Recognition of psychological testing forms from scratch
Three months ago, I was approached by a good friend and colleague with a request to write a small program for psychological testing. I, who previously wrote exclusively for the small needs of office automation on vba, vb, vb.net, decided to seize the moment and learn C # during the project. By the way, the project is simple, only 5 psychodiagnostic methods. Later it turned out that his dream was a form recognition system for these techniques. The situation has become complicated. It became clear that the main amount of time I spend on recognition.
Of course, I had no experience with images, and recognition, and began searching for libraries for letter recognition. Unfortunately, it was not possible to find anything free. So I rolled up my sleeves and started writing on my own.
I will not write code here, as I believe that the main problem in creating such a system is in the algorithm of work.
So…
For a start, forms were created. Each method has its own, but they differ only in the number of questions and the number of answers in the questions.

Forms with my words created a good friend and co-worker. They were originally created in Excel and saved as PDF.
The most important detail on the form is black squares (I called them markers). The upper central marker is needed to determine where the top and where the bottom of the form. In psychodiagnostics, the subject is asked to draw a diagonal cross in the desired cell. It is assumed that:
1. The level of education of the subject may be low.
2. This is not an exam, and the subject makes a mistake, crosses them out many times.
3. The subject uses pencils, ballpoint, gel pens of different colors of ink.
4. The test subject is poorly instructed, and instead of the crosses, ticks.
')
Now, step by step formalization of the task itself of working with the test form recognition system:
1. Remove the blank image from the input device.
2. Bring the image into a standard form.
3. Find the cells in the image that need to be recognized.
4. Recognize cells.
5. Save the answers.
Now about everything in order.
1. Obtaining images for processing.
I chose a flatbed scanner as the cheapest and most common means of obtaining images. In the native C # operating system, there are two main APIs for working with scanners: TWAIN and WIA . No problems with WIA. The technology is well supported in Windows, well documented and there are many examples on the web. The most difficult thing was to set the scan parameters .
The unpleasant thing about WIA technology is the list of supported devices . They are few. Therefore, I had to add the ability to work with TWAIN scanners. I used the free TwainDotNet library. Its only drawback is that the scanner is checked for compatibility at the beginning of the scan. Older scanners, for example, do not pass inspection due to the lack of auto-rotate image features. Given the open source, I quickly corrected the situation.
When using both APIs, I disabled their standard GUIs. Set the size of the A4 image and resolution of 100 DPI. For completeness, I encapsulated into my Scanner class the ability to select an image from a file.
2. Image normalization.
Reduction of the image to the universal view is divided into stages:
1. Reduction of the image to the resolution of 100 DPI.
2. Image binarization.
3. Finding markers.
4. Rotate the image.
I used the AForge.NET Framework to work with images. This is free and convenient, since you do not need to write numerous algorithms for working with images, especially since you would have to write unsafe code for speed, and I'm new to C #. In the future, I will refer to the classes of this particular library.
So, at the beginning of the incoming image is reduced to 100 DPI. Smaller resolution threatens with binarization problems, and more with processing speed problems. Then we translate the image into the Grayscale color mode. For this operation, we use the GrayScale class. For image binarization, I used BradleyLocalThresholding . The algorithm does an excellent job with small heaps of brightness.
One of the difficult nuances of successful recognition is the correct orientation of the image. Rotate by 3-4 degrees, and everything is gone. There is no stream feed, the tablet scanner, the forms are crumpled. In general, to determine the angle of rotation of the form, I used DocumentSkewChecker . And to rotate the image RotateBilinear , because it is fast. This rotation leveled the image in the range of 0-45 degrees, but it could remain inverted. Therefore, it is necessary to find the markers and determine the top of the form by the central one.
To search for objects in the image, I successfully applied BlobCounter . To determine the markers, I filtered all the objects found by size and Fullness property, setting the threshold to 0.8. And if I did not find three markers on top, I turned the image 180 degrees.
With such simple manipulations, all images are brought to a single form and format.
