Atomic commit mechanism in SQLite
This article is a partial translation of one interesting article from sqlite.org, which discusses in detail the implementation of transactions in SQLite. In fact, I rarely work with SQLite, but nevertheless I really enjoyed this reading. Therefore, if you just want to develop your horizons, it will be interesting to read. The first two sections are not included in the translation, since there is nothing interesting there, and I am too lazy to fill them (the post is so huge).
We begin by reviewing the steps SQLite is taking to commit an atomic commit to a transaction that affects only one database file. Details of the file format used to protect against damage to the database and equipment that are used for a commit to several databases will be shown below.
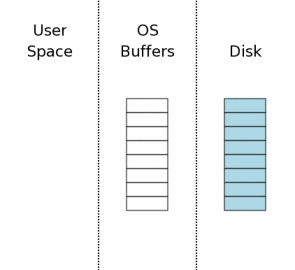
The state of the system, when the connection with the database has just been raised, is superficially depicted in the figure to the right. The right shows information stored on an energy-independent storage medium. Each rectangle is a sector. The blue color indicates that this sector contains the original data. In the middle is the disk cache of the operating system. At the very beginning of our example, the cache is cold, it is shown in white. On the left side of the figure - the contents of the process memory that uses SQLite. The connection to the database has just been opened, and no information has been read.
Before SQLite can start writing, it must first know what is already there. Even if it is just inserting new data, it needs to read the schema from the sqlite_master table so that it knows how to parse the INSERT query and understand where to write the data.
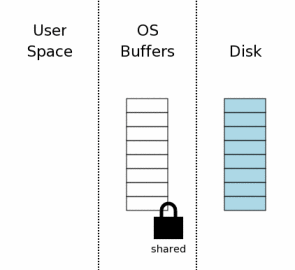
The first step is to obtain shared lock (shared lock) on the database file. Joint blocking allows two or more connections to read from a file at the same time. But this type of blocking prohibits other connections from recording until it is removed. This is mandatory, as if another connection made a record at the same time, we could read a part of the unchanged data and another part of the data after the change. Then the record could be considered non-atomic.
Note that the lock was installed on the OS and the disk cache, and not on the disk itself. File locks are usually just flags controlled by the system kernel. They will be reset for any system crash or power failure. Also, they are usually reset when the process that received the lock dies.
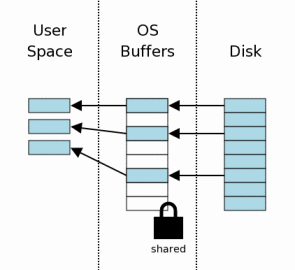
After the lock has been acquired, we can start reading from the database file. In this scenario, we mean that the cache is not yet warmed up, so the information must first be read from the data collector to the operating system cache, and then it can be moved from the OS cache to user space. On subsequent readings, all or some of the information will already be in the cache, so it will only need to be given to the user space.
Usually only a small part of the pages will be read from the database file. In our example, we see that out of eight pages, only three have been read. In a typical database application, there will be thousands of pages and the request will affect a very small percentage of them.
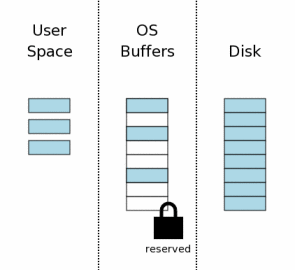
Before you make any changes to the database, SQLite first gets a “backup” lock (reserved lock) on the database file (approx. Lane is the most tolerable translation that came to my mind). Such a lock is similar to a joint one in that it also allows other processes to read from the database file. One reserving lock can coexist with several joint. However, only one reserving lock per file can exist at a time. Thus, only one process can write to the database at a time.
The idea of a reserving lock is that it says that the process intends to start writing to the file in the near future, but so far it has not begun to do this. And, since the changes have not yet begun to be written, other processes can continue reading from the database. But no processes can no longer initiate a recording while the lock is alive.

Before you start writing to the database file, SQLite first creates a separate log for rolling back the changes, and writes the original database pages to it, which will be changed. The rollback log contains all the necessary information to roll back the database to its original state before the transaction.
The rollback log contains a small header (shown in green in the diagram), which contains the size of the database file in its original state. So, if after changing the database file will grow in size, we will still know its original size. The page number is stored next to each page in the log.
When a new file is created, most operating systems (Windows, Linux, Mac OS X) will not actually write anything to disk. A new file is created only in the cache of the operating system. The file is not created on the drive until the operating system finds a suitable time for this. This makes it appear to the user that the I / O operations on the drive are performed much faster than is possible. We depicted this process in the diagram on the right, showing that the rollback log appeared only in the disk cache, but not on the disk itself.

After the original content has been saved to the redo log, the pages can be changed in user memory. Each connection to the database has its own private copy of the user space, so that changes made to the user space are visible only to this connection. Other connections still see information from the disk cache, which has not yet been changed. So, even though one process deals with changing data in the database, other processes can continue to read their own copies of the original content.
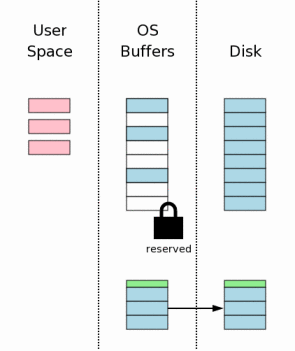
The next step is to reset the rollback journal from the cache to non-volatile memory. As we will see later, this is a very important step, which gives us a guarantee of data integrity in case of power failure. This step also takes a lot of time, since writing to non-volatile memory is usually a slow operation.
This step is usually more complicated than simply dumping the log to disk. On most platforms, you need to do two flushs (or fsyncs). The first flush writes the main contents of the log. Then the header of the log is changed to reflect the number of pages in the log. After that, the header is flushed to disk. The explanations for why we need this will be given below.

Before making changes in the database file itself, we must first obtain an exclusive lock on it. Getting such a lock consists of two steps. First, SQLite acquires a pending lock. Then this lock is translated into exclusive.
“Pending lock” allows other processes that already have joint lock on a file to continue reading from the file. But he forbids other processes to receive new joint locks. This is necessary so that the situation where the recording cannot be perfect, because of the large and constantly arriving number of read requests, did not work out. Each process first gets a shared lock before starting to read, after which it reads and resets the lock. When there are many processes that constantly need to be read, a situation may occur when each new process gets its lok before any of the existing ones releases its lok. Thus, there will never be a moment when there is not a single shared lock on the file, and accordingly it will not be possible to get an exclusive lock. A “pending” lock is needed to prevent the possibility of such a situation, preventing new joint locks from being received on a file, but allowing the existing ones to continue to live. When all shared locks are released, the pending lock can be transferred to the exclusive lock state.
