Deanonymization through genetic information
Brief essence:
Some time ago, databases with human genetic information (information of different levels of detail, from the complete sequences ( sequence ) of the entire genome to limited information on the short tandem repetitions of the Y chromosome ( Y-STRs ). For example, enthusiasts share information about their Y-STRs (haplotype) on genealogical sites for finding out relationships and searching for distant relatives, these data are not anonymous. Anonymous medical genetic information is also freely available, for example, from the research project “ 1000 human genomes ” (a project for the complete decoding of the genomes of thousands of different people), where the anonymity of DNA donors is maintained for ethical reasons.
This is where the fun begins. Genealogical databases (even very poorly populated, but nonetheless) allow to de-anonymize people. For example, it is shown that in the case of artificial insemination with sperm from an anonymous donor, the use of genealogical databases allows you to find out at least the name of the child’s real biological father (that is, through very distant relatives lit up in the database, and from which family the donor was) in the presence of additional information, such as place of residence, etc., allows you to uniquely identify the biological father. Recently it has been shown that anonymous genetic data in the public domain, plus additional information about age, etc., can accurately identify approximately 50 anonymous DNA donors from the 1000 Human Genomes project. This is a very alarming achievement, since the complete genetic information of these people, which is in the public domain, contains data on their susceptibility to certain diseases, etc., it can be self-interestedly used by insurance companies and similar organizations.

')
If you are interested in details and details, welcome under cat.
Some time ago, a theory was advanced that for accurate identification of a person in the modern world, 33 bits of information is sufficient. By combining various information known about a person, we reduce the informational entropy, narrowing the circle of possible options, and, eventually, accurately identifying the person. It is absolutely obvious that information about people that is publicly available - profiles of social networks, data provided when registering on numerous web services, etc., can directly help in deanonymization of a person registered in social. networks and other sites that collect information about users. It is less obvious that data mining can reliably provide a lot of information about a person who is not directly listed in his profile, based only on very indirect information, for example, on Facebook likes: www.pnas.org/content/110 / 15/5802 . The authors of this work can correctly distinguish the Republican from the Democrat in 85% of cases, and the black American from the white - in 95% of cases. However, there is another source of information about people that is not obvious to most IT people - open databases of genetic information. Their charm lies in the fact that the person himself does not have to leave his genetic information in the public domain to be identified - his child’s genetic information is enough to determine through very distant relatives (separated even 8 or more generations ago) in the database at least the family from which the father comes (and if there is additional information - to find the father himself). If your genetic information is publicly available, even if anonymously, the chance of authentic identification of your identity is quite high.
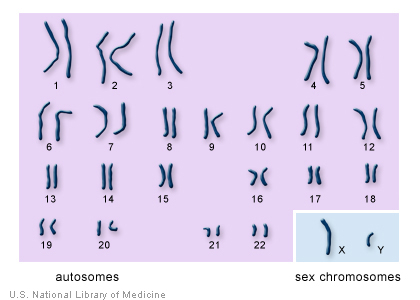
We all remember from school that in every cell of our body there is DNA in which our genetic information is encoded. In total, there are 46 pairs of chromosomes in the cells of the human body, and more specifically - 23 pairs of chromosomes, and from each of the parents we get one 23 chromosome set. On the one hand, the genetic information of different people is quite similar: for example, if we take only the protein-coding regions of human DNA, their similarity even to the protein-coding regions of chimpanzee DNA is approximately 99%, that is, in humans, they are even more similar . On the other hand, there are many areas in DNA that are not very genetically stable, for example, the so-called short tandem repeats ( STRs ). These are DNA segments in which a short sequence 2-4 nucleotides in length is repeated more than 10 (up to one hundred) times. Such areas are not very convenient for copying, and cellular machinery for DNA copying often sculpts errors on these repetitions. As a result, even the next of kin have very similar, but nonetheless slightly different DNA sequences in these repeats. The further the relationship is, the more differences accumulate, and it can even be assumed by the number of differences how many generations ago there was a separation between these branches of the family. One more detail is interesting. Among the 23 pairs of chromosomes there is a special pair - the so-called sex chromosomes, XX in a woman and XY in a man. Here inheritance works as follows - since the female has the genotype XX, the female egg always carries the X chromosome. The sperm cell can carry either the X or Y chromosome, since in men the XY genotype. Thus, the sex of the child is always determined by the sperm and there is another interesting property - the Y chromosome is always inherited through the male line, from grandfather to father, from father to son, etc. (The X chromosome of the same man comes from the mother and can be inherited as from grandmother by father, and from grandmother by mother, statistically with a probability of 50%). Since the surname is usually inherited from our father, short tandem repeats that are on the Y chromosome ( en.wikipedia.org/wiki/Y-STR ), inherited only from father to son, can be used to establish the surname of a person. Although, in principle, STRs from any chromosome can be used to assess the degree of kinship, the Y chromosome, due to the nature of its inheritance, makes it possible to clearly outline the inheritance along the male line.
