Fault tolerance of systems based on HP Storageworks P4xxx without a third data center
Prehistory
About two years ago, the management decided to invest in the virtualization project of our data center. The task was quite simple, about 50 servers, mostly Windows, a couple of Linux machines, nothing non-standard. Datacenter, though small but veryWhat happened?
By the accepted rules, we test redundancy & failover twice a year; in the case of virtualized services, we decided to divide the process into two stages. The first step was to simulate the failure of only the hypervisor hosts (we actually cut down the power supply - roughly, but this is how the testing process is described in the documentation). As expected, VMWare HA and FT worked as they should, the committee ticked off the protocols and signed. At the second stage, along with the hypervisors, the storage devices (LeftHand) were cut down and ... no miracle happened. Error in HP Centralized Management Console, data is not available, although backup devices are turned on and available, ... but there is no quorum. It was not possible to restore working capacity - we had to immediately turn everything back on; we could not achieve any filer.Began to find out.
We knew that for an automatic file server, 3 data centers were needed - at pre-sales meetings, HP representatives warned us about this many times. Admins were not invited to meetings, clarifying questions were not asked, for some reason the management decided that “automatic file server is possible only with 3 data centers” implies that “if manually, then two data centers are enough”. But no, in response to the request, HP Support responded that neither manually nor automatically without the third data center, the file carrier is impossible. The principle is similar to that described here (in our case, the systems are somewhat different - but in general, the same case). In short, everything is tied to the Failover Manager (FOM) - it should be accessible from the backup data center network at the time of the failure of the main device - in order to avoid the situation of parallel operation - split brain. The FOM itself does not contain any data, and is needed only in the event of a malfunction, as a witness. For the operation of the FOM, which is a normal virtual machine with more than modest requirements (2Ghz, 1GB RAM, 13Gb HDD), you only need access to our iSCSI VLAN. We immediately figured out and presented to management a version of the Windows server in the cloud with a VPN in our iSCSI VLAN and free VMWare Server to run the FOM ... but the project was rejected with comments:
In short, everything is tied to the Failover Manager (FOM) - it should be accessible from the backup data center network at the time of the failure of the main device - in order to avoid the situation of parallel operation - split brain. The FOM itself does not contain any data, and is needed only in the event of a malfunction, as a witness. For the operation of the FOM, which is a normal virtual machine with more than modest requirements (2Ghz, 1GB RAM, 13Gb HDD), you only need access to our iSCSI VLAN. We immediately figured out and presented to management a version of the Windows server in the cloud with a VPN in our iSCSI VLAN and free VMWare Server to run the FOM ... but the project was rejected with comments:- a) Automatic faylover not needed;
- b) the use of cloud-hosted servers in the storage network is contrary to the IB policy.
')
And this is how we solved the problem:
- On one of the ESXi hosts in the backup data center, activate local storage (to provide access in case of a SAN failure)
- Create a full copy of the main FOM (we copy everything, and most importantly the MAC address of the virtual network card connected to the iSCSI network) on the host in the backup data center
- We leave the FOM in the backup data center in StandBy mode
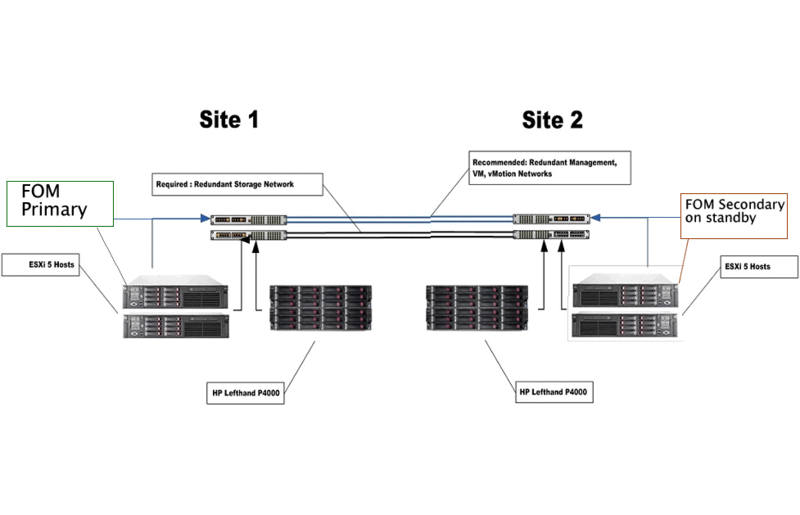
ps sorry that the text on the pictures in English, copied from the report
Source: https://habr.com/ru/post/181956/
All Articles