Porting code to iOS / Android mobile devices
What do you think is more attractive: to face new interesting problems and develop nontrivial algorithms or to rewrite existing logic from one language to another and fight with strange features of specific APIs? I have been working on mobile development for 8 years already, and, without hesitation, I choose the first option, but I also like to make war with the API. Those who agree with me, but still do not know how to do the first and minimize the second, it will be interesting to look under the cat.
In this article I will share with you my thoughts on the general principles of porting. We will not get into the jungle of specific software implementations of applications for Android or iOS. I'll just try to tell you how to make the application easily transferred to various devices and could be called cross-platform.
To begin, we define a range of tasks. In this article, we will not affect embedded systems, which, of course, also work for the benefit of mobile technology. We will consider only modern mobile devices: phones and tablets. The first part of the article will be devoted to the architecture of modern mobile processors and restrictions, and vice versa, the features that the mobile developer receives from them. In the second part I will talk about some basic techniques that are necessary for writing portable code.
')
Not so long ago, about five years ago, there were a lot of different companies that produced mobile processors with their own architectures. However, now the main architecture can be counted on the fingers of one hand, and there will still be a reserve. First of all, it is ARM. In addition to it, there are MIPS, which are usually included in the Java NDK, and Intel with its Atom.
All the methods discussed below are applicable to all of these systems. But for convenience, we consider them on the example of the most common ARM-processors. What do we need to know about them?
ARM itself does not release processors, it sells a release license, and various firms (Samsung, LG, Broadcom, Apple, Qualcomm, Freescale) buy licenses and release their own versions of processors, single-core or multi-core - which ones they like.
What does licensing give? You do not just take the core, you make your processor. You can refine it: to improve it or, on the contrary, to simplify it is your right. A history example is a famous Intel with an XScale processor . They bought a license for ARMv5TE and seriously reworked it. In my opinion, this is the most successful of the existing processing. They improved the work with memory, increased the cache, and, if we compare the implementation of Intel and Samsung based on ARMv5TE, then Intel won times, probably two times. The main feature of this processor was the fact that a 40-bit battery coprocessor first appeared in it, which allowed multiplying with 4 numbers in 1 clock cycle, while the older ones had the Wireless MMX coprocessor, which provides a powerful set of SIMD instructions
From an engineer’s point of view, what is a system on a chip? This is a small microprocessor, on which a bunch of different devices. You buy a license from ARM, put there one, two-as you want cores. Additional coprocessors (graphics, DSP, etc.), memory (ROM, FLASH ...) In addition, I / O interfaces are usually inserted there: Ethernet, USB, COM ports, if necessary. In order to make all this go to work, oscillators and timers are added to the same crystal in order not to make additional strapping by separate blocks onto the board.

The implementation of the system on a chip has become possible for ARM, because this system has very few transistors compared to the same Pentium. Because of this, it takes up little space on the chip, and technologically it turns out to contain everything that the developers want. It is unlikely that we would have managed to fit all these units in Core i5 - if only because it is large in itself and with a large heatsink (since there are many transistors and they all get very hot).
Consider the features of architecture that are important for developers.
As the ARM family developed and progressed:
I would like to dwell separately on the last row of the table from the previous paragraph. What is Thumb? Initially it was a set of packaged ARM instructions. If we choose the second between speed and compactness of the code, then short 16-bit instructions with limited functionality are an excellent solution.
Thumb2 is an evolution of Thumb. It includes part of the ARM instructions, and consists of a set of 16-bit and 32-bit instructions designed to ensure the density of the code in Thumb and at the same time preserve the performance of a full-fledged ARM.
I will take the liberty to define cross-platform: “A cross-platform code can be considered a code for which the cost of transferring to another system is much less than the cost of writing this code from scratch.” That is, we do not call porting the situation "I have some kind of algorithm, I want to do the same on iOS - accordingly, I have to write the same for this platform." This is not porting, this is writing again. To port an algorithm, it must meet the conditions of cross-platform.
I define the principles of writing cross-platform code as “separation and unification”. I will try to explain what it is. These items are not postulates, this is my vision.
Let us consider each item in more detail.
What do I mean by uniform typing? You simply define your types. The above example describes stdint. It is defined for the Microsoft compiler and for Linux. If you want more control, you can write “my_love_int8”, “my_love_int16” and then use these types in your program. This helps a lot, for example, if you work with a network: you are always sure that all packages are int16, the distance between them is 0, the offset is different and nothing else. After all, if you define everything through char, which suddenly becomes two-byte, everything will go somewhere wrong.