Now let's talk about the level of detail available genetic information. Of course, the most complete genetic information is the complete sequence ( sequence ) of the entire genome . The first project “Human Genome” was 13 years old, the project budget was approximately 3 billion (!) Dollars. However, in the course of this work, technologies were developed and brought to mind, which a little later allowed us to sequence one person’s genome in 2 months and a million dollars . Although in recent years, the cost of sequencing continues to plummet and has not yet reached the bottom (the most important task has been set to achieve a cost of $ 1,000 per genome), however, it is still expensive, inaccessible to ordinary people. But the project " 1000 human genomes" was launched. His goal is to collect a fairly complete catalog of genetic differences between people, for this purpose, anonymous DNA samples were taken from people of different races, from different countries to get the greatest variety of genomes within this thousand. At the moment, the main part of sequencing is completed and anonymous genomic sequences are freely available: www.1000genomes.org/home , so that scientists can calmly analyze and compare them (that's where a lot of work for data mining!). Even now one can say a lot about the person in full sequence - determine his predisposition to many diseases, such as cancer or Alzheimer's disease, reliably determine his race, in many cases reliably determine eye color and so on - even a correlation has been recently found genetic markers and level of education .
Less informative, but much cheaper and faster are hybridization methods, for example, hybridization on a chip . In this case, we do not determine the complete sequence of the entire genome, but ask - which of the known possible variants is present in this particular genome? There is such a scary word SNP - single nucleotide polymorphism , one of the goals of the project “1000 human genomes” is precisely to search for and characterize such single nucleotide polymorphisms (when the DNA sequence of two people differs in some place by one nucleotide). Many of the SNPs are genetic markers of susceptibility to cancer and other diseases, so for medical purposes it is not necessary to sequence the entire genome — it is enough to drive out hybridization on a chip, see which SNPs that are known to be markers of certain diseases, are present in the patient and make conclusion about its susceptibility to these diseases. SNP databases are also publicly available .
Even less informative, but sufficient to identify a person, is information about his haplotype - the features of his short tandem repeats (STRs), which we have already mentioned above. Technically, the STRs profile can be obtained very cheaply in less than half a day using PCR , or the hybridization method on the chip can be used again. Although the haplotype hardly helps with medical diagnostics, it makes it possible to identify a person that has been used for a long time in forensic science, and all advanced countries - the United States , Britain and, including, our Motherland , have already attended to the compilation of genetic databases for the identification of criminals. These databases, as I understand it, are closed and not accessible to the general public. It should be noted that the less complete information can be reconstructed using more complete information, that is, the STR profiles can be easily calculated using the full genomic sequence, a similar operation is theoretically possible for polymorphism data (SNP).
