Dryad. Distributed Computing Framework
Imagine a general purpose framework for distributed execution of applications with the following statistics *:

* Statistics for 2011.
Now imagine that this is not Hadoop.
')
It’s about what the framework is, about the ideas and concepts that underlie it, and why this framework is even more innovative (subjective) than Hadoop will be discussed below.
1. Dryad. General information
Dryad is a general purpose software framework for distributed application execution . Dryad is a project of Microsoft Research . The central concept of the Dryad project is the construction of a directed acyclic graph (directed acyclic graph, DAG) for each distributed task. The vertices of the graph are operations on the data (in fact, programs), and the edges of the graph are the channels through which data is transmitted.
Abstraction based on a directed acyclic graph model makes it possible to effectively implement the execution plans of a large number of parallel algorithms , iterative algorithms , machine learning algorithms. Thus, the only (before the appearance of YARN ) program map / reduce model implemented in Hadoop ** is, in essence, only a special case of the distributed computation model provided by Dryad .
Dryad is optimized for running on a medium or large computing cluster (from 100 to 10K computing nodes) and is aimed mainly at long batch tasks that do not require frequent interactions.
2004 ... 2008
Attempts to deal with the past, present and future of Dryad led me to a rather limited number of articles, the authors of which, referring to and not to the original sources, argue that:
2008 ... 2009
One of the fundamental documents describing the concepts laid down in Dryad won the Best Paper award at OSDI'08 (USENIX Symposium on Operating Systems Design and Implementation).
In November 2009, Dryad became available under an academic license .
2010 ... 2011
In 2011, the Windows HPC Team announced the beta version of LINQ to HPC (Dryad for Windows HPC Server) for the corresponding Windows OS line. In the same year, it was announced that LINQ to HPC "will not be released" from the preview version (that is, in fact, about the termination of support).
It is worth noting that the Windows HPC Team did not say anything (and could not say in principle) about the support / development of the Dryad Project. There were no other statements about the further support of Dryad or, on the contrary, an unambiguous refusal of support during the past (2012) and this year.
2. Dryad Ecosystem

The Dryad project consists of 3 key components:
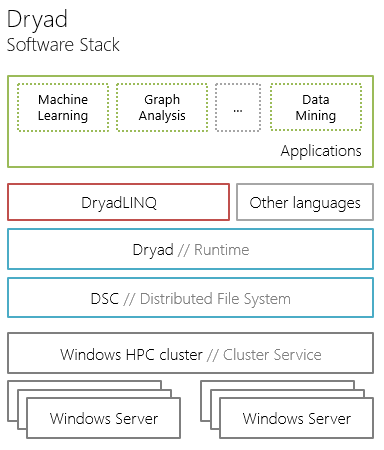
Below we take a closer look at the elements of the Dryad ecosystem: the Dryad runtime and the DryadLINQ query language.
3. Dryad Runtime
Dryad runtime is a distributed application execution environment , like Hadoop, taking on such functions as:
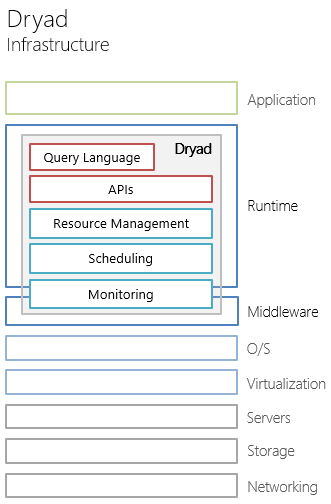
The task in the Dryad runtime is a directed acyclic graph , where the vertices are programs , and the edges of the graph are data channels . This logical graph is reflected (mapped) by the executable medium on the physical resources in the cluster. In general, the case of the number of vertices in the graph exceeds the number of physical computing nodes in the cluster.

3.1. Data feeds
Data channels, as well as vertices, are abstractions and are represented by:
The need to disclose information about the physical resources of the cluster for the most efficient execution of a distributed task makes the channel abstraction not as “clean” as it seems at first glance. Nevertheless, the developer of a distributed application "does not see" a violation of the abstraction "channel", since it hides under other levels (task manager), which will be discussed below.
