Journey through the processor's computing pipeline
 Since the career of a programmer is closely related to the processor, it would be nice to know how it works.
Since the career of a programmer is closely related to the processor, it would be nice to know how it works.What happens inside the processor? How long does it take to execute one instruction? What does it mean when a new processor has a 12, or 18, or even a 31-level pipeline?
Programs usually work with a processor, as with a black box. Instructions enter and exit from it in order, and inside there is some computational magic.
')
It is useful for the programmer to know what is going on inside this box, especially if he will be engaged in the optimization of programs. If you do not know what processes are taking place inside the processor, how can you optimize for it?
This article describes the structure of the x86 processor's computing pipeline.
Things you should already know
First, it is assumed that you know a little about programming or may even know a little assembler. If you don’t understand what I mean when I use the term “instruction pointer”, then perhaps this article is not for you. When I write about registers, instructions and caches, I assume that you already know what it means, you can understand or google.
Secondly, this article is a simplification of a complex topic. If it seems to you that I missed some important points, welcome to the comments.
Thirdly, I focus only on the Intel x86 processor family. I know about the existence of other processor families besides x86. I know that AMD has made many useful innovations in the x86 family, and Intel has adopted them. But the architecture and the instruction set belong to Intel, and Intel also presented the implementation of the most important features of the family, so for simplicity and consistency, it will be about their processors.
Fourth, this article is already outdated. In the development of newer processors, and some of them are expected to be available soon. I am very pleased that technologies are developing at such a rapid pace and I hope that someday all the stages described below will completely become obsolete and will be replaced by even more amazing advances in processor design.
Basics of the computing pipeline
If you look at the x86 family as a whole, you can see that it has not changed much in 35 years. There were many additions, but the original design, like almost the entire set of commands, mostly remained intact and can still be seen in modern processors.
The original 8086 processor has 14 registers that are still in use. The four general purpose registers are AX, BX, CX and DX. Four segment registers that are used to facilitate work with pointers - CS (Code Segment), DS (Data Segment), ES (Extra Segment) and SS (Stack Segment). Four index registers that indicate different addresses in memory - SI (Source Index), DI (Destination Index), BP (Base Pointer) and SP (Stack Pointer). One register contains bit flags. And finally, the most important register in this article is IP (Instruction Pointer).
An IP register is a pointer with a special function, its task is to point to the next instruction that is to be executed.
All processors in the x86 family follow the same principle. First, they follow the instruction pointer and decode the next command at that address. After decoding, this is followed by the step of performing this instruction. Some instructions are read from or written to memory, others produce calculations, comparisons, or other work. When the work is finished, the team goes through the retirement stage (retirement stage) and the IP starts pointing to the next instruction.
This principle of decoding, execution and resignation is equally applied in both the first 8086 processor and the latest Core i7. Over time, new stages of the pipeline were added, but the principle of operation remained the same.
What has changed in 35 years
The first processors were simple by today's standards. The 8086 processor started by checking the command on the current pointer to the instruction, decoded it, executed it, dropped it and continued to work with the following instruction to which the IP indicated.
Each new chip in the family adds new functionality. Most added new instructions, some added new registers. To stay within the scope of this article, I will pay attention to changes that directly affect the passage of commands through the CPU. Other changes, such as adding virtual memory or parallel processing, are of course interesting, but beyond the scope of this article.
In 1982, the instruction cache was entered. Instead of accessing the memory on each instruction, the processor read several bytes past the current IP. The instruction cache was only a few bytes in size, sufficient to store only a few commands, but significantly increased performance, eliminating constant memory accesses every few clock cycles.
In 1985, the data cache was added to the 386 processor and the size of the instruction cache was increased. This step allowed to increase productivity by reading a few bytes beyond the request for data. At that time, data and instruction caches were measured in kilobytes, rather than in bytes.
