In the wake of intelligence 2
Some people think that they are thinking, while they are simply rearranging their prejudices.
Long time ago I wrote a review article on the evolution of neuron modeling methods and abandoned this case. The description includes old and well-known methods for all interested neurons, one might say, we got a review of textbooks issued before the collapse of the USSR. If anyone is interested can go habrahabr.ru/post/101020 , see the old review. Now I have gathered a few material from my point of view fascinating and more modern methods of modeling, which deserve mention in the form of a structured review. Here I will only mention these methods in a descriptive order, for the simple reason that for the majority it is more interesting to know why we use it, and not how it works and how to use it. The volume of the text will significantly decrease, the interestingness will increase, and how these methods actually work, everyone can find himself.
So get ready.
Awful incomprehensible jumble of clever words. This method was described in article habrahabr.ru/post/146077 where it was transferred to a less frightening form. There he was called asynchronous gradient descent (asynchronous SGD). I tried to figure it out and clung to the English name "asynchronous SGD".
The first to mention is the gradient descent method itself. This is a method for finding the local minimum or maximum of a function. If you had a tower, you should have a vague understanding of what is being discussed here. In general, it is used as an optimization algorithm, and if you work with neural networks, then calmly call it a machine learning algorithm.
')
Now add the word "stochastic". Why is this necessary for our method? What is the use of it? This method uses only one example from the student set at a time, unlike other methods that use the entire set at once. The point is that you can add more data for additional training or stop training if you are tired of waiting and you want to see the training results on the processed part of the data.
There is a compromise between these two (conventional and stochastic) gradient descent types, called “mini-batch” (mini-batches). In this case, small packs of training samples are used. It is this method with small batches that is most appropriate for distributing computations among multiple computers on a network.
Now, regarding asynchrony and distribution - using distributed asynchronous data processing (Asynchronous peer-to-peer). In this case, several mini-batches are processed simultaneously on their computers in the peer-to-peer network, allowing you to continue learning with any number and any combination of available nodes. No one waits until all computers have completed their calculations for the last batch to update the overall model. For each batch they use potentially different and, as a rule, obsolete parameters of the model. This is the main and main drawback. The advantage is that all the machines involved in the optimization are busy with calculations all the time, and we can add and turn off the machines during the learning process. The disadvantage is leveled by the fact that with data homogeneity, the model still converges (optimized, trained). I did not dare to go to work proving this statement. I can only share the link simply enough setting forth the principle of the asynchronous “data mining” method in the peer-to-peer network. Maybe someone needs, it's interesting in itself. Now you do not need a supercomputer, you need friends in the network.
http://www.inf.u-szeged.hu/~ormandi/presentations/europar2011.pdf
On foreign it sounds like “Sparse Distributed Representations”.
The main point of this method is to slash the property of biological neural networks. Although neurons in the cerebral cortex are very tightly interconnected, numerous suppressive (inhibitory) neurons ensure that only a small percentage of all neurons will be active at the same time, and they are usually quite spaced apart. That is, information is always presented in the brain only by a small number of active neurons from all those present there. This type of information coding is called “sparse distributed representation”.
There is also a sparse autoencoder method “Sparse Autoencoder”, read here habrahabr.ru/post/134950 , but its meaning is the same, just to slash the property of a biological neural network.
Let's return to our method. “Sparse” is the requirement that only a small percentage of the layer's neurons can be simultaneously active. What way you achieve it is not important. The underlying principle remains the same, as in the encoder, and in sparse representations. The main thing is that the dimensionality of the input data for the next layer decreases, data is compressed, as the network must find hidden relationships, correlations of features, and in general no frequent structure in the data.
“Distributed” is also a requirement that in order to represent something in a neural network layer, it is necessary to activate that very small percentage of neurons, while neurons are scattered across the layer remotely from each other. A surplus of silent neurons is also bad. A sufficient number of active neurons in the layer allows you to avoid trivial patterns while finding those most hidden relationships and correlations. The activity of a single neuron, of course, also means something; let us recall the "grandmother's neuron", but the activity should be interpreted only in the context of many other neurons. A single activity will not go up the layer hierarchy. In fact, the activity of the neurons of the last layer will represent a picture of the world through the receptive field of our neural network.