3. Finding Recognized Response Cells
The easiest way was used to find the answer cells. I took the reference blank form of each technique and saved the center of the first (left) cell of each question in the database. It also saved the distance between the centers of the cells of each question and the size of the cells. Thus, to determine the areas of recognition, I simply took the data from the database. Here you need to make two very important observations. If the scanned form is crumpled, then the recognition areas will be incorrect, since the reference form is even. The percentage of errors in this case will be too large. This is what happens if you ignore it:
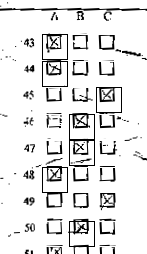
It is solved quite simply. The area of the first cell expands from the center. Then in this area I look for an object using BlobCounter . After finding the cell inside the expanded area, the area is compressed relative to the center found. It looks like this:
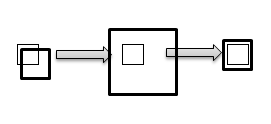
These manipulations are made only with the first cell of each question, the coordinates of the remaining cells are recalculated relative to it.
Also, the image dimensions (recognition areas) may slightly change, so the data on the cells should not be saved in absolute coordinates on the original image but rather their position relative to the markers. This is the second important function of markers.
It is worth noting that it is possible to find recognition areas without knowing their coordinates. This is done on the basis of vertical and horizontal brightness histograms. However, I did not use this algorithm, and I will not describe it.
4. Cell recognition
Here I am stuck. Recognition is essentially a classification task. Given the task at hand, there are 3 classes of cells:
1. Empty (free).
2. Marked by the subject (cross).
3. Erroneously marked by the test (miss).
With the free class, everything is clear. This is an absolutely empty cell, untouched by the test subject's pen. But the cross class already has problems: anything can be found in the cell. In spite of the excellent instructions, the persons undergoing testing do not carefully write out diagonal crosses. Additionally, the subjects are instructed to shade a cell if they make a mistake and want to correct a variant of their answer. This is the miss class.
By and large, I had two approaches to the classification: separation of cells according to the level of brightness and the use of machine learning methods. As an old fan of neural networks (I wrote something on vba), I took the Encog library and trained a multilayer perceptron on 20 completed test forms. And I got an error of 15-35% wrong answers. It became clear that it was necessary to use more subtle algorithms (convolutional networks, ensembles of networks, a combination of learning algorithms). At the same time, it was necessary to present the networks with various variants of the classes of cells, for example:

As a result of all trial and error, I returned to the classification by brightness. But not in the sum of the brightness of all the pixels of the cell, as it turns out not too sensitive. I used the VerticalIntensityStatistics class for the vertical histogram of the cell pixel brightness sums. Below is the cross class histogram and the free class histogram:
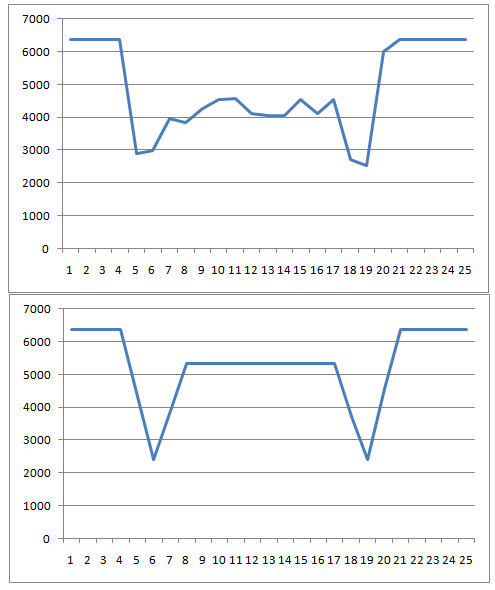
I took the histogram values for the vertical pixels from 8 to 17 (cut off the minima) and used the formula: threshold = 1 - average (histogram value for brightness) / maximum brightness. By the value of the threshold, I determined the class of the cell. As a rule, classes were divided as follows:
from 0 to 0.18 class free,
from 0.18 to 0.6 class cross,
from 0.6 to 1 miss class.
5. Saving answers.
Since the system is not automatic, the automated errors that occur during recognition can be corrected manually. After this, the cell ID of the class cross is sent to the database.