In 1989, the i486 processor switched to a 5-level pipeline. Instead of having one instruction in the entire processor, now each level of the pipeline could have instructions. This innovation made it possible to more than double the performance compared to the 386 processor at that frequency. The fetch stage retrieved a command from the instruction cache (the cache size at that time was usually 8kb). The second stage decoded the instruction. The third stage transmitted the memory and offset addresses needed for the command. The fourth stage fulfilled the instruction. The fifth stage sent the team to resign and write the results back to the registers and memory as needed. The appearance of the ability to hold multiple instructions in a processor at the same time allowed programs to run much faster.
1993 was the year of the Pentium processor. The name of the processor family was changed from numbers to names because of the trial, so it was named Pentium instead of 586. The chip conveyor changed even more compared to i486. The Pentium architecture added a second separate superscalar pipeline. The main pipeline worked the same way as on i486, while the second followed simpler instructions, such as integer arithmetic, in parallel and much faster.
In 1995, Intel released the Pentium Pro processor, which had dramatic changes in design. The chip has several features, including a core with an out-of-order (Out-of-Order, OOO) and pre-emptive (Speculative) execution of commands. The conveyor was extended to 12 stages, and it included something called a super-pipeline (superpipeline), where a large number of instructions could be executed simultaneously. OOO core will be covered in more detail later in the article.
Between 1995, when OOO OOO core was introduced, and 2002 many important changes were made. Additional registers were added and instructions were provided that could process multiple data at once (Single Instruction Multiple Data, SIMD). New caches appeared, old ones increased in size. The stages of the pipeline were divided and united, adapting to the requirements of the real world. These and many other changes were important for overall performance, but did not matter much when it came to data flow through the processor.
In 2002, Pentium 4 introduced a new technology - Hyper-Threading. The OOO kernel was so successful in processing commands that it was able to process instructions faster than they could be sent to the kernel. For most LLC users, the processor core was practically inactive most of the time, even under load. To ensure a constant flow of instructions to the OOO core, a second front-end was added. The operating system saw two processors instead of one. The processor contained two sets of x86 registers, two decoder instructions, which monitored two sets of IP and processed two sets of instructions. Further, the commands were processed by one common OOO core, but this was imperceptible for programs. Then the instructions went through the resignation stage, as before, and were sent back to the virtual processors to which they arrived.
In 2006, Intel released the Core micro-architecture. For marketing purposes, it was called Core 2 (because everyone knows that two is better than one). An unexpected move was to reduce the frequency of processors and the rejection of Hyper-Threading. The reduction of frequencies contributed to the expansion of all stages of the computing pipeline. OOO core has been expanded, caches and buffers have been increased. The processor architecture has been redesigned with a bias on dual- and quad-core chips with shared caches.
In 2008, Intel introduced the naming scheme for its Core i3, Core i5, and Core i7 processors. Hyper-Threading with a common OOO core reappeared in these processors, and they differed mainly in cache sizes only.
Future processors: The next microarchitecture update, called Haswell, is rumored to be released in the second half of 2013. Currently published documents show that this will be a 14-level pipeline, and, most likely, the principle of information processing will also follow the design Pentium Pro.
So what is this computing pipeline, what is OOO OOO core and how does all this increase processing speed?
Processor computing pipeline
In the simplest form described above, a single instruction enters the processor, is processed and exits from the other side. This is quite intuitive for most programmers.
The i486 processor had a 5-level pipeline — load (Fetch), basic decoding (D1), secondary decoding or translation (D2), execution (EX), writing the result to the registers and memory (WB). Each stage of the pipeline could contain the instructions.

Conveyor i486 and five instructions passing through it simultaneously.
However, this scheme had a serious drawback. Imagine the code below. Before the arrival of the pipeline, the next three lines of code were a common way to change the values of two variables without using the third.
XOR a, b XOR b, a XOR a, b Chips from 8086 until 386 did not have an internal conveyor. They processed only one instruction at a time, independently and completely. Three consecutive XOR instructions in such an architecture are not at all a problem.
Now let's think about what happens with the i486, since it was the first x86 chip with a pipeline. Watching many things in motion at the same time can be difficult, so you may find it helpful to refer to the diagram above.
