DryadLINQ. Microsoft Research Distributed LINQ
The focus of yesterday's post on Habré was the Microsoft Research - Dryad framework for distributed computing .
The framework is based on the representation of a task as a directed acyclic graph , where the vertices of the graph are programs , and the edges are the channels through which data is transmitted. Also, the Dryad framework ecosystem was reviewed and a detailed overview of the architecture of one of the central components of the framework ecosystem , the execution environment for distributed applications of Dryad, was made.
In this article we will discuss the top-level component of the software stack of the Dryad framework, a query language for the distributed storage DryadLINQ.
')
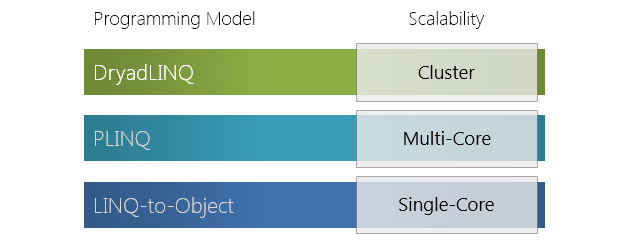
1. General information
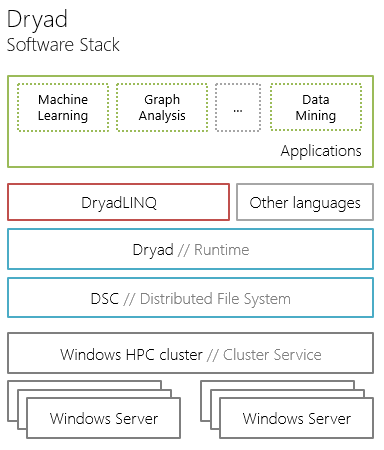
DryadLINQ is a high-level query language for data stored in a distributed file system and has an SQL-like syntax. DryadLINQ is based on the .NET Language Integrated Query (LINQ) software model, implements a specific LINQ provider for interacting with the Dryad runtime and provides the developer with an API for writing distributed running LINQ expressions.
Unlike the query languages for the Hadoop platform - HiveQL, Pig Latin - DryadLINQ is not another query language with a specific syntax (necessary for learning). Instead, DryadLINQ is based on well-known .NET developers:
Expanding the first paragraph of the above list, it is worth noting that LINQ initially did not contain explicit references to the nature of the data warehouse to which the request is made. And built on the basis of LINQ, API DryadLINQ alsodoes not give out strive not to "betray" their distributed nature.
Thus, by minimizing the differences in the syntax for writing a query to a database (on LINQ-to-SQL) or to a distributed file system (on DryadLINQ), the solution to one of the most frequent cases — migration from a database to a database — is greatly simplified. based on a distributed file system.
This is how DryadLINQ is presented to a distributed application developer. Below we talk about the internal implementation of DryadLINQ: about the stages of querying data, components and concepts that underlie DryadLINQ .
2. Stages of implementation

Source of illustration [5]
Step 1. A custom distributed application containing a LINQ expression is running. LINQ expressions are executed deferred (they will not be executed until the data returned by the query will be needed). DryadLINQ expressions are also deferred.
Step 2. When parsing LINQ expressions, the DryadLINQ-specific trigger “ToDryadTable ()” is called. DryadLINQ intercepts this trigger (so at this stage it becomes clear that the request for data will be distributed).
Step 3. DryadLINQ compiles the LINQ expression into the distributed Dryad query plan: the LINQ expression tree expands over subqueries, each of which represents a separate vertex in the future Dryad execution graph; the generation of service data necessary for launching remote vertex operations, generation of the code executed on the vertices, serialization of the necessary data types.
Step 4. DryadLINQ calls application-specific Dryad Job Manager.
Step 5. The Job Manager creates an application execution graph using the plan generated in step 3.
Step 6. Vertex programs are executed on the vertices defined for them.
Step 7. At the end of the execution of the Dryad-task, the result is recorded in the output table (s).
