FeatureBranch
With the spread of distributed version control systems (DVCS), such as Git and Mercurial, I increasingly see discussions on the proper use of branching (branch) and merging (merge), and how this fits into the idea of continuous integration (CI). There is a certain ambiguity in this question, especially when it comes to feature branching (a branch on functionality) and its correspondence to CI ideas.
The main idea of the feature branch is to create a new branch when you start working on some functionality. In DVCS, you do this in your own repository, but the same principles work in centralized VCS.
I will illustrate my thoughts with the following number of diagrams. In them, the main development line (trunk) is marked in blue, and two developers marked in green and purple (Reverend Green and Professor Plum).
')
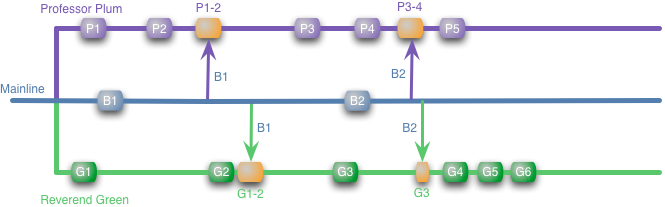
I use the designated colored rectangles as symbols for local commits in branching. The arrows between the branches indicate mergers, the orange rectangles select the merges themselves. In this example, there are updates in the main line, say a couple of fixed bugs. When this happens, our developers merge them into their local branches. In order to get a sense of time, let's assume that we are talking about several days of work, when each developer commits his changes about once a day.
To make sure that the code works, they can run builds and tests on their branches. In this article, we will assume that with each commit and merge, automatic builds and tests for the branch in which it was made run.
The main advantage of feature branching is that each developer can work on his task and be isolated from what is happening around. They can merge changes from the main line at their own pace and be sure that this does not interfere with the functionality being developed. Moreover, it allows the team to choose what to make of the new developments in the release, and what to leave for later. If Reverend Green is late, we can provide a version with only changes to Professor Plum. Or, on the contrary, we can postpone the additions of the professor, perhaps because we are not sure that they work the way we want. In this case, we simply ask the professor not to merge his changes into the main line until we are ready to release its functionality. This approach gives us the opportunity to be selective, the team decides what functionality to merge before each release.
Despite the attractiveness of this image, there may be some problems with this approach.
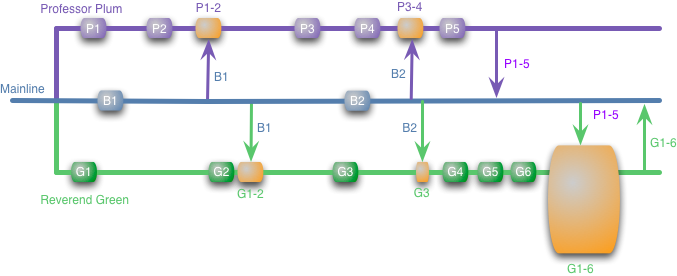
Although developers can work on their functionality in isolation, at some point the result of their work should be integrated. In our example, Professor Plum easily updates the main line with his changes, there is no merger, because he already received all the changes in the main line to his branch (and passed the build). However, not everything is so simple for Reverend Green, it must merge all its changes (G1-6) with the changes by Professor Plum (P1-5).
(In this example, many DVCS users may feel that I miss many of the details in such a simple, even simplified explanation of feature branching. I will explain a more complex diagram later.)
I made this rectangle merge huge because it is a dangerous merge. It can go without problems, it is likely that the developers worked on different parts of the code without interactions, and then the merge will go smoothly. But they could also work on the parts that interact, and then he would be in complete hell.
Nightmares can take various forms, and development tools can save from some . The most standard can be in the difficulties of merging sources, when two developers are working on the same theme files. Modern DVCS cope well with such problems, sometimes it even seems that not without the help of magic. Git has a reputation as a tool that knows how to deal well with complex conflicts. So good that we even leave this question beyond the scope of this article.