In conclusion, I can say that such a presentation of information in the neural network just leads to the formation of the notorious "grandmother's neurons." If you do not understand what it is about, take a look at the picture, this image corresponds to the maximum stimulus for a neuron engaged in the recognition of the cat's muzzle from the article habrahabr.ru/post/153945 . Pure "concept of a muzzle of a cat".

Or watch 5 minutes of the speech of Comrade Anokhin from the specified time 49:15 . Based on his words, it can be argued that there is a neuron in your brain responsible for the concept of citizen Sasha Gray.
This is the rule of good tone in the simulation of neural networks. Depending on the methods used and the model of neurons, you can get different buns. I don't even want to list, just take my word for it. Local receptive fields are our everything.
Of course, it is worthwhile to stipulate that the greatest advantage of this method is obtained with the homogeneity of the input data. A simple example is visual data. The neurons from the first layer on such data by the method of sparse representations will learn to recognize the same simplest elements of the contours from different angles, which fits very well with the biology of the brain.

The separation of dendrites by type is a remarkable innovation in the modeling of neurons, opening up limitless possibilities for experimentation. This principle becomes a new trend in the modeling of neurons both in the west and here, although the paths that led to this decision are different. In the west, this principle is attempted to bring a biological basis; now they say that neurons of the fourth neocortex accept synapses from other layers and other brain regions to dendrites close to the body of cells, and communicate with each other only through remote dendrites in the layer.
We also do not refuse such a basis, but in addition criticize the hypothesis of the summation of excitations on a single neuron.
We now turn to the opened possibilities of modeling. We can assign different rules for the response of a neuron to signals from different types of dendrites, set rules for the transition of dendrites from one type to another. Naturally, the introduction of various types affects the operation of the entire neural network as a whole, so many excellent proposals for the rules are not viable within the entire neural network. But there are already several well-established and well-manifested models of neurons with the separation of dendrites by type.
Below I will talk about new properties of neural networks, which coincide with the properties of human memory and which can be obtained by separating dendrites into types. In each particular case of the method used, the property may have a different name (the name is always the arbitrariness of the author of the method) and seriously differ in the implementation mechanism, but this does not negate the similarity of the underlying principle.
And first, take a look at the structural diagram of the neuron model from the “Hierarchical Temporal Memory” method.
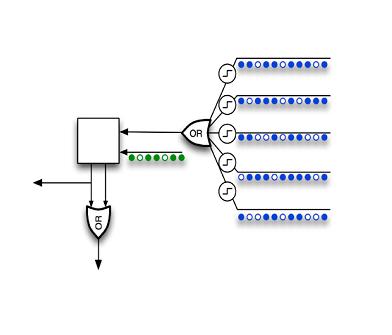
The principle is in the separation of dendrites into two types and the logical coupling of signals at their inputs.
The dendrites of the first type, which can be called the “permanent memory” dendrites, work according to quite usual rules of neuron modeling. There is no innovation here; you can use any old rules you know that came up with neural networks without splitting inputs into types, for example, something like the rule “If a signal arrives at the desired set of inputs, then the neuron is activated”. For the triggering of such a rule, the neuron must recognize the pattern, and for convenience we will call it the “permanent memory triggering”.
The second type of dendrites, which can be called the “associative memory” dendrites, work according to new, but intuitively understandable rules. Here lies the innovation in modeling. The basic principle of such rules can be expressed in the following words: “The inputs of an associative dendrite can force a neuron to activate, if permanent memory has not worked. Input associativity increases if it is active when the persistent memory is activated. ” If someone does not understand, then we work on the same neuron the conditioned reflex of a comrade and academician Pavlov. In this case, the dogs do not suffer.