Also, to simplify reading and writing code dependent on the platform / compiler / version of the language, it is very useful to introduce your own unified defaults. such as:
In my practice there were a lot of heavy algorithms, such as voice and video codecs. For ease of porting, it is desirable that the algorithm does not use any system functions, and even better to do without system libraries.
One of the basic principles of writing portable and managed code is not to use malloc inside algorithms. Your algorithm should determine how much memory it will need, transfer this value to your memory manager, who already allocates memory and gives a reference to the allocated chunk during initialization. The algorithm uses this piece. Happiness and harmony.
What happens when your algorithm allocates memory itself? If you often create and kill processes, and many more algorithms, they begin to allocate and free memory randomly, then memory fragmentation begins. This leads to the fact that at some point you simply can not allocate the required amount of memory, even if the total amount of free memory is more than you need. RAM is still a fairly expensive resource, especially on mobile devices.
By the same principle, it is desirable to allocate other system functions.
Under the basic operations means the selection of such non-specific operations that are not in C, but which you use often.
Consider a simple CLZ (Count Leading Zeros) operation. There is no such operation in C, and if necessary, you can write an algorithm for counting zeros. The point is that in some processors, in particular in ARM, it is implemented at the hardware level. In these cases, we calmly use what we have. For this, the compiler may have an intrinsic function. If the compiler does not implement such a function (as in our example, the implementation of GCC), you can put an assembler operation. For those processors in which this operation is not implemented, you will have to write a separate code. However, this is still a basic operation. What is good? You write a basic operation once, call it in your code, and if you need to port, you simply write a unit test, port this operation, check the result with a unit test. If everything is OK, then the code you use will also be OK.
To demonstrate the need to highlight the basic operations, I would give a seemingly simple example: a shift for int64. In principle, this command is in C, but it can be implemented differently, since it is not a standard int, but int64. Int64 in different systems are differently called, but this is half the problem. The biggest trouble is that they can also be performed in different ways.
Consider a basic operation called logical shift right. There is a number that needs to be shifted by 63 and by 64. These are the boundary values. As is known, it is the boundary values that bring the most trouble. What will be in res63 and res64? The idea should be zeros. But in fact, everything is not so simple.

Depending on the bitness of the platform, we get different results, although everything is done thoroughly and according to the rules. That is why it is better to allocate controversial things to the basic operators and when porting separately do tests on them.
The hardware-dependent parts of the mobile application have the following features:
In order to somehow unify the work with hardware-dependent parts of the code, it will be a good practice to single out a set of basic wrappers. I will offer my version of the list of wrappers.
Depending on what the device does, you may need additional wrappers. Here is a brief list of hardware parts that make it necessary to use wrappers (they are necessary for porting to go smoothly).
Following all the above recommendations, we get an algorithm that is written through the same types that you transfer. This algorithm does not require any intervention at all. In theory, it should compile and earn immediately. It is better to have unit tests for it. If the algorithm is compiled and tested, then most likely everything will be fine. Basic operations are also ported, but they may not be.
Hardware parts already require porting. And it is better that they have an interface as close as possible to the system. They will be easier to check, and they are faster ported.
Finally, I would like to give some general recommendations: what you should pay attention to when writing portable code.
If you want to see a good example of the implementation of cross-platform code, I advise you to pay attention to libjingle. Almost all of the postulates discussed in this article are performed there.
If you know how to make porting the code even easier or you want to discuss some of the points I have outlined in more detail, I’ll be happy to talk to you in the comments.
In this article I will share with you my thoughts on the general principles of porting. We will not get into the jungle of specific software implementations of applications for Android or iOS. I'll just try to tell you how to make the application easily transferred to various devices and could be called cross-platform.
Action plan
To begin, we define a range of tasks. In this article, we will not affect embedded systems, which, of course, also work for the benefit of mobile technology. We will consider only modern mobile devices: phones and tablets. The first part of the article will be devoted to the architecture of modern mobile processors and restrictions, and vice versa, the features that the mobile developer receives from them. In the second part I will talk about some basic techniques that are necessary for writing portable code.
')
CPU
Not so long ago, about five years ago, there were a lot of different companies that produced mobile processors with their own architectures. However, now the main architecture can be counted on the fingers of one hand, and there will still be a reserve. First of all, it is ARM. In addition to it, there are MIPS, which are usually included in the Java NDK, and Intel with its Atom.