Externally, the recognition interface looks like this:
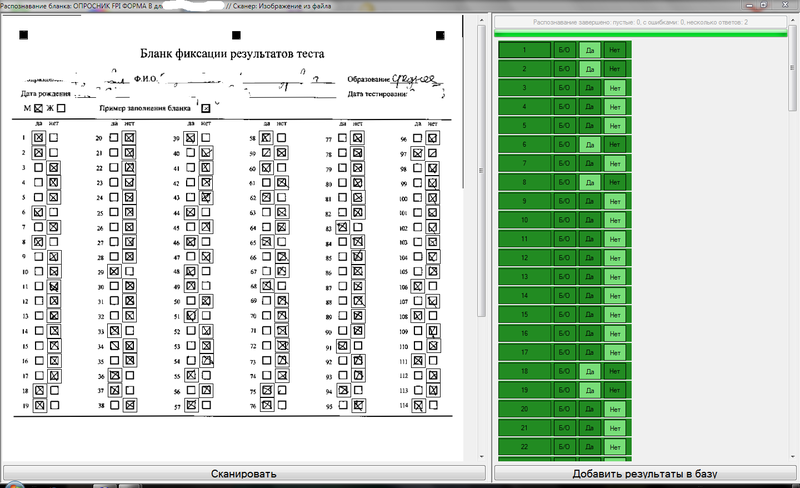
Eventually:
For three months of learning the language C #, I made a free application for recognition of forms of psychological testing. Prior use showed a throughput of approximately 1 form in a minute and a half. This is very good, given the manual entry of personal data before recognition.
Now I am happy to correct myhorror code, and even, to be honest, I am writing documentation to give the product to people. And at the same time optimizing the classification process.
Or maybe this article will spur any pro to write a great free framework for recognition of forms, at least for such simple needs as my good friend and colleague ...
Of course, I had no experience with images, and recognition, and began searching for libraries for letter recognition. Unfortunately, it was not possible to find anything free. So I rolled up my sleeves and started writing on my own.
I will not write code here, as I believe that the main problem in creating such a system is in the algorithm of work.
So…
For a start, forms were created. Each method has its own, but they differ only in the number of questions and the number of answers in the questions.
Forms with my words created a good friend and co-worker. They were originally created in Excel and saved as PDF.
The most important detail on the form is black squares (I called them markers). The upper central marker is needed to determine where the top and where the bottom of the form. In psychodiagnostics, the subject is asked to draw a diagonal cross in the desired cell. It is assumed that:
1. The level of education of the subject may be low.
2. This is not an exam, and the subject makes a mistake, crosses them out many times.
3. The subject uses pencils, ballpoint, gel pens of different colors of ink.
4. The test subject is poorly instructed, and instead of the crosses, ticks.
')
Now, step by step formalization of the task itself of working with the test form recognition system:
1. Remove the blank image from the input device.
2. Bring the image into a standard form.
3. Find the cells in the image that need to be recognized.
4. Recognize cells.
5. Save the answers.
Now about everything in order.
1. Obtaining images for processing.
I chose a flatbed scanner as the cheapest and most common means of obtaining images. In the native C # operating system, there are two main APIs for working with scanners: TWAIN and WIA . No problems with WIA. The technology is well supported in Windows, well documented and there are many examples on the web. The most difficult thing was to set the scan parameters .
The unpleasant thing about WIA technology is the list of supported devices . They are few. Therefore, I had to add the ability to work with TWAIN scanners. I used the free TwainDotNet library. Its only drawback is that the scanner is checked for compatibility at the beginning of the scan. Older scanners, for example, do not pass inspection due to the lack of auto-rotate image features. Given the open source, I quickly corrected the situation.
When using both APIs, I disabled their standard GUIs. Set the size of the A4 image and resolution of 100 DPI. For completeness, I encapsulated into my Scanner class the ability to select an image from a file.
2. Image normalization.
Reduction of the image to the universal view is divided into stages:
1. Reduction of the image to the resolution of 100 DPI.
2. Image binarization.
3. Finding markers.
4. Rotate the image.
I used the AForge.NET Framework to work with images. This is free and convenient, since you do not need to write numerous algorithms for working with images, especially since you would have to write unsafe code for speed, and I'm new to C #. In the future, I will refer to the classes of this particular library.
So, at the beginning of the incoming image is reduced to 100 DPI. Smaller resolution threatens with binarization problems, and more with processing speed problems. Then we translate the image into the Grayscale color mode. For this operation, we use the GrayScale class. For image binarization, I used BradleyLocalThresholding . The algorithm does an excellent job with small heaps of brightness.