The problem that worries us more is semantic conflicts. The simplest example is the case in which Professor Plum changes the name of a method that Reverend Green calls in its code. Tools for refactoring will help you rename the method without problems, but only in your code. Therefore, if G1-6 contains a new code that calls foo, Professor Plum will not know about it, because this change is not in its branch. Awareness of where the dog is buried will come to us only in the big merj.
Renaming a function is the clearest example of semantic conflict. In practice, they can be much more secretive. Tests are the key to them, but the more code you need to merge, the more chances of conflicts and the harder it is to fix them. The risk of conflict in general and semantic in particular makes great mergers terrible.
The consequence of the fear of big merdzhi is the reluctance of re-factoring. Keeping the code clean requires constant effort and in order to succeed everyone must clean up the garbage when he sees it. However, such a refactoring in the feature branch is problematic, insofar as it makes the Big Scary Merge even bigger and more scary. As a result, developers are afraid of refactoring as a fire and the code is cluttered with freaks.
In the above problem, I see the main reason why feature branching is a bad idea. At that moment when the team is afraid of refactoring to maintain a healthy code - they are in a long peak without a chance for an elegant way out.
It is these problems that continuous integration should solve. With CI, my diagram will look like this.

There are a lot more merdzhey here, but merging is one of those things that it’s better to do a little bit often than rarely and in tons. As a result, if Professor Plum changes a part of the code on which Reverend Green depends, our green colleague will find out this much earlier, in P1-2. At the moment, he needs to change G1-2 to work with these changes, instead of G1-6 (as it was in the last example).
CI is effective in neutralizing big merge problems, but beyond that it is also a crucial communication mechanism. In this scenario, a potential conflict will manifest itself when Professor Plum merges G1 and realizes that Reverend Green is using professor libraries. Then Professor Plum can find Reverend Green and together they can discuss the interaction of their functionality. Perhaps the functionality of Professor Pum requires some changes that do not get along with the functionality of Reverend Green. Together, they can make much better design decisions that will not interfere with their work. With isolated transfers, our developers do not know about the problem until the last moment, when it is often too late to resolve the conflict without serious consequences. Communication is one of the key factors in software development and one of the main features of CI is promoting it.
It is important to mention that in most cases, branching has a different approach to CI. One of the principles of CI is that everyone commits to the main line every day, so if the feature branch lives more than one day, it turns it into something very far from CI. I heard people say that they use CI because their builds run on the CI server, on each branch and for each commit. This is a continuous build, which is good, but there is no integration , so this is not CI.
Earlier, I said in brackets that there are other ways to feature branching. Let's say Professor Plum and Reverend Green at the beginning of the iteration brew flavored green tea together and discuss their tasks. They discover that there are interacting parts among the tasks and decide to integrate between each other like this:
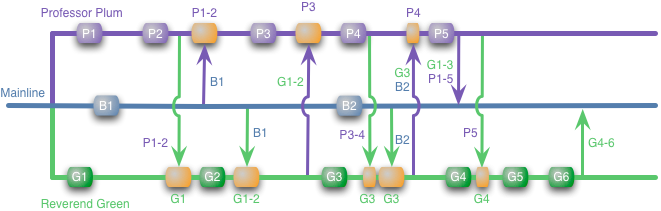
With this approach, they merge with the main line at the end, as in the first example, but they also often do the merdzh among themselves to avoid the Big Scary Merdzh. The idea is that the main advantage of feature branching is isolation. When you isolate isolate your branches, there is a risk of nasty conflict escalating beyond your knowledge. Then isolation is an illusion that will painfully break sooner or later.
Still, is this more labor-intensive integration a form of CI or is it a completely different beast? I think they are different, again, a key property of CI is that each integrates with the main line every day. Integration among feature branches, which I will call “promiscuous integration, PI,” with your permission, does not include and does not even need a main line. I think this difference is very important.
And yet, if PI is different from CI, then for what case is PI better than CI?