We turn to the most interesting. As we have said, the inheritance of the Y chromosome goes strictly from father to son, which means that the data on Y-STR ( haplotype ) allow us to track the paternal line of inheritance. Currently, at least 8 genealogical databases are available on the Web, containing a total of hundreds of thousands of records matching the haplotype with the person’s last name. The largest open access databases with search capabilities are Ysearch ( www.ysearch.org ) and SMGF ( www.smgf.org ). The idea of these bases is to search for your distant relatives and dig in your own family tree - for this you make your haplotype searchable in the hope that distant relatives will someday be found, plus you are looking for similar (related) ones already existing in the haplotype database. To determine the haplotype, you need to send your DNA sample for analysis to one of these companies. It should be noted that, basically, these bases cover the population of the United States and Western countries, so everything that will be discussed below about personal identification will be fairly true for the West. For example, in Ysearch there were as many as 11 people with the surname “Ivanov”, one from Bulgaria, two Russians, the rest with a “dual” origin of Russia-USA, or the origin is not indicated. People with the name "Johns" (probably the closest English version of Ivanov) there are 30 pieces - 3 times more.
What can be done with these databases now? With low occupancy - hundreds of thousands of records, the available data already allow you to determine membership of a family for millions (perhaps tens of millions) of people, which is already a significant percentage for the same US population (population ~ 300 million). The method is sensitive enough to pull out relatives from family lines that have been divided more than 8 generations ago, and the bases are constantly growing, increasing coverage. Now the era of genomic anonymity (for example, in the case of anonymous donation of sperm) comes to an end. Increasingly, sentimental stories like this appear in the press. In this case, the woman underwent artificial insemination at a medical facility using sperm from an anonymous donor and gave birth to a wonderful girl with some mental disabilities. Although the institution signed a non-disclosure obligation on the donor and strictly adhered to this agreement, the donor did not save the de-anonymization. Mummy primarily using genetic bases was able to find several other children born from the same anonymous donor - there is even a special base aimed at reuniting brothers and sisters in a father-anonymous sperm donor - www.donorsiblingregistry.com . It turned out that many of the children (and there were already 13 of them) have autism and other deviations. Our heroine was very interested and she persuaded another woman who had given birth to a boy from the same donor father to take her son’s genetic material for analysis through the Y-STRs database. As a result, the bases found two families of very distant relatives of the donor, but using the additional information that the donor discovered about himself (he allowed to give women minimal information about himself - his education, his mother's profession and that his father was a famous baseball player), he was clearly identified - he had to take guests and get acquainted with his daughter and her mom.
Another story - if in short, on his deathbed, the old man told his son that in fact he was not his own, but an adoptee. The old man died, and his son had an idea-fix to find his real father. The details are similar to the previous case - the base of Y-STRs, a lead through a distant relative, promotion with the involvement of additional information about the place of residence, etc., as a result, the biological father was found, though it turned out that he, too, had already died. But the father brothers are alive and now the happy man regularly visits them to listen to stories about his biological daddy. And such stories will be more and more as you fill the bases.
There is another side to this medal. As we have already discussed above, now on the Web, the full genetic sequences of anonymous DNA donors, for example, from the project “1000 Human Genomes”, are in open access. In addition to the actual complete sequence of genomes, a certain minimum of information about donors is available - age, geographical location, and so on. The identities of these people must remain secret for ethical reasons - they donated DNA in the name of science so that genetic differences between people can be analyzed as accurately as possible, but their DNA also contains sensitive information - their susceptibility to diseases, for example. I would not want this information to be known to insurance companies (in America with insurance medicine you will not be fooled). However, in the complete sequence of the genome, you can safely count Y-STRs, and then ... Well, you understand. The base, the search for distant relatives, the attraction of additional information to clarify - and an article in Science about de-anonymization of at least 50 people out of 1000. Ethical committees sigh heavily, the guys from the project “1000 human genomes” urgently remove from all records information about age to make accurate identification of the person is impossible (the circle of search without it is narrowed down to several (dozens) people, but more precisely it will not work), and the rest recall the story of a simple African American, Henrietta Lax .