You should not assume that the principle is too simple, depending on the implementation, you will encounter the complexity of the rules and the many features of modeling. For example, associativity can increase both from the activity of the neuron as a whole (it can already work from constant memory and from associative) and from recognition of the pattern by permanent memory. Associativity may decrease with each triggering, or it may be maintained and decreased depending on time. Dendrites can move from one type to another, and can also grow by adding new connections. There may be rules that impose spatial restrictions. For example, dendrites of “permanent memory” can only communicate with neurons from the previous layer, while dendrites of “associative memory” are associated only with neurons of their own layer or layer that is higher in the hierarchy.
The mechanism for recognizing a new one can be added only in a neural network with the separation of dendrites into types. The principle of the mechanism can be expressed in the following words: “A neural network is confronted with a new situation if a neuron or a group of neurons show increased activity”. The meaning of this principle is not obvious, since the rules of triggering are too different from implementation to implementation, but they all have in common only increased neuron activity after recognition of a new one. In the meantime, while the neuron shows increased activity, the rules are fulfilled within the network, the main task of which is to eliminate this increased activity.
Let's start with the benefits that the new recognition mechanism allows for the neural network as a whole. The neural network can implement the well-known "orienting reflex", described by a friend and academician Pavlov. For some time now, neurophysiologists began to talk about the new detectors in the composition of the neural networks of the brain, which are receptors of the orienting reflex, which manifests itself when a significant new in the perception occurs. But unlike conventional receptors (sensors), the receptors of a specific new situation cannot be fundamentally implemented as a sensor of a certain combination of symptoms. Just because they are disposable, the new situation does not repeat, as she has already met and remembered. And with such a new recognition mechanism, each neuron in the network becomes a new detector. This is innovation.
In addition, the recognition of a new one is a wonderful occasion for establishing new associative links, that is, the growth of dendrites of “associative memory”. In addition, you can implement “context memory”, either by adding a new type of dendrites, or simply by introducing rules for processing the neural network as a whole. The point is that we have to remember, all the new situations encountered, they become the context. The context memory mechanism is connected inseparably with the new recognition mechanism, but will be discussed below in a separate section.
Now you can talk about the features of the implementation depending on the neural network.
In neural networks with permanent and associative memory, working in time and capable of remembering sequences, associative activation is usually called prediction. The work of such a neural network consists in a constant forecast of subsequent events, and this event, which was not predicted, is considered to be truly new. That is, the rule is as follows: "If the triggering of the permanent memory did not follow the triggering of the associative memory, then we are faced with a new situation." After recognizing a new one, a new associative link is added to the neural network.
In neural networks with permanent and contextual memory, a similar, but more intuitive rule is used: "If permanent memory has worked and context memory is silent, then we are faced with a well-known pattern in a new situation." An event that occurred in an unknown context can be considered significantly new and becomes a reason to add new contextual links.
In neural networks with constant, associative and contextual memory (three types of dendrites), the addition of a new situation recognition mechanism solves the important problem of separating associations and context. Until the neuron recognizes a new situation, all activities of the surrounding neurons are perceived and remembered as a context. At the moment when the neuron realized the novelty of the situation, all the activities of the surrounding neurons are perceived and remembered as associations.
The context memory mechanism can be obtained by adding a new type of dendrites along with its new recognition mechanism. This context memory is actually responsible for serving the needs of the recognition mechanism of a new, based on the rule “If the persistent memory has worked and the context memory is silent, then we are faced with a new situation.” Context memory stores in itself all the situations that a neuron has already encountered, in which the permanent memory worked, in fact allowing you to correctly recognize new situations. A novelty of context memory is that its main task is not in associative activation of a neuron, but on the contrary, in quenching an increased activity of a neuron.
In reality, the difference between some implementations of associative and contextual memory is only in the impact on the neuron, and the rules for establishing and regulating associative and contextual connections sometimes coincide to fine details. Context memory can also be used for prediction, that is, for associative activation of a neuron. At the same time, associative memory can be successfully used as a context in sequences, recognizing situations that we could not predict. I propose to distinguish them precisely by the effect on the neuron, the association excites, and the context calms.