With CI, you lose the ability to use a version control system to selectively change. Each developer affects the main line, so all the functionality grows in it. With CI, the main line should always be healthy, and in theory (and often in practice) you can make a release after each commit. Having a half-completed functionality, or the functionality that you prefer not to release, you will not damage the functionality of the entire system, but will require some kind of masking to hide it from the user interface, such as not turning on a new item in the menu.
In such cases, PI can provide something in the middle. This allows Reverend Green to choose when to accept the changes to Professor Plum. If Professor Plum makes any changes to the kernel API of the system in P2, Reverend Green can import P1-2 but leave the rest until Professor Plum finishes its work and merges into the main branch.
However, in general, I do not think that fetching functionality for a release using VCS is a good idea.
I prefer to design software so that you can turn on and off functionality with a configuration change. To do this, there are two useful techniques FeatureToggles and BranchByAbstraction . They require you to think more about what and how to divide into modules and how to control these options, but we came to the conclusion that the result is much more accurate than what comes out, if you hope for VCS.
What bothers me most about PI is his susceptibility to communication skills within the team. With CI, the main line serves as a communication point. Even if Professor Plum and Reverend Green never spoke, they will find an emerging conflict on the day of its formation. With PI, they will have to notice that they are working on interacting code. Constantly updating the main line contributes to everyone’s confidence that it integrates with everyone, it’s not necessary to find out who does what, and therefore there is less chance of changes that remain hidden until late integration.
PI originated from open source and, presumably, a less intense open source project speed may be a factor for it. In the full-time job, you work quite a few hours a day on a project. This allows you to work on the functionality with priorities. With open source, people often donate an hour here and a couple of days there. Functionality can take one developer a lot of time to complete, while others, with plenty of free time, can bring their changes to acceptable quality before. In such a situation, a selective approach may be more important.
It is important to realize that the tools you use do not depend on the strategy you choose. Although many associate DVCS with feature branching, they can also be used with CI. All you need to do is mark one of the branches as the main line. If everyone does pull and push to this thread every day, then you have the most basic line. In fact, in a well-disciplined team, I would prefer to use DVCS for a CI project than a centralized VCS. With a less disciplined team, I’ll worry that using DVCS will push people to long-lived branches, at the moment when centralized VCS and complication of branching will push them to frequent commits to the main line.
PS From the translator to the study of questions to the approaches of using VCS, this article inspired me, thanks to which I began to look for more detailed descriptions of the "correct" use of branching and came across the above translated text. Although I do not pretend to the quality of the translation, I just want to get into the tape to the developers and give them a reason to think from the opposite approach adopted in the open source (forking). Do not hurt with sticks, but constructively criticize, I do it for the first time :-) .
Simple (Isolated) Feature Branch
The main idea of the feature branch is to create a new branch when you start working on some functionality. In DVCS, you do this in your own repository, but the same principles work in centralized VCS.
I will illustrate my thoughts with the following number of diagrams. In them, the main development line (trunk) is marked in blue, and two developers marked in green and purple (Reverend Green and Professor Plum).
')
I use the designated colored rectangles as symbols for local commits in branching. The arrows between the branches indicate mergers, the orange rectangles select the merges themselves. In this example, there are updates in the main line, say a couple of fixed bugs. When this happens, our developers merge them into their local branches. In order to get a sense of time, let's assume that we are talking about several days of work, when each developer commits his changes about once a day.
To make sure that the code works, they can run builds and tests on their branches. In this article, we will assume that with each commit and merge, automatic builds and tests for the branch in which it was made run.
The main advantage of feature branching is that each developer can work on his task and be isolated from what is happening around. They can merge changes from the main line at their own pace and be sure that this does not interfere with the functionality being developed. Moreover, it allows the team to choose what to make of the new developments in the release, and what to leave for later. If Reverend Green is late, we can provide a version with only changes to Professor Plum. Or, on the contrary, we can postpone the additions of the professor, perhaps because we are not sure that they work the way we want. In this case, we simply ask the professor not to merge his changes into the main line until we are ready to release its functionality. This approach gives us the opportunity to be selective, the team decides what functionality to merge before each release.