The first instruction is included in the boot phase, the first step is complete. The next step is the first instruction is included in the D1 stage, the second instruction is placed in the loading stage. The third step - the first instruction moves to the D2 stage, the second one to the D1 and the third one is loaded into the Fetch. At the next step, something goes wrong - the first instruction goes to EX ..., but the rest remain in place. The decoder stops because the second XOR command requires the result of the first. The variable "a" should be used in the second instruction, but it will not be written to it until the first instruction has been executed. Therefore, teams in the pipeline are waiting until the first team passes the EX and WB stages. Only after that the second instruction can continue its way along the pipeline. The third team will likewise get stuck waiting for the second team to complete.
This phenomenon is called a pipeline stall or pipeline bubble.
Another problem with pipelines is the ability of some instructions to run very quickly, and others very slowly, which was more noticeable with the dual Pentium pipeline.
Pentium Pro introduced a 12-level pipeline. When this number was first announced, programmers who understood how a superscalar pipeline worked, held their breath. If Intel followed the same principle with a 12-level pipeline, then any pipeline stupor or slow instruction would seriously affect performance. But at the same time, Intel announced a radically different pipeline, called the core with an extraordinary execution (OOO core). Despite the fact that it was difficult to understand from the documentation, Intel assured the developers that they would be shocked by the results.
Let's disassemble OOO core in more detail.
OOO conveyor
In the case of the OOO core, an illustration is worth a thousand words. So let's see some pictures.
CPU pipeline diagrams
The i486 5-level pipeline worked fine. This idea was quite common among other processor families at the time and worked perfectly in real-world conditions.

Superscalar conveyor i486.
The Pentium pipeline was even better than the i486. It had two compute lines that could run in parallel, and each of them could contain many instructions at various stages, allowing you to process almost two more instructions at the same time.

Two parallel superscalar pipelines Pentium.
However, the presence of fast commands waiting for the execution of slow ones was still a problem in parallel pipelines, as was the presence of consecutive commands (hello stupor). Conveyors were still linear and could face insurmountable performance limitations.
The OOO OOO core design was very different from previous chips with linear paths. The complexity of the pipeline has increased, and non-linear paths have been introduced.

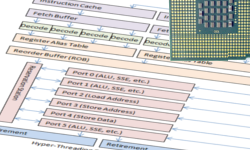
OOO core used since 1995. The color designation corresponds to the five stages used in previous processors. Some steps and buffers are not shown, as they vary from processor to processor.
First, the instructions are loaded from memory and placed in the processor instruction cache. A modern processor decoder can predict the appearance of fast branching (for example, a function call) and start downloading instructions in advance.
The decoding stage has been slightly modified compared to earlier chips. Instead of processing only one instruction per IP, the Pentium Pro could decode up to three instructions per clock. Today's processors (2008-2013) can decode up to four instructions per clock. The result of the decoding are micro-operations (micro-ops / µ-ops).
The next stage (or a group of stages) consists of the translation of micro-operations (micro-op transaltion) and the subsequent assignment of aliases to registers (register aliasing). Many operations are performed simultaneously, possibly out of turn, so one instruction can read from the register while the other writes to it. Writing to the register can suppress the value needed by another instruction. The original registers inside the processor (AX, BX, CX, DX, etc.) are translated (or aliases are created) into internal registers hidden from the programmer. The value of the registers and memory addresses must then be bound to temporary values for processing. At the moment, 4 micro-operations can go through a broadcast stage per clock.
After the broadcast, all micro-operations are included in the reorder buffer (ROB). At the moment, this buffer can hold up to 128 micro-operations. On HT processors, ROB can also act as input command coordinator from virtual processors, distributing two instruction flows to one OOO core.
Now micro-operations are ready for processing and are placed on a reservation (reservation station, RS). RS currently can hold 36 micro-operations at any time.
Now it's time for the OOO core magic. Microoperations are processed simultaneously on a set of execution units (execution unit), with each unit running as fast as possible. Micro-operations can be processed out of turn, if all the necessary data for this are already available. If data is not available, execution is postponed until they are ready, while other ready-made micro-operations are performed. Thus, long operations do not block fast and the consequences of the stupor of the conveyor are not so sad.