The basic principle of context memory can be expressed in the following words: “The active context input lets the neuron understand that the permanent memory has already worked in such conditions. Two neurons become the context for each other if they are active at the same time. ”
Contextual memory helps to fulfill the conditions of “Sparse distributed representations” by actions of rules inside a neuron, and not by rules affecting the entire network at the same time. Let's just say this is more biologically plausible. If we assume that during the learning of the permanent memory pattern, the neuron is activated, and take into account that two simultaneously active neurons are trying to plug each other. That active neighbor signals to our uneducated neuron that "Kid, I know better than you what is happening now, determine your pattern in a different situation."
This is the mechanism that forces neurons to choose various patterns for themselves to trigger permanent memory, and it is located inside the neuron. Neurons understand each other themselves, no need to use an external grouper.
This method assumes that among all the inputs of each neuron, in addition to the motivational, authorizing and emotional inputs. In addition, it is based on the theory of functional systems of Anokhin and the theory of emotions Simonov.
I myself have not fully understood the method, but I can safely say the following things. In addition to permanent and associative memory, motivation can also activate a neuron. Motivational, authorizing and emotional inputs are used as external control and assessment of neuron activity. The function of the neuron, according to which it learns and works, is called "Semantic probabilistic inference". And there is no talk about the “pitiful” summation of inputs. This neural network is not engaged in data retrieval, it deals with the problem of satisfying its emotional needs. It is necessary to model both the neural network itself and the environment with which it is connected. Outputs of a neural network should influence the world around, otherwise it will not be washed away from its functioning.
From the point of view of the external observer, the semantic probabilistic conclusion for the currently dominant emotion can be viewed as a calculation of the truth of the predicted satisfaction of the emotion with the help of a neural network reflecting the idea of the environment. From the receptive field to the outputs of the neural network, a lightning signal passes along the path of least resistance (in fact, the path consists of the highest probabilities), and emotions, sanctions and motivation are the keys that allow or forbid neurons to skip lightning.

From logical inference, semantic probabilistic inference differs in that every neuron is a reliable with a certain probability inference rule, which is obtained by observing the environment, while in a logical inference all derivation rules are strictly defined, absolutely reliable and their number is invariable.
It turns out that fuzzy logic leaves on fuzzy logic, and even chases by probability. An example of a neural network can be described as well. If we really want to get to our home from the forest, then we harness (we use the possible rules of withdrawal) either a cow or a horse, and we are going (the probable results) either to a rented apartment or to grandmother. Wins option from our point of most approximate to reality (likely) in this situation.
I will not describe the work of emotions, sanctions and motivations in this method, since I myself have not fully understood it, and it will take a lot of space. To quench the thirst for knowledge here.
www.math.nsc.ru/AP/ScientificDiscovery/PDF/principals_anokhin_simonov.pdf
The method of effective evolution of topology in neural networks is the same method with the evolutionary algorithm, only for the topology of the neural network. In principle, the evolutionary algorithm has recently become a kind of wand. If you have no ideas in your field of scientific activity, it is enough to apply an evolutionary algorithm, bang, and a “brand new” scientific direction in your pocket, if someone intelligent has not thought of this before you. A universal problem solver exists, it is enough to evolve the problem.
http://nn.cs.utexas.edu/downloads/papers/stanley.cec02.pdf
Another way to use the evolutionary algorithm is to replace the machine learning algorithm in the neural network with it. In fact, nothing new, even more trivial method than the previous one. The reference does not deserve.
Originality is the art of hiding your sources.
Long time ago I wrote a review article on the evolution of neuron modeling methods and abandoned this case. The description includes old and well-known methods for all interested neurons, one might say, we got a review of textbooks issued before the collapse of the USSR. If anyone is interested can go habrahabr.ru/post/101020 , see the old review. Now I have gathered a few material from my point of view fascinating and more modern methods of modeling, which deserve mention in the form of a structured review. Here I will only mention these methods in a descriptive order, for the simple reason that for the majority it is more interesting to know why we use it, and not how it works and how to use it. The volume of the text will significantly decrease, the interestingness will increase, and how these methods actually work, everyone can find himself.