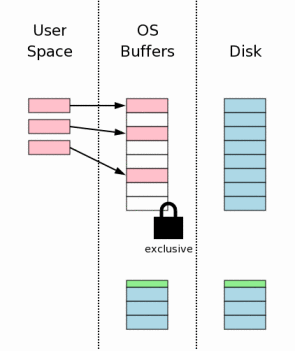
When an exclusive lock is obtained, we can be sure that no other process writes to this file and it is possible to make changes in it. Typically, these changes only reach the OS OS disk cache and are not flushed to the disk itself.
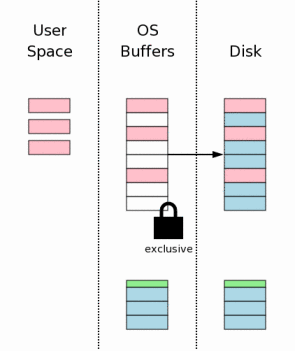
Now you need to call flush to be sure that all changes in the database are written to the energy-independent memory. This is a critical step to ensure that the data survive a further possible power outage. Due to the slowness of disks and flash memory, this step, along with writing a rollback log (p. 3.7), takes the most part of the time it takes to commit a transaction in SQLite.

After the changes have been saved to disk, we need to delete the rollback log. This is exactly the moment when we can say that the commit is completed successfully. If there is a power failure or some kind of system failure before deleting, then the base will be restored to its previous state - before the commit. If a power failure occurs after the rollback log is deleted, then the commit will be committed. Thus, the success of a commit in SQLite ultimately depends on whether the file with the log for rollback has been deleted or not.
Deleting a file is not really an atomic operation, but it looks like this from the point of view of the user process. A process can always ask the operating system: “Does this file exist?” And it will receive either “yes” or “no” in response. After a power failure that occurred during the commit of a transaction, SQLite will ask the operating system if there is a file with a transaction rollback log. If so, the transaction has not been completed and will be rolled back. If the answer was no, then the transaction was successfully completed.
The existence of an incomplete transaction depends on whether the rollback log file exists, and deleting it looks like an atomic operation from the end user's point of view. Consequently, the transaction looks like an atomic operation.
File deletion is an expensive operation on many systems. As an optimization, SQLite can cut to zero bytes in length, or fill the header with zeros. In any case, as a result, the log file will no longer be possible to read for rollback and the transaction will be commited. Trimming a file to zero in length, as well as deletion, is intended as an atomic operation from the point of view of the user process. Overwriting a log header with zeros is not atomic, but if any part of the header is damaged, the log will not be used for rollback. Thus, we can say that the commit occurred when the header of the redo log became invalid. This usually happens when only the first byte of the header is set to zero.

The final step of a commit is to unlock an exclusive lock so that other processes can access the database again.
In the figure on the right, we showed that the information that was in user memory was cleared after the lock was released. This was indeed the case in older versions of SQLite. But in newer versions of SQLite, information is stored in the user space in case it is needed for the next transaction. It is cheaper to use data that is already in memory, instead of getting it from disk cache or reading from the disk itself. Before using this data, we need to get the shared lock again, and also we need to make sure that no process has changed the state of the database until we had a lock. On the very first page in the database file there is a counter, which is incremented with each change. We can find out if the state of the database has changed by checking this counter. If changes were made to the database, then the user cache should be cleared and overheated. But more often it happens that no changes were made and the user cache can be used further, which gives a good performance boost.
Atomic commit should be made instantly. But all the actions described above obviously take some finite time to perform. Suppose the computer was turned off in the middle of the commit process described above. To maintain the illusion of instant changes, we must roll back all partial changes that were made and restore the state of the database to the original.

Suppose that a power failure occurred at step 3.10 when changes were written to disk. When power is restored, the situation will be somewhat similar to what is shown on the right in the figure. We tried to change three pages in the database file, but only one of them was successfully overwritten on disk. Another page was partially recorded, and the third remained in its original state.
The rollback log will be whole on the disk after power is restored. This is the key point. The reason for the need to flush in step 3.7 is to be absolutely sure that the entire rollback log is completely saved to non-volatile memory before any changes are made to the database file.
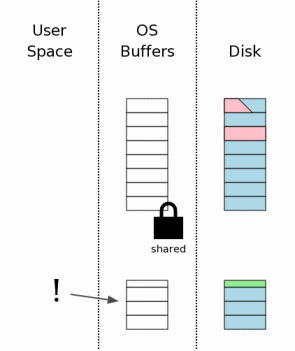
When the SQLite process first tries to access a database file, it first gets a shared lock on it, as described in section 3.2. But then he discovers that there is a rollback log. Then SQLite checks if this log is a “hot rollback log”. A hot log is a rollback log that must be applied to the database in order to restore it to an intact state. A hot log exists only when a process was at some step of a transaction commit and, for some reason, dropped at that moment.
The cooldown log is “hot” if all conditions are true:
The presence of a hot log is a signal that the previous process tried to commit a transaction, but failed for some reason. A hot log indicates that the database file is in inconsistent state and must be restored before use.
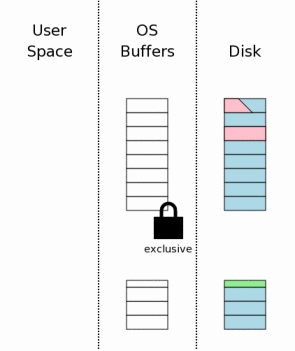
The first step before working with the hot log is getting an exclusive lock on the database file. This will prevent the possibility of a situation where two or more processes try to use the same hot log at one time.

Once a process receives an exclusive lock, it is allowed to write to the database file. Then he tries to read the original content of the pages from the rollback log and write it back to the base. Remember that the header of the log contains the size of the database file in its original state? SQLite uses this information to trim the database file to its original size in cases where an incomplete transaction caused the file to grow. After this step, the database must be the same size and contain exactly the same data that was before the unfinished transaction.
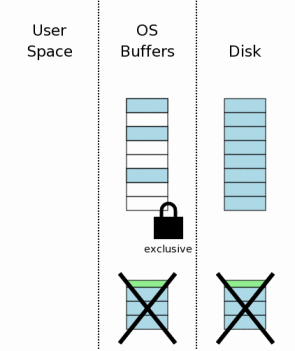
After the entire log has been applied to the database file (and also flushed to disk in case of another power loss), its (log) can be deleted.
As in section 3.11, the log file can be truncated to zero bytes in length, or its header can be overwritten with zeros. In any case, the log is no longer “hot” after this step.