Step 8. The Job Manager returns the result to the node performing the DryadLINQ job and completes.
Step 9. The control is returned to the application that initiated the execution of the DryadLINQ expression. The result of the query is a DryadTable object. DryadTable implements IEnumerable <T>, so the contents of the strongly typed collection of DryadTable can be accessed as normal .NET objects.
3. DryadLINQ compiler
The heart of the query language DryadLINQ is the parallel compiler (parallel compiler) DryadLINQ. If we draw an analogy with the world of the SQL query language, the DryadLINQ compiler can be compared with the DBMS query scheduler / optimizer.
The compiler is responsible for compiling DryadLINQ expressions into a distributed program that runs on a Dryad cluster. The DryadLINQ compiler contains both a static component that generates an execution plan and a dynamic component that allows you to optimize performance based on different policies, changing the execution plan right in runtime.
3.1. Execution Plan Graph
When passing control to the compiler, the latter transforms the LINQ expression into an execution plan graph (Execution Plan Graph, EPG). An EPG is a prototype of a performance graph (that is, not a final plan).
The DryadLINQ optimizer also supplements EPG with metadata that can provide additional information about the distributed task during planning and execution. So for the vertices of the graph is information about the data partitioning scheme , and for the edges of the graph it is the .NET data type and data compression scheme, if any.
3.2. DryadLINQ Optimizations
In turn, DryadLINQ optimizer performs both static optimization based on greedy algorithms (greedy heuristics) and dynamic optimization based on the statistical information collected during the execution.
Static optimization
The main tasks of the static optimizer are two: minimizing the number of I / O operations on disk media and in the network. Which is logical, since traditionally the disk subsystem and interfaces for machine-to-machine interaction are a bottleneck in distributed computing environments.
The most interesting static optimization techniques are listed below:
Dynamic optimization
The dynamic optimizer changes the execution graph during the execution of a distributed task . Thus, based on the collected statistical data (potentially, even a specially trained model), the optimizer can override the graph. The main techniques for dynamic optimization are listed below:
Dynamic aggregation : data aggregation is one of the most effective ways to reduce the amount of data transferred between nodes. Aggregation occurs in turn at the level of the compute node, rack, and cluster. Such optimization very much depends on the topological location of the node and the aggregated data; therefore, it is most effective to carry it out during execution (that is, dynamically).
Data-dependent partitioning : the optimizer dynamically sets the number of partitions (partitions) in a data set, depending on its size of the input data set. As with Dynamic aggregation, it is precisely possible to estimate the size of the input set only during the execution of a distributed task.
4. Practice
Word count
DryadLINQ offers surprisingly concise syntax for writing queries to data. The following listing is a complete implementation of the calculation in accordance with the map / reduce model:
Listing 1. Implementing the map / reduce programming model.
Listing 2 demonstrates how the implementation of the map / reduce program model presented above is used to create a Dryad word counting task in a certain data source foo.pt (Partitioned Table) stored in a distributed file system.
Listing 2. Word counting with DryadLINQ.
The Dryad framework generates the following execution graph for this application:
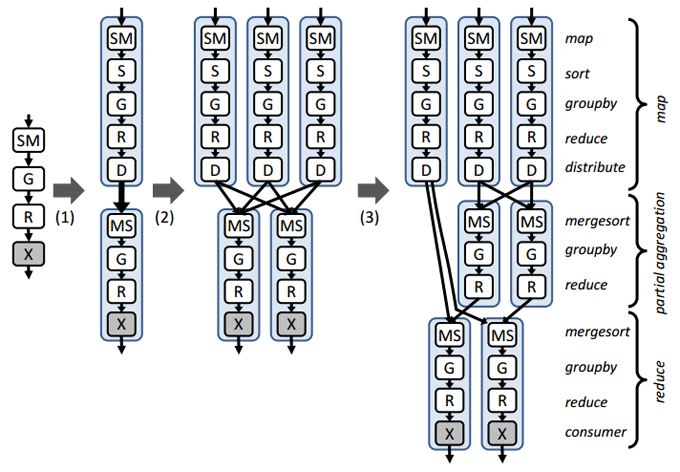
Source of illustration [3].
