Libraries for converting PDF document to image
“The Print Screen key does an excellent job with the task. What could be simpler than saving the document as an image? ”- you ask. For a long time I worked on the tasks of saving reports and forms in PDF format. But even with simple multipage tables of numbers, not all PDF generators coped equally well.
Not so long ago, I came across a project whose customer wanted to convert his marketing masterpieces saved in PDF into one of the graphic formats, such as PNG. After much persuasion and counter-argument, the project budget allowed to buy an inexpensive .NET component.
It remained to choose the most suitable for the requirements of the customer and, if possible, with a good English-speaking, English writing support service (not from the Indian Subcontinent):
')
The main attention was paid to such features of converters as:
After several queries, the search engine issued a group of suitable .NET components:
For testing purposes, a single-page PDF file was chosen 3BigPreview.pdf (taken from the official Adobe site). It includes a large number of graphic elements, demonstrating the ability of the component to render PDF graphic objects and their properties.
It was not immediately possible to launch an example for this library on a 64-bit machine, only by changing the platform from AnyCPU to x86, the result was obtained. The problem arose with setting the correct resolution of the picture. A picture of the correct size of 612 x 792 pixels was obtained only by clearly setting the resolution of the resulting image to 72 dots per inch, which is strange, since other components expose 96dpi (for Win7). The correct display of hieroglyphs Kinsoku Shori pleased. Some letters look brighter than others, which suggests an impartial use of anti-aliasing. The result is good for those who do not care that not 100% managed code is used, but we go further.
A piece of code for ABCpdf:
Result:
It is easy to understand that the native Adobe library can not be no favorites. But calls to com objects are not exactly what we wanted, especially since you need an installed Pro version of the product.
A piece of code for Adobe:
Result: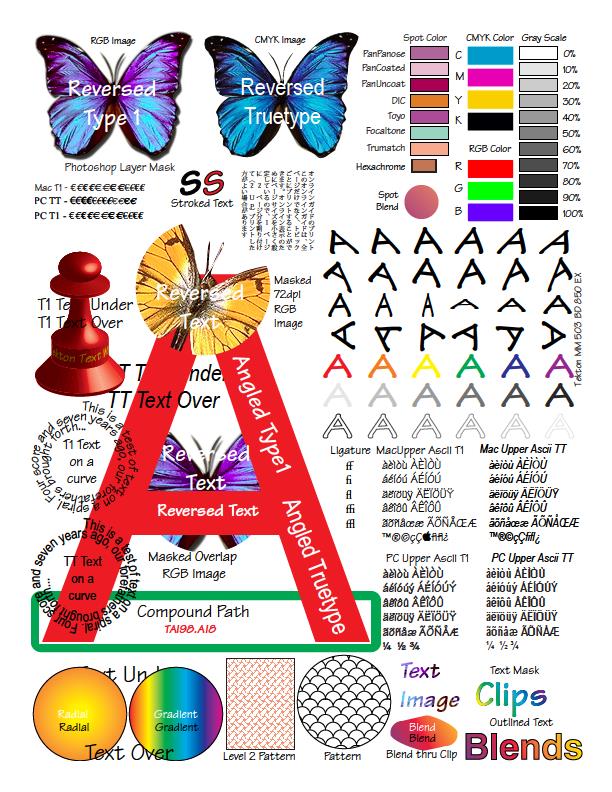
The component coped well with the test. Convenient API, it is possible to customize fonts and disable drawing annotations. The image looks clear. All elements of the original PDF document are drawn. I noticed that when converting the document all eight cores of the working machine were involved, most likely it would be convenient for those who want to increase application performance by increasing the RAM and the number of processors of the working system.
Apitron code snippet:
Result:
The Romanian component satisfactorily coped with the test. Not all elements of the document are saved correctly. As can be seen from the resulting file, all elements of the specification are supported. There are obvious problems with drawing text.