So get ready.
Asynchronous distributed stochastic gradient descent in mini-batches
Rich and expressive Russian language. But he was already missed.Awful incomprehensible jumble of clever words. This method was described in article habrahabr.ru/post/146077 where it was transferred to a less frightening form. There he was called asynchronous gradient descent (asynchronous SGD). I tried to figure it out and clung to the English name "asynchronous SGD".
The first to mention is the gradient descent method itself. This is a method for finding the local minimum or maximum of a function. If you had a tower, you should have a vague understanding of what is being discussed here. In general, it is used as an optimization algorithm, and if you work with neural networks, then calmly call it a machine learning algorithm.
')
Now add the word "stochastic". Why is this necessary for our method? What is the use of it? This method uses only one example from the student set at a time, unlike other methods that use the entire set at once. The point is that you can add more data for additional training or stop training if you are tired of waiting and you want to see the training results on the processed part of the data.
There is a compromise between these two (conventional and stochastic) gradient descent types, called “mini-batch” (mini-batches). In this case, small packs of training samples are used. It is this method with small batches that is most appropriate for distributing computations among multiple computers on a network.
Now, regarding asynchrony and distribution - using distributed asynchronous data processing (Asynchronous peer-to-peer). In this case, several mini-batches are processed simultaneously on their computers in the peer-to-peer network, allowing you to continue learning with any number and any combination of available nodes. No one waits until all computers have completed their calculations for the last batch to update the overall model. For each batch they use potentially different and, as a rule, obsolete parameters of the model. This is the main and main drawback. The advantage is that all the machines involved in the optimization are busy with calculations all the time, and we can add and turn off the machines during the learning process. The disadvantage is leveled by the fact that with data homogeneity, the model still converges (optimized, trained). I did not dare to go to work proving this statement. I can only share the link simply enough setting forth the principle of the asynchronous “data mining” method in the peer-to-peer network. Maybe someone needs, it's interesting in itself. Now you do not need a supercomputer, you need friends in the network.
http://www.inf.u-szeged.hu/~ormandi/presentations/europar2011.pdf
Sparse distributed views
If artificial intelligence exists, then artificial stupidity must exist.On foreign it sounds like “Sparse Distributed Representations”.
The main point of this method is to slash the property of biological neural networks. Although neurons in the cerebral cortex are very tightly interconnected, numerous suppressive (inhibitory) neurons ensure that only a small percentage of all neurons will be active at the same time, and they are usually quite spaced apart. That is, information is always presented in the brain only by a small number of active neurons from all those present there. This type of information coding is called “sparse distributed representation”.
There is also a sparse autoencoder method “Sparse Autoencoder”, read here habrahabr.ru/post/134950 , but its meaning is the same, just to slash the property of a biological neural network.
Let's return to our method. “Sparse” is the requirement that only a small percentage of the layer's neurons can be simultaneously active. What way you achieve it is not important. The underlying principle remains the same, as in the encoder, and in sparse representations. The main thing is that the dimensionality of the input data for the next layer decreases, data is compressed, as the network must find hidden relationships, correlations of features, and in general no frequent structure in the data.
“Distributed” is also a requirement that in order to represent something in a neural network layer, it is necessary to activate that very small percentage of neurons, while neurons are scattered across the layer remotely from each other. A surplus of silent neurons is also bad. A sufficient number of active neurons in the layer allows you to avoid trivial patterns while finding those most hidden relationships and correlations. The activity of a single neuron, of course, also means something; let us recall the "grandmother's neuron", but the activity should be interpreted only in the context of many other neurons. A single activity will not go up the layer hierarchy. In fact, the activity of the neurons of the last layer will represent a picture of the world through the receptive field of our neural network.
In conclusion, I can say that such a presentation of information in the neural network just leads to the formation of the notorious "grandmother's neurons." If you do not understand what it is about, take a look at the picture, this image corresponds to the maximum stimulus for a neuron engaged in the recognition of the cat's muzzle from the article habrahabr.ru/post/153945 . Pure "concept of a muzzle of a cat".
