system crash, unlike some other systems, such as UIO-IXGBE, PF_RING_DNA. In fact, the memory area exported by NETMAP to the user space does not contain critical areas, all indexes and sizes of packet and other buffers are easily checked for validity by the OS kernel before use.
4.7. Zero copy packet forwarding
The presence of all buffers for all network cards in the same shared memory area allows for very fast (zero copy) transfer of packets from one interface to another or to host stack. To do this, you just need to exchange indices for packet buffers in the netmap rings associated with the incoming and outgoing interfaces, update the packet size, slot flags and set the current position values in the netmap ring (cur), and update the netmap values ring / avail, which signals the appearance of a new package for receiving and sending.
ns_src = &src_nr_rx->slot[i]; /* locate src and dst slots */ ns_dst = &dst_nr_tx->slot[j]; /* swap the buffers */ tmp = ns_dst->buf_index; ns_dst->buf_index = ns_src->buf_index; ns_src->buf_index = tmp; /* update length and flags */ ns_dst->len = ns_src->len; /* tell kernel to update addresses in the NIC rings */ ns_dst->flags = ns_src->flags = BUF_CHANGED; dst_nr_tx->avail--; // src_nr_rx->avail--; // avail > 0 5. Example: NETMAP API for use in the traffic clearing subsystem for the DDOS protection system
5.1. Primary requirements
Due to the combination of extremely high performance and convenient mechanisms for accessing the contents of packets, controlling the routing of packets between interfaces and the network stack, NETMAP is a very convenient framework for systems that process network packets at high speeds. Examples of such systems are traffic monitoring applications, IDS / IPS systems, firewalls, routers and, in particular, traffic clearing systems, which are a key component of DDOS protection systems.
The main requirements for the traffic clearing subsystem in the DDOS protection system are the possibility of packet filtering at extreme speeds and the packet processing capabilities in the filter system that implement various currently known techniques for countering DDOS attacks.
5.2. Preparing and enabling netmap mode
Since it is assumed that the prototype of the traffic clearing subsystem will analyze and modify the contents of the packets, as well as manage its own lists and data structures necessary to perform DDOS protection, it is necessary to redistribute CPU resources as much as possible to perform the DDOS module operations, respectively, leaving the to work at full speed minimum. For these purposes, several CPU cores are supposed to be associated with “their own” netmap rings.
struct nmreq nmr; //… for (i=0, i < MAX_THREADS, i++) { // … targ[i]->nmr.ringid = i | NETMAP_HW_RING; … ioctl(targ[i].fd, NIOCREGIF, &targ[i]->nmr); //… targ[i]->mem = mmap(0, targ[i]->nmr.nr_memsize, PROT_WRITE | PROT_READ, MAP_SHARED, targ[i].fd, 0); targ[i]->nifp = NETMAP_IF(targ[i]->mem, targ[i]->nmr.nr_offset); targ[i]->nr_tx = NETMAP_TXRING(targ[i]->nifp, i); targ[i]->nr_rx = NETMAP_RXRING(targ[i]->nifp, i); //… } In case we plan to exchange packets with the OS network stack, you need to open the netmap rings couple responsible for interacting with the stack.
struct nmreq nmr; //… /* NETMAP netmap ring ringid */ targ->nmr.ringid = stack_ring_id | NETMAP_SW_RING; // … ioctl(targ.fd, NIOCREGIF, &targ->nmr); // … <h2>5.3. rx_thread</h2> NETMAP, thread' <source lang="cpp"> for ( i = 0; i < MAX_THREADS; i++ ) { /* start first rx thread */ targs[i].used = 1; if (pthread_create(&targs[i].thread, NULL, rx_thread, &targs[i]) == -1) { D("Unable to create thread %d", i); exit(-1); } } //… /* Wait until threads will finish their loops */ for ( r = 0; r < MAX_THREAD; r++ ) { if( pthread_join(targs[r].thread, NULL) ) ioctl(targs[r].fd, NIOCUNREGIF, &targs[r].nmr); close(targs[r].fd); } //… } As a result, after running all threads, the system leaves max_threads + 1 independent threads, each of which works with its netmap ring without the need to synchronize with each other. Synchronization is only required when sharing with a network stack.
The wait and packet loop thus works in rx_thread ().
while(targ->used) { ret = poll(fds, 2, 1 * 100); if (ret <= 0) continue; … /* run filters */ for ( i = targ->begin; i < targ->end; i++) { ioctl(targ->fd, NIOCTXSYNC, 0); ioctl(targ->fd_stack, NIOCTXSYNC, 0); targ->rx = NETMAP_RXRING(targ->nifp, i); targ->tx = NETMAP_TXRING(targ->nifp, i); if (targ->rx->avail > 0) { … /* process rings */ cnt = process_incoming(targ->id, targ->rx, targ->tx, targ->stack_rx, targ->stack_tx); … } } Thus, after receiving a signal that incoming packets were received in one of the netmap_ring after the system call poll (), control is passed to the process_incoming () function to process the packets in the filters.