A piece of code for O2S:
Result:
The test case generation failed. The image looks blurry, the text is not readable. When converting the test file received errors.
Piece of code for PDFLibNET:
Result:
PDFSharp, like other wrappers of the well-known GhostScript tool (for example, gouda, GhostscriptSharp), works specifically and is not always predictable. Having spent several hours of time it turned out to make only the extraction of pictures, the entire document could not be saved as an image. I would mark it as a good idea for a new article.
You can also note here, everyone's favorite, iTextSharp. A handy tool, but not for our task.
In my review I also got a domestic component. But, unfortunately, with the tests he failed.
On the test file, he issued an NRE error. But on other files, he showed himself well.
(To the author: “Maxim, I’m sure that you have great software and this little thing will be quickly corrected.”)
A piece of code for SautinSoft:
The Dutch component coped well with the test. The complexity of a specific API was offset by basic knowledge of Graphics. Visible small problems with drawing text.
A piece of code for CallCamponents:
Result: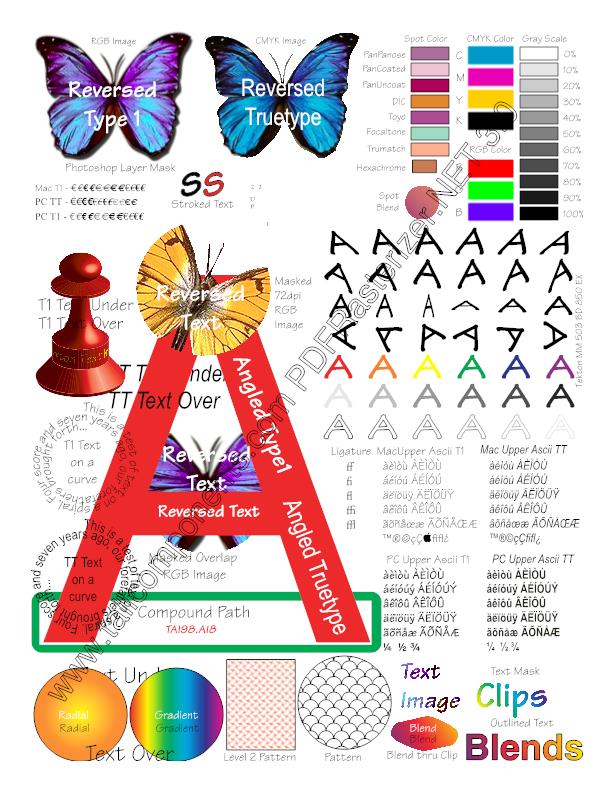
Saving PDF documents to a BMP, JPEG, TIFF image is not a trivial task, as it may seem at first glance. You can find a lot of software utilities, libraries and commercial services and their shareware versions, but in a small startup you cannot do without reliable components of third-party developers. After analyzing the results, re-reading the documentation, code samples and prices on the sites, I chose a component for my project. In terms of performance, all libraries are at the same level, possibly due to the specifics of reading a PDF document into one stream. When choosing, I did not consider the possibility of using products on mobile devices, since not all components, due to GDI + limitations, will be able to work correctly for the Android platform or are compatible with Mono.Xamarin.
Not so long ago, I came across a project whose customer wanted to convert his marketing masterpieces saved in PDF into one of the graphic formats, such as PNG. After much persuasion and counter-argument, the project budget allowed to buy an inexpensive .NET component.