Her story is sad and somewhat surreal. She died of cervical cancer at the age of 31 in 1951, living an unremarkable life (perhaps the most outstanding thing she did - gave birth to a child at 14), but today every molecular biologist knows at least the first two letters of her name and last names - HeLa . This is the name of the most famous cancer cell line used today for experiments in most laboratories working in the field of cancer research and not only. The point is that when the doctor took Henriette Lax's cancer cells for analysis, he noticed that they quickly divided and were relatively easy to cultivate. Many cancer cell lines are unstable, the same line was very stable, for which she fell in love. Henrietta herself died more than 60 years ago, but the cancer that killed her is still alive in hundreds of laboratories. Since cancer cells are human cells of their own, in which the control of cell divisions has broken, it can be said that Henrietta herself, in a sense, is still alive in the form of his cancer. Now she is immortal, lives in laboratories and multiplies and breeds in a nutrient medium ... A story worthy of Stephen King. Of course, when the sequencing technologies were brought to a modern level, the complete genomic sequence of the HeLa cancer line was determined and, of course, laid out in open access. The European Laboratory of Molecular Biology (EMBL, Germany), which carried out the project, stated that the publication of the complete genomic sequence of the HeLa line does not reveal any information about Henrietta Lax herself and her relatives and descendants, but we all know that all markers of susceptibility to diseases are in full Sequence - as in the palm of your hand, and American insurers are already looking over their shoulders. After numerous raids, EMBL recognized that publishing a genomic sequence violates the privacy of Henrietta's relatives and removed it from free access.
To summarize Databases have appeared on the Web to search for distant relatives and genealogy games on genetic information (alas, in order to fully use the search, you will have to send them a sample of their genetic information for analysis - usually it is scraped from the inside of the cheek, from which they will extract DNA). These bases can be effectively used not only to search for your lost four cousins and sisters, but also to accurately identify the sperm donor in case of artificial insemination (an anonymous donor, forget about anonymity) or biological parents in case of adoption. Now the databases contain hundreds of thousands of records that will allow tens of millions of people to be pulled out through distant kinship (if there is additional information for accurate identification). This figure will only grow with an increase in the number of records in the databases. It also raises the question of de-anonymization through anonymous genetic information used in biological and medical research. So, if you inadvertently left someone your genetic information in the form of a child, they might come to you and say, “Hello, Dad!”, And if you participated in anonymous medical genetic research, don’t be surprised if the insurers become Break the big money for your health insurance, since you have a marker of predisposition to skin cancer or something similar.
On this optimistic note, allow me to bow out - be healthy, do not be ill, and be more careful about your genetic information.
Some time ago, databases with human genetic information (information of different levels of detail, from the complete sequences ( sequence ) of the entire genome to limited information on the short tandem repetitions of the Y chromosome ( Y-STRs ). For example, enthusiasts share information about their Y-STRs (haplotype) on genealogical sites for finding out relationships and searching for distant relatives, these data are not anonymous. Anonymous medical genetic information is also freely available, for example, from the research project “ 1000 human genomes ” (a project for the complete decoding of the genomes of thousands of different people), where the anonymity of DNA donors is maintained for ethical reasons.
This is where the fun begins. Genealogical databases (even very poorly populated, but nonetheless) allow to de-anonymize people. For example, it is shown that in the case of artificial insemination with sperm from an anonymous donor, the use of genealogical databases allows you to find out at least the name of the child’s real biological father (that is, through very distant relatives lit up in the database, and from which family the donor was) in the presence of additional information, such as place of residence, etc., allows you to uniquely identify the biological father. Recently it has been shown that anonymous genetic data in the public domain, plus additional information about age, etc., can accurately identify approximately 50 anonymous DNA donors from the 1000 Human Genomes project. This is a very alarming achievement, since the complete genetic information of these people, which is in the public domain, contains data on their susceptibility to certain diseases, etc., it can be self-interestedly used by insurance companies and similar organizations.
')
If you are interested in details and details, welcome under cat.