Dryad's data model is a shared-nothing architecture . The advantages of this architecture traditionally include scalability , no need to support tracking changes , the implementation of complex transactions , the use of synchronization primitives . The Dryad platform is well suited for large static volumes of data and is not suitable for frequently changing or streaming data.
Dryad expects to get an immutable (immutable) and a finite amount of input data. The results of the distributed program will not be available until all the subroutines are executed. It is logical to assume that tasks with streaming data are fundamentally impracticable in Dryad.
3.3. Job manager
The job manager Job Manager (JM) is engaged in orchestrating the Dryad job. Job Manager contains application-specific code for creating a task calculation graph.
Job Manager is responsible for:
Application data is sent directly from the vertex operation to the vertex operation. Job Manager is responsible only for initialization, planning and monitoring the execution of distributed tasks. Therefore, JM is not an application bottleneck . In addition, during transfer, the code of a vertex operation can be either sent from the Job Manager or from the nearest computational node on which the similar vertex operation is performed.
3.4. Name Server. Daemon
Name Server Name Server is responsible for disclosing information about available compute nodes and their topological location in the cluster.
A Daemon process is launched on each compute node, the main purpose of which is to run vertex operations sent by Job Manager. Daemon acts as a proxy object, so Job Manager has the ability to find out the status and stage of a vertex operation executed by a remote Daemon.
The Dryad architecture and place in this architecture are Job Manager , Name Server (NS) and Daemon (PD) below.
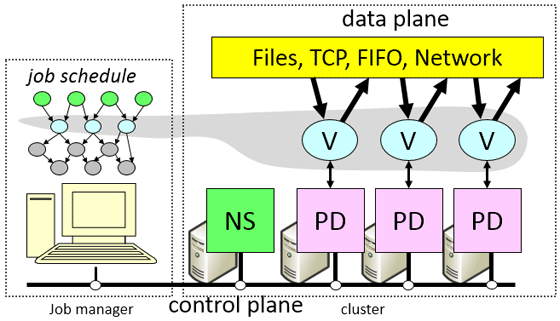
Source of illustration [3]
( Explanation of the illustration : JM initializes the execution graph, based on the data on the available nodes and their location, obtained from NS. JM controls the execution of the graph, I get the status from the PD. PD exchange data on the available channels to bypass the NS and JM. Shaded area in the illustration demonstrates operations performed at the current time.)
3.5. Dynamic graph change
Job Manager, like JobTracker in Hadoop, performs static performance optimization . But unlike Hadoop, Dryad has the ability to dynamically optimize performance .
Due to Dryad's central concept of a directed acyclic graph and support for the callback mechanism (the callback informs JM about the change in the execution stage of a vertex operation), the execution graph can be changed during execution (runtime). Dynamic change allows you to quite elegantly solve the following tasks:
In addition, due to the dynamic change of the graph during execution and the abstraction of the concept of “channel” from a specific data transfer method, it is important (i.e. it is possible to implement if not implemented) the data can be reached not only from the node where the data is physically stored , but also:
As previously mentioned, Daemon is a proxy, so the Job Manager has the ability to find out the status and stage of a vertex operation performed by a remote Daemon. If Daemon “fell”, then Job Manager will know about it:
After diagnosing a PD failure, the operation performed on it is re-executed on another Daemon.

In the Dryad documentation, I did not find information about what would happen if the Name Server crashed. It is reasonable to assume that in the absence of a heartbeat from the NS process, the Job Manager will restart the NS on another node. For idle time, the Name Server part of the computing power of the cluster, for the disclosure of information about which the NS is responsible, will simply “fall out”.
It was also not clear from the documentation what measures were taken to prevent the Job Manager from becoming a single point of failure. In the event that each distributed application has its own Job Manager, stopping the Job Manager will not cause downtime of the whole cluster, as is the case with Hadoop if Name Node fails.
But the presence of separate JM processes for each of the distributed applications immediately presents 2 problems:
4. Practice
Dryad is available for free under an academic license [4]. To run the framework, you need a Windows HPC cluster with Microsoft HPC Pack 2008 SP1, 4 Gb RAM, 1Gb Ethernet and 200 Gb of free space on each node of the cluster [1].