One of the difficult nuances of successful recognition is the correct orientation of the image. Rotate by 3-4 degrees, and everything is gone. There is no stream feed, the tablet scanner, the forms are crumpled. In general, to determine the angle of rotation of the form, I used DocumentSkewChecker . And to rotate the image RotateBilinear , because it is fast. This rotation leveled the image in the range of 0-45 degrees, but it could remain inverted. Therefore, it is necessary to find the markers and determine the top of the form by the central one.
To search for objects in the image, I successfully applied BlobCounter . To determine the markers, I filtered all the objects found by size and Fullness property, setting the threshold to 0.8. And if I did not find three markers on top, I turned the image 180 degrees.
With such simple manipulations, all images are brought to a single form and format.
3. Finding Recognized Response Cells
The easiest way was used to find the answer cells. I took the reference blank form of each technique and saved the center of the first (left) cell of each question in the database. It also saved the distance between the centers of the cells of each question and the size of the cells. Thus, to determine the areas of recognition, I simply took the data from the database. Here you need to make two very important observations. If the scanned form is crumpled, then the recognition areas will be incorrect, since the reference form is even. The percentage of errors in this case will be too large. This is what happens if you ignore it:
It is solved quite simply. The area of the first cell expands from the center. Then in this area I look for an object using BlobCounter . After finding the cell inside the expanded area, the area is compressed relative to the center found. It looks like this:
These manipulations are made only with the first cell of each question, the coordinates of the remaining cells are recalculated relative to it.
Also, the image dimensions (recognition areas) may slightly change, so the data on the cells should not be saved in absolute coordinates on the original image but rather their position relative to the markers. This is the second important function of markers.
It is worth noting that it is possible to find recognition areas without knowing their coordinates. This is done on the basis of vertical and horizontal brightness histograms. However, I did not use this algorithm, and I will not describe it.
4. Cell recognition
Here I am stuck. Recognition is essentially a classification task. Given the task at hand, there are 3 classes of cells:
1. Empty (free).
2. Marked by the subject (cross).
3. Erroneously marked by the test (miss).
With the free class, everything is clear. This is an absolutely empty cell, untouched by the test subject's pen. But the cross class already has problems: anything can be found in the cell. In spite of the excellent instructions, the persons undergoing testing do not carefully write out diagonal crosses. Additionally, the subjects are instructed to shade a cell if they make a mistake and want to correct a variant of their answer. This is the miss class.
By and large, I had two approaches to the classification: separation of cells according to the level of brightness and the use of machine learning methods. As an old fan of neural networks (I wrote something on vba), I took the Encog library and trained a multilayer perceptron on 20 completed test forms. And I got an error of 15-35% wrong answers. It became clear that it was necessary to use more subtle algorithms (convolutional networks, ensembles of networks, a combination of learning algorithms). At the same time, it was necessary to present the networks with various variants of the classes of cells, for example:
As a result of all trial and error, I returned to the classification by brightness. But not in the sum of the brightness of all the pixels of the cell, as it turns out not too sensitive. I used the VerticalIntensityStatistics class for the vertical histogram of the cell pixel brightness sums. Below is the cross class histogram and the free class histogram:
I took the histogram values for the vertical pixels from 8 to 17 (cut off the minima) and used the formula: threshold = 1 - average (histogram value for brightness) / maximum brightness. By the value of the threshold, I determined the class of the cell. As a rule, classes were divided as follows:
from 0 to 0.18 class free,
from 0.18 to 0.6 class cross,
from 0.6 to 1 miss class.
5. Saving answers.
Since the system is not automatic, the automated errors that occur during recognition can be corrected manually. After this, the cell ID of the class cross is sent to the database.
Externally, the recognition interface looks like this:
Eventually:
For three months of learning the language C #, I made a free application for recognition of forms of psychological testing. Prior use showed a throughput of approximately 1 form in a minute and a half. This is very good, given the manual entry of personal data before recognition.
Now I am happy to correct my
Or maybe this article will spur any pro to write a great free framework for recognition of forms, at least for such simple needs as my good friend and colleague ...
Source: https://habr.com/ru/post/181878/
All Articles