OOO Pentium Pro's core had six execution units: two for working with integers, one for floating point numbers, a boot block, an address storage block, and a data storage block. Two integer blocks were specialized, one could work with complex operations, the other could handle two simple operations at a time. Under ideal conditions, Pentium Pro execution units could process seven micro-operations per clock.
Today's OOO core also contains six execution units. It still contains blocks for loading an address, saving an address, and saving data. However, the other three have changed a bit. Each of the three blocks can now perform simple mathematical operations or a more complex micro-operation. Each of the three blocks is specialized for specific micro-operations, allowing you to perform work faster compared to general-purpose blocks. Under ideal conditions, the current OOO core can process 11 micro-operations per clock.
Finally, the microoperation starts. It goes through smaller stages (different between processors) and goes through a retirement stage. At this point, the micro-operation returns to the outside world and the IP starts pointing to the next instruction. From the point of view of the program, the instruction simply enters the processor and exits on the other hand, just as it did with the old 8086.
If you carefully read the article, you might have noticed a very important problem in the description above. What happens if the place of performance changes? For example, what happens if the code reaches the if or switch constructs? In older processors, this meant dropping all the work in the superscalar pipeline and waiting for the start of processing a new branch of execution.
The stupor of the pipeline, when there are a hundred or more instructions in the processor, seriously affects the performance. Each instruction has to wait until the instructions from the new address are loaded and the pipeline is restarted. In this situation, the OOO core must cancel all current work, roll back to the previous state, wait until all microoperations have been resigned, discard them along with the results and then continue working at the new address. This problem was very serious and often happened during the design. Performance indicators in this situation were unacceptable for engineers. This is where one more important feature of the OOO kernel comes to the rescue.
Their response was proactive execution. A proactive execution means that when OOO the kernel encounters conditional constructs in the code (for example, if a block), it will simply load and execute two branches of the code. As soon as the kernel understands which branch is correct, the results of the second will be reset. This prevents the stupor of the pipeline at the cost of negligible costs of running the code in the wrong branch. A cache for branch prediction cache was also added, which greatly improved the results in situations where the kernel was forced to predict among a variety of conditional transitions. The stupors of the conveyor are still encountered due to branching, however, this decision has made it possible to make them a rare exception rather than a common occurrence.
Finally, a processor with an HT provides two virtual processors for one common OOO kernel. They share a common ROB and OOO core and will be visible to the operating system as two separate processors. It looks like this:

OOO core with Hyper-Threading, see note .
The processor with an HT receives two virtual processors, which in return supply more data to the OOO core, which gives an increase in performance under normal use. Only some heavy computational loads optimized for multiprocessor systems can fully load the OOO core. In this case, the HT may slightly decrease performance. However, such loads are relatively rare. For the consumer, HT typically allows for approximately double the speed of operation with normal daily computer use.
Example
All this may seem a bit confusing. I hope the example will put everything in its place.
From the point of view of the application, we are still working on the computing pipeline of the old 8086. This is a black box. The instruction pointed to by IP is processed by this box, and when the instruction goes out of it, the results are already displayed in memory.
Although in terms of instructions, this black box is still an adventure.
Below is the path that makes the instruction in the modern processor (2008-2013).
Let's go, you are the instruction in the program, and this program starts.
You wait patiently until the IP starts pointing at you for further processing. When the IP indicates approximately 4kb before your location, or 1500 instructions, you are moved to the instruction cache. Downloading to the cache takes some time, but it's not scary, since you will not be running soon. This preloading (prefetch) is part of the first stage of the pipeline.
Meanwhile, IP indicates closer and closer to you, and when it begins to indicate 24 instructions before you, you and five neighboring teams go to the instruction queue.
This processor has four decoders that can accommodate one complex command and up to three simple ones. It so happened that you are a complicated instruction and were decoded into four micro-operations.