The last recovery step is to change the exclusive lock to a joint one. When this happens, the database will be in such a state as if there was no roll back transaction. Since this entire recovery process occurs automatically and transparently for the user, it looks as if no recovery has taken place.
SQLite allows you to talk to two or more databases simultaneously from a single connection using the
When a transaction affects several database files, each of these files has its own rollback log and the lock on each file is obtained separately. The figure on the right shows the situation when three different database files were modified within the same transaction. The situation at this step is similar to a normal transaction over a single file from section 3.6. On each file of DB the reserving lock is hung up. For each database, the original contents of those pages that will now be changed were recorded in the corresponding rollback logs, but these logs have not yet been flushed to disk. The database files have not yet been changed, but the changes are already in the user memory of the process.
For brevity, the drawings in this section are simplified relative to those in the other sections. Blue color still means original information, and pink - new. But individual pages in the rollback logs are not shown in the database files, and we do not show what information is already on the disk, and what else is in the system cache. Nevertheless, all these factors still exist in a multi-file transaction, but they would take up a lot of space on the charts and would not give us much useful information, so here they are omitted.
 The next step in a multi-file transaction is to create a master log. The name of the master log is the same as the name of the original database file (to which the connection was opened) with the added line “-mjHHHHHHHH” (“mj” from the “master journal”), where HHHHHHHH is a random 32-bit value that is generated for each new master log.
The next step in a multi-file transaction is to create a master log. The name of the master log is the same as the name of the original database file (to which the connection was opened) with the added line “-mjHHHHHHHH” (“mj” from the “master journal”), where HHHHHHHH is a random 32-bit value that is generated for each new master log.
(This algorithm for generating the name of the master log file is only a detail of the implementation of SQLite 3.5.0. It is not specified in the specifications and can be changed in any new version)
Unlike redo logs, the master log does not contain any original content from the database pages. Instead, it contains the full paths to the rollback log files for each database that participates in the transaction.
After the master log has been compiled, its contents are flushed to disk. On Unix systems, the master log directory is also reset to ensure that the master log appears in this directory after a power failure.

The next step is to write the full path to the master log file to the header of each redo log. The place under the name of the master log file in the rollback log files was set aside before they were created.
The content of each rollback log is flushed to disk before and after writing the name of the master log to its header. It is important that we do exactly two data flushes. Fortunately, the second flush is usually inexpensive because usually only one page of the log file will be changed.

As the rollback log files were flushed to disk, we can start updating the database files. We need to get exclusive locks for all the files we are going to write changes to. After the changes are recorded, you will need to reset them to disk.
This step reflects sections 3.8, 3.9 and 3.10 from a single-file commit.
The next step is to delete the master log file. At this point, the transaction can be considered complete. This step reflects section 3.11 from a single-file commit where the rollback log is removed.
If at this moment there is a power failure or some kind of system failure, the transaction will not be rolled back after the system is restored, even if the rollback logs are still alive. Their headers contain the name of the master-log file, which means they will not be used if the master-log itself does not already exist.
The final step is to remove each of the rollback logs and reset the exclusive locks to the database files so that other processes can see the changes we have made.
At this point, the transaction is already considered completed, so the time spent deleting the logs is not so critical. In the current implementation, all logs are deleted one by one along with the removal of locks from the corresponding database files - first, the first log is deleted, and the corresponding lock is released, then the second log and lock, and so on. But in the future, we may change this behavior to one in which all logs will be deleted first, and then all locks will be removed. The main thing is that the removal of logs occurs before the release of locks, and not after.
Section 3.0 provides an overview of how atomic commits occur in SQLite, but several important details are omitted there. In the following subsections we will try to fill these gaps.
')
When the original data is written to the rollback log, SQLite always writes full sectors, even if the page size is smaller than the sector size. So historically, the sector size was zakardkozhen in SQLite code as 512 bytes and, since the minimum page size is also 512 bytes, this was never a problem. But starting with SQLite 3.3.14, it can work with larger sectors. So starting from this version, when any page is written to the rollback log, then another page can also be recorded with it that falls into the same sector on the disk.
It is important to secure all pages that are on the right sector in order to prevent the scenario with a sudden loss of energy during the recording sector. Suppose that pages 1, 2, 3, and 4 are all stored in sector 1, and that page 2 is modified. To write changes to page 2, the file system will also have to rewrite the contents of pages 1, 3, and 4, as it operates with whole sectors. If this write operation is interrupted by a loss of energy, any of pages 1, 3, or 4 may be left with incorrect data. Therefore, to avoid such a scenario, you need to save all these pages to the rollback log.
When data is written to a rollback log file, SQLite assumes that the file is first filled with “random” data (data that used to be in this place before the file grows and captures this part of the disk), and then it is replaced with valid data. In other words, SQLite assumes that at first the file size increases (it allocates (sorry, allocates) the space for it), and then only the data is written to it. If a power failure occurs after changing the file size, but before the data is written, the rollback log will contain bad data. After the restoration of energy supply, another SQLite process will see a rollback log file that contains garbage (“garbage data”) and will try to roll back based on it, thus the database will be corrupted.
SQLite uses two techniques to combat this problem. First, SQLite records the number of pages in the header of the redo log. This number is first written as zero. So during the attempt to rollback an incomplete log, the process will see that the log does not contain a single page and the rollback will not happen. Before a commit, the rollback log is flushed to the disk, and only after that the number of pages is corrected in the correct number. The header of the log is always written in a separate sector of the disk to ensure that rewriting does not harm the data pages in the event of a power failure. Note that the log is flushed to disk twice: first to record the content of the pages, and then to add the number of pages to the header.
The previous paragraph describes the behavior of SQLite under the
By default, this flag is set to
Signatures in the logs are optional if the
The commit process in section 3.0 assumes that all changes will fit into memory before completing the commit. This is the most likely case. But sometimes it happens that the changeset overflows the memory allocated for the user process. In such cases, the cache must be sent to the database before the transaction is completed.
At the very beginning of the dispatch, the database is in the state as shown in section 3.6. The original data was saved to the rollback log and changes are in user memory. To send the cache, SQLite goes through steps 3.7, 3.8 and 3.9. The log is flushed to disk, an exclusive lock is received on the database file and all changes are recorded. After that, one more header is added to the log at the end, and we return to step 3.6. When the transaction is completed, or if there is more data to write, we will return to step 3.7, then 3.9. (step 3.8 now we don’t need it, since we didn’t release the lock) (approx. lane: I didn’t understand nifiga in this chapter, it’s written very strangely, if you have ideas, write)
Tests say that in most cases, SQLite spends most of its time waiting to be written to disk. Accordingly, we must first optimize the recording and work with the disc. This section describes some of the techniques used by SQLite in trying to reduce the number of I / O operations to a minimum, while maintaining the integrity of the commit.
