Microsoft Dryad vs Apache Hadoop. Uncomplicated Big Data Battle
Last week, 2 posts about the Microsoft Research - Dryad framework of distributed computing appeared on Habré. In particular, the concepts and architecture of the key components of Dryad — the Dryad execution environment and the DryadLINQ query language — were described in detail.
The logical conclusion of the cycle of articles about Dryad seems to be a comparison of the Dryad framework with other tools MPP-applications familiar to developers: relational DBMS (including parallel ones), GPU computing and the Hadoop platform .

')
I do not suggest , nor do I discourage the use of Dryad in my research projects (since only an academic license is now available).
Dryad is an “internal” product to all of us known
The fact that Dryad is proprietary software is not (I speak for myself) studying the principles and architecture of this platform less interesting or useful for professional development (again for myself). If you have something different, then
In the first part, using Dryad as an example, a general review will be made of the advantages of distributed computing frameworks, which provide developers with high-level abstractions, over lower-level computation parallelization tools - MPI and GPU calculations.
Such a comparison in isolation from the context (ie, a specific task) is incorrect, but it is acceptable for our purpose - to show cases of the appropriate use of distributed application execution frameworks.
The second part will be compared with RDBMS and parallel DBMS. Of course, the publication volume does not allow comparing Dryad separately with MySQL and separately with SQL Server 2012 Parallel Data Warehouse (and why?). Therefore, the “average hospital temperature” of the DBMS is taken for analysis: let's discuss the common problems of solutions based on relational databases and consider Dryad as a continuation of the best ideas of the DBMS world.
In the final part, a comparison will be made with the Hadoop software platform (the latter can either not know or admire).
Hadoop has 2 big advantages (of course, more) - a new framework (about it later), providing an API for implementing your own distributed algorithms, and a rich ecosystem . Paradoxically, these are the main drawbacks of Hadoop: a new beta framework (the start of development is 2008), and without installing many components from the Hadoop ecosystem (installation, training, support), using Hadoop in the enterprise segment is not a trivial task.
Therefore, comparing Dryad comes with the release branch of plain Hadoop and an endless look at the opportunities provided by the Hadoop ecosystem, and how this problem (if any) will be solved in Hadoop v2.0.
1. Dryad vs GPU. Dryad vs mpi
Taking into account the availability of the academic license of Dryad, I became interested in the possibility of using the Dryad framework in calculations for research (I am a graduate student). But historically, in an academic environment (my university, for sure), the main platforms for “scientific computing” are MPI (Message Passing Interface) and GPU computing.
Unlike MPI, the Dryad platform is based on a shared-nothing architecture that does not have shared (different processes) data and, as a result, does not need to use synchronization primitives . This makes the Dryad cluster not only potentially more scalable, but also more time-efficient for solving problems that use data-parallel algorithms.
In addition, infrastructure tasks such as monitoring execution, handling failures are usually the responsibility of the MPI developer , while in Dryad the listed tasks are the responsibility of the framework.
Speaking of GPU computing, it is worth noting that, unlike Dryad, development under GPU is quite strongly related to the hardware level at which the application is launched. NVidia and AMD provide their own SDK for development for their graphics cards (CUDA and APP, respectively). Obviously, these are various incompatible development platforms.
Corporation of evil Microsoft attempted to unify the development process for the GPU, releasing C ++ AMP. But this fact is too much proof that when developing for a GPU, the developer must “look back” at the hardware of the graphics adapter. Moreover, the “roots” of the hardware level penetrate the code so deeply that it may be difficult to launch the application even when changing the model of a graphics card, not to mention changing the vendor. Naturally, this creates additional difficulties both when debugging and when migrating to a more productive / suitable for a specific task hardware platform.
All this, ultimately, forces the researcher to address infrastructure issues related to hardware, debugging, deployment, and support, instead of solving applied issues in the subject area of the study.
The Dryad framework, unlike the GPU, hides the hardware level from the developers of distributed applications, although it does have quite specific hardware platform requirements for running a distributed application (the requirements were discussed in the first article of the cycle).
2. Dryad vs Parallel DB
The main fundamental difference between Dryad and a DBMS is the absence of strong connectivity between the storage layers, the execution layer and the Dryad program model , and the presence of such connectivity for the DBMS. This distinction is demonstrated on
illustration in the introduction.
Nevertheless, Dryad "absorbed" many of the ideas of the world, both traditional and parallel DBMS.
So, like many parallel DBMSs (Teradata, IBM DB2 Parallel Edition), Dryad uses a shared-nothing architecture, sharding (horizontal partitioning), dynamic repartitioning, partitioning strategies: hash-partitioning, range partitioning and round-robin.
