High Availability Optical Ring
Good afternoon, dear Habrayuzer.
Would you like to tell you about the project implemented by our engineers to build a high-availability optical ring between our clouds in Moscow.

When building a fault-tolerant system capable of maintaining control and performance in case of damage, the cloud provider must place particularly high demands on its topology. Such a fault-tolerant system provides for the connection of two or more data centers (DC) and corporate networks using fiber optic links, which allows not to transport the components of the storage system from one place to another to create a copy of the data.
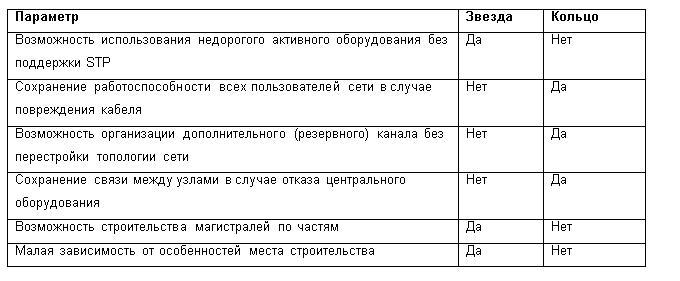
The two main competing topologies of the DC connection to the corporate optical networks are “star” and “ring”. In the event of failure of any node (or part of the cable system) of the “ring”, the network is generally functioning. In addition, the ring topology is redundant in the number of links, and therefore more expensive. In turn, the "star" is somewhat better suited to provide the centralized service that is usual for a local network. Indeed, in a local area network (LAN) there is almost always a server or a router, for which the network is usually built. Comparative characteristics of the “ring” and “star” topologies are presented in the table.
')
Comparing star and ring topologies
Ensuring the continuous operation of customer information systems located in the cloud is the main goal that the cloud hosting provider should set for itself, which means that increasing the SLA level will be the main task.
Creating our own high-availability optical ring, the circuit of which is shown in the figure below, has allowed us to significantly increase the level of SLA, which we guarantee to our customers.
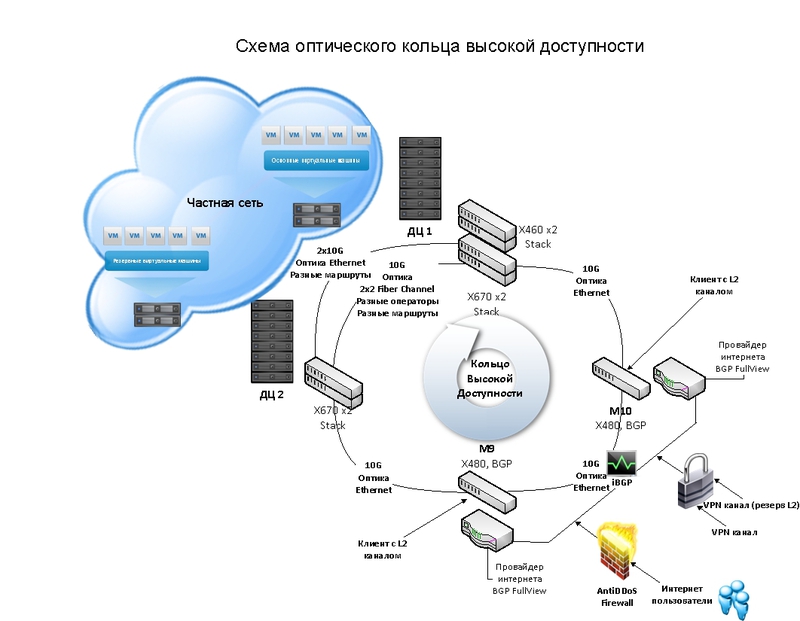
The optical ring is built between our two clouds in Moscow, which are physically located in DC Tier 3, and the switching nodes M9 and M10. The distance between the DC can be up to 100 km, in our case it is about 15 km. The main feature of the ring is the absence of a single (critical) point of failure. Optical channels are completely duplicated, and they are laid along different routes and different operators. Thanks to this solution, the inaccessibility of services in the cloud is virtually eliminated due to problems with channels, since even in the event of failure of one optical channel, all work will continue along another circuit and there will be no interruption. In addition to the optical channels, all switches and routers are duplicated, which also provides automatic switching to the working circuit in case of failure of one of the routers or switches. In addition to problems with channels, this scheme allows to exclude damage from earthworks, which for some reason are carried out exactly where the fiber optic line lies.
The total bandwidth of the optical ring is 180 Gbit / s, of which 120 Gbit / s is the capacity between the DC, 20 Gbit / s between the first DC and the switching node M10, 20 Gbit / s between the switching nodes M10 and M9 and 20 Gbit / s - between the switching node M9 and the second DC. Each of the routes consists of physically independent fiber optic pairs, which are aggregated into a common channel on the root routers.