In step 3.12, you can see that once the joint lock is released, the entire user cache is cleared. This is done because when you are not sharing a file, other processes can change the database file and make your user cache obsolete. Consequently, each new transaction will begin with reading data from the database. This is not as bad as it may seem, since this data is most likely still in the disk cache of the operating system, so it will only be a copy of the data from the OS memory. But nevertheless, it takes time.
Starting with version 3.3.14, a mechanism has been added that reduces the likelihood that data will need to be re-read. The data in the user cache remains after the transaction, and before the next transaction, SQLite looks to see if the database file has been changed. If so, the user cache is reset. But often at this point the file will be in the same state, so that we avoid unnecessary reads.
To determine whether the database file has changed or not, SQLite uses a counter in the database header (from 24 to 27 bytes), which is incremented after each file change operation. A custom SQLite process maintains the state of the counter before completing the transaction. Then, after receiving the lock on the database, it compares the counter with what it was before the first transaction and, if the values differ, resets the cache.
SQLite 3.3.14 received a new feature, called "Exclusive Access Mode". In this mode, SQLite saves an exclusive lock to the database file after the transaction. This prevents the database from being accessed by other processes, but in most cases using SQLite, at one point in time only one process uses the database, so this is not a problem. Thus, the number of disk operations can be reduced by:
Part three of optimization, setting the log header instead of deleting the file, actually requires exclusive access mode, it can be enabled using the
When information is removed from the SQLite database, the pages that contained the deleted information are added to the “freelist”. Subsequent inserts will simply overwrite these pages in the database file, without the need for file extensions in sizes.
Some freelist pages contain important information, to be more precise, the locations of other freelist pages. But most of them contain nothing important. Those pages that are not critical are called leaf pages. We are free to change their contents, and the state of the database will not change at all.
Since the contents of leaf pages are so insignificant, SQLite avoids storing them in the redo logs in step 3.5 of the commit process. If the leaf page is changed and this change does not roll back during recovery, the database will not be damaged by this.
Starting with SQLite 3.5.0, the new Virtual File System (VFS) interface contains the
SQLite by default assumes that the disk produces a linear record, and not atomic. Linear recording starts from one end of a sector and, byte by byte, reaches its other end. If a power failure occurs during recording, then part of the sector may be damaged (contain old data). In the atomic sector recording, either the entire sector will be overwritten, or the entire sector will remain in its previous state.
Most modern disks support atomic sector recording. When power is lost, the disk uses the energy stored in its capacitors and / or the rotational energy of the pancake to complete all the scheduled recording tasks. Nevertheless, there are so many layers between the system call for recording and the electronics of the disk itself, that we decided to make a pessimistic assumption on all platforms that the sectors are written linearly.
When the record of sectors is atomic, and the size of the database page is equal to the size of the sector, if there is a need to change just one page, SQLite will skip the whole logging process, instead simply writing the changes directly to the database file. And the change counter will be incremented separately, since a power outage will not cause any harm here, even if it happens before the counter changes.
Another optimization, which was introduced in version 3.5.0, uses the safe append disk feature. As you remember, usually SQLite assumes that when a new piece of data is appended to a file, its size increases first, and then only the data is written. So if the disk loses energy between these events, the file will eventually contain dead data at the end. One of the methods in
With safe append enabled, SQLite leaves the number of pages in the rollback log header to be -1. When -1 is found in the log, the process understands that the number of pages needs to be calculated from the size of the log. Because of this, we save one flush operation.
On many systems, file deletion is a rather expensive operation. So in SQLite, you can disable the removal of logs. Instead, you can either trim the file to zero length, or fill in the header with zeros. Clipping a file is more profitable, because then you don’t need to touch the directory in which it is contained, because the file itself will remain in that case. Overwriting the header, on the other hand, allows you not to touch the length of the file (in the inode of this file) and not to waste time on the allocation of the newly freed sectors on the disk. Then, on the next transaction, the log will be created in an already existing file, overwriting it will also be faster than appending.
SQLite will stick to this strategy if you set the
Using this mode usually gives a noticeable performance boost on most systems. Of course there is a minus - the logs remain on the disk and eat up the place.The only safe way to remove such logs is to commit a transaction with a logging mode
If you try to delete the files manually, you can get into a situation where the logs still belong to an incomplete transaction.
Starting from version 3.6.4, the
In this mode, the log file size will be truncated to zero bytes. This strategy is also good because the directory in which the file is stored will not be affected. So, often, clipping a file is faster than deleting. Also, it
On embedded systems with a synchronous file system, TRUNCATE usually runs slower than PERSIST. The first commit is the same in speed, but subsequent transactions are slower, since overwriting data is faster than appending to the end of the file. New logs will always be added after TRUNCATE, while with a persistent strategy they will overwrite old ones.
SQLite developers are confident that this system is reliable in the face of a power failure and various system failures. Automatic testing procedures test SQLite for the ability to recover from simulated failures. We call it "crash tests."
SQLite VFS, , - . , «» - . , — , , . . , .
SQLite , , , . , .
SQLite , , . , VFS . SQLite , - , .
- NFS, . , , , . SQLite - .
SQLite, Max OS X , , Apple. , , . , () , AFP , dot-file (, ), , .
SQLite
Mac
SQLite assumes that deleting a file is an atomic operation from the point of view of the user process. If there is a loss of energy during the deletion of the file, SQLite expects that the file will either be saved completely or be deleted. Transactions cannot be considered atomic on systems that work differently.
The SQLite database is in regular files on disk that can be opened by other processes and modified. Any process can open a database file and fill it with “bad” data. SQLite can do nothing to protect against such interference.
, , , . SQLite , . , .
, , , .
( ) , , . ( ), .
,
3.0 Single File Commit
We begin by reviewing the steps SQLite is taking to commit an atomic commit to a transaction that affects only one database file. Details of the file format used to protect against damage to the database and equipment that are used for a commit to several databases will be shown below.
3.1 Initial state
The state of the system, when the connection with the database has just been raised, is superficially depicted in the figure to the right. The right shows information stored on an energy-independent storage medium. Each rectangle is a sector. The blue color indicates that this sector contains the original data. In the middle is the disk cache of the operating system. At the very beginning of our example, the cache is cold, it is shown in white. On the left side of the figure - the contents of the process memory that uses SQLite. The connection to the database has just been opened, and no information has been read.