Moreover, the execution graph in step (2) and (3) is generated dynamically based on information about the amount of data sent between the vertices and the topological location of vertex-operations, processing this data.
PageRank calculation
Listings 3-5 presents the code for the distributed PageRank calculation algorithm.
Listing 3. Implementing the PageRank calculation algorithm [5].
Listing 4. Calculating PageRank using DryadLINQ. Source [5].
Data transfer between different iterations will occur through the in-memory FIFO channel , which guarantees an order of magnitude higher performance than data transmission over the network, as is the case with the implementation of a similar algorithm in Hadoop (this is the latest release version of [plain] Hadoop) .
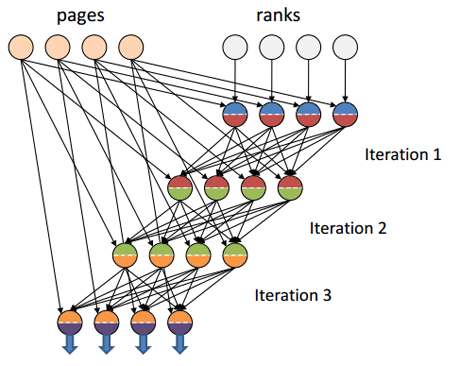
Source of illustration [5]
Addition to the illustration : data transfer between iterations iteration 1> iteration 2> ...> iteration n occurs exclusively through the in-memory channel FIFO.
5. Limitations
The Dryad framework, unlike Hadoop MapReduce, does not confuse the responsibility of executing a distributed application and a programming model / query language with which such applications can be written.
Despite this division of responsibilities, in my opinion, the DryadLINQ software model in itself still mixes responsibilities when it assumes not only direct obligations regarding the interpretation of LINQ expressions in the Dryad program, but also builds EPG graphs of execution and optimizations . The latter will inevitably lead to a longer run time for the Dryad job: more CPU cycles are spent on interpreting the DryadLINQ expression than it would have left with fewer commitments.
As a consequence, the interpretation of the set of DryadLINQ expressions on a single computational node will have a greater negative impact on the task execution time, both at the local level and at the cluster level as a whole. Although I still do not see how the described problem can grow into the problem of scalability of the Dryad cluster as a whole.
Another note relates to a static optimizer, which, in order to effectively apply optimizations, needs to know too much , including the internal "affairs" of the components of the Runtime Runtime - the topology of web sites, the data partitioning scheme.
From the documentation it remains unclear what the statistics are for the dynamic optimizer: after all, the statistics on the number of I / O operations is again the internal data of the execution engine (Dryad runtime), which should not be disclosed at the level of the program model (DryadLINQ).
6. Advantages
Full programming language
Development using modern high-level programming languages, LINQ model with the ability to write queries to data in a functional style.
Strong data typing
The Dryad framework performs calculations on strongly typed data and returns strongly typed collections of objects.
Automatic data serialization
The data is automatically serialized / deserialized by the framework during transmission over channels.
Automatic execution parallelization
DryadLINQ generates a distributed execution plan that runs in a cluster. Improved utilization of multiprocessor compute nodes through the use of PLINQ (Parallel LINQ) for tasks running locally.
Automatic performance optimization
The execution graph is optimized by the special components of the Dryad framework, both during the creation of the execution plan, using optimization policies, and dynamically during execution, relying on statistical data.
Familiar development tools
For writing MPP applications using the DryadLINQ program model, you can use MS Visual Studio, as well as VS features such as: Intellisense, code refactoring, integrated debugging, build, source code management.
100% compatible with the .NET Framework
DryadLINQ can be used with any .NET-library and CLS-compatible programming languages with static typing.
