Sort the list by analogy of "Windows Explorer"
When the project is almost completed and the entire business logic is in testing, sometimes there is a desire to add it with “frills and fictions” and other “decorations”, for example, to redraw a couple of icons to more beautiful ones, or to select elements through the gradient with the alpha channel.
There are a lot of options for such spontaneous hackers (especially if there is time), and all of the series of decorations that do not carry any semantic load, but that's all.
In this mini-article, I will consider one of these "hotelok."
Suppose you have a list of items displayed in a TListView, you try to sort it and get this result.
')
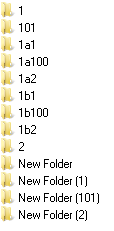
Not beautiful, why is this second element named “101” misplaced? After all, this number, and therefore to be a place to him at least after the element with the name "2". Yes, and "New Folder (101)" should obviously be after the "New Folder (2)". After all, in the conductor everything looks fine.

Let's try to understand the reasons for this behavior and implement the algorithm more correct, from the point of view of a person, sorting.
First, let's look at the reasons for incorrect sorting.
By default, TListView uses the lstrcmp function to compare strings, which compare strings character-by-character.
For example, if you take two lines "1" and "2", then the first line should be located above the second, because the unit symbol goes before the two. However, if instead of the first line we take “101”, the lstrcmp function will also say that this line should go first, because in this case it decides on the result of comparing the very first character of both lines, disregarding the fact that both lines are a string representation of numbers .
Let's complicate a little, let's take the strings “1a2” and “1a101” on which lstrcmp will again produce an incorrect result, saying that the second line should go first. It makes this decision based on the result of comparing the third character of both strings, despite the fact that in this case they are also string representations of numbers.
With the reasons figured out, now we think the solution.
Since lstrcmp makes a mistake on the comparison, interpreting parts of numbers as symbols, you need to implement a comparison algorithm similar to it, in which the numbers will be compared exactly as numbers, and not as symbols.
Algorithmically, this is quite simple.
Take again the same "1a2" and "1a101". We divide them into separate components, where the characters will be separated from the numbers. If we represent the first line in the form “1 + a + 2”, and the second in the form “1 + a + 101”, it turns out that we need to perform only three comparisons.
1. Number with number
2. Symbol with symbol
3. Again number with number
The result of such a comparison will be correct and will show that the second line should really go second, and not the first, as lstrcmp informed us about this.
Now we will think over the terms of reference for the implementation of this algorithm.
It's obvious that:
1. If one of the lines passed for comparison is empty - it should go higher than the first.
2. If both strings are empty, they are identical.
3. The string register is not considered when comparing.
4. To analyze the lines, use the cursor containing the address of the current character being analyzed for each line.
5. If the cursor of one of the lines contains a number, and the cursor of the other line contains a character - the first line is higher than the second.
6. If the row cursors point to a character - the comparison is made by analogue lstrcmp
7. If the row cursors indicate a number - extract both numbers and compare them with each other.
7.1 If both numbers are zero (for example, “00” and “0000”), then a number with a smaller number of zeros is placed upwards.
8. If during the analysis the cursor any of the lines found a terminating zero - this line goes higher.
8.1 If at the same time the cursor of the second line is also on the terminating zero - the lines are identical.
To implement the algorithm, this TZ is more than enough.
Actually we realize:
We look at the result of this algorithm.
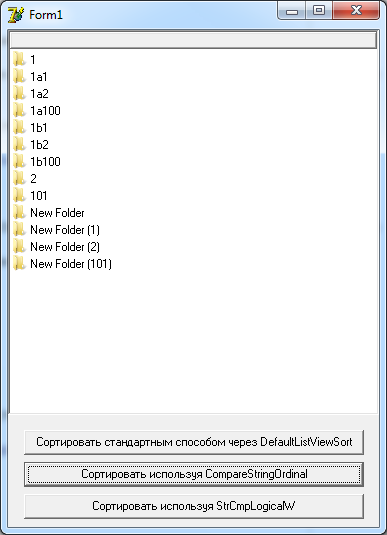
Actually as expected.
The next "decorator" is ready.
You can certainly say that this is a bicycle and you need to use StrCmpLogicalW:
msdn.microsoft.com/en-us/library/windows/desktop/bb759947
Well, try - the third button is responsible for such sorting.
Notice the first five items in the list after sorting.
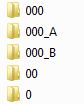
Although they are similar to what the explorer will display, but not quite true. Well, there should not be an element with the name "0" located under the element "00" and others.
The source code of the demo example can be collected at this link .
There are a lot of options for such spontaneous hackers (especially if there is time), and all of the series of decorations that do not carry any semantic load, but that's all.
In this mini-article, I will consider one of these "hotelok."
Suppose you have a list of items displayed in a TListView, you try to sort it and get this result.
')
Not beautiful, why is this second element named “101” misplaced? After all, this number, and therefore to be a place to him at least after the element with the name "2". Yes, and "New Folder (101)" should obviously be after the "New Folder (2)". After all, in the conductor everything looks fine.
Let's try to understand the reasons for this behavior and implement the algorithm more correct, from the point of view of a person, sorting.
First, let's look at the reasons for incorrect sorting.
By default, TListView uses the lstrcmp function to compare strings, which compare strings character-by-character.