3.2 Getting a read lock
Before SQLite can start writing, it must first know what is already there. Even if it is just inserting new data, it needs to read the schema from the sqlite_master table so that it knows how to parse the INSERT query and understand where to write the data.
The first step is to obtain shared lock (shared lock) on the database file. Joint blocking allows two or more connections to read from a file at the same time. But this type of blocking prohibits other connections from recording until it is removed. This is mandatory, as if another connection made a record at the same time, we could read a part of the unchanged data and another part of the data after the change. Then the record could be considered non-atomic.
Note that the lock was installed on the OS and the disk cache, and not on the disk itself. File locks are usually just flags controlled by the system kernel. They will be reset for any system crash or power failure. Also, they are usually reset when the process that received the lock dies.
3.3 Reading information from a database
After the lock has been acquired, we can start reading from the database file. In this scenario, we mean that the cache is not yet warmed up, so the information must first be read from the data collector to the operating system cache, and then it can be moved from the OS cache to user space. On subsequent readings, all or some of the information will already be in the cache, so it will only need to be given to the user space.
Usually only a small part of the pages will be read from the database file. In our example, we see that out of eight pages, only three have been read. In a typical database application, there will be thousands of pages and the request will affect a very small percentage of them.
3.4 Getting a “Reserving” Block
Before you make any changes to the database, SQLite first gets a “backup” lock (reserved lock) on the database file (approx. Lane is the most tolerable translation that came to my mind). Such a lock is similar to a joint one in that it also allows other processes to read from the database file. One reserving lock can coexist with several joint. However, only one reserving lock per file can exist at a time. Thus, only one process can write to the database at a time.
The idea of a reserving lock is that it says that the process intends to start writing to the file in the near future, but so far it has not begun to do this. And, since the changes have not yet begun to be written, other processes can continue reading from the database. But no processes can no longer initiate a recording while the lock is alive.
3.5 Creating a rollback log
Before you start writing to the database file, SQLite first creates a separate log for rolling back the changes, and writes the original database pages to it, which will be changed. The rollback log contains all the necessary information to roll back the database to its original state before the transaction.
The rollback log contains a small header (shown in green in the diagram), which contains the size of the database file in its original state. So, if after changing the database file will grow in size, we will still know its original size. The page number is stored next to each page in the log.
When a new file is created, most operating systems (Windows, Linux, Mac OS X) will not actually write anything to disk. A new file is created only in the cache of the operating system. The file is not created on the drive until the operating system finds a suitable time for this. This makes it appear to the user that the I / O operations on the drive are performed much faster than is possible. We depicted this process in the diagram on the right, showing that the rollback log appeared only in the disk cache, but not on the disk itself.
3.6 Changing DB pages in user space
After the original content has been saved to the redo log, the pages can be changed in user memory. Each connection to the database has its own private copy of the user space, so that changes made to the user space are visible only to this connection. Other connections still see information from the disk cache, which has not yet been changed. So, even though one process deals with changing data in the database, other processes can continue to read their own copies of the original content.
3.7 Resetting the rollback log to drive
The next step is to reset the rollback journal from the cache to non-volatile memory. As we will see later, this is a very important step, which gives us a guarantee of data integrity in case of power failure. This step also takes a lot of time, since writing to non-volatile memory is usually a slow operation.
This step is usually more complicated than simply dumping the log to disk. On most platforms, you need to do two flushs (or fsyncs). The first flush writes the main contents of the log. Then the header of the log is changed to reflect the number of pages in the log. After that, the header is flushed to disk. The explanations for why we need this will be given below.
3.8 Getting an exclusive lock
Before making changes in the database file itself, we must first obtain an exclusive lock on it. Getting such a lock consists of two steps. First, SQLite acquires a pending lock. Then this lock is translated into exclusive.
“Pending lock” allows other processes that already have joint lock on a file to continue reading from the file. But he forbids other processes to receive new joint locks. This is necessary so that the situation where the recording cannot be perfect, because of the large and constantly arriving number of read requests, did not work out. Each process first gets a shared lock before starting to read, after which it reads and resets the lock. When there are many processes that constantly need to be read, a situation may occur when each new process gets its lok before any of the existing ones releases its lok. Thus, there will never be a moment when there is not a single shared lock on the file, and accordingly it will not be possible to get an exclusive lock. A “pending” lock is needed to prevent the possibility of such a situation, preventing new joint locks from being received on a file, but allowing the existing ones to continue to live. When all shared locks are released, the pending lock can be transferred to the exclusive lock state.
3.9 Writing data to a database file
When an exclusive lock is obtained, we can be sure that no other process writes to this file and it is possible to make changes in it. Typically, these changes only reach the OS OS disk cache and are not flushed to the disk itself.
3.10 Resetting data to the drive
Now you need to call flush to be sure that all changes in the database are written to the energy-independent memory. This is a critical step to ensure that the data survive a further possible power outage. Due to the slowness of disks and flash memory, this step, along with writing a rollback log (p. 3.7), takes the most part of the time it takes to commit a transaction in SQLite.
3.11 Deleting a redo log
After the changes have been saved to disk, we need to delete the rollback log. This is exactly the moment when we can say that the commit is completed successfully. If there is a power failure or some kind of system failure before deleting, then the base will be restored to its previous state - before the commit. If a power failure occurs after the rollback log is deleted, then the commit will be committed. Thus, the success of a commit in SQLite ultimately depends on whether the file with the log for rollback has been deleted or not.
Deleting a file is not really an atomic operation, but it looks like this from the point of view of the user process. A process can always ask the operating system: “Does this file exist?” And it will receive either “yes” or “no” in response. After a power failure that occurred during the commit of a transaction, SQLite will ask the operating system if there is a file with a transaction rollback log. If so, the transaction has not been completed and will be rolled back. If the answer was no, then the transaction was successfully completed.
The existence of an incomplete transaction depends on whether the rollback log file exists, and deleting it looks like an atomic operation from the end user's point of view. Consequently, the transaction looks like an atomic operation.
File deletion is an expensive operation on many systems. As an optimization, SQLite can cut to zero bytes in length, or fill the header with zeros. In any case, as a result, the log file will no longer be possible to read for rollback and the transaction will be commited. Trimming a file to zero in length, as well as deletion, is intended as an atomic operation from the point of view of the user process. Overwriting a log header with zeros is not atomic, but if any part of the header is damaged, the log will not be used for rollback. Thus, we can say that the commit occurred when the header of the redo log became invalid. This usually happens when only the first byte of the header is set to zero.