Conclusion
DryadLINQ is a program model familiar to .net developers, perfectly integrated into the existing .NET Framework stack, with expressiveness and brevity inherent in the functional style of writing programs. In addition, the DryadLINQ model provides developers with LINQ-like syntax for writing queries to a distributed data repository, encapsulating the details of the distributed nature of a query, scheduling execution, and its optimization.
List of sources
[1] The DryadLINQ Project . Microsoft Research.
[2] M. Isard and Y. Yu. Distributed data-parallel computing using a high-level programming language . In International Conference on Management of Data (SIGMOD), 2009.
[3] Y. Yu, M. Isard, Fetterly, M. Budiu, U. Erlingsson, PK Gunda, and J. Currey. DryadLINQ: a system for general-purpose distributed data-parallel computing using a high-level language . In Proceedings of the 8th Symposium on Operating Systems Design and Implementation (OSDI), 2008.
[4] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, PK Gunda, J. Currey, Report MSR-TR-2008-74, Microsoft Research, 2008.
[5] Jinyang Li. Dryad / DryadLinq Slides adapted from those of Yuan Yu and Michael Isard , 2009.
The framework is based on the representation of a task as a directed acyclic graph , where the vertices of the graph are programs , and the edges are the channels through which data is transmitted. Also, the Dryad framework ecosystem was reviewed and a detailed overview of the architecture of one of the central components of the framework ecosystem , the execution environment for distributed applications of Dryad, was made.
In this article we will discuss the top-level component of the software stack of the Dryad framework, a query language for the distributed storage DryadLINQ.
')
#region Lyrical digression (about writing motivation)
Yesterday's article about Dryad, I missed one paragraph, which should be written whenever you write something about Microsoft products.
I emphasize: I do not propose , nor do I discourage the use of Dryad in my research projects (since only an academic license is now available). More than this, I repeat that Dryad is an “ internal ” product to all of us a well-knownevil corporation, whose development strategy [of product and evil] Microsoft has the right to decide alone (which is quite fair).
All these facts do not (speak for myself) the study of the ideas and concepts of the Dryad platform are less interesting or less useful for professional development (again for themselves). If you have something different, thenthis is not your business.
For those whoread through the line worries that the article on the comparison with Hadoop open-source projects, and not about DryadLINQ, I hint that the comparison with alternative solutions will be only in the next article .
I emphasize: I do not propose , nor do I discourage the use of Dryad in my research projects (since only an academic license is now available). More than this, I repeat that Dryad is an “ internal ” product to all of us a well-known
All these facts do not (speak for myself) the study of the ideas and concepts of the Dryad platform are less interesting or less useful for professional development (again for themselves). If you have something different, then
For those who
1. General information
For example, it can be used to write the code. That's the beauty of the DryadLINQ programming model.
- Yuan Yu, Principal Researcher, Microsoft Research
DryadLINQ is a high-level query language for data stored in a distributed file system and has an SQL-like syntax. DryadLINQ is based on the .NET Language Integrated Query (LINQ) software model, implements a specific LINQ provider for interacting with the Dryad runtime and provides the developer with an API for writing distributed running LINQ expressions.
Unlike the query languages for the Hadoop platform - HiveQL, Pig Latin - DryadLINQ is not another query language with a specific syntax (necessary for learning). Instead, DryadLINQ is based on well-known .NET developers:
- LINQ unified software model ;
- => as a result - an elegant functional approach for writing queries to data ;
- the .NET Framework object model ;
- MS Visual Studio development environment ;
- higher-level PL , such as C #, F #, or any CLS-compatible language.
Expanding the first paragraph of the above list, it is worth noting that LINQ initially did not contain explicit references to the nature of the data warehouse to which the request is made. And built on the basis of LINQ, API DryadLINQ also
Thus, by minimizing the differences in the syntax for writing a query to a database (on LINQ-to-SQL) or to a distributed file system (on DryadLINQ), the solution to one of the most frequent cases — migration from a database to a database — is greatly simplified. based on a distributed file system.
This is how DryadLINQ is presented to a distributed application developer. Below we talk about the internal implementation of DryadLINQ: about the stages of querying data, components and concepts that underlie DryadLINQ .