Despite the attractiveness of this image, there may be some problems with this approach.
Although developers can work on their functionality in isolation, at some point the result of their work should be integrated. In our example, Professor Plum easily updates the main line with his changes, there is no merger, because he already received all the changes in the main line to his branch (and passed the build). However, not everything is so simple for Reverend Green, it must merge all its changes (G1-6) with the changes by Professor Plum (P1-5).
(In this example, many DVCS users may feel that I miss many of the details in such a simple, even simplified explanation of feature branching. I will explain a more complex diagram later.)
I made this rectangle merge huge because it is a dangerous merge. It can go without problems, it is likely that the developers worked on different parts of the code without interactions, and then the merge will go smoothly. But they could also work on the parts that interact, and then he would be in complete hell.
Nightmares can take various forms, and development tools can save from some . The most standard can be in the difficulties of merging sources, when two developers are working on the same theme files. Modern DVCS cope well with such problems, sometimes it even seems that not without the help of magic. Git has a reputation as a tool that knows how to deal well with complex conflicts. So good that we even leave this question beyond the scope of this article.
The problem that worries us more is semantic conflicts. The simplest example is the case in which Professor Plum changes the name of a method that Reverend Green calls in its code. Tools for refactoring will help you rename the method without problems, but only in your code. Therefore, if G1-6 contains a new code that calls foo, Professor Plum will not know about it, because this change is not in its branch. Awareness of where the dog is buried will come to us only in the big merj.
Renaming a function is the clearest example of semantic conflict. In practice, they can be much more secretive. Tests are the key to them, but the more code you need to merge, the more chances of conflicts and the harder it is to fix them. The risk of conflict in general and semantic in particular makes great mergers terrible.
The consequence of the fear of big merdzhi is the reluctance of re-factoring. Keeping the code clean requires constant effort and in order to succeed everyone must clean up the garbage when he sees it. However, such a refactoring in the feature branch is problematic, insofar as it makes the Big Scary Merge even bigger and more scary. As a result, developers are afraid of refactoring as a fire and the code is cluttered with freaks.
In the above problem, I see the main reason why feature branching is a bad idea. At that moment when the team is afraid of refactoring to maintain a healthy code - they are in a long peak without a chance for an elegant way out.
Continuous integration
It is these problems that continuous integration should solve. With CI, my diagram will look like this.
There are a lot more merdzhey here, but merging is one of those things that it’s better to do a little bit often than rarely and in tons. As a result, if Professor Plum changes a part of the code on which Reverend Green depends, our green colleague will find out this much earlier, in P1-2. At the moment, he needs to change G1-2 to work with these changes, instead of G1-6 (as it was in the last example).
CI is effective in neutralizing big merge problems, but beyond that it is also a crucial communication mechanism. In this scenario, a potential conflict will manifest itself when Professor Plum merges G1 and realizes that Reverend Green is using professor libraries. Then Professor Plum can find Reverend Green and together they can discuss the interaction of their functionality. Perhaps the functionality of Professor Pum requires some changes that do not get along with the functionality of Reverend Green. Together, they can make much better design decisions that will not interfere with their work. With isolated transfers, our developers do not know about the problem until the last moment, when it is often too late to resolve the conflict without serious consequences. Communication is one of the key factors in software development and one of the main features of CI is promoting it.
It is important to mention that in most cases, branching has a different approach to CI. One of the principles of CI is that everyone commits to the main line every day, so if the feature branch lives more than one day, it turns it into something very far from CI. I heard people say that they use CI because their builds run on the CI server, on each branch and for each commit. This is a continuous build, which is good, but there is no integration , so this is not CI.