3.12. Unlocking
The final step of a commit is to unlock an exclusive lock so that other processes can access the database again.
In the figure on the right, we showed that the information that was in user memory was cleared after the lock was released. This was indeed the case in older versions of SQLite. But in newer versions of SQLite, information is stored in the user space in case it is needed for the next transaction. It is cheaper to use data that is already in memory, instead of getting it from disk cache or reading from the disk itself. Before using this data, we need to get the shared lock again, and also we need to make sure that no process has changed the state of the database until we had a lock. On the very first page in the database file there is a counter, which is incremented with each change. We can find out if the state of the database has changed by checking this counter. If changes were made to the database, then the user cache should be cleared and overheated. But more often it happens that no changes were made and the user cache can be used further, which gives a good performance boost.
4.0 Rollback
Atomic commit should be made instantly. But all the actions described above obviously take some finite time to perform. Suppose the computer was turned off in the middle of the commit process described above. To maintain the illusion of instant changes, we must roll back all partial changes that were made and restore the state of the database to the original.
4.1 When something goes wrong
Suppose that a power failure occurred at step 3.10 when changes were written to disk. When power is restored, the situation will be somewhat similar to what is shown on the right in the figure. We tried to change three pages in the database file, but only one of them was successfully overwritten on disk. Another page was partially recorded, and the third remained in its original state.
The rollback log will be whole on the disk after power is restored. This is the key point. The reason for the need to flush in step 3.7 is to be absolutely sure that the entire rollback log is completely saved to non-volatile memory before any changes are made to the database file.
4.2 Hot Rollback Logs
When the SQLite process first tries to access a database file, it first gets a shared lock on it, as described in section 3.2. But then he discovers that there is a rollback log. Then SQLite checks if this log is a “hot rollback log”. A hot log is a rollback log that must be applied to the database in order to restore it to an intact state. A hot log exists only when a process was at some step of a transaction commit and, for some reason, dropped at that moment.
The cooldown log is “hot” if all conditions are true:
- Redo log exists
- Rollback log is not an empty file
- There is no “reserved” lock on the database file
- The header of the log file is valid and has not been corrupted.
- The redo log does not contain the name of the redo master log file (see 5.5), or if it does, this file exists
The presence of a hot log is a signal that the previous process tried to commit a transaction, but failed for some reason. A hot log indicates that the database file is in inconsistent state and must be restored before use.
4.3 Obtaining an exclusive lock on a database file
The first step before working with the hot log is getting an exclusive lock on the database file. This will prevent the possibility of a situation where two or more processes try to use the same hot log at one time.
4.4 Rolling back incomplete changes
Once a process receives an exclusive lock, it is allowed to write to the database file. Then he tries to read the original content of the pages from the rollback log and write it back to the base. Remember that the header of the log contains the size of the database file in its original state? SQLite uses this information to trim the database file to its original size in cases where an incomplete transaction caused the file to grow. After this step, the database must be the same size and contain exactly the same data that was before the unfinished transaction.
4.5 Removing a hot log
After the entire log has been applied to the database file (and also flushed to disk in case of another power loss), its (log) can be deleted.
As in section 3.11, the log file can be truncated to zero bytes in length, or its header can be overwritten with zeros. In any case, the log is no longer “hot” after this step.
4.6 We continue as if there were no pending transactions.
The last recovery step is to change the exclusive lock to a joint one. When this happens, the database will be in such a state as if there was no roll back transaction. Since this entire recovery process occurs automatically and transparently for the user, it looks as if no recovery has taken place.
5.0 Commit to multiple files
SQLite allows you to talk to two or more databases simultaneously from a single connection using the
ATTACH DATABASE . When multiple database files are changed within a single transaction, all files are updated atomically. In other words, either all of them are updated, or none of them will be updated. Reaching the atomic update of several files is a bit more complicated than just one. In this section, all the magic behind this will be described.5.1 Separate log backlog for each database
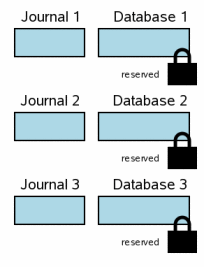
When a transaction affects several database files, each of these files has its own rollback log and the lock on each file is obtained separately. The figure on the right shows the situation when three different database files were modified within the same transaction. The situation at this step is similar to a normal transaction over a single file from section 3.6. On each file of DB the reserving lock is hung up. For each database, the original contents of those pages that will now be changed were recorded in the corresponding rollback logs, but these logs have not yet been flushed to disk. The database files have not yet been changed, but the changes are already in the user memory of the process.
For brevity, the drawings in this section are simplified relative to those in the other sections. Blue color still means original information, and pink - new. But individual pages in the rollback logs are not shown in the database files, and we do not show what information is already on the disk, and what else is in the system cache. Nevertheless, all these factors still exist in a multi-file transaction, but they would take up a lot of space on the charts and would not give us much useful information, so here they are omitted.
5.2 Master log file
The next step in a multi-file transaction is to create a master log. The name of the master log is the same as the name of the original database file (to which the connection was opened) with the added line “-mjHHHHHHHH” (“mj” from the “master journal”), where HHHHHHHH is a random 32-bit value that is generated for each new master log.(This algorithm for generating the name of the master log file is only a detail of the implementation of SQLite 3.5.0. It is not specified in the specifications and can be changed in any new version)
Unlike redo logs, the master log does not contain any original content from the database pages. Instead, it contains the full paths to the rollback log files for each database that participates in the transaction.
After the master log has been compiled, its contents are flushed to disk. On Unix systems, the master log directory is also reset to ensure that the master log appears in this directory after a power failure.
5.3 Update rollback log headers
The next step is to write the full path to the master log file to the header of each redo log. The place under the name of the master log file in the rollback log files was set aside before they were created.
The content of each rollback log is flushed to disk before and after writing the name of the master log to its header. It is important that we do exactly two data flushes. Fortunately, the second flush is usually inexpensive because usually only one page of the log file will be changed.
5.4 Updating Database Files
As the rollback log files were flushed to disk, we can start updating the database files. We need to get exclusive locks for all the files we are going to write changes to. After the changes are recorded, you will need to reset them to disk.
This step reflects sections 3.8, 3.9 and 3.10 from a single-file commit.
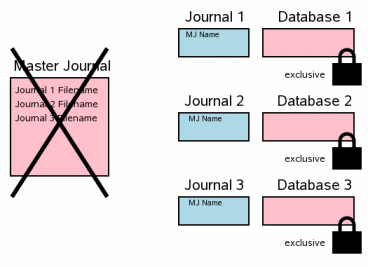
5.5 Delete Master Log
The next step is to delete the master log file. At this point, the transaction can be considered complete. This step reflects section 3.11 from a single-file commit where the rollback log is removed.