All the methods discussed below are applicable to all of these systems. But for convenience, we consider them on the example of the most common ARM-processors. What do we need to know about them?
- from a commercial point of view: kernel licensing . You can buy a license and create your processor.
- from a technological point of view: system on chip (System On Chip) . All modules are collected in one place.
- from the point of view of the software developer: a powerful RISC-architecture
Licensing
ARM itself does not release processors, it sells a release license, and various firms (Samsung, LG, Broadcom, Apple, Qualcomm, Freescale) buy licenses and release their own versions of processors, single-core or multi-core - which ones they like.
What does licensing give? You do not just take the core, you make your processor. You can refine it: to improve it or, on the contrary, to simplify it is your right. A history example is a famous Intel with an XScale processor . They bought a license for ARMv5TE and seriously reworked it. In my opinion, this is the most successful of the existing processing. They improved the work with memory, increased the cache, and, if we compare the implementation of Intel and Samsung based on ARMv5TE, then Intel won times, probably two times. The main feature of this processor was the fact that a 40-bit battery coprocessor first appeared in it, which allowed multiplying with 4 numbers in 1 clock cycle, while the older ones had the Wireless MMX coprocessor, which provides a powerful set of SIMD instructions
System on chip
From an engineer’s point of view, what is a system on a chip? This is a small microprocessor, on which a bunch of different devices. You buy a license from ARM, put there one, two-as you want cores. Additional coprocessors (graphics, DSP, etc.), memory (ROM, FLASH ...) In addition, I / O interfaces are usually inserted there: Ethernet, USB, COM ports, if necessary. In order to make all this go to work, oscillators and timers are added to the same crystal in order not to make additional strapping by separate blocks onto the board.
The implementation of the system on a chip has become possible for ARM, because this system has very few transistors compared to the same Pentium. Because of this, it takes up little space on the chip, and technologically it turns out to contain everything that the developers want. It is unlikely that we would have managed to fit all these units in Core i5 - if only because it is large in itself and with a large heatsink (since there are many transistors and they all get very hot).
RISC architecture
Consider the features of architecture that are important for developers.
- First of all, it is a load / store architecture . All operations are performed with registers: loaded - calculated - unloaded, and nothing else. Cannot perform an operation with operand in memory.
- To support work with registers, the kernel has a large register file - 16 registers of 32 bits each . They are, in principle, equivalent. Some, of course, have specialized names that seem to hint at their purpose, but all operations are available to you with reference to any register.
- Fixed length commands . In ARM mode, this is usually 32 bits: 1 command - 1 word, one after another. The conveyor to this fact is certainly pleased, because nothing changes, everything is predictable.
- One of the features of ARM is the ability to not only handle memory offset, but also read and load from memory with pre-increment, post-increment with shift in a register or directly in numeric form. Powerful address commands - one of the most important features of ARM
- All operations tend to be completed in 1 clock . Maybe more or less - these are nuances for different cores.
- Another great ARM chip is conditional execution . When you write instructions (arithmetic, or just check the flag), you have flags, and the following operations are performed only if the condition is met. Accordingly, you do not need to make large transitions. It is very convenient: it does not reset the conveyor, while increasing productivity.
- Fast shift ARM allows you to perform shift arithmetic: you can write a + = (j << 2); in one command, which will be executed in one clock.
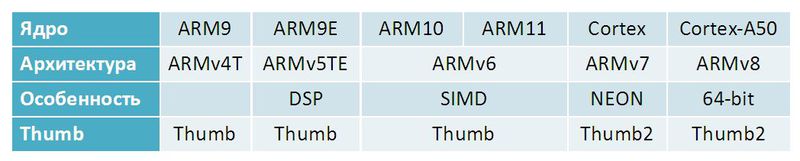
ARM family
As the ARM family developed and progressed:
- ARM9 will be considered basic. This is the past, although it is used, but not in modern phones.
- ARM9E is still found in Android, and this must be taken into account. In ARM9E appeared DSP-instructions, which made it possible to greatly accelerate the voice processing algorithms.
- The core of the ARM10 has gone almost unnoticed.
- On the basis of the ARM11 various devices came out, but the most significant device was the first iPhone. An innovation here is the emergence of SIMD instructions, albeit weaker than Intel's Wireless MMX in XScale.