2. Stages of implementation
Source of illustration [5]
Step 1. A custom distributed application containing a LINQ expression is running. LINQ expressions are executed deferred (they will not be executed until the data returned by the query will be needed). DryadLINQ expressions are also deferred.
Step 2. When parsing LINQ expressions, the DryadLINQ-specific trigger “ToDryadTable ()” is called. DryadLINQ intercepts this trigger (so at this stage it becomes clear that the request for data will be distributed).
Step 3. DryadLINQ compiles the LINQ expression into the distributed Dryad query plan: the LINQ expression tree expands over subqueries, each of which represents a separate vertex in the future Dryad execution graph; the generation of service data necessary for launching remote vertex operations, generation of the code executed on the vertices, serialization of the necessary data types.
Step 4. DryadLINQ calls application-specific Dryad Job Manager.
Step 5. The Job Manager creates an application execution graph using the plan generated in step 3.
Step 6. Vertex programs are executed on the vertices defined for them.
Step 7. At the end of the execution of the Dryad-task, the result is recorded in the output table (s).
Step 8. The Job Manager returns the result to the node performing the DryadLINQ job and completes.
Step 9. The control is returned to the application that initiated the execution of the DryadLINQ expression. The result of the query is a DryadTable object. DryadTable implements IEnumerable <T>, so the contents of the strongly typed collection of DryadTable can be accessed as normal .NET objects.
3. DryadLINQ compiler
The heart of the query language DryadLINQ is the parallel compiler (parallel compiler) DryadLINQ. If we draw an analogy with the world of the SQL query language, the DryadLINQ compiler can be compared with the DBMS query scheduler / optimizer.
The compiler is responsible for compiling DryadLINQ expressions into a distributed program that runs on a Dryad cluster. The DryadLINQ compiler contains both a static component that generates an execution plan and a dynamic component that allows you to optimize performance based on different policies, changing the execution plan right in runtime.
3.1. Execution Plan Graph
When passing control to the compiler, the latter transforms the LINQ expression into an execution plan graph (Execution Plan Graph, EPG). An EPG is a prototype of a performance graph (that is, not a final plan).
The DryadLINQ optimizer also supplements EPG with metadata that can provide additional information about the distributed task during planning and execution. So for the vertices of the graph is information about the data partitioning scheme , and for the edges of the graph it is the .NET data type and data compression scheme, if any.
3.2. DryadLINQ Optimizations
In turn, DryadLINQ optimizer performs both static optimization based on greedy algorithms (greedy heuristics) and dynamic optimization based on the statistical information collected during the execution.
Static optimization
The main tasks of the static optimizer are two: minimizing the number of I / O operations on disk media and in the network. Which is logical, since traditionally the disk subsystem and interfaces for machine-to-machine interaction are a bottleneck in distributed computing environments.
The most interesting static optimization techniques are listed below:
- Pipelining (interprocess communication): the optimizer tries to localize the calculations as much as possible within a single computing node, if possible;
- I / O reduction : the optimizer tries to use TCP-pipe and in-memory FIFO for data transfer between vertex operations instead of the default data transfer method - writing / reading temporary files to / from the disk (Dryad data channels were discussed in detail in the previous article);
- Removing redundancy : the optimizer removes redundant / unnecessary hash- and range-partitioning steps.
Dynamic optimization
The dynamic optimizer changes the execution graph during the execution of a distributed task . Thus, based on the collected statistical data (potentially, even a specially trained model), the optimizer can override the graph. The main techniques for dynamic optimization are listed below:
Dynamic aggregation : data aggregation is one of the most effective ways to reduce the amount of data transferred between nodes. Aggregation occurs in turn at the level of the compute node, rack, and cluster. Such optimization very much depends on the topological location of the node and the aggregated data; therefore, it is most effective to carry it out during execution (that is, dynamically).
Data-dependent partitioning : the optimizer dynamically sets the number of partitions (partitions) in a data set, depending on its size of the input data set. As with Dynamic aggregation, it is precisely possible to estimate the size of the input set only during the execution of a distributed task.