If at this moment there is a power failure or some kind of system failure, the transaction will not be rolled back after the system is restored, even if the rollback logs are still alive. Their headers contain the name of the master-log file, which means they will not be used if the master-log itself does not already exist.
5.6 Clearing the rollback logs
The final step is to remove each of the rollback logs and reset the exclusive locks to the database files so that other processes can see the changes we have made.
At this point, the transaction is already considered completed, so the time spent deleting the logs is not so critical. In the current implementation, all logs are deleted one by one along with the removal of locks from the corresponding database files - first, the first log is deleted, and the corresponding lock is released, then the second log and lock, and so on. But in the future, we may change this behavior to one in which all logs will be deleted first, and then all locks will be removed. The main thing is that the removal of logs occurs before the release of locks, and not after.
6.0 Additional details of the commit process
Section 3.0 provides an overview of how atomic commits occur in SQLite, but several important details are omitted there. In the following subsections we will try to fill these gaps.
')
6.1 Always whole disk sectors are logged.
When the original data is written to the rollback log, SQLite always writes full sectors, even if the page size is smaller than the sector size. So historically, the sector size was zakardkozhen in SQLite code as 512 bytes and, since the minimum page size is also 512 bytes, this was never a problem. But starting with SQLite 3.3.14, it can work with larger sectors. So starting from this version, when any page is written to the rollback log, then another page can also be recorded with it that falls into the same sector on the disk.
It is important to secure all pages that are on the right sector in order to prevent the scenario with a sudden loss of energy during the recording sector. Suppose that pages 1, 2, 3, and 4 are all stored in sector 1, and that page 2 is modified. To write changes to page 2, the file system will also have to rewrite the contents of pages 1, 3, and 4, as it operates with whole sectors. If this write operation is interrupted by a loss of energy, any of pages 1, 3, or 4 may be left with incorrect data. Therefore, to avoid such a scenario, you need to save all these pages to the rollback log.
6.2 What to do with bad data in the logs
When data is written to a rollback log file, SQLite assumes that the file is first filled with “random” data (data that used to be in this place before the file grows and captures this part of the disk), and then it is replaced with valid data. In other words, SQLite assumes that at first the file size increases (it allocates (sorry, allocates) the space for it), and then only the data is written to it. If a power failure occurs after changing the file size, but before the data is written, the rollback log will contain bad data. After the restoration of energy supply, another SQLite process will see a rollback log file that contains garbage (“garbage data”) and will try to roll back based on it, thus the database will be corrupted.
SQLite uses two techniques to combat this problem. First, SQLite records the number of pages in the header of the redo log. This number is first written as zero. So during the attempt to rollback an incomplete log, the process will see that the log does not contain a single page and the rollback will not happen. Before a commit, the rollback log is flushed to the disk, and only after that the number of pages is corrected in the correct number. The header of the log is always written in a separate sector of the disk to ensure that rewriting does not harm the data pages in the event of a power failure. Note that the log is flushed to disk twice: first to record the content of the pages, and then to add the number of pages to the header.
The previous paragraph describes the behavior of SQLite under the
PRAGMA synchronous=FULL; flag PRAGMA synchronous=FULL;By default, this flag is set to
FULL , if it is set to NORMAL , SQLite will reset the log only once, after recording the number of pages. This entails the risk of data corruption, as it may happen that the number of pages is recorded before the database pages. Although the data pages were sent to the record first, SQLite assumes that the file system can reorganize the order of tasks for writing, and accordingly write the number of pages in the first place. As another protection against this, SQLite uses 32-bit signatures (hashes) for each page in the redo log. If it turns out that some page in the log does not match its signature, then the rollback is canceled.Signatures in the logs are optional if the
synchronous flag is set to FULL . We only need them if this flag is NORMAL . However, they never hurt, so we include them in the logs in all modes.6.3 Cache overflow during commit
The commit process in section 3.0 assumes that all changes will fit into memory before completing the commit. This is the most likely case. But sometimes it happens that the changeset overflows the memory allocated for the user process. In such cases, the cache must be sent to the database before the transaction is completed.
At the very beginning of the dispatch, the database is in the state as shown in section 3.6. The original data was saved to the rollback log and changes are in user memory. To send the cache, SQLite goes through steps 3.7, 3.8 and 3.9. The log is flushed to disk, an exclusive lock is received on the database file and all changes are recorded. After that, one more header is added to the log at the end, and we return to step 3.6. When the transaction is completed, or if there is more data to write, we will return to step 3.7, then 3.9. (step 3.8 now we don’t need it, since we didn’t release the lock) (approx. lane: I didn’t understand nifiga in this chapter, it’s written very strangely, if you have ideas, write)
7.0 Optimization
Tests say that in most cases, SQLite spends most of its time waiting to be written to disk. Accordingly, we must first optimize the recording and work with the disc. This section describes some of the techniques used by SQLite in trying to reduce the number of I / O operations to a minimum, while maintaining the integrity of the commit.
7.1 Saving cache between transactions
In step 3.12, you can see that once the joint lock is released, the entire user cache is cleared. This is done because when you are not sharing a file, other processes can change the database file and make your user cache obsolete. Consequently, each new transaction will begin with reading data from the database. This is not as bad as it may seem, since this data is most likely still in the disk cache of the operating system, so it will only be a copy of the data from the OS memory. But nevertheless, it takes time.
Starting with version 3.3.14, a mechanism has been added that reduces the likelihood that data will need to be re-read. The data in the user cache remains after the transaction, and before the next transaction, SQLite looks to see if the database file has been changed. If so, the user cache is reset. But often at this point the file will be in the same state, so that we avoid unnecessary reads.
To determine whether the database file has changed or not, SQLite uses a counter in the database header (from 24 to 27 bytes), which is incremented after each file change operation. A custom SQLite process maintains the state of the counter before completing the transaction. Then, after receiving the lock on the database, it compares the counter with what it was before the first transaction and, if the values differ, resets the cache.
7.2 Exclusive Access Mode
SQLite 3.3.14 received a new feature, called "Exclusive Access Mode". In this mode, SQLite saves an exclusive lock to the database file after the transaction. This prevents the database from being accessed by other processes, but in most cases using SQLite, at one point in time only one process uses the database, so this is not a problem. Thus, the number of disk operations can be reduced by:
- No need to increment the counter after the first transaction. This will often save you the operation of writing the first page to the rollback log and to the database file itself.
- Other processes cannot change the database, so you don’t need to check the aforementioned counter each time and never need to clean the user cache.