From the world of traditional DBMS , the concepts of query optimizer and execution plan were taken. These concepts were extremely transformed: the result of the work of the DryadLINQ scheduler is the execution graph (EPG, Execution Plan Graph), which is dynamically changed based on policies and collected during the execution of statistics.
Like all DBMSs, Dryad uses a data query language. In Dryad, the DryadLINQ programming model plays the role of a query language. But unlike SQL, DryadLINQ:
+ was originally designed to work with data structures and complex types ;
+ is a high-level abstraction that does not associate the application level with the level
storage;
+ has native support for common programming patterns , such as iterations;
- does not support transactions and update operations.
In addition, SQL is not fundamentally suitable for describing machine learning algorithms, parsing sequences of facts (logs, genomic databases), graph analysis. Also, Dryad is ineffective for solving problems based on algorithms that require random-access data access.
Below is a table comparing solutions based on relational database management systems and based on distributed computing frameworks.
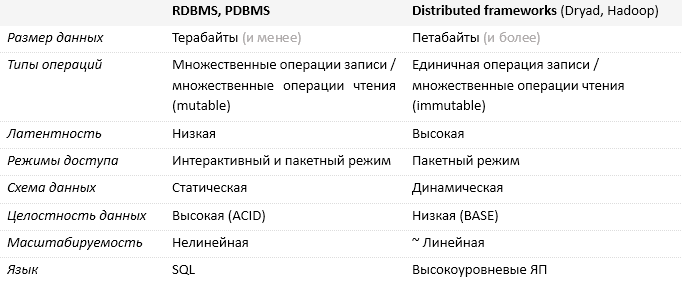
In the conclusion of the comparison, I note: the greatest obstacle to the wide distribution of solutions based on parallel DBMS is the cost of the solution, which, in general, amounts to hundreds of thousands of dollars. How much would cost a solution based on the Dryad-cluster can only be assumed; in my opinion, we are talking about the amount much lower.
3. Dryad vs Hadoop
The map / reduce paradigm is an extremely elegant way of describing data parallel algorithms. The emergence of Hadoop, which provided the execution infrastructure and software model for writing map / reduce-applications, was a revolutionary leap in solving Big Data problems.

* Directed Acyclic Graph (English Directed Acyclic Graph).
** Only beta version is available (as of June 2013).
*** Any CLS-compatible PL with static typing.
**** Infrastructure for deploying Hadoop cluster and executing Hadoop tasks.
***** Only available when installing third-party components of the Hadoop ecosystem.
3.1. Hadoop
The ideologists and developers of Hadoop, discarding everything superfluous, made a simple, understandable to the maximum circle of developers, an extremely effective and equally limited platform for developing MPP applications.
Hadoop is perfect for map / reduce and so far does not stand up to scrutiny when developing for other distributed algorithms (waiting for YARN). Hence, a huge number of Hadoop support tools, based both on the Hadoop MapReduce computing framework (such as, Pig), and representing separate computing frameworks (Hive, Storm, Apache Giraph). And all these tools provide often duplicate solutions for problems of a narrow nature (in fact, bypassing restrictions) instead of providing a single universal tool for solving both log parsing and PageRank counting and graph analysis.
Naturally, installing, configuring and maintaining the entire Hadoop ecosystem that is necessary for solving everyday analytics tasks are considerable time and, as a result, financial costs that go to solving infrastructure problems, not business and / or researcher tasks . As a partial solution to this problem, distributors of the Hadoop platform appeared in assembled form (the largest of them are Cloudera and Hortonworks). But this is still not a solution to the problem - this is another confirmation of its presence.
An evolutionary leap will be (for the time being in the future tense) a software framework YARN , providing developers with the components and API needed to develop distributed algorithms other than map / reduce. YARN also solves many of the problems of Hadoop v1.0, including low resource utilization and scalability threshold, which are now at ~ 4K compute nodes (while Dryad already worked on 10K nodes in 2011).
As of May 2013, YARN is not yet in the release version. Considering the “slowness” of the Apache community, it is necessary to take into account the high probability that the time interval between the release of the release version of YARN and the release versions of distributed algorithms other than map / reduce, written using the YARN API, may be years.
3.2. Dryad
The Dryad framework initially allowed developers to implement arbitrary distributed algorithms. Thus, the Hadoop MapReduce (v1.0) software model is only a special case of the more general Dryad software model .
We will not delve into the problems of Hadoop with Join operations, the efficiency of calculating PageRank, other limitations of the Hadoop platform, and ways to solve them, as this is clearly beyond the scope of the article. Instead, we will discuss the possibilities of the Dryad framework, which have no analogues in the Hadoop platform.