5.5. process_incoming ()
After transferring control to process_incoming, you need to access the contents of the packets for analysis and processing by various DDOS recognition techniques.
limit = nic_rx->avail; while ( limit-- > 0 ) { struct netmap_slot *rs = &nic_rx->slot[j]; // rx slot struct netmap_slot *ts = &nic_tx->slot[k]; // tx slot eth = (struct ether_header *)NETMAP_BUF(nic_rx, rs->buf_idx); if (eth->ether_type != htons(ETHERTYPE_IP)) { goto next_packet; // pass non-ip packet } /* get ip header of the packet */ iph = (struct ip *)(eth + 1); // … } The considered code examples reveal the basic techniques for working with NETMAP, ranging from transferring a network card to NETMAP mode and ending with accessing the contents of the packets as the packet passes through a chain of filters.
6. Performance
6.1. Metrics
When performing performance evaluation tests, it is always necessary to first determine the testing metrics. A number of subsystems are involved in packet processing: CPU, caches, data bus, etc. The report discusses the CPU usage parameter, since This parameter may be most dependent on the proper implementation of the framework performing the packet processing.
CPU load is usually measured on the basis of two approaches: depending on the size of the transmitted data (per-byte costs) and depending on the number of processed packets (per-packet cost). In the case of NETMAP, due to the fact that zero copy packet forwarding is performed, measuring CPU load based on per-byte is not so interesting compared to per-packet costs, since there is no copying of memory and therefore when transferring large volumes, the load on the CPU will be minimal. At the same time, when measuring on the basis of per-packet costs, NETMAP performs relatively many actions when processing each packet, and therefore, the performance measurement in this approach is of particular interest. So, the measurements were carried out on the basis of the shortest packets, 64 bytes in size (60 bytes + 4 bytes of CRC).
For the measurements, two programs were used: a NETMAP-based traffic generator and a traffic receiver, which performed exclusively incoming packet counts. The traffic generator takes as parameters: the number of cores, the size of the transmitted packet, the number of packets transmitted per system call (batch size).
6.2. Test iron and OS
The i7-870 4-core 2.93GHz CPU (3.2 GHz in turbo-boost mode) was used as a test hardware, the RAM ran at 1.33GHz, a dual-port network card based on the Intel 82599 chipset was installed in the system. As an operating system used by FreeBSD HEAD / amd64.
All measurements were performed on two identical systems connected by cable directly to each other. The obtained results are well correlated, the maximum deviation from the average is about 2%.
The first test results showed that NETMAP is very efficient and completely fills the 10GBit / s channel with the maximum number of packets. Therefore, to perform the experiments, a decrease in the frequency of the processor was performed in order to determine the effectiveness of changes made by the NETMAP code and to obtain various dependencies. The base clock for the Core i7 CPU is 133 MHz, respectively, using the CPU multiplier (max x21) it is possible to run the system on a set of discrete values up to 3GHz.
6.3. Speed depending on the frequency of the processor, cores, etc.
The first test is to perform traffic generation at different processor frequencies, using different numbers of cores, sending multiple packets in one system call (batch mode).
When transmitting 64-byte packets, it allows you to instantly completely fill the 10GBit / s channel on one core and a frequency of 900Mz. Simple calculations show that about 60-65 processor cycles are spent on processing one packet. Obviously, this test only affects the costs that the NETMAP package handling brings. No analysis of the package contents and other actions for the useful processing of the package.
A further increase in the number of cores and the frequency of the processor leads to the fact that the CPU is idle, until the network card is engaged in sending packets and does not inform it of the appearance of new free slots for sending packets.
With an increase in the frequency, the following indicators can be observed for CPU usage on one core:
6.4. Speed depending on the packet size
The previous test shows performance on the shortest packets, which are the most expensive in terms of per-packet costs. This test measures the performance of NETMAP depending on the size of the transmitted packet.
As can be seen from the figure, the speed of sending packets by almost the formula 1 / size decreases with increasing packet size. At the same time, as a surprise, we see that the speed of receiving packets varies in an unusual way. When sending packets of 65 to 127 bytes in size, the speed drops to 7.5 Mpps. This feature is tested in several network cards, including 1Gbit / s.
6.5. Speed depending on the number of packets for one system call
Obviously, working with a large number of packages simultaneously reduces overheads and reduces the cost of processing a single package. Since not all applications can afford to work in this way, it is of interest to measure the processing speed of packets depending on the number of packets processed in one system call.
7. Conclusion
The author of NETMAP (Luigi Rizzo) managed to achieve a dramatic increase in productivity by eliminating from the process of processing overhead packages that occur when a packet passes through the OS network stack. The speed that NETMAP allows you to receive is limited only by the bandwidth of the channel. NETMAP combines the best techniques for increasing productivity in the processing of network packets, and the concept embedded in the NETMAP API offers a new, healthy approach to developing high-performance applications for processing network traffic.
Currently, the effectiveness of NETMAP is evaluated by the FreeBSD community, NETMAP is included in the HEAD version of OS FreeBSD, as well as in the stable / 9, stable / 8 branches.
Source: https://habr.com/ru/post/183832/
All Articles