Applications for Dryad can be written both in C ++ and C # (it is reasonable to assume that any CLS-compatible language will do).
The instruction for the distributed execution of the operation for Dryad is as follows (InitialReduce, Combine, Initialize, Iterate, Merge are the names of the functions responsible for the corresponding stages of the distributed execution; the examples in the listings consider the arithmetic average):
The query language DryadLINQ encapsulates the complexity of the code, so, in general, the application developer does not have to write the constructions given in the listings. DryadLINQ will be discussed in the next article in this series.
5. Limitations and limitations
In conclusion, we will look at the limitations of Dryad and the “wrong” expectations, associated primarily with the incorrect representation of the purpose of this class of software.
One of the main limitations of Dryad is the complexity of adaptation for working in realtime mode and, probably, the fundamental impossibility of working with streaming data . It should also be added that the Dryad framework will show good performance for batch tasks, but the use of Drayd will not be justified for random-access operations. Additionally, I will note a potential problem with a single point of failure [at the application level] when Job Manager’s job manager “crashes” (perhaps there is no such point of failure, but it is not clear from the documentation how this problem is solved).
You also need to understand that Dryad is only a distributed computing framework , so you should not expect from Dryad:
The rest of Dryad is a powerful and flexible abstraction for a distributed application developer. The platform is an extremely organic symbiosis of modern concepts and ideas about the development of parallel software, providing familiar PL and elegant solutions to problems that often occur (and rarely solve) the framework of distributed computing .
List of sources
[1] The Dryad Project . Microsoft Research.
[2] Y. Yu, PK Gunda, M. Isard. Distributed Aggregation for Data-Parallel Computing: Interfaces and Implementations , 2009.
[3] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: Distributed data-parallel programs from sequential building blocks .
In Proceedings of the European Conference on Computer Systems (EuroSys), 2007.
[4] Dryad and DryadLINQ Academic Release . Microsoft Research.
* Sorted alphabetically.
** Comparison in the article takes place exclusively with the 1st version of the Hadoop platform (i.e., without YARN). A detailed comparison of Dryad with the DBMS, GPU computing and the Hadoop framework will be made in the final article of the Dryad series .
* Statistics for 2011.
Now imagine that this is not Hadoop.
')
It’s about what the framework is, about the ideas and concepts that underlie it, and why this framework is even more innovative (subjective) than Hadoop will be discussed below.
1. Dryad. General information
Dryad is a general purpose software framework for distributed application execution . Dryad is a project of Microsoft Research . The central concept of the Dryad project is the construction of a directed acyclic graph (directed acyclic graph, DAG) for each distributed task. The vertices of the graph are operations on the data (in fact, programs), and the edges of the graph are the channels through which data is transmitted.
Abstraction based on a directed acyclic graph model makes it possible to effectively implement the execution plans of a large number of parallel algorithms , iterative algorithms , machine learning algorithms. Thus, the only (before the appearance of YARN ) program map / reduce model implemented in Hadoop ** is, in essence, only a special case of the distributed computation model provided by Dryad .
Dryad is optimized for running on a medium or large computing cluster (from 100 to 10K computing nodes) and is aimed mainly at long batch tasks that do not require frequent interactions.
2004 ... 2008
Attempts to deal with the past, present and future of Dryad led me to a rather limited number of articles, the authors of which, referring to and not to the original sources, argue that:
- the idea of building such a system appeared in 2004 (analogy with Google MapReduce) from Michael Isard (later he took the position of a researcher at Microsoft);
- In 2006, Dryad presented Bill Gates himself at one of the Computer Science conferences;
- Dryad is adapted and used in Bing, Microsoft AdCenter,
Kinect, Windows HPC Server 2008 R2 (the latter is known reliably).
2008 ... 2009
One of the fundamental documents describing the concepts laid down in Dryad won the Best Paper award at OSDI'08 (USENIX Symposium on Operating Systems Design and Implementation).
In November 2009, Dryad became available under an academic license .