It remained to choose the most suitable for the requirements of the customer and, if possible, with a good English-speaking, English writing support service (not from the Indian Subcontinent):
')
Requirements for PDF converters
The main attention was paid to such features of converters as:
- The simplicity of the API, including for setting up fonts (in addition to embedded fonts, it should be possible to add the missing system font or a link to it)
- Ability to export to TIFF, PNG, JPEG, BMP formats
- Support for transparent images inside a PDF document
- Color mask support
- Asian font support
- Annotations must be converted with the document (the ability to disable this option)
- Different blending modes
- Various tiling patterns
- Different color spaces RGB, CMYK, Gray, DeviceN
- Transparent groups for documents created using Adobe Illustrator
After several queries, the search engine issued a group of suitable .NET components:
| ABCpdf | 6.1.1.5 |
| Adobe Acrobat (Interop.Acrobat) | Adobe Acrobat 10.0 Type Library |
| Apitron.PDF.Rasterizer | 3.0.1.0 |
| O2S.Components.PDFRender4NET | 4.5.1.0 |
| PDFLibNET | |
| PDFSharp | 1.31.1789.0 |
| SautinSoft.PdfFocus | 2.2.2.2 |
| TallComponents.PDF.Rasterizer | 3.0.91.0 |
The beginning of the test
For testing purposes, a single-page PDF file was chosen 3BigPreview.pdf (taken from the official Adobe site). It includes a large number of graphic elements, demonstrating the ability of the component to render PDF graphic objects and their properties.
ABCPDF
It was not immediately possible to launch an example for this library on a 64-bit machine, only by changing the platform from AnyCPU to x86, the result was obtained. The problem arose with setting the correct resolution of the picture. A picture of the correct size of 612 x 792 pixels was obtained only by clearly setting the resolution of the resulting image to 72 dots per inch, which is strange, since other components expose 96dpi (for Win7). The correct display of hieroglyphs Kinsoku Shori pleased. Some letters look brighter than others, which suggests an impartial use of anti-aliasing. The result is good for those who do not care that not 100% managed code is used, but we go further.
A piece of code for ABCpdf:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Doc document = new Doc(); document.Read(fs); document.Rendering.DotsPerInch = 72; document.Rendering.DrawAnnotations = true; document.Rendering.AntiAliasImages = true; document.Rect.String = document.CropBox.String; document.Rendering.Save(Path.ChangeExtension(Path.Combine(imageOutputPath ,imageName), imageFormat.ToString())); } Result:
Adobe Acrobat 10.0 Type Library
It is easy to understand that the native Adobe library can not be no favorites. But calls to com objects are not exactly what we wanted, especially since you need an installed Pro version of the product.
A piece of code for Adobe:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { CAcroPDDoc pdfDoc = (CAcroPDDoc) Interaction.CreateObject("AcroExch.PDDoc", ""); pdfDoc.Open(pdfInputPath); CAcroPDPage pdfPage = (CAcroPDPage) pdfDoc.AcquirePage(0); CAcroPoint pdfPoint = (CAcroPoint) pdfPage.GetSize(); CAcroRect pdfRect = (CAcroRect) Interaction.CreateObject("AcroExch.Rect", ""); pdfRect.Left = pdfRect.Top = 0; pdfRect.right = pdfPoint.x; pdfRect.bottom = pdfPoint.y; pdfPage.CopyToClipboard(pdfRect, 0, 0, 100); IDataObject clipboardData = Clipboard.GetDataObject(); if (clipboardData.GetDataPresent(DataFormats.Bitmap)) { using(Bitmap pdfBitmap = (Bitmap) clipboardData.GetData(DataFormats.Bitmap)) { pdfBitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } } pdfDoc.Close(); Marshal.ReleaseComObject(pdfPage); Marshal.ReleaseComObject(pdfRect); Marshal.ReleaseComObject(pdfDoc); Marshal.ReleaseComObject(pdfPoint); } Result:
Apitron.PDF.Rasterizer for .NET
The component coped well with the test. Convenient API, it is possible to customize fonts and disable drawing annotations. The image looks clear. All elements of the original PDF document are drawn. I noticed that when converting the document all eight cores of the working machine were involved, most likely it would be convenient for those who want to increase application performance by increasing the RAM and the number of processors of the working system.