Decoding is a multi-level process. The decoding part includes the analysis for the data you need and the probability of moving to some new place. The decoder recorded the need for additional data. Without your participation, somewhere at the other end of the computer, the data you need starts loading data into the cache.
Your four microoperations match the register alias table. You declare what memory address you are reading from (this turns out to be fs: [eax + 18h]), and the chip translates it into a temporary address for your micro-operations. Your micro operations go into ROB, from where, at the first opportunity, move to the reservation.
The reservation contains instructions ready for execution. Your third micro-operation is immediately picked up by the fifth port of execution. You do not know why she was chosen first, but it is already gone. After a few ticks, your first micro-operation rushes to the second port, the block of loading addresses. The remaining micro-operations are waiting for the various ports to pick up other micro-operations. They wait for the second port to load data from the data cache into temporary memory slots.
Long wait ...
Very long waiting ...
Other instructions come and go, while your micro-operations are waiting for their friend as he downloads the necessary data. It is good that this processor knows how to handle them extraordinarily.
Suddenly, both of the remaining micro-operations are picked up by the zero and the first port, the data loading should be completed. All microoperations are running and, over time, they reappear on the reservation.
On the way back through the gate, micro-operations transfer their tickets with temporary addresses. Micro-operations are collected and combined, and again, as an instruction, you feel that you are one. The processor gives you your result and politely directs you to the exit.
Through the door marked “Resignation” is a short line. you queue up and find out that you are standing behind the same instruction that you entered. You even stand in the same manner. It turns out that OOO core really knows its business.
From the outside, it looks like each team leaving the processor goes one by one, in exactly the same order in which the IP pointed to them.
Conclusion
I hope that this little lecture has shed some light on what is happening inside the processor. As you can see, there is no magic, smoke and mirrors.
Now we can answer the questions asked at the beginning of the article.
So what happens inside the processor? This is a complex world, where instructions are broken down into micro-operations, processed at the earliest opportunity and in any order, and are again put together, keeping their order and location. To the outside world it looks as if they are processed sequentially and independently of each other. But we now know that, in fact, they are processed out of sequence, sometimes even predicting and launching possible branches of code.
How long does it take to execute one instruction? Whereas in the non-pipelined world there was a good answer for this, but in the modern processor everything depends on what instructions are nearby, what size of neighboring caches and what is in them. There is a minimum time for passing a command through the processor, but this value is almost constant. A good programmer or optimizing compiler can force many instructions to be executed in an average time close to zero. The average time close to zero is not the execution time of the slowest instruction, but the time required for the instruction to pass through the OOO core and the time required for the cache to load and unload data.
What does it mean when a new processor has a 12, or 18, or even a 31-level pipeline? This means that more instructions at a time can be invited to a party. A very long pipeline can mean that several hundred instructions can be labeled as “processed” at a time. When everything goes according to plan, the OOO core is constantly loaded and the processor bandwidth is simply impressive. Unfortunately, this also means that the stupor of the conveyor develops from petty trouble, as it was before, into a nightmare, as hundreds of teams will have to wait for the cleaning of the conveyor.
How can you apply this knowledge in your programs? The good news is that the processor can predict most of the common code patterns, and compilers have been optimizing the code for the OOO kernel for almost two decades. The processor works best with ordered instructions and data. Always write simple code. Simple and not tortuous code will help the compiler optimizer to find and speed up the results. If possible, do not create jumps on the code. If you need to make transitions, try to do it by following a specific pattern. Complex designs, like dynamic transition tables, look cool and much can, but neither the compiler nor the processor can predict which piece of code will be executed in the next moment in time. Therefore, a complex code is likely to provoke stupors and incorrect predictions of branching. On the contrary, keep your data simple. Organize data in an orderly, coherent and consistent manner to prevent stupor. Choosing the right structure and layout for your data can have a dramatic effect on performance improvement. As long as your data and code remain simple, you can usually rely on the work of the optimizing compiler.
Thank you for being part of this journey.
Original - www.gamedev.net/page/resources/_/technical/general-programming/a-journey-through-the-cpu-pipeline-r3115
Source: https://habr.com/ru/post/182002/
All Articles