2010 ... 2011
In 2011, the Windows HPC Team announced the beta version of LINQ to HPC (Dryad for Windows HPC Server) for the corresponding Windows OS line. In the same year, it was announced that LINQ to HPC "will not be released" from the preview version (that is, in fact, about the termination of support).
2012 ... 2013 / UPD /
It is worth noting that the Windows HPC Team did not say anything (and could not say in principle) about the support / development of the Dryad Project. There were no other statements about the further support of Dryad or, on the contrary, an unambiguous refusal of support during the past (2012) and this year.
2. Dryad Ecosystem
The Dryad project consists of 3 key components:
- Dryad - runtime (runtime) of distributed applications (hereinafter, in order to avoid ambiguity, we will call this component Dryad Runtime);
- DryadLINQ is a high-level query language based on the .NET Language Integrated programming model.
Query (LINQ); - Distributed Storage Catalog (DSC) is a distributed file system with configurable redundancy.
Below we take a closer look at the elements of the Dryad ecosystem: the Dryad runtime and the DryadLINQ query language.
3. Dryad Runtime
Dryad runtime is a distributed application execution environment , like Hadoop, taking on such functions as:
- planning and management of distributed tasks;
- resource management;
- fault tolerance;
- monitoring.
The task in the Dryad runtime is a directed acyclic graph , where the vertices are programs , and the edges of the graph are data channels . This logical graph is reflected (mapped) by the executable medium on the physical resources in the cluster. In general, the case of the number of vertices in the graph exceeds the number of physical computing nodes in the cluster.
3.1. Data feeds
Data channels, as well as vertices, are abstractions and are represented by:
- Shared-memory FIFO (intra-machine): the fastest way to exchange data between operations (graph vertices), but operations must be performed within a single computing node;
- TCP pipes (inter-machine): channel that does not require access to the disk (we avoid the overhead associated with writing / reading data from the disk); the channel can only be used if the operations between which the data is transmitted are available at the time of transmission;
- SMB / NTFS files (temporary files): output sent over the channel is recorded
to disk, input data is read; default channel.
The need to disclose information about the physical resources of the cluster for the most efficient execution of a distributed task makes the channel abstraction not as “clean” as it seems at first glance. Nevertheless, the developer of a distributed application "does not see" a violation of the abstraction "channel", since it hides under other levels (task manager), which will be discussed below.
3.2. Data model
Dryad's data model is a shared-nothing architecture . The advantages of this architecture traditionally include scalability , no need to support tracking changes , the implementation of complex transactions , the use of synchronization primitives . The Dryad platform is well suited for large static volumes of data and is not suitable for frequently changing or streaming data.
Dryad expects to get an immutable (immutable) and a finite amount of input data. The results of the distributed program will not be available until all the subroutines are executed. It is logical to assume that tasks with streaming data are fundamentally impracticable in Dryad.
3.3. Job manager
The job manager Job Manager (JM) is engaged in orchestrating the Dryad job. Job Manager contains application-specific code for creating a task calculation graph.
Job Manager is responsible for:
- initialization of the calculation graph ;
- planning operations (vertices, hereinafter - vertex-operations) so that the physical hardware associated with these vertices is located topologically as close as possible to the data processed by these vertices;
- fault tolerance ;
- performance monitoring and statistics collection ;
- Dynamic transformation of the graph in accordance with existing policies.
Application data is sent directly from the vertex operation to the vertex operation. Job Manager is responsible only for initialization, planning and monitoring the execution of distributed tasks. Therefore, JM is not an application bottleneck . In addition, during transfer, the code of a vertex operation can be either sent from the Job Manager or from the nearest computational node on which the similar vertex operation is performed.
3.4. Name Server. Daemon
Name Server Name Server is responsible for disclosing information about available compute nodes and their topological location in the cluster.
A Daemon process is launched on each compute node, the main purpose of which is to run vertex operations sent by Job Manager. Daemon acts as a proxy object, so Job Manager has the ability to find out the status and stage of a vertex operation executed by a remote Daemon.
The Dryad architecture and place in this architecture are Job Manager , Name Server (NS) and Daemon (PD) below.