4. Practice
Word count
DryadLINQ offers surprisingly concise syntax for writing queries to data. The following listing is a complete implementation of the calculation in accordance with the map / reduce model:
Listing 1. Implementing the map / reduce programming model.
public static IQueryable<TResult> MapReduce<TSource, TMap, TKey, TResult>( this IQueryable<TSource> source, Expression<Func<TSource, IEnumerable<TMap>>> mapper, Expression<Func<TMap, TKey>> keySelector, Expression<Func<IGrouping<TKey, TMap>, TResult>> reducer) { return source .SelectMany(mapper) .GroupBy(keySelector) .Select(reducer); } Listing 2 demonstrates how the implementation of the map / reduce program model presented above is used to create a Dryad word counting task in a certain data source foo.pt (Partitioned Table) stored in a distributed file system.
Listing 2. Word counting with DryadLINQ.
const string inputPath = @"file://\\machine\directory\foo.pt"; const string outputPath = @"file://\\machine\directory\count.pt"; PartitionedTable<LineRecord> inputTable = PartitionedTable.Get<LineRecord>(inputPath); var result = inputTable.MapReduce( r => r.Line.Split(' '), // r: rows w => w, // w: words g => new Tuple<string, int>(g.Key, g.Count())); // g: groups result.ToDryadPartitionedTable(outputPath); The Dryad framework generates the following execution graph for this application:
Source of illustration [3].
Moreover, the execution graph in step (2) and (3) is generated dynamically based on information about the amount of data sent between the vertices and the topological location of vertex-operations, processing this data.
PageRank calculation
Listings 3-5 presents the code for the distributed PageRank calculation algorithm.
Listing 3. Implementing the PageRank calculation algorithm [5].
public static IQueryable<Rank> PRStep(IQueryable<Page> pages, IQueryable<Rank> ranks) { // join pages with ranks, and disperse updates var updates = from page in pages join rank in ranks on page.Name equals rank.Name select page.Disperse(rank); // re-accumulate return from list in updates from rank in list group rank.Rank by rank.Name into g select new Rank(g.Key, g.Sum()); } Listing 4. Calculating PageRank using DryadLINQ. Source [5].
const string inputPath = @"dfs://pages.txt"; const string outputPath = @"dfs://outputranks.txt"; var pages = PartitionedTable.Get<Page>(inputPath); var ranks = pages.Select(page => new Rank(page.Name, 1.0)); const int iterationCount = 1000; for (int iter = 0; iter < iterationCount; iter++) ranks = PRStep(pages, ranks); ranks.ToPartitionedTable<Rank>(outputPath); Listing 5. Helper classes. Source [5]
public class Page { public Page(Int64 name, Int64 degreee, Int64[] links) { this.Name = name; this.Degree = degreee; this.Links = links; } public Int64 Name { get; set; } public Int64 Degree { get; set; } public Int64[] Links { get; set; } public Rank[] Disperse(Rank rank) { Rank[] ranks = new Rank[Links.Length]; double score = rank.Value / this.Degree; for (int i = 0; i < ranks.Length; i++) ranks[i] = new Rank(this.Links[i], score); return ranks; } } public class Rank { public Rank(Int64 name, double rank) { this.Name = name; this.Value = rank; } public Int64 Name { get; set; } public double Value { get; set; } } Data transfer between different iterations will occur through the in-memory FIFO channel , which guarantees an order of magnitude higher performance than data transmission over the network, as is the case with the implementation of a similar algorithm in Hadoop (this is the latest release version of [plain] Hadoop) .
Source of illustration [5]
Addition to the illustration : data transfer between iterations iteration 1> iteration 2> ...> iteration n occurs exclusively through the in-memory channel FIFO.
5. Limitations
The Dryad framework, unlike Hadoop MapReduce, does not confuse the responsibility of executing a distributed application and a programming model / query language with which such applications can be written.