Or watch 5 minutes of the speech of Comrade Anokhin from the specified time 49:15 . Based on his words, it can be argued that there is a neuron in your brain responsible for the concept of citizen Sasha Gray.
Local receptive fields
Nothing is good enough that somewhere there is someone who hates it.This is the rule of good tone in the simulation of neural networks. Depending on the methods used and the model of neurons, you can get different buns. I don't even want to list, just take my word for it. Local receptive fields are our everything.
Of course, it is worthwhile to stipulate that the greatest advantage of this method is obtained with the homogeneity of the input data. A simple example is visual data. The neurons from the first layer on such data by the method of sparse representations will learn to recognize the same simplest elements of the contours from different angles, which fits very well with the biology of the brain.
Dendrite separation by type
Give in to the temptation. And then he may not happen again.The separation of dendrites by type is a remarkable innovation in the modeling of neurons, opening up limitless possibilities for experimentation. This principle becomes a new trend in the modeling of neurons both in the west and here, although the paths that led to this decision are different. In the west, this principle is attempted to bring a biological basis; now they say that neurons of the fourth neocortex accept synapses from other layers and other brain regions to dendrites close to the body of cells, and communicate with each other only through remote dendrites in the layer.
We also do not refuse such a basis, but in addition criticize the hypothesis of the summation of excitations on a single neuron.
We now turn to the opened possibilities of modeling. We can assign different rules for the response of a neuron to signals from different types of dendrites, set rules for the transition of dendrites from one type to another. Naturally, the introduction of various types affects the operation of the entire neural network as a whole, so many excellent proposals for the rules are not viable within the entire neural network. But there are already several well-established and well-manifested models of neurons with the separation of dendrites by type.
Below I will talk about new properties of neural networks, which coincide with the properties of human memory and which can be obtained by separating dendrites into types. In each particular case of the method used, the property may have a different name (the name is always the arbitrariness of the author of the method) and seriously differ in the implementation mechanism, but this does not negate the similarity of the underlying principle.
And first, take a look at the structural diagram of the neuron model from the “Hierarchical Temporal Memory” method.
Associative memory
Not everything is a pattern that activates a neuron.The principle is in the separation of dendrites into two types and the logical coupling of signals at their inputs.
The dendrites of the first type, which can be called the “permanent memory” dendrites, work according to quite usual rules of neuron modeling. There is no innovation here; you can use any old rules you know that came up with neural networks without splitting inputs into types, for example, something like the rule “If a signal arrives at the desired set of inputs, then the neuron is activated”. For the triggering of such a rule, the neuron must recognize the pattern, and for convenience we will call it the “permanent memory triggering”.
The second type of dendrites, which can be called the “associative memory” dendrites, work according to new, but intuitively understandable rules. Here lies the innovation in modeling. The basic principle of such rules can be expressed in the following words: “The inputs of an associative dendrite can force a neuron to activate, if permanent memory has not worked. Input associativity increases if it is active when the persistent memory is activated. ” If someone does not understand, then we work on the same neuron the conditioned reflex of a comrade and academician Pavlov. In this case, the dogs do not suffer.
You should not assume that the principle is too simple, depending on the implementation, you will encounter the complexity of the rules and the many features of modeling. For example, associativity can increase both from the activity of the neuron as a whole (it can already work from constant memory and from associative) and from recognition of the pattern by permanent memory. Associativity may decrease with each triggering, or it may be maintained and decreased depending on time. Dendrites can move from one type to another, and can also grow by adding new connections. There may be rules that impose spatial restrictions. For example, dendrites of “permanent memory” can only communicate with neurons from the previous layer, while dendrites of “associative memory” are associated only with neurons of their own layer or layer that is higher in the hierarchy.