Introduction
Some time ago, a theory was advanced that for accurate identification of a person in the modern world, 33 bits of information is sufficient. By combining various information known about a person, we reduce the informational entropy, narrowing the circle of possible options, and, eventually, accurately identifying the person. It is absolutely obvious that information about people that is publicly available - profiles of social networks, data provided when registering on numerous web services, etc., can directly help in deanonymization of a person registered in social. networks and other sites that collect information about users. It is less obvious that data mining can reliably provide a lot of information about a person who is not directly listed in his profile, based only on very indirect information, for example, on Facebook likes: www.pnas.org/content/110 / 15/5802 . The authors of this work can correctly distinguish the Republican from the Democrat in 85% of cases, and the black American from the white - in 95% of cases. However, there is another source of information about people that is not obvious to most IT people - open databases of genetic information. Their charm lies in the fact that the person himself does not have to leave his genetic information in the public domain to be identified - his child’s genetic information is enough to determine through very distant relatives (separated even 8 or more generations ago) in the database at least the family from which the father comes (and if there is additional information - to find the father himself). If your genetic information is publicly available, even if anonymously, the chance of authentic identification of your identity is quite high.
Little genetics
We all remember from school that in every cell of our body there is DNA in which our genetic information is encoded. In total, there are 46 pairs of chromosomes in the cells of the human body, and more specifically - 23 pairs of chromosomes, and from each of the parents we get one 23 chromosome set. On the one hand, the genetic information of different people is quite similar: for example, if we take only the protein-coding regions of human DNA, their similarity even to the protein-coding regions of chimpanzee DNA is approximately 99%, that is, in humans, they are even more similar . On the other hand, there are many areas in DNA that are not very genetically stable, for example, the so-called short tandem repeats ( STRs ). These are DNA segments in which a short sequence 2-4 nucleotides in length is repeated more than 10 (up to one hundred) times. Such areas are not very convenient for copying, and cellular machinery for DNA copying often sculpts errors on these repetitions. As a result, even the next of kin have very similar, but nonetheless slightly different DNA sequences in these repeats. The further the relationship is, the more differences accumulate, and it can even be assumed by the number of differences how many generations ago there was a separation between these branches of the family. One more detail is interesting. Among the 23 pairs of chromosomes there is a special pair - the so-called sex chromosomes, XX in a woman and XY in a man. Here inheritance works as follows - since the female has the genotype XX, the female egg always carries the X chromosome. The sperm cell can carry either the X or Y chromosome, since in men the XY genotype. Thus, the sex of the child is always determined by the sperm and there is another interesting property - the Y chromosome is always inherited through the male line, from grandfather to father, from father to son, etc. (The X chromosome of the same man comes from the mother and can be inherited as from grandmother by father, and from grandmother by mother, statistically with a probability of 50%). Since the surname is usually inherited from our father, short tandem repeats that are on the Y chromosome ( en.wikipedia.org/wiki/Y-STR ), inherited only from father to son, can be used to establish the surname of a person. Although, in principle, STRs from any chromosome can be used to assess the degree of kinship, the Y chromosome, due to the nature of its inheritance, makes it possible to clearly outline the inheritance along the male line.
Technical Details: Different Levels of Genetic Information Details
Now let's talk about the level of detail available genetic information. Of course, the most complete genetic information is the complete sequence ( sequence ) of the entire genome . The first project “Human Genome” was 13 years old, the project budget was approximately 3 billion (!) Dollars. However, in the course of this work, technologies were developed and brought to mind, which a little later allowed us to sequence one person’s genome in 2 months and a million dollars . Although in recent years, the cost of sequencing continues to plummet and has not yet reached the bottom (the most important task has been set to achieve a cost of $ 1,000 per genome), however, it is still expensive, inaccessible to ordinary people. But the project " 1000 human genomes" was launched. His goal is to collect a fairly complete catalog of genetic differences between people, for this purpose, anonymous DNA samples were taken from people of different races, from different countries to get the greatest variety of genomes within this thousand. At the moment, the main part of sequencing is completed and anonymous genomic sequences are freely available: www.1000genomes.org/home , so that scientists can calmly analyze and compare them (that's where a lot of work for data mining!). Even now one can say a lot about the person in full sequence - determine his predisposition to many diseases, such as cancer or Alzheimer's disease, reliably determine his race, in many cases reliably determine eye color and so on - even a correlation has been recently found genetic markers and level of education .