Source of illustration [3]
( Explanation of the illustration : JM initializes the execution graph, based on the data on the available nodes and their location, obtained from NS. JM controls the execution of the graph, I get the status from the PD. PD exchange data on the available channels to bypass the NS and JM. Shaded area in the illustration demonstrates operations performed at the current time.)
3.5. Dynamic graph change
Job Manager, like JobTracker in Hadoop, performs static performance optimization . But unlike Hadoop, Dryad has the ability to dynamically optimize performance .
Due to Dryad's central concept of a directed acyclic graph and support for the callback mechanism (the callback informs JM about the change in the execution stage of a vertex operation), the execution graph can be changed during execution (runtime). Dynamic change allows you to quite elegantly solve the following tasks:
- degradation of network bandwidth , when several nodes need to transfer data to the input of another node (in Hadoop, this degradation occurs when data is sent between the Combine and Reduce stages);
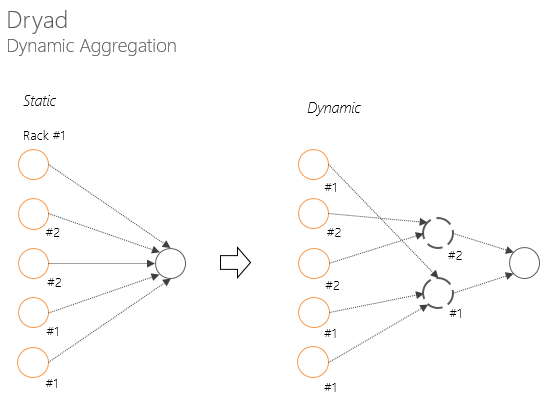
- simple computational nodes to wait for the completion of "slow" operations (in Hadoop, convolution cannot start until all map tasks are completed, which leads to map slot idle time and makes the best execution time of the program equal to the execution time of the slowest map- tasks).

In addition, due to the dynamic change of the graph during execution and the abstraction of the concept of “channel” from a specific data transfer method, it is important (i.e. it is possible to implement if not implemented) the data can be reached not only from the node where the data is physically stored , but also:
- One Daemon can save a temporary file with intermediate results in a rack local to a vertex operation that accepts this data as input;
- One Daemon can store data in the RAM of a node if a vertex operation that accepts this data as input is running on the same compute node.
3.6. Fault tolerance
As previously mentioned, Daemon is a proxy, so the Job Manager has the ability to find out the status and stage of a vertex operation performed by a remote Daemon. If Daemon “fell”, then Job Manager will know about it:
- an error message that Daemon sent to JM before closing its own process;
- overdue time for a heartbeat message if, when Daemon closed, no diagnostic events were sent to JM.
After diagnosing a PD failure, the operation performed on it is re-executed on another Daemon.
In the Dryad documentation, I did not find information about what would happen if the Name Server crashed. It is reasonable to assume that in the absence of a heartbeat from the NS process, the Job Manager will restart the NS on another node. For idle time, the Name Server part of the computing power of the cluster, for the disclosure of information about which the NS is responsible, will simply “fall out”.
It was also not clear from the documentation what measures were taken to prevent the Job Manager from becoming a single point of failure. In the event that each distributed application has its own Job Manager, stopping the Job Manager will not cause downtime of the whole cluster, as is the case with Hadoop if Name Node fails.
But the presence of separate JM processes for each of the distributed applications immediately presents 2 problems:
- time costs for initial initialization of Job Manager;
- the problem of resource sharing, the Job Manager cannot “adequately” estimate the amount of free resources (CPU, RAM, bandwidth), since does not know how many more JM processes are serviced by this physical computing node.
4. Practice
Dryad is available for free under an academic license [4]. To run the framework, you need a Windows HPC cluster with Microsoft HPC Pack 2008 SP1, 4 Gb RAM, 1Gb Ethernet and 200 Gb of free space on each node of the cluster [1].
Applications for Dryad can be written both in C ++ and C # (it is reasonable to assume that any CLS-compatible language will do).