Recognizing a new situation
Sorry, I'm saying when you interrupt.The mechanism for recognizing a new one can be added only in a neural network with the separation of dendrites into types. The principle of the mechanism can be expressed in the following words: “A neural network is confronted with a new situation if a neuron or a group of neurons show increased activity”. The meaning of this principle is not obvious, since the rules of triggering are too different from implementation to implementation, but they all have in common only increased neuron activity after recognition of a new one. In the meantime, while the neuron shows increased activity, the rules are fulfilled within the network, the main task of which is to eliminate this increased activity.
Let's start with the benefits that the new recognition mechanism allows for the neural network as a whole. The neural network can implement the well-known "orienting reflex", described by a friend and academician Pavlov. For some time now, neurophysiologists began to talk about the new detectors in the composition of the neural networks of the brain, which are receptors of the orienting reflex, which manifests itself when a significant new in the perception occurs. But unlike conventional receptors (sensors), the receptors of a specific new situation cannot be fundamentally implemented as a sensor of a certain combination of symptoms. Just because they are disposable, the new situation does not repeat, as she has already met and remembered. And with such a new recognition mechanism, each neuron in the network becomes a new detector. This is innovation.
In addition, the recognition of a new one is a wonderful occasion for establishing new associative links, that is, the growth of dendrites of “associative memory”. In addition, you can implement “context memory”, either by adding a new type of dendrites, or simply by introducing rules for processing the neural network as a whole. The point is that we have to remember, all the new situations encountered, they become the context. The context memory mechanism is connected inseparably with the new recognition mechanism, but will be discussed below in a separate section.
Now you can talk about the features of the implementation depending on the neural network.
In neural networks with permanent and associative memory, working in time and capable of remembering sequences, associative activation is usually called prediction. The work of such a neural network consists in a constant forecast of subsequent events, and this event, which was not predicted, is considered to be truly new. That is, the rule is as follows: "If the triggering of the permanent memory did not follow the triggering of the associative memory, then we are faced with a new situation." After recognizing a new one, a new associative link is added to the neural network.
In neural networks with permanent and contextual memory, a similar, but more intuitive rule is used: "If permanent memory has worked and context memory is silent, then we are faced with a well-known pattern in a new situation." An event that occurred in an unknown context can be considered significantly new and becomes a reason to add new contextual links.
In neural networks with constant, associative and contextual memory (three types of dendrites), the addition of a new situation recognition mechanism solves the important problem of separating associations and context. Until the neuron recognizes a new situation, all activities of the surrounding neurons are perceived and remembered as a context. At the moment when the neuron realized the novelty of the situation, all the activities of the surrounding neurons are perceived and remembered as associations.
Context memory
Everyone thought to the best of his promiscuity, but everyone thought the same thing.The context memory mechanism can be obtained by adding a new type of dendrites along with its new recognition mechanism. This context memory is actually responsible for serving the needs of the recognition mechanism of a new, based on the rule “If the persistent memory has worked and the context memory is silent, then we are faced with a new situation.” Context memory stores in itself all the situations that a neuron has already encountered, in which the permanent memory worked, in fact allowing you to correctly recognize new situations. A novelty of context memory is that its main task is not in associative activation of a neuron, but on the contrary, in quenching an increased activity of a neuron.
In reality, the difference between some implementations of associative and contextual memory is only in the impact on the neuron, and the rules for establishing and regulating associative and contextual connections sometimes coincide to fine details. Context memory can also be used for prediction, that is, for associative activation of a neuron. At the same time, associative memory can be successfully used as a context in sequences, recognizing situations that we could not predict. I propose to distinguish them precisely by the effect on the neuron, the association excites, and the context calms.
The basic principle of context memory can be expressed in the following words: “The active context input lets the neuron understand that the permanent memory has already worked in such conditions. Two neurons become the context for each other if they are active at the same time. ”
Contextual memory helps to fulfill the conditions of “Sparse distributed representations” by actions of rules inside a neuron, and not by rules affecting the entire network at the same time. Let's just say this is more biologically plausible. If we assume that during the learning of the permanent memory pattern, the neuron is activated, and take into account that two simultaneously active neurons are trying to plug each other. That active neighbor signals to our uneducated neuron that "Kid, I know better than you what is happening now, determine your pattern in a different situation."