Less informative, but much cheaper and faster are hybridization methods, for example, hybridization on a chip . In this case, we do not determine the complete sequence of the entire genome, but ask - which of the known possible variants is present in this particular genome? There is such a scary word SNP - single nucleotide polymorphism , one of the goals of the project “1000 human genomes” is precisely to search for and characterize such single nucleotide polymorphisms (when the DNA sequence of two people differs in some place by one nucleotide). Many of the SNPs are genetic markers of susceptibility to cancer and other diseases, so for medical purposes it is not necessary to sequence the entire genome — it is enough to drive out hybridization on a chip, see which SNPs that are known to be markers of certain diseases, are present in the patient and make conclusion about its susceptibility to these diseases. SNP databases are also publicly available .
Even less informative, but sufficient to identify a person, is information about his haplotype - the features of his short tandem repeats (STRs), which we have already mentioned above. Technically, the STRs profile can be obtained very cheaply in less than half a day using PCR , or the hybridization method on the chip can be used again. Although the haplotype hardly helps with medical diagnostics, it makes it possible to identify a person that has been used for a long time in forensic science, and all advanced countries - the United States , Britain and, including, our Motherland , have already attended to the compilation of genetic databases for the identification of criminals. These databases, as I understand it, are closed and not accessible to the general public. It should be noted that the less complete information can be reconstructed using more complete information, that is, the STR profiles can be easily calculated using the full genomic sequence, a similar operation is theoretically possible for polymorphism data (SNP).
Luke, who is your father?
We turn to the most interesting. As we have said, the inheritance of the Y chromosome goes strictly from father to son, which means that the data on Y-STR ( haplotype ) allow us to track the paternal line of inheritance. Currently, at least 8 genealogical databases are available on the Web, containing a total of hundreds of thousands of records matching the haplotype with the person’s last name. The largest open access databases with search capabilities are Ysearch ( www.ysearch.org ) and SMGF ( www.smgf.org ). The idea of these bases is to search for your distant relatives and dig in your own family tree - for this you make your haplotype searchable in the hope that distant relatives will someday be found, plus you are looking for similar (related) ones already existing in the haplotype database. To determine the haplotype, you need to send your DNA sample for analysis to one of these companies. It should be noted that, basically, these bases cover the population of the United States and Western countries, so everything that will be discussed below about personal identification will be fairly true for the West. For example, in Ysearch there were as many as 11 people with the surname “Ivanov”, one from Bulgaria, two Russians, the rest with a “dual” origin of Russia-USA, or the origin is not indicated. People with the name "Johns" (probably the closest English version of Ivanov) there are 30 pieces - 3 times more.
What can be done with these databases now? With low occupancy - hundreds of thousands of records, the available data already allow you to determine membership of a family for millions (perhaps tens of millions) of people, which is already a significant percentage for the same US population (population ~ 300 million). The method is sensitive enough to pull out relatives from family lines that have been divided more than 8 generations ago, and the bases are constantly growing, increasing coverage. Now the era of genomic anonymity (for example, in the case of anonymous donation of sperm) comes to an end. Increasingly, sentimental stories like this appear in the press. In this case, the woman underwent artificial insemination at a medical facility using sperm from an anonymous donor and gave birth to a wonderful girl with some mental disabilities. Although the institution signed a non-disclosure obligation on the donor and strictly adhered to this agreement, the donor did not save the de-anonymization. Mummy primarily using genetic bases was able to find several other children born from the same anonymous donor - there is even a special base aimed at reuniting brothers and sisters in a father-anonymous sperm donor - www.donorsiblingregistry.com . It turned out that many of the children (and there were already 13 of them) have autism and other deviations. Our heroine was very interested and she persuaded another woman who had given birth to a boy from the same donor father to take her son’s genetic material for analysis through the Y-STRs database. As a result, the bases found two families of very distant relatives of the donor, but using the additional information that the donor discovered about himself (he allowed to give women minimal information about himself - his education, his mother's profession and that his father was a famous baseball player), he was clearly identified - he had to take guests and get acquainted with his daughter and her mom.