The entire network is physically divided into internal and external, different server interfaces are connected to different switches and work in different networks. On the external network, the servers communicate with the Internet; on the internal network, all the servers communicate with each other. The servers are connected to L2 and L3 switchboards, which, in turn, are connected by at least two 10-gigabit links to the aggregating stack of switches. Each link goes to a separate switch in the stack.
The optical ring is made on Summit switches of the Extreme company.

In addition to the basic functionality based on the support of standard Ethernet technologies, Summit switches incorporate RPR (Resilient Packet Ring) technology. This technology allows switches to form a ring topology, to provide recovery in less than 50 ms, and to efficiently use bandwidth in ring structures.
Summit switches can have up to 24 mini-GBIC slots for installing 1000Base-X interface modules, 4 10/100 / 1000Base-T ports and 2 slots for installing 10GBase-X interface modules (XENPAK). The bandwidth of the switching matrix is 160 Gbit / s, and the bandwidth per L3 is 65 million packets / s. The switches support RIPv1 / 2, OSPF, BGP-4, PIM-SM, IGMP protocols, various QoS provisioning technologies on L1-L4, incl. bandwidth limitation in increments of 64 Kbps (1 Mbps on 10 Gbps channels), 8 hardware-serviced queues on each port. Power supply redundancy, external power supply, memory bank backup for storing configuration and ExtremeWare XOS operating system image are provided.
The solution provides for the possibility of connecting to each node of the trunk ring via optical interfaces of aggregating nodes. Access switches can be connected to each aggregating switch via optical interfaces to connect users.
RPR technology is based on the standard second-channel Ethernet switching mechanism, supplemented by the RAD Data Communications algorithm. The latter allows all nodes of the ring to receive information about the state of the network and in the event of an accident or abnormal situation, quickly transfer traffic to an alternative route.
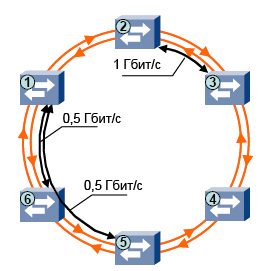
The RPR ring node is a network device that functions as a regular switch at the second level. Each node has two trunk ports for transmitting traffic around the ring, as well as access ports through which traffic enters the ring, and user ports for delivering traffic to specific services. In normal mode, all RPR nodes exchange special service messages. Each node at certain intervals sends a message about the state of the link (link state) through both its trunk ports. Even if there is no status message for the ring, the node must send “keep-alive” messages, meaning for the neighboring node that everything is in order. When a node receives a service message indicating that its neighbor also received such a message, it considers the ring to function normally. A channel is considered abnormal when a node receives a corresponding message or when a node does not receive any overhead messages for 30 ms. In this case, the traffic starts in the opposite direction, bypassing the emergency site. This algorithm allows us to combine the simplicity of conventional switching with the ability to quickly re-route traffic in the event of a failure.
Results:
Thus, a high availability optical ring can increase the availability of services in the cloud (SLA) to 99.99% or more. This means that there is a unique opportunity to adapt the level of SLA of cloud services to the requirements of individual customers and industries, which is a huge competitive advantage. Thanks to adaptable SLA, cloud providers have a differentiation method that is beneficial for both themselves and customers. Not all customers need equally high guarantees of uptime. For example, for a customer who uses the cloud to test applications, in most cases the same high SLA is not required as for customers who deploy critical systems in the cloud. Understanding this fact will allow customers to significantly reduce their IT costs, and cloud providers can offer customers the necessary level of service and special prices in accordance with the chosen SLA level.
Ps All habra users are still provided with free test access to our cloud.
Would you like to tell you about the project implemented by our engineers to build a high-availability optical ring between our clouds in Moscow.
When building a fault-tolerant system capable of maintaining control and performance in case of damage, the cloud provider must place particularly high demands on its topology. Such a fault-tolerant system provides for the connection of two or more data centers (DC) and corporate networks using fiber optic links, which allows not to transport the components of the storage system from one place to another to create a copy of the data.
The two main competing topologies of the DC connection to the corporate optical networks are “star” and “ring”. In the event of failure of any node (or part of the cable system) of the “ring”, the network is generally functioning. In addition, the ring topology is redundant in the number of links, and therefore more expensive. In turn, the "star" is somewhat better suited to provide the centralized service that is usual for a local network. Indeed, in a local area network (LAN) there is almost always a server or a router, for which the network is usually built. Comparative characteristics of the “ring” and “star” topologies are presented in the table.
')
Comparing star and ring topologies
Ensuring the continuous operation of customer information systems located in the cloud is the main goal that the cloud hosting provider should set for itself, which means that increasing the SLA level will be the main task.