"Messy" integration
Earlier, I said in brackets that there are other ways to feature branching. Let's say Professor Plum and Reverend Green at the beginning of the iteration brew flavored green tea together and discuss their tasks. They discover that there are interacting parts among the tasks and decide to integrate between each other like this:
With this approach, they merge with the main line at the end, as in the first example, but they also often do the merdzh among themselves to avoid the Big Scary Merdzh. The idea is that the main advantage of feature branching is isolation. When you isolate isolate your branches, there is a risk of nasty conflict escalating beyond your knowledge. Then isolation is an illusion that will painfully break sooner or later.
Still, is this more labor-intensive integration a form of CI or is it a completely different beast? I think they are different, again, a key property of CI is that each integrates with the main line every day. Integration among feature branches, which I will call “promiscuous integration, PI,” with your permission, does not include and does not even need a main line. I think this difference is very important.
I see CI mainly as a means for the birth of a release candidate at each commit. The task of the CI system and the deployment process is to refute the readiness for the production of the current release candidate. This model needs some kind of main line of development which represents the current state of the full picture.
- Dave Farley
Random integration vs continuous integration
And yet, if PI is different from CI, then for what case is PI better than CI?
With CI, you lose the ability to use a version control system to selectively change. Each developer affects the main line, so all the functionality grows in it. With CI, the main line should always be healthy, and in theory (and often in practice) you can make a release after each commit. Having a half-completed functionality, or the functionality that you prefer not to release, you will not damage the functionality of the entire system, but will require some kind of masking to hide it from the user interface, such as not turning on a new item in the menu.
In such cases, PI can provide something in the middle. This allows Reverend Green to choose when to accept the changes to Professor Plum. If Professor Plum makes any changes to the kernel API of the system in P2, Reverend Green can import P1-2 but leave the rest until Professor Plum finishes its work and merges into the main branch.
However, in general, I do not think that fetching functionality for a release using VCS is a good idea.
Feature branching is a modular architecture for beggars, instead of building a system with the ability to easily replace functionality during raintime / deployment, people tie themselves to the source control for this mechanism through manual merge.
- Dan Bodart
I prefer to design software so that you can turn on and off functionality with a configuration change. To do this, there are two useful techniques FeatureToggles and BranchByAbstraction . They require you to think more about what and how to divide into modules and how to control these options, but we came to the conclusion that the result is much more accurate than what comes out, if you hope for VCS.
What bothers me most about PI is his susceptibility to communication skills within the team. With CI, the main line serves as a communication point. Even if Professor Plum and Reverend Green never spoke, they will find an emerging conflict on the day of its formation. With PI, they will have to notice that they are working on interacting code. Constantly updating the main line contributes to everyone’s confidence that it integrates with everyone, it’s not necessary to find out who does what, and therefore there is less chance of changes that remain hidden until late integration.
PI originated from open source and, presumably, a less intense open source project speed may be a factor for it. In the full-time job, you work quite a few hours a day on a project. This allows you to work on the functionality with priorities. With open source, people often donate an hour here and a couple of days there. Functionality can take one developer a lot of time to complete, while others, with plenty of free time, can bring their changes to acceptable quality before. In such a situation, a selective approach may be more important.
It is important to realize that the tools you use do not depend on the strategy you choose. Although many associate DVCS with feature branching, they can also be used with CI. All you need to do is mark one of the branches as the main line. If everyone does pull and push to this thread every day, then you have the most basic line. In fact, in a well-disciplined team, I would prefer to use DVCS for a CI project than a centralized VCS. With a less disciplined team, I’ll worry that using DVCS will push people to long-lived branches, at the moment when centralized VCS and complication of branching will push them to frequent commits to the main line.
PS From the translator to the study of questions to the approaches of using VCS, this article inspired me, thanks to which I began to look for more detailed descriptions of the "correct" use of branching and came across the above translated text. Although I do not pretend to the quality of the translation, I just want to get into the tape to the developers and give them a reason to think from the opposite approach adopted in the open source (forking). Do not hurt with sticks, but constructively criticize, I do it for the first time :-) .
Source: https://habr.com/ru/post/181924/
All Articles