This is the mechanism that forces neurons to choose various patterns for themselves to trigger permanent memory, and it is located inside the neuron. Neurons understand each other themselves, no need to use an external grouper.
A neuron with constant and associative memory, as well as motivational, authorizing and emotional inputs.
When you did something that nobody did before you, people are not able to appreciate how difficult it was.This method assumes that among all the inputs of each neuron, in addition to the motivational, authorizing and emotional inputs. In addition, it is based on the theory of functional systems of Anokhin and the theory of emotions Simonov.
I myself have not fully understood the method, but I can safely say the following things. In addition to permanent and associative memory, motivation can also activate a neuron. Motivational, authorizing and emotional inputs are used as external control and assessment of neuron activity. The function of the neuron, according to which it learns and works, is called "Semantic probabilistic inference". And there is no talk about the “pitiful” summation of inputs. This neural network is not engaged in data retrieval, it deals with the problem of satisfying its emotional needs. It is necessary to model both the neural network itself and the environment with which it is connected. Outputs of a neural network should influence the world around, otherwise it will not be washed away from its functioning.
From the point of view of the external observer, the semantic probabilistic conclusion for the currently dominant emotion can be viewed as a calculation of the truth of the predicted satisfaction of the emotion with the help of a neural network reflecting the idea of the environment. From the receptive field to the outputs of the neural network, a lightning signal passes along the path of least resistance (in fact, the path consists of the highest probabilities), and emotions, sanctions and motivation are the keys that allow or forbid neurons to skip lightning.
From logical inference, semantic probabilistic inference differs in that every neuron is a reliable with a certain probability inference rule, which is obtained by observing the environment, while in a logical inference all derivation rules are strictly defined, absolutely reliable and their number is invariable.
It turns out that fuzzy logic leaves on fuzzy logic, and even chases by probability. An example of a neural network can be described as well. If we really want to get to our home from the forest, then we harness (we use the possible rules of withdrawal) either a cow or a horse, and we are going (the probable results) either to a rented apartment or to grandmother. Wins option from our point of most approximate to reality (likely) in this situation.
I will not describe the work of emotions, sanctions and motivations in this method, since I myself have not fully understood it, and it will take a lot of space. To quench the thirst for knowledge here.
www.math.nsc.ru/AP/ScientificDiscovery/PDF/principals_anokhin_simonov.pdf
Other "modern" methods of working with neural networks
It is not enough to know its worth - you must also be in demand.The method of effective evolution of topology in neural networks is the same method with the evolutionary algorithm, only for the topology of the neural network. In principle, the evolutionary algorithm has recently become a kind of wand. If you have no ideas in your field of scientific activity, it is enough to apply an evolutionary algorithm, bang, and a “brand new” scientific direction in your pocket, if someone intelligent has not thought of this before you. A universal problem solver exists, it is enough to evolve the problem.
http://nn.cs.utexas.edu/downloads/papers/stanley.cec02.pdf
Another way to use the evolutionary algorithm is to replace the machine learning algorithm in the neural network with it. In fact, nothing new, even more trivial method than the previous one. The reference does not deserve.
Literature
It is better to keep quiet and sound like a fool than to open your mouth and finally dispel doubts.Originality is the art of hiding your sources.
- Hierarchical temporal memory (HTM) and its cortical learning algorithms https://www.groksolutions.com/htm-overview/education/HTM_CorticalLearningAlgorithms_ru.pdf
- Asynchronous peer-to-peer data mining with gradient descent http://www.inf.u-szeged.hu/~ormandi/presentations/europar2011.pdf
- Vityaev E.E. The principles of the brain, contained in the theory of functional systems PK Anokhin and the theory of emotions P.V. Simonov http://www.math.nsc.ru/AP/ScientificDiscovery/PDF/principals_anokhin_simonov.pdf
- Zhdanov A.A. Autonomous artificial intelligence. M .: BINOM. Laboratory of knowledge, 2008.
Source: https://habr.com/ru/post/181456/
All Articles