Creating our own high-availability optical ring, the circuit of which is shown in the figure below, has allowed us to significantly increase the level of SLA, which we guarantee to our customers.
The optical ring is built between our two clouds in Moscow, which are physically located in DC Tier 3, and the switching nodes M9 and M10. The distance between the DC can be up to 100 km, in our case it is about 15 km. The main feature of the ring is the absence of a single (critical) point of failure. Optical channels are completely duplicated, and they are laid along different routes and different operators. Thanks to this solution, the inaccessibility of services in the cloud is virtually eliminated due to problems with channels, since even in the event of failure of one optical channel, all work will continue along another circuit and there will be no interruption. In addition to the optical channels, all switches and routers are duplicated, which also provides automatic switching to the working circuit in case of failure of one of the routers or switches. In addition to problems with channels, this scheme allows to exclude damage from earthworks, which for some reason are carried out exactly where the fiber optic line lies.
The total bandwidth of the optical ring is 180 Gbit / s, of which 120 Gbit / s is the capacity between the DC, 20 Gbit / s between the first DC and the switching node M10, 20 Gbit / s between the switching nodes M10 and M9 and 20 Gbit / s - between the switching node M9 and the second DC. Each of the routes consists of physically independent fiber optic pairs, which are aggregated into a common channel on the root routers.
The entire network is physically divided into internal and external, different server interfaces are connected to different switches and work in different networks. On the external network, the servers communicate with the Internet; on the internal network, all the servers communicate with each other. The servers are connected to L2 and L3 switchboards, which, in turn, are connected by at least two 10-gigabit links to the aggregating stack of switches. Each link goes to a separate switch in the stack.
The optical ring is made on Summit switches of the Extreme company.
In addition to the basic functionality based on the support of standard Ethernet technologies, Summit switches incorporate RPR (Resilient Packet Ring) technology. This technology allows switches to form a ring topology, to provide recovery in less than 50 ms, and to efficiently use bandwidth in ring structures.
Summit switches can have up to 24 mini-GBIC slots for installing 1000Base-X interface modules, 4 10/100 / 1000Base-T ports and 2 slots for installing 10GBase-X interface modules (XENPAK). The bandwidth of the switching matrix is 160 Gbit / s, and the bandwidth per L3 is 65 million packets / s. The switches support RIPv1 / 2, OSPF, BGP-4, PIM-SM, IGMP protocols, various QoS provisioning technologies on L1-L4, incl. bandwidth limitation in increments of 64 Kbps (1 Mbps on 10 Gbps channels), 8 hardware-serviced queues on each port. Power supply redundancy, external power supply, memory bank backup for storing configuration and ExtremeWare XOS operating system image are provided.
The solution provides for the possibility of connecting to each node of the trunk ring via optical interfaces of aggregating nodes. Access switches can be connected to each aggregating switch via optical interfaces to connect users.
RPR technology is based on the standard second-channel Ethernet switching mechanism, supplemented by the RAD Data Communications algorithm. The latter allows all nodes of the ring to receive information about the state of the network and in the event of an accident or abnormal situation, quickly transfer traffic to an alternative route.
The RPR ring node is a network device that functions as a regular switch at the second level. Each node has two trunk ports for transmitting traffic around the ring, as well as access ports through which traffic enters the ring, and user ports for delivering traffic to specific services. In normal mode, all RPR nodes exchange special service messages. Each node at certain intervals sends a message about the state of the link (link state) through both its trunk ports. Even if there is no status message for the ring, the node must send “keep-alive” messages, meaning for the neighboring node that everything is in order. When a node receives a service message indicating that its neighbor also received such a message, it considers the ring to function normally. A channel is considered abnormal when a node receives a corresponding message or when a node does not receive any overhead messages for 30 ms. In this case, the traffic starts in the opposite direction, bypassing the emergency site. This algorithm allows us to combine the simplicity of conventional switching with the ability to quickly re-route traffic in the event of a failure.
Results:
Thus, a high availability optical ring can increase the availability of services in the cloud (SLA) to 99.99% or more. This means that there is a unique opportunity to adapt the level of SLA of cloud services to the requirements of individual customers and industries, which is a huge competitive advantage. Thanks to adaptable SLA, cloud providers have a differentiation method that is beneficial for both themselves and customers. Not all customers need equally high guarantees of uptime. For example, for a customer who uses the cloud to test applications, in most cases the same high SLA is not required as for customers who deploy critical systems in the cloud. Understanding this fact will allow customers to significantly reduce their IT costs, and cloud providers can offer customers the necessary level of service and special prices in accordance with the chosen SLA level.
Ps All habra users are still provided with free test access to our cloud.
Source: https://habr.com/ru/post/182502/
All Articles