For example, if you take two lines "1" and "2", then the first line should be located above the second, because the unit symbol goes before the two. However, if instead of the first line we take “101”, the lstrcmp function will also say that this line should go first, because in this case it decides on the result of comparing the very first character of both lines, disregarding the fact that both lines are a string representation of numbers .
Let's complicate a little, let's take the strings “1a2” and “1a101” on which lstrcmp will again produce an incorrect result, saying that the second line should go first. It makes this decision based on the result of comparing the third character of both strings, despite the fact that in this case they are also string representations of numbers.
With the reasons figured out, now we think the solution.
Since lstrcmp makes a mistake on the comparison, interpreting parts of numbers as symbols, you need to implement a comparison algorithm similar to it, in which the numbers will be compared exactly as numbers, and not as symbols.
Algorithmically, this is quite simple.
Take again the same "1a2" and "1a101". We divide them into separate components, where the characters will be separated from the numbers. If we represent the first line in the form “1 + a + 2”, and the second in the form “1 + a + 101”, it turns out that we need to perform only three comparisons.
1. Number with number
2. Symbol with symbol
3. Again number with number
The result of such a comparison will be correct and will show that the second line should really go second, and not the first, as lstrcmp informed us about this.
Now we will think over the terms of reference for the implementation of this algorithm.
It's obvious that:
1. If one of the lines passed for comparison is empty - it should go higher than the first.
2. If both strings are empty, they are identical.
3. The string register is not considered when comparing.
4. To analyze the lines, use the cursor containing the address of the current character being analyzed for each line.
5. If the cursor of one of the lines contains a number, and the cursor of the other line contains a character - the first line is higher than the second.
6. If the row cursors point to a character - the comparison is made by analogue lstrcmp
7. If the row cursors indicate a number - extract both numbers and compare them with each other.
7.1 If both numbers are zero (for example, “00” and “0000”), then a number with a smaller number of zeros is placed upwards.
8. If during the analysis the cursor any of the lines found a terminating zero - this line goes higher.
8.1 If at the same time the cursor of the second line is also on the terminating zero - the lines are identical.
To implement the algorithm, this TZ is more than enough.
Actually we realize:
// // CompareStringOrdinal , .. // " (3)" < " (103)" // // // -1 - // 0 - // 1 - // ============================================================================= function CompareStringOrdinal(const S1, S2: string): Integer; // CharInSet Delphi 2009, // function CharInSet(AChar: Char; ASet: TSysCharSet): Boolean; begin Result := AChar in ASet; end; var S1IsInt, S2IsInt: Boolean; S1Cursor, S2Cursor: PChar; S1Int, S2Int, Counter, S1IntCount, S2IntCount: Integer; SingleByte: Byte; begin // if S1 = '' then if S2 = '' then begin Result := 0; Exit; end else begin Result := -1; Exit; end; if S2 = '' then begin Result := 1; Exit; end; S1Cursor := @AnsiLowerCase(S1)[1]; S2Cursor := @AnsiLowerCase(S2)[1]; while True do begin // if S1Cursor^ = #0 then if S2Cursor^ = #0 then begin Result := 0; Exit; end else begin Result := -1; Exit; end; // if S2Cursor^ = #0 then begin Result := 1; Exit; end; // S1IsInt := CharInSet(S1Cursor^, ['0'..'9']); S2IsInt := CharInSet(S2Cursor^, ['0'..'9']); if S1IsInt and not S2IsInt then begin Result := -1; Exit; end; if not S1IsInt and S2IsInt then begin Result := 1; Exit; end; // if not (S1IsInt and S2IsInt) then begin if S1Cursor^ = S2Cursor^ then begin Inc(S1Cursor); Inc(S2Cursor); Continue; end; if S1Cursor^ < S2Cursor^ then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; // S1Int := 0; Counter := 1; S1IntCount := 0; repeat Inc(S1IntCount); SingleByte := Byte(S1Cursor^) - Byte('0'); S1Int := S1Int * Counter + SingleByte; Inc(S1Cursor); Counter := 10; until not CharInSet(S1Cursor^, ['0'..'9']); S2Int := 0; Counter := 1; S2IntCount := 0; repeat SingleByte := Byte(S2Cursor^) - Byte('0'); Inc(S2IntCount); S2Int := S2Int * Counter + SingleByte; Inc(S2Cursor); Counter := 10; until not CharInSet(S2Cursor^, ['0'..'9']); if S1Int = S2Int then begin if S1Int = 0 then begin if S1IntCount < S2IntCount then begin Result := -1; Exit; end; if S1IntCount > S2IntCount then begin Result := 1; Exit; end; end; Continue; end; if S1Int < S2Int then begin Result := -1; Exit; end else begin Result := 1; Exit; end; end; end; We look at the result of this algorithm.
Actually as expected.
The next "decorator" is ready.
You can certainly say that this is a bicycle and you need to use StrCmpLogicalW:
msdn.microsoft.com/en-us/library/windows/desktop/bb759947
Well, try - the third button is responsible for such sorting.
Notice the first five items in the list after sorting.
Although they are similar to what the explorer will display, but not quite true. Well, there should not be an element with the name "0" located under the element "00" and others.
The source code of the demo example can be collected at this link .
Source: https://habr.com/ru/post/181760/
All Articles