Apitron code snippet:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Document doc = new Apitron.PDF.Rasterizer.Document(fs); RenderingSettings option = new RenderingSettings(); option.DrawAnotations = true; doc.Pages[0].Render((int) doc.Pages[0].Width, (int) doc.Pages[0].Height, option).Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } Result:
O2S.Components.PDFRender4NET
The Romanian component satisfactorily coped with the test. Not all elements of the document are saved correctly. As can be seen from the resulting file, all elements of the specification are supported. There are obvious problems with drawing text.
A piece of code for O2S:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PDFFile pdfFile = O2S.Components.PDFRender4NET.PDFFile.Open(pdfInputPath); using (Bitmap pageImage = pdfFile.GetPageImage(0, 300)) { pageImage.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } } Result:
xPDF Wrapper Library (PDFLibNET)
The test case generation failed. The image looks blurry, the text is not readable. When converting the test file received errors.
Piece of code for PDFLibNET:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PDFWrapper pdfWrapper = new PDFWrapper(); pdfWrapper.LoadPDF(pdfInputPath); pdfWrapper.ExportJpg(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), 10); pdfWrapper.Dispose(); } Result:
PDFSharp (GhostScript and other wrappers)
PDFSharp, like other wrappers of the well-known GhostScript tool (for example, gouda, GhostscriptSharp), works specifically and is not always predictable. Having spent several hours of time it turned out to make only the extraction of pictures, the entire document could not be saved as an image. I would mark it as a good idea for a new article.
You can also note here, everyone's favorite, iTextSharp. A handy tool, but not for our task.
PdfFocus by SautinSoft
In my review I also got a domestic component. But, unfortunately, with the tests he failed.
On the test file, he issued an NRE error. But on other files, he showed himself well.
(To the author: “Maxim, I’m sure that you have great software and this little thing will be quickly corrected.”)
A piece of code for SautinSoft:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { PdfFocus pdfFocus = new PdfFocus(); pdfFocus.OpenPdf(pdfInputPath); pdfFocus.ImageOptions.Dpi = 96; pdfFocus.ImageOptions.ImageFormat = imageFormat; using (Image bitmap = pdfFocus.ToDrawingImage(1)) { bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } pdfFocus.ClosePdf(); } TallCompnents.PDF.Rasterizer
The Dutch component coped well with the test. The complexity of a specific API was offset by basic knowledge of Graphics. Visible small problems with drawing text.
A piece of code for CallCamponents:
public static void ConvertPDFToImage(string pdfInputPath, string imageOutputPath, string imageName, ImageFormat imageFormat) { FileStream fs = new FileStream(pdfInputPath, FileMode.Open); Document document = new Document(fs); Page page = document.Pages[0]; RenderSettings renderSettings = new RenderSettings(); renderSettings.GdiSettings.WorkAroundImageTransparencyPrintSize = true; using (Bitmap bitmap = new Bitmap((int) page.Width, (int) page.Height)) { using (Graphics graphics = Graphics.FromImage(bitmap)) { graphics.SmoothingMode = SmoothingMode.AntiAlias; graphics.CompositingQuality = CompositingQuality.HighQuality; graphics.Clear(Color.White); page.Draw(graphics, renderSettings); } bitmap.Save(Path.ChangeExtension(Path.Combine(imageOutputPath, imageName), imageFormat.ToString()), imageFormat); } } Result:
Total
Saving PDF documents to a BMP, JPEG, TIFF image is not a trivial task, as it may seem at first glance. You can find a lot of software utilities, libraries and commercial services and their shareware versions, but in a small startup you cannot do without reliable components of third-party developers. After analyzing the results, re-reading the documentation, code samples and prices on the sites, I chose a component for my project. In terms of performance, all libraries are at the same level, possibly due to the specifics of reading a PDF document into one stream. When choosing, I did not consider the possibility of using products on mobile devices, since not all components, due to GDI + limitations, will be able to work correctly for the Android platform or are compatible with Mono.Xamarin.
Source: https://habr.com/ru/post/182800/
All Articles