- Each transaction can overwrite the previous log, the title of which was filled with zeros, instead of deleting the file. Due to this, we don’t need to touch the directory with the log file, and also deploy the disk sectors on which the log was located. Thus, the next transaction will simply overwrite the previous log, instead of creating a new one and writing data to it, because in most systems, rewriting is much cheaper.
Part three of optimization, setting the log header instead of deleting the file, actually requires exclusive access mode, it can be enabled using the
journal_mode_pragma directive, as described in section 7.6 below.7.3 Do not log freelist pages
When information is removed from the SQLite database, the pages that contained the deleted information are added to the “freelist”. Subsequent inserts will simply overwrite these pages in the database file, without the need for file extensions in sizes.
Some freelist pages contain important information, to be more precise, the locations of other freelist pages. But most of them contain nothing important. Those pages that are not critical are called leaf pages. We are free to change their contents, and the state of the database will not change at all.
Since the contents of leaf pages are so insignificant, SQLite avoids storing them in the redo logs in step 3.5 of the commit process. If the leaf page is changed and this change does not roll back during recovery, the database will not be damaged by this.
7.4 One page changes and atomic sector records
Starting with SQLite 3.5.0, the new Virtual File System (VFS) interface contains the
xDeviceCharacteristics method, which returns the storage properties (disk). Among these properties is the possibility of atomic sector recording.SQLite by default assumes that the disk produces a linear record, and not atomic. Linear recording starts from one end of a sector and, byte by byte, reaches its other end. If a power failure occurs during recording, then part of the sector may be damaged (contain old data). In the atomic sector recording, either the entire sector will be overwritten, or the entire sector will remain in its previous state.
Most modern disks support atomic sector recording. When power is lost, the disk uses the energy stored in its capacitors and / or the rotational energy of the pancake to complete all the scheduled recording tasks. Nevertheless, there are so many layers between the system call for recording and the electronics of the disk itself, that we decided to make a pessimistic assumption on all platforms that the sectors are written linearly.
When the record of sectors is atomic, and the size of the database page is equal to the size of the sector, if there is a need to change just one page, SQLite will skip the whole logging process, instead simply writing the changes directly to the database file. And the change counter will be incremented separately, since a power outage will not cause any harm here, even if it happens before the counter changes.
7.5 File systems with safe append
Another optimization, which was introduced in version 3.5.0, uses the safe append disk feature. As you remember, usually SQLite assumes that when a new piece of data is appended to a file, its size increases first, and then only the data is written. So if the disk loses energy between these events, the file will eventually contain dead data at the end. One of the methods in
xDeviceCharacteristics tells us whether the disk can make a safe append. This feature is implemented in such a way that the disk, on the contrary, will first write the data to the “pre-allocated” area, after which it will increase the file size and give that area to this file. Thus, the loss of energy is not terrible even during recording (in fact, it is an atomic append).With safe append enabled, SQLite leaves the number of pages in the rollback log header to be -1. When -1 is found in the log, the process understands that the number of pages needs to be calculated from the size of the log. Because of this, we save one flush operation.
7.6 Failure to delete logs
On many systems, file deletion is a rather expensive operation. So in SQLite, you can disable the removal of logs. Instead, you can either trim the file to zero length, or fill in the header with zeros. Clipping a file is more profitable, because then you don’t need to touch the directory in which it is contained, because the file itself will remain in that case. Overwriting the header, on the other hand, allows you not to touch the length of the file (in the inode of this file) and not to waste time on the allocation of the newly freed sectors on the disk. Then, on the next transaction, the log will be created in an already existing file, overwriting it will also be faster than appending.
SQLite will stick to this strategy if you set the
journal_mode option to PERSIST . ( PRAGMA journal_mode=PERSIST )Using this mode usually gives a noticeable performance boost on most systems. Of course there is a minus - the logs remain on the disk and eat up the place.The only safe way to remove such logs is to commit a transaction with a logging mode
DELETE: PRAGMA journal_mode=DELETE BEGIN EXCLUSIVE COMMIT; If you try to delete the files manually, you can get into a situation where the logs still belong to an incomplete transaction.
Starting from version 3.6.4, the
TRUNCATEfollowing mode is also supported : PRAGMA journal_mode=TRUNCATE In this mode, the log file size will be truncated to zero bytes. This strategy is also good because the directory in which the file is stored will not be affected. So, often, clipping a file is faster than deleting. Also, it
TRUNCATEdoes not require a system call to synchronize the state to disk (fsync, flush). But with such a challenge it would be safer. But on most file systems, TRUNCATE is an atomic and synchronous operation, so most likely it will be safe, even with energy loss. If you are not sure whether your file system supports atomic TRUNCATE, and data integrity is important to you, then it is better to choose another logging strategy.On embedded systems with a synchronous file system, TRUNCATE usually runs slower than PERSIST. The first commit is the same in speed, but subsequent transactions are slower, since overwriting data is faster than appending to the end of the file. New logs will always be added after TRUNCATE, while with a persistent strategy they will overwrite old ones.
8.0 Testing Atomic Commit
SQLite developers are confident that this system is reliable in the face of a power failure and various system failures. Automatic testing procedures test SQLite for the ability to recover from simulated failures. We call it "crash tests."
SQLite VFS, , - . , «» - . , — , , . . , .
9.0
SQLite , , , . , .
9.1
SQLite , , . , VFS . SQLite , - , .
- NFS, . , , , . SQLite - .
SQLite, Max OS X , , Apple. , , . , () , AFP , dot-file (, ), , .
9.2
SQLite
fsync Unix- FlushFileBuffers win32, . , , , . FlushFileBuffers Windows. Linux fsync , . , , , , , , , .Mac
PRAGMA fillfsync=ON;That will guarantee a complete reset of data on the pancakes of the disk, and not just in the disk cache. But the implementation of fullfsync is rather slow and will slow down other disk operations.9.3 Incomplete file deletion
SQLite assumes that deleting a file is an atomic operation from the point of view of the user process. If there is a loss of energy during the deletion of the file, SQLite expects that the file will either be saved completely or be deleted. Transactions cannot be considered atomic on systems that work differently.
9.4 Modification of the database file from the outside
The SQLite database is in regular files on disk that can be opened by other processes and modified. Any process can open a database file and fill it with “bad” data. SQLite can do nothing to protect against such interference.
9.5
, , , . SQLite , . , .
, , , .
( ) , , . ( ), .
,
/lost+found . , , . SQLite (fsync) . , - , , . , SQLite, , . , ( , ), SQLite .Source: https://habr.com/ru/post/181584/
All Articles