Create Shazam in Java

A couple of weeks ago, I came across this article How Shazam Works
I wondered how programs like Shazam work ... More importantly, how hard is it to write something similar in Java?
About shazam
If someone does not know, Shazam is an application with which you can analyze / pick up music. Having installed it on your phone, and bringing the microphone to any music source for 20-30 seconds, the application will determine what kind of song it is.
')
When first used, I had a magical feeling. “How did it do it !?” And even today, when I have already used it many times, this feeling does not leave me.
Wouldn't it be cool if we could write something ourselves that would cause the same feelings? That was my goal last weekend.
Listen carefully..!
First of all, before taking a sample of music for analysis, we need to listen to the microphone through our Java application ...! This is something that I did not have to implement in Java at that time, so I could not even imagine how difficult it would be.
But it turned out that it is quite simple:

Now we can read data from the TargetDataLine as with normal InputStream streams:

This method makes it easy to open the microphone and record all sounds! In this case, I use the following AudioFormat:

And so, now we have recorded data in the class ByteArrayOutputStream, great! The first stage is completed.
Microphone data
The following test - data analysis, the output, the data was in the form of a byte array, it was a long list of numbers, like this:

Hmmm ... yes. And that sound?
To find out if the data can be visualized, I threw it into Open Office and converted it to a line graph:

Yes! Now it looks like a "sound". It looks as if you, for example, used Windows Sound Recorder.
Data of this type is known as the time domain . But at this stage, these numbers are useless for us ... if you read the above article about how Shazam works, then you will find out that they use spectrum analysis instead of continuous data of the time domain.
Therefore, the next important question is: “How do we convert our data in the format of spectral analysis?”
Discrete Fourier Transform
To transform our data into something suitable, we must apply the so-called Discrete Fourier Transformation (Discrete Fourier Transform). That will allow us to convert our data from the time domain into frequency intervals.
But this is only one problem, if you convert the data into frequency intervals, then every bit of information regarding the time data will be lost. And so, you will know the magnitude of each wobble, but you will not have a clue as to when it should occur.
To solve this problem, we use the sliding window protocols. We take part of the data (in my case 4096 bytes of data) and convert only this bit of information. Then we will know the magnitude of all oscillations occurring during these 4096 bytes.
Application
Instead of thinking about the Fourier Transform, I went a little bit and found the code for the so-called FFT (Fast Fourier Transform). I call this code - a code with data packets:

Now we have two rows with packets of all data - Complex []. These series contain data about all frequencies. To visualize this data, I decided to use the analyzer of the entire spectrum (just to make sure that my calculations are correct).
To show you the data, I put it together:

Enter, Aphex Twin
This is a bit off topic, but I would like to tell you about the electric musician Aphex Twin (Richard David James). He wrote crazy electronic music ... but some of his songs have an interesting characteristic. For example, his greatest hit is Windowlicker , it contains an image - a spectrogram.
If you look at the song as a spectral image, you will see a beautiful spiral. Another song - Mathematical Equation, shows the face of Twin! You can find out more here - Bastwood - Aphex Twin's face .
Having driven this song through my spectrum analyzer, I got the following results:
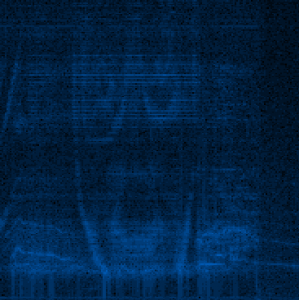
Of course, not perfect, but it must be the face of Twin'a!
Identify key music points
The next step in the Shazam application algorithm is to identify some key points in the song, save them as characters, and then try to pick the right song from your more than 8 million database of songs. This happens very quickly, the sign search happens at a speed of - O (1). Now it becomes clear why Shazam works so great!
Since I wanted everything to work for me after one weekend (unfortunately this is the maximum amount of time I spend concentrating on one case, then I need to find a new project) I tried to simplify my algorithm as much as possible. And to my surprise, it worked.
For each line in the spectral analysis, in a certain range, I selected points with the highest magnitude. In my case: 40-80, 80-120, 120-180, 180-300.
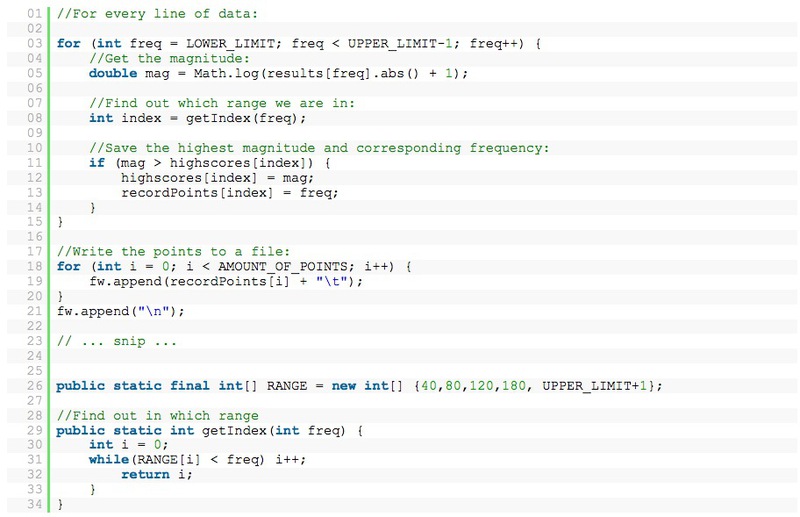
Now, when we record a song, we get a list of numbers like this:

If I record a song and visualize it, it will look something like this:

(all red dots are “key points”)
Indexing my own music
Having a working algorithm in my hands, I decided to index all my 3000 songs. Instead of a microphone, you can simply open mp3 files, convert them to the desired format, and read them in the same way as when using a microphone, using the AudioInputStream. Converting stereo recordings to mono mode turned out to be more difficult than I thought. Examples can be found on the Internet (requires a bit more coding to post here) will have to change examples a little.
Selection process
The most important part of the application is the selection process. From the guide to Shazam, it is clear that they use signs to find matches and then decide which song comes best.
Instead of using intricate temporal groupings of points, I decided to use our data string (for example, 33, 47, 94, 137) as one single character: 1370944733
(in the process of testing, 3 or 4 points is the best option, harder with fine tuning, every time I have to reindex my mp3s!)
An example of character encoding using 4 points per line:

Now I will create two data arrays:
- List of songs, List (where List index is a Song-ID, String is a songname)
- Database of characters: Map <Long, List>
Long in the character database is the character itself, and includes the DataPoints segment.
DataPoints are as follows:

Now we have everything you need to start your search. At first I counted all the songs and generated marks for each data point. This will enter the database of characters.
The second step is reading the data of the song we want to identify. These characters are retrieved and a match is searched for the database.
This is only one problem, for each sign there are several hits, but how do we determine which song is the same ..? By the number of matches? No, that will not do…
The most important thing is time. We have to impose time ...! But how can we do this if we don’t know which part of the song we are in? With the same success, we could just record the last chords of the song.
Studying the data, I found something interesting, since we have the following data:
- Signs of the record
- Matching signs of likely options
- ID of the song of probable variants
- The time stream in our own records
- The time marks the likely options
Now we can minimize the current time in our record (for example, line 34) with the sign time (for example, line 1352). This difference is stored with the song ID. Since this contrast, this difference, tells us where we can be in the song.
After we finish with all the signs from our recording, we will be left with a bunch of ID songs and contrasts. The trick is that if you have a lot of signs with selected contrasts, then you have found your song.
Results
For example, listening to The Kooks - Match Box for the first 20 seconds, we get the following data in my application:

Works!!!
After listening to 20 seconds it can identify almost all the songs that I have. And even this live recording of the Editors can be determined after 40 seconds of listening!
And again, this feeling of magic!
At the moment, the code cannot be considered complete and it works imperfectly. I blinded him over one weekend, this is more like a proof of theory / study of the algorithm.
Perhaps, if enough people ask about it, then I will bring it to mind and lay it out somewhere.
Addition
The lawyers of the patent rights to Shazam send me emails with a request to stop issuing the code and delete this topic, you can read about it here .
From translator
A small announcement: in the summer of 2013, Yandex opens the Tolstoy Summer Camp — an experimental workshop for those who want to learn how to create and launch startups. As part of the two-month course, Yandex will help participants build a decent team, formulate a concept correctly, get feedback from the right experts and develop a project prototype. A variety of seminars and workshops will allow you to pump the necessary skills. We will also regularly publish interesting translated articles on start-up topics. If you come across something interesting, throw in a personal! Kst, an article on Habré as Yandex learned to recognize music.
Apply (2 days left !!) and find more information here . And also in the announcement on Habré . I will talk about Lean-methods, Customer Development and MVP. Come!
Source: https://habr.com/ru/post/181654/
All Articles