- Cortex is the most common core today. This may be a multi-core Cortex A9 system or a single-core Cortex A8, but they have the same architecture - ARMv7. Here ARM made a small revolution called NEON. This is a separate coprocessor, which may not be on the chip, even though it is included in the ARMv7 architecture. A feature of NEON is the presence of 64-bit and 128-bit commands that provide parallel addition, subtraction, translation, and saturation. It is here that ARM has a full-fledged SIMD, which provides acceleration in processing digital signals.
- ARM has announced "our bright future" - 64-bit Cortex-A50 core with ARMv8 architecture. They promise full compatibility with everything that happened before in a separate 32-bit mode.
Thumb
I would like to dwell separately on the last row of the table from the previous paragraph. What is Thumb? Initially it was a set of packaged ARM instructions. If we choose the second between speed and compactness of the code, then short 16-bit instructions with limited functionality are an excellent solution.
Thumb2 is an evolution of Thumb. It includes part of the ARM instructions, and consists of a set of 16-bit and 32-bit instructions designed to ensure the density of the code in Thumb and at the same time preserve the performance of a full-fledged ARM.
Cross platform
I will take the liberty to define cross-platform: “A cross-platform code can be considered a code for which the cost of transferring to another system is much less than the cost of writing this code from scratch.” That is, we do not call porting the situation "I have some kind of algorithm, I want to do the same on iOS - accordingly, I have to write the same for this platform." This is not porting, this is writing again. To port an algorithm, it must meet the conditions of cross-platform.
I define the principles of writing cross-platform code as “separation and unification”. I will try to explain what it is. These items are not postulates, this is my vision.
- First of all, uniform typing - it is important to write code in its single types, since native native types may differ on different platforms
- Separation of code into algorithmic and non-algorithmic part. The system calls and basic operations are pulled from the algorithms.
- The device-dependent part : we divide the program into an algorithmic part (mathematics) and into what depends on the system
Let us consider each item in more detail.
Uniform typing
#if defined(_MSC_VER) typedef signed char int8_t; typedef signed short int16_t; typedef signed int int32_t; typedef signed __int64 int64_t; typedef unsigned char uint8_t; typedef unsigned short uint16_t; typedef unsigned int uint32_t; typedef unsigned __int64 uint64_t; #elif defined(LINUX_ARM) typedef signed char int8_t; typedef signed short int16_t; typedef signed int int32_t; typedef signed long long int64_t; typedef unsigned char uint8_t; typedef unsigned short uint16_t; typedef unsigned int uint32_t; typedef unsigned long long uint64_t; #else #include <stdint.h> #endif What do I mean by uniform typing? You simply define your types. The above example describes stdint. It is defined for the Microsoft compiler and for Linux. If you want more control, you can write “my_love_int8”, “my_love_int16” and then use these types in your program. This helps a lot, for example, if you work with a network: you are always sure that all packages are int16, the distance between them is 0, the offset is different and nothing else. After all, if you define everything through char, which suddenly becomes two-byte, everything will go somewhere wrong.
struct NetworkStatistics { uint16_t currentBufferSize; uint16_t preferredBufferSize; uint16_t currentPacketLossRate; uint16_t currentDiscardRate; uint16_t currentExpandRate; uint16_t currentPreemptiveRate; uint16_t currentAccelerateRate; }; Also, to simplify reading and writing code dependent on the platform / compiler / version of the language, it is very useful to introduce your own unified defaults. such as:
#if defined(__APPLE__) # ifdef TARGET_OS_IPHONE # define MAILRU_OS_IOS # elif defined(TARGET_IPHONE_SIMULATOR) # define MAILRU_OS_IOS # define MAILRU_OS_IOS_SIMULATOR # elif defined(TARGET_OS_MAC) || defined (__OSX__) # define MAILRU_OS_MACOSX # else # define MAILRU_OS_MACOSX # endif #elif defined(_WIN64) # define MAILRU_OS_WIN64 # define MAILRU_OS_WINDOWS #elif _WIN32 # define MAILRU_OS_WIN32 # define MAILRU_OS_WINDOWS #elif ANDROID # define MAILRU_OS_ANDROID #else # error Unsupported OS target! #endif #if defined(_M_X64) || defined(__x86_64__) # define MAILRU_ARCH_X86_FAMILY # define MAILRU_ARCH_64_BIT #elif defined(__ARMEL__) || defined(__arm) || defined(_M_ARM_FP) # define MAILRU_ARCH_ARM_FAMILY # define MAILRU_ARCH_32_BIT #elif defined(__ppc__) # define MAILRU_ARCH_PPC_FAMILY # define MAILRU_ARCH_32_BIT #else # error Please add support for your architecture in typedefs.h #endif Algorithms
In my practice there were a lot of heavy algorithms, such as voice and video codecs. For ease of porting, it is desirable that the algorithm does not use any system functions, and even better to do without system libraries.