Dryad has an impressive list of tools for planning the execution of a distributed application , described in previous articles of the cycle. So there is a parallel compiler that converts expressions written in DryadLINQ into an execution graph - EPG. The EPG passes the optimization stage both before execution ( static optimizer ) and during execution ( dynamic optimization based on policies and statistics collected during execution).
The parallel compiler, the execution graph and the static / dynamic graph optimization feature make the planning / execution of a distributed application open for improvements and optimizations.
The concept of a directed acyclic graph allows you to solve many problems related to fault tolerance, monitoring, planning and resource management , in much more elegant ways than is implemented in Hadoop (I wrote about this in the first article of the cycle).

Failure processing of compute nodes allows you to not restart the entire stage again.

Processing "slow" compute nodes allows you not to "wait" for the nodes that have "completed" the work, the slowest node (for example, to start the Reduce phase)
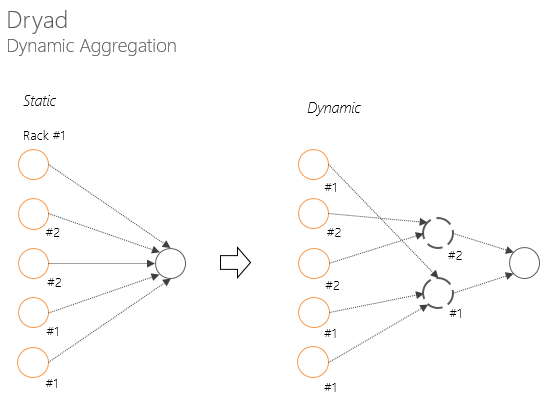
Dynamic aggregation in Dryad avoids degradation of network bandwidth before the next stage (for example, convolution).
Another interesting feature that Hadoop lacks is the abstraction of the notion of channel . Due to the introduced abstraction, the channel in Dryad can be either TCP, or a temporary file and shared memory FIFO. That allows in such algorithms as the calculation of PageRank, to exchange data between iterations through channels with low latency (for example, shared memory FIFO). While in Hadoop, data transfer between iterations will always go over TCP channels that have a rather high latency compared to shared memory. (There is information that this behavior was corrected in YARN, but I haven’t yet seen a working confirmation.)
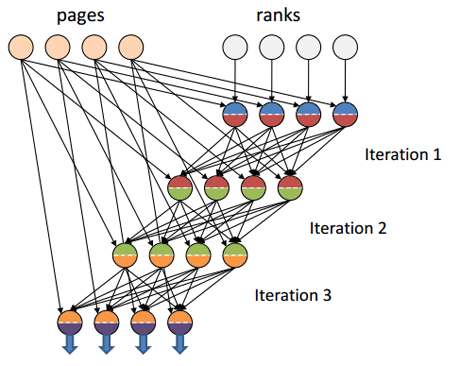
Source of illustration [7]
Some architectural solutions from Dryad (one of which was discussed in the previous article, “attaching” metadata to execution graphs) and native support of the framework for high-level PL with static typing allowed the development of Dryad applications with extremely strictly typed data . While for developers under Hadoop, the usual practice is parsing the input data and further (not the safest) conversion to the expected type.
3.3. Practice
Below are listings of arithmetic mean calculating applications for Hadoop and Dryad using low-level APIs.
Listing 1. Calculation of arithmetic mean in Hadoop (Java). Source [1].
// InitialReduce: input is a sequence of raw data tuples; // produces a single intermediate result as output static public class Initial extends EvalFunc<Tuple> { @Override public void exec(Tuple input, Tuple output) throws IOException { try { output.appendField(new DataAtom(sum(input))); output.appendField(new DataAtom(count(input))); } catch(RuntimeException t) { throw new RuntimeException([...]); } } } // Combiner: input is a sequence of intermediate results; // produces a single (coalesced) intermediate result static public class Intermed extends EvalFunc<Tuple> { @Override public void exec(Tuple input, Tuple output) throws IOException { combine(input.getBagField(0), output); } } // FinalReduce: input is one or more intermediate results; // produces final output of aggregation function static public class Final extends EvalFunc<DataAtom> { @Override public void exec(Tuple input, DataAtom output) throws IOException { Tuple combined = new Tuple(); if(input.getField(0) instanceof DataBag) { combine(input.getBagField(0), combined); } else { throw new RuntimeException([...]); } double sum = combined.getAtomField(0).numval(); double count = combined.getAtomField(1).numval(); double avg = 0; if (count > 0) { avg = sum / count; } output.setValue(avg); } } static protected void combine(DataBag values, Tuple output) throws IOException { double sum = 0; double count = 0; for (Iterator it = values.iterator(); it.hasNext();) { Tuple t = (Tuple) it.next(); sum += t.getAtomField(0).numval(); count += t.getAtomField(1).numval(); } output.appendField(new DataAtom(sum)); output.appendField(new DataAtom(count)); } static protected long count(Tuple input) throws IOException { DataBag values = input.getBagField(0); return values.size(); } static protected double sum(Tuple input) throws IOException { DataBag values = input.getBagField(0); double sum = 0; for (Iterator it = values.iterator(); it.hasNext();) { Tuple t = (Tuple) it.next(); sum += t.getAtomField(0).numval(); } return sum; } Listing 2. Calculate the arithmetic average in Dryad (C #). Source [1].