Despite this division of responsibilities, in my opinion, the DryadLINQ software model in itself still mixes responsibilities when it assumes not only direct obligations regarding the interpretation of LINQ expressions in the Dryad program, but also builds EPG graphs of execution and optimizations . The latter will inevitably lead to a longer run time for the Dryad job: more CPU cycles are spent on interpreting the DryadLINQ expression than it would have left with fewer commitments.
As a consequence, the interpretation of the set of DryadLINQ expressions on a single computational node will have a greater negative impact on the task execution time, both at the local level and at the cluster level as a whole. Although I still do not see how the described problem can grow into the problem of scalability of the Dryad cluster as a whole.
Another note relates to a static optimizer, which, in order to effectively apply optimizations, needs to know too much , including the internal "affairs" of the components of the Runtime Runtime - the topology of web sites, the data partitioning scheme.
From the documentation it remains unclear what the statistics are for the dynamic optimizer: after all, the statistics on the number of I / O operations is again the internal data of the execution engine (Dryad runtime), which should not be disclosed at the level of the program model (DryadLINQ).
DryadLINQ performs both static and dynamic optimizations. [3]From the passage quoted above, the question immediately arises: why does the dynamic optimization problem fall under the responsibility of DryadLINQ? Indeed, according to the semantics, the dynamic optimizer works already after the final interpretation of the DryadLINQ expression, that is, at the runtime level.
6. Advantages
Full programming language
Development using modern high-level programming languages, LINQ model with the ability to write queries to data in a functional style.
Strong data typing
The Dryad framework performs calculations on strongly typed data and returns strongly typed collections of objects.
Automatic data serialization
The data is automatically serialized / deserialized by the framework during transmission over channels.
Automatic execution parallelization
DryadLINQ generates a distributed execution plan that runs in a cluster. Improved utilization of multiprocessor compute nodes through the use of PLINQ (Parallel LINQ) for tasks running locally.
Automatic performance optimization
The execution graph is optimized by the special components of the Dryad framework, both during the creation of the execution plan, using optimization policies, and dynamically during execution, relying on statistical data.
Familiar development tools
For writing MPP applications using the DryadLINQ program model, you can use MS Visual Studio, as well as VS features such as: Intellisense, code refactoring, integrated debugging, build, source code management.
100% compatible with the .NET Framework
DryadLINQ can be used with any .NET-library and CLS-compatible programming languages with static typing.
Conclusion
DryadLINQ is a program model familiar to .net developers, perfectly integrated into the existing .NET Framework stack, with expressiveness and brevity inherent in the functional style of writing programs. In addition, the DryadLINQ model provides developers with LINQ-like syntax for writing queries to a distributed data repository, encapsulating the details of the distributed nature of a query, scheduling execution, and its optimization.
For those who are bored (or a bonus)
In the third and final part of the cycle, the Dryad framework will be compared with other MPP “tools” - relational DBMS, GPU computing and the Hadoop platform. Therefore, ahead of us are waiting for "fascinating" arguments in the comments on the topic "Windows is buggy" and the fall of karma.
List of sources
[1] The DryadLINQ Project . Microsoft Research.
[2] M. Isard and Y. Yu. Distributed data-parallel computing using a high-level programming language . In International Conference on Management of Data (SIGMOD), 2009.
[3] Y. Yu, M. Isard, Fetterly, M. Budiu, U. Erlingsson, PK Gunda, and J. Currey. DryadLINQ: a system for general-purpose distributed data-parallel computing using a high-level language . In Proceedings of the 8th Symposium on Operating Systems Design and Implementation (OSDI), 2008.
[4] Y. Yu, M. Isard, D. Fetterly, M. Budiu, U. Erlingsson, PK Gunda, J. Currey, Report MSR-TR-2008-74, Microsoft Research, 2008.
[5] Jinyang Li. Dryad / DryadLinq Slides adapted from those of Yuan Yu and Michael Isard , 2009.
Source: https://habr.com/ru/post/182282/
All Articles