System calls
One of the basic principles of writing portable and managed code is not to use malloc inside algorithms. Your algorithm should determine how much memory it will need, transfer this value to your memory manager, who already allocates memory and gives a reference to the allocated chunk during initialization. The algorithm uses this piece. Happiness and harmony.
// Interface int32 MyAlgorithm_GetMemSizeNeed() int32 MyAlgorithm_Init(void *memory) void *MyAlgorithm_Destroy() // Using { void *m = MyManager_GetMem(MyAlgorithm_GetMemSizeNeed()); MyAlgorithm_init(m); //... m = MyAlgorithm_Destroy(); MyManager_FreeMem(m); } What happens when your algorithm allocates memory itself? If you often create and kill processes, and many more algorithms, they begin to allocate and free memory randomly, then memory fragmentation begins. This leads to the fact that at some point you simply can not allocate the required amount of memory, even if the total amount of free memory is more than you need. RAM is still a fairly expensive resource, especially on mobile devices.
By the same principle, it is desirable to allocate other system functions.
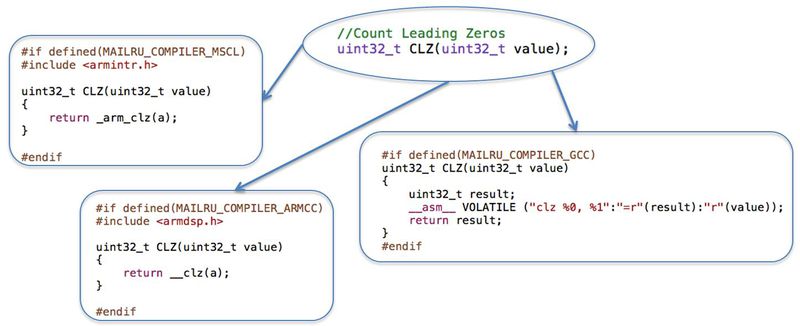
Basic operations
Under the basic operations means the selection of such non-specific operations that are not in C, but which you use often.
Consider a simple CLZ (Count Leading Zeros) operation. There is no such operation in C, and if necessary, you can write an algorithm for counting zeros. The point is that in some processors, in particular in ARM, it is implemented at the hardware level. In these cases, we calmly use what we have. For this, the compiler may have an intrinsic function. If the compiler does not implement such a function (as in our example, the implementation of GCC), you can put an assembler operation. For those processors in which this operation is not implemented, you will have to write a separate code. However, this is still a basic operation. What is good? You write a basic operation once, call it in your code, and if you need to port, you simply write a unit test, port this operation, check the result with a unit test. If everything is OK, then the code you use will also be OK.
Unseen circumstances
To demonstrate the need to highlight the basic operations, I would give a seemingly simple example: a shift for int64. In principle, this command is in C, but it can be implemented differently, since it is not a standard int, but int64. Int64 in different systems are differently called, but this is half the problem. The biggest trouble is that they can also be performed in different ways.
Example: uint64 >> n
uint64_t LogicalShiftRigth(uint64_t number, int shift) { return number >> shift; } uint64_t test = 0x1234567812345678; uint64_t res63 = LogicalShiftRigth(test, 63); uint64_t res64 = LogicalShiftRigth(test, 64); Consider a basic operation called logical shift right. There is a number that needs to be shifted by 63 and by 64. These are the boundary values. As is known, it is the boundary values that bring the most trouble. What will be in res63 and res64? The idea should be zeros. But in fact, everything is not so simple.
Depending on the bitness of the platform, we get different results, although everything is done thoroughly and according to the rules. That is why it is better to allocate controversial things to the basic operators and when porting separately do tests on them.
Hardware dependent parts
The hardware-dependent parts of the mobile application have the following features:
- Strongly depend on API frameworks , whether it be Android, iOS or something else.