public static IntPair InitialReduce(IEnumerable<int> g) { return new IntPair(g.Sum(), g.Count()); } public static IntPair Combine(IEnumerable<IntPair> g) { return new IntPair(g.Select(x => x.first).Sum(), g.Select(x => x.second).Sum()); } [AssociativeDecomposable("InitialReduce", "Combine")] public static IntPair PartialSum(IEnumerable<int> g) { return InitialReduce(g); } public static double Average(IEnumerable<int> g) { IntPair final = g.Aggregate(x => PartialSum(x)); if (final.second == 0) return 0.0; return (double)final.first / (double)final.second; } 3.4. Developer Accessibility
Dryad is a proprietary system with a hazy future (or rather no such) at all, rather closed from the professional community. In contrast, Hadoop is an open-source project with a huge community, a clear licensing method, and several large distributors (Cloudera, Hortonworks, etc.).
In conclusion, the chapter on comparison with Hadoop, I note that getting a Hadoop cluster into its use at the current level of cloud services development is not difficult: Amazon Web Services provides Hadoop cluster through its Amazon Elastic MapReduce service , and the Windows Azure cloud platform - through Microsoft HDInsight service .
With the advent of the bunch “Hadoop + {WA | AWS} "The availability of the Hadoop platform for startups and researchers has become extremely high. There is no need to talk about the availability of Dryad: there are no commercial licenses, almost no one talked about academic use.
Hadoop is the de facto standard for working with Big Data. There is an expectation that after the future release of YARN no one will have any doubt that the platform has become deserved by this standard. As for the project, Dryad seems to have reincarnations, one of them is Naiad (incremental Dryad); and the principles laid down in Dryad, for sure, have been continued not only in Microsoft Research projects, but also in the open-source community.
Conclusion
The Dryad framework, having in its basis the concept of a directed acyclic graph , imposed on this concept the latest ideas of the world of frameworks of distributed execution of applications of traditional and parallel DBMS . Sharing responsibilities related to the execution environment, distributed storage and software model between the individual modules allowed Dryad to remain an extremely flexible system; and tight integration with the existing software stack for .NET developers (.NET Framework, C #, Visual Studio) significantly reduces the time required to start working with the framework.
A simple and elegant concept, innovative ideas, beautiful architecture and a familiar technology stack make Dryad an effective tool for working with Big Data. More efficient than hardware-specific GPU computing; poorly scalable solutions based on traditional DBMS; expensive and limited to the primitiveness of the SQL language solutions based on parallel DBMS. Dryad surpasses the “looped” Hadoop on the map / reduce model, which suffers before the emergence of YARN, sometimes from single points of failure, sometimes from low utilization of resources, or from the inertia of its own community.
At the same time, all the obvious advantages of Dryad are easily leveled by the nature of this product - this is Microsoft’s proprietary product for internal use , which Microsoft alone decides the fate of.
But this does not prevent Dryad from being what it is - a new interesting look, an innovative vision of Microsoft Research's distributed application execution systems.
List of sources
[1] Y. Yu, PK Gunda, M. Isard. Distributed Aggregation for Data-Parallel Computing: Interfaces and Implementations , 2009.
[2] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: Distributed data-parallel programs from sequential building blocks . In Proceedings of the European Conference on Computer Systems (EuroSys), 2007.
[3] Tom White. Hadoop: The Definitive Guide, 3rd Edition. O'Reilly Media / Yahoo Press, 2012.
[4] Arun C Murthy. The Next Generation of Apache Hadoop MapReduce . Yahoo 2011
[5] D. DeWitt and J. Gray. Parallel database systems: The future of high performance database processing. Communications of the ACM, 36 (6), 1992.
[6] David Tarditi, Sidd Puri, and Jose Oglesby. Accelerator: using data-parallelism to program GPUs for general-purpose uses. International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Boston, MA, October 2006.
[7] Jinyang Li. Dryad / DryadLinq Slides adapted from those of Yuan Yu and Michael Isard , 2009.
Source: https://habr.com/ru/post/182688/
All Articles