Another story - if in short, on his deathbed, the old man told his son that in fact he was not his own, but an adoptee. The old man died, and his son had an idea-fix to find his real father. The details are similar to the previous case - the base of Y-STRs, a lead through a distant relative, promotion with the involvement of additional information about the place of residence, etc., as a result, the biological father was found, though it turned out that he, too, had already died. But the father brothers are alive and now the happy man regularly visits them to listen to stories about his biological daddy. And such stories will be more and more as you fill the bases.
Use of anonymous genetic information
There is another side to this medal. As we have already discussed above, now on the Web, the full genetic sequences of anonymous DNA donors, for example, from the project “1000 Human Genomes”, are in open access. In addition to the actual complete sequence of genomes, a certain minimum of information about donors is available - age, geographical location, and so on. The identities of these people must remain secret for ethical reasons - they donated DNA in the name of science so that genetic differences between people can be analyzed as accurately as possible, but their DNA also contains sensitive information - their susceptibility to diseases, for example. I would not want this information to be known to insurance companies (in America with insurance medicine you will not be fooled). However, in the complete sequence of the genome, you can safely count Y-STRs, and then ... Well, you understand. The base, the search for distant relatives, the attraction of additional information to clarify - and an article in Science about de-anonymization of at least 50 people out of 1000. Ethical committees sigh heavily, the guys from the project “1000 human genomes” urgently remove from all records information about age to make accurate identification of the person is impossible (the circle of search without it is narrowed down to several (dozens) people, but more precisely it will not work), and the rest recall the story of a simple African American, Henrietta Lax .
Her story is sad and somewhat surreal. She died of cervical cancer at the age of 31 in 1951, living an unremarkable life (perhaps the most outstanding thing she did - gave birth to a child at 14), but today every molecular biologist knows at least the first two letters of her name and last names - HeLa . This is the name of the most famous cancer cell line used today for experiments in most laboratories working in the field of cancer research and not only. The point is that when the doctor took Henriette Lax's cancer cells for analysis, he noticed that they quickly divided and were relatively easy to cultivate. Many cancer cell lines are unstable, the same line was very stable, for which she fell in love. Henrietta herself died more than 60 years ago, but the cancer that killed her is still alive in hundreds of laboratories. Since cancer cells are human cells of their own, in which the control of cell divisions has broken, it can be said that Henrietta herself, in a sense, is still alive in the form of his cancer. Now she is immortal, lives in laboratories and multiplies and breeds in a nutrient medium ... A story worthy of Stephen King. Of course, when the sequencing technologies were brought to a modern level, the complete genomic sequence of the HeLa cancer line was determined and, of course, laid out in open access. The European Laboratory of Molecular Biology (EMBL, Germany), which carried out the project, stated that the publication of the complete genomic sequence of the HeLa line does not reveal any information about Henrietta Lax herself and her relatives and descendants, but we all know that all markers of susceptibility to diseases are in full Sequence - as in the palm of your hand, and American insurers are already looking over their shoulders. After numerous raids, EMBL recognized that publishing a genomic sequence violates the privacy of Henrietta's relatives and removed it from free access.
Finita la commedia
To summarize Databases have appeared on the Web to search for distant relatives and genealogy games on genetic information (alas, in order to fully use the search, you will have to send them a sample of their genetic information for analysis - usually it is scraped from the inside of the cheek, from which they will extract DNA). These bases can be effectively used not only to search for your lost four cousins and sisters, but also to accurately identify the sperm donor in case of artificial insemination (an anonymous donor, forget about anonymity) or biological parents in case of adoption. Now the databases contain hundreds of thousands of records that will allow tens of millions of people to be pulled out through distant kinship (if there is additional information for accurate identification). This figure will only grow with an increase in the number of records in the databases. It also raises the question of de-anonymization through anonymous genetic information used in biological and medical research. So, if you inadvertently left someone your genetic information in the form of a child, they might come to you and say, “Hello, Dad!”, And if you participated in anonymous medical genetic research, don’t be surprised if the insurers become Break the big money for your health insurance, since you have a marker of predisposition to skin cancer or something similar.
On this optimistic note, allow me to bow out - be healthy, do not be ill, and be more careful about your genetic information.
Source: https://habr.com/ru/post/182716/
All Articles