- Often use non-native means . For example, the code that uses video in Android can have this algorithm: the engine is written in C. It calls Java via JNI, which then returns the result via JNI.
- Use less portable languages . For less portable languages, I refer, for example, Objective C and Java. Despite the fact that Java is considered a cross-platform language, it is clearly lacking in comparison with C universality.
Base Wrappers
In order to somehow unify the work with hardware-dependent parts of the code, it will be a good practice to single out a set of basic wrappers. I will offer my version of the list of wrappers.
- System log Normal printf () helps a lot with development. Each platform has its own frameworks; for example, for iOS it could be NSLog, for Android - Logcat.
- Memory manager . As we’ve already figured out, it’s better to have your own memory manager, which makes malloc / free. In addition, you can teach him to look for memory leaks.
- Mutexes / atomic operations also have different implementations in different systems.
- The thread manager is an add-on for mutexes and the main API for creating a multi-threaded application.
- System information can be useful if you change something in runtime. If your code is optimized for multiple processors, you can in the runtime find out what the system is and connect the necessary part.
- Tracing / logging is no longer just a system log; it's debugging bugs, and it's great if it is the same for all platforms.
- Working with files involves file I / O, .pm dumps, and so on. It is very convenient to have output through a single interface.
- Profiling tools . If you have a heavy code, standard means can not always quickly figure out what is lost and where. You can, of course, use the native tools of each specific platform, or you can write your own cross-platform clock, log, and so on, and call them in the code.
Additional Wrappers
Depending on what the device does, you may need additional wrappers. Here is a brief list of hardware parts that make it necessary to use wrappers (they are necessary for porting to go smoothly).
- Sockets / Networking
- Audio devices
- Video devices
- Input device
Subtotal
Following all the above recommendations, we get an algorithm that is written through the same types that you transfer. This algorithm does not require any intervention at all. In theory, it should compile and earn immediately. It is better to have unit tests for it. If the algorithm is compiled and tested, then most likely everything will be fine. Basic operations are also ported, but they may not be.
Hardware parts already require porting. And it is better that they have an interface as close as possible to the system. They will be easier to check, and they are faster ported.
Attention!
Finally, I would like to give some general recommendations: what you should pay attention to when writing portable code.
- Memory data / code. Remember, in mobile memory devices, a lot does not happen. She is always a little, and the one that is, constantly trying to sneak off somewhere, is to give her freedom. Therefore, it is better to have your own memory manager to avoid fragmentation. In addition, it is desirable that the code be small: if ARM-specific operations are not critical for you, it is better to use Thumb2.
- Data alignment Prior to ARMv7, ARM architectures did not support access to unaligned data. But even after such behavior became possible, this operation causes an additional idle processor to operate. So it is better to align the memory along the int border, and even better along the cache boundary: this will provide you with a quick load.
- Optimization for the processor. If you have heavy algorithms, especially voice and video, without optimization, nothing will work for you. And if it suddenly takes off, it will quickly devour the entire battery.
- Floating point By default, there is no floating point on ARM. Now in the Cortex unit appeared NEON, it implements floating point operations, but, again, not in all devices. If about smartphones running iOS it is known that there is always a floating point there, then manufacturers of Android devices may refuse it in order to save it. Therefore, in the case of Android, Get CPU Features will help us, where there is a floating point check.
- Integer division. With it, things are the same as with floating point: not all kernels can divide int into int, and this should be remembered.
- Multithreading and MainThread. If your application is not multi-threaded - make it multi-threaded. Loading UI in mobile applications is a terrible thing: with a single-threaded implementation, a wide range of effects are possible, from brakes to crash of an application. If you already have a multi-threaded system, pay attention to MainThread, because many things must be executed only from it.
Small total
- First, understanding the processor architecture improves porting quality.
- Second: the key to successful porting is a good cross-platform code. That is, the less time you spend rewriting existing code, the better, faster and cheaper. Everyone will be happy, especially the manager.
- And third: the simplicity of code portability is determined by the well-thought-out architecture. So if you are writing a new application, think of it as cross-platform from the very beginning. Even if you do not plan to endure it, maybe someone else will have to do this.
If you want to see a good example of the implementation of cross-platform code, I advise you to pay attention to libjingle. Almost all of the postulates discussed in this article are performed there.
If you know how to make porting the code even easier or you want to discuss some of the points I have outlined in more detail, I’ll be happy to talk to you in the comments.
Source: https://habr.com/ru/post/182506/
All Articles