The instruction for the distributed execution of the operation for Dryad is as follows (InitialReduce, Combine, Initialize, Iterate, Merge are the names of the functions responsible for the corresponding stages of the distributed execution; the examples in the listings consider the arithmetic average):
///<summary>For iterator-based implementation</summary> [AssociativeDecomposable("InitialReduce", "Combine")] public static TOutput H(IEnumerable<TInput> source) { … } Listing 1. Iterator-based implementation example. Source [2].
public static double Average(IEnumerable<int> g) { IntPair final = g.Aggregate(x => PartialSum(x)); if (final.second == 0) return 0.0; return (double)final.first / (double)final.second; } [AssociativeDecomposable("InitialReduce", "Combine")] public static IntPair PartialSum(IEnumerable<int> g) { return InitialReduce(g); } public static IntPair InitialReduce(IEnumerable<int> g) { return new IntPair(g.Sum(), g.Count()); } public static IntPair Combine(IEnumerable<IntPair> g) { return new IntPair(g.Select(x => x.first).Sum(), g.Select(x => x.second).Sum()); } ///<summary>For accumulator-based implementation</summary> [AssociativeDecomposable("Initialize", "Iterate", "Merge")] public static TOutput H(IEnumerable<TInput> source) { … } Listing 2. Accumulator-based implementation example. Source [2].
public static double Average(IEnumerable<int> g) { IntPair final = g.Aggregate(x => PartialSum(x)); if (final.second == 0) return 0.0; else return (double)final.first / (double)final.second } [AssociativeDecomposable("Initialize", "Iterate", "Merge")] public static IntPair PartialSum(IEnumerable<int> g) { return new IntPair(g.Sum(), g.Count()); } public static IntPair Initialize() { return new IntPair(0, 0); } public static IntPair Iterate(IntPair x, int r) { x.first += r; x.second += 1; return x; } public static IntPair Merge(IntPair x, IntPair o) { x.first += o.first; x.second += o.second; return x; } The query language DryadLINQ encapsulates the complexity of the code, so, in general, the application developer does not have to write the constructions given in the listings. DryadLINQ will be discussed in the next article in this series.
5. Limitations and limitations
In conclusion, we will look at the limitations of Dryad and the “wrong” expectations, associated primarily with the incorrect representation of the purpose of this class of software.
One of the main limitations of Dryad is the complexity of adaptation for working in realtime mode and, probably, the fundamental impossibility of working with streaming data . It should also be added that the Dryad framework will show good performance for batch tasks, but the use of Drayd will not be justified for random-access operations. Additionally, I will note a potential problem with a single point of failure [at the application level] when Job Manager’s job manager “crashes” (perhaps there is no such point of failure, but it is not clear from the documentation how this problem is solved).
You also need to understand that Dryad is only a distributed computing framework , so you should not expect from Dryad:
- transaction support , because it is not a RDBMS;
- performance comparable to GPU computing , because Dryad solves a fundamentally wider class of problems with fundamentally different tools;
- Open source license because it is
Microsoftinitially a different type of product (but there is still free access under an academic license); - Rapid development of distributed applications that work within the map / reduce paradigm, because Dryad is not Hadoop: the map / reduce model is only a special case for Dryad, while for Hadoop it is the only possible execution model.
Conclusion
The rest of Dryad is a powerful and flexible abstraction for a distributed application developer. The platform is an extremely organic symbiosis of modern concepts and ideas about the development of parallel software, providing familiar PL and elegant solutions to problems that often occur (and rarely solve) the framework of distributed computing .
List of sources
[1] The Dryad Project . Microsoft Research.
[2] Y. Yu, PK Gunda, M. Isard. Distributed Aggregation for Data-Parallel Computing: Interfaces and Implementations , 2009.
[3] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: Distributed data-parallel programs from sequential building blocks .
In Proceedings of the European Conference on Computer Systems (EuroSys), 2007.
[4] Dryad and DryadLINQ Academic Release . Microsoft Research.
* Sorted alphabetically.
** Comparison in the article takes place exclusively with the 1st version of the Hadoop platform (i.e., without YARN). A detailed comparison of Dryad with the DBMS, GPU computing and the Hadoop framework will be made in the final article of the Dryad series .
Source: https://habr.com/ru/post/182164/
All Articles