How Yandex recognizes music from a microphone


In the world there are only a few specialized companies that are professionally engaged in the recognition of music tracks. As far as we know, from search companies, Yandex was the first to help the Russian user in this task. Despite the fact that we still have a lot to do, the quality of recognition is already comparable with the leaders in this area. In addition, the search for music by audio fragment is not the most trivial and illuminated topic in RuNet; we hope that many will be curious to know the details.
About the achieved quality level
The basic quality we call the percentage of valid requests, to which we gave the relevant answer - now about 80%. The relevant response is the track that contains the user's request. We consider as valid only those requests from the Yandex.Music application that actually contain a musical recording, and not just noise or silence. When we request a work that is not known to us, we consider the answer as obviously irrelevant.
Technically, the task is formulated as follows: a 10-second fragment of an audio signal recorded on a smartphone (we call it a request) arrives at the server, after which among the known tracks we need to find exactly the one from which the fragment was recorded. If the fragment is not contained in any known track, as well as if it is not a musical record at all, you need to answer “nothing found”. Answer the most similar sound tracks in the absence of an exact match is not required.
')
Base tracks
As in a web search, in order to search well, you need to have a large database of documents (in this case, tracks), and they must be correctly labeled: for each track you need to know the name, artist and album. As you probably already guessed, we had such a base. Firstly, this is a huge number of entries in Yandex.Music, officially provided by copyright holders for listening. Secondly, we have collected a selection of music tracks posted on the Internet. So we got 6 million tracks that users are most interested in.
Why do we need tracks from the Internet, and what we do with them
Our goal as a search engine is completeness: we must give a relevant answer for every valid query. The base Yandex.Music is not some popular artists, not all copyright holders are still involved in this project. On the other hand, the fact that we do not have the right to give users to listen to any tracks from the service does not mean at all that we cannot recognize them and report the name of the artist and the name of the song.
Since we are the mirror of the Internet, we have collected ID3 tags and descriptors for each popular track on the Web to identify those works that are not in the Yandex.Music database. It is enough to store only these metadata - for them we show music videos, when there were only records from the Internet.
Since we are the mirror of the Internet, we have collected ID3 tags and descriptors for each popular track on the Web to identify those works that are not in the Yandex.Music database. It is enough to store only these metadata - for them we show music videos, when there were only records from the Internet.
Unpromising approaches
What is the best way to compare the fragment with the tracks? Immediately discard the obviously inappropriate options.
- Bitwise comparison Even if the signal is received directly from the optical output of a digital player, inaccuracies will arise as a result of transcoding. And during the transmission of the signal there are many other sources of distortion: the loudspeaker of the sound source, the acoustics of the room, the uneven frequency response of the microphone , even digitization from the microphone. All this makes inapplicable even fuzzy bitwise comparison.
- Watermarks . If Yandex itself released music or participated in the production cycle of releasing all the records played on the radio, in cafes and discos - one could embed an analogue of the watermarks into the tracks. These tags are invisible to the human ear, but are easily recognized by algorithms.
- Loose comparison of spectrograms. We need a way to lax comparison. Let's look at the spectrograms of the original track and the recorded fragment. They can be considered as images, and you can search for the most similar among images of all tracks (for example, comparing them as vectors using one of the well-known metrics, such as L² ):
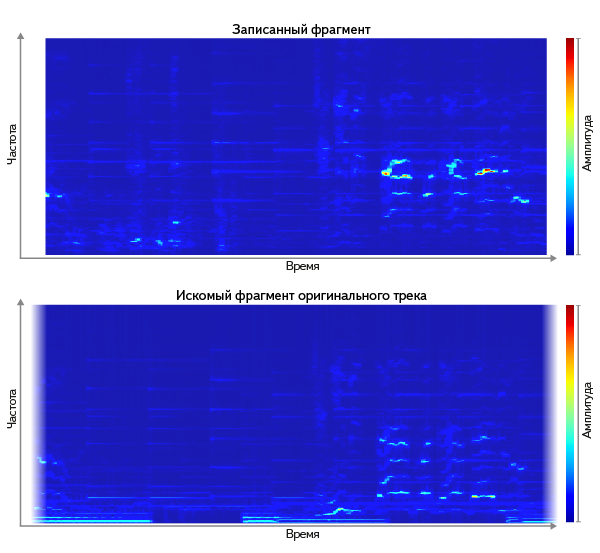
But in the application of this method "in the forehead" there are two difficulties:
a) comparison with 6 million images is obviously an expensive operation. Even the coarsening of the full spectrogram, which generally preserves the properties of a signal, yields several megabytes of uncompressed data.
b) it turns out that some differences are more indicative than others.
As a result, for each track we need the minimum number of the most characteristic (that is, briefly and accurately describing the track) attributes.
What signs are not afraid of distortion?
The main problems arise from noise and distortion in the path from the source of the signal to digitization from the microphone. For different tracks, it is possible to compare the original with a fragment recorded in different artificially noisy conditions - and by many examples it is possible to find which characteristics are best preserved. It turns out that the spectrogram peaks work well, identified in one way or another - for example, as the local maximum points of the amplitude. The height of the peaks does not fit (the microphone's frequency response changes them), but their location on the frequency-time grid does not change much with noise. This observation, in one form or another, is used in many well-known solutions — for example, in Echoprint . On average, about 300 thousand peaks are obtained per track - this amount of data is much more realistic to compare with the millions of tracks in the database than the full query spectrogram.
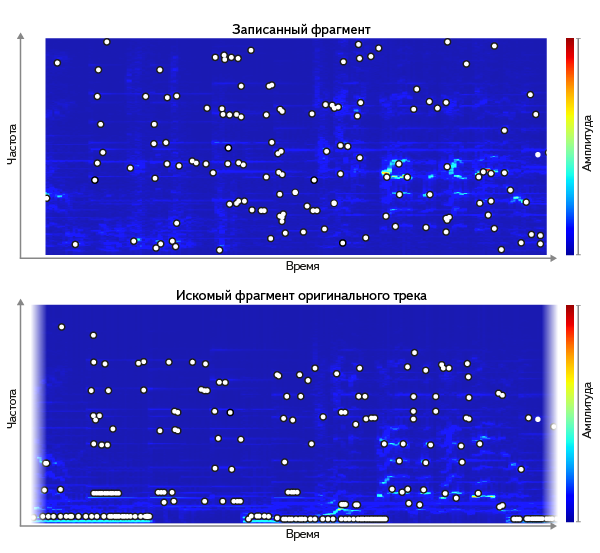
But even if we take only the locations of the peaks, the identity of the set of peaks between the query and the segment of the original is a bad criterion. For a large percentage of the fragments that are known to us, he finds nothing. The reason - inaccuracies when writing a request. Noise adds some peaks, suppresses others; The frequency response of the entire signal transmission medium can even shift the frequency of the peaks. So we come to a non-strict comparison of the set of peaks.
We need to find in the entire database the segment of the track, most similar to our query. I.e:
- first in each track to find such a shift in time, where the maximum number of peaks would coincide with the request;
- then from all the tracks choose the one where the coincidence was greatest.
To do this, we build a histogram: for each frequency of the peak, which is present both in the request and in the track, we postpone +1 on the Y axis in the offset where there was a match:

The track with the highest column in the histogram is the most relevant result - and the height of this column is a measure of the proximity between the request and the document.
Fight for search accuracy
Experience shows that if we look for all the peaks equivalently, we will often find the wrong tracks. But the same measure of proximity can be applied not only to the entire set of document peaks, but also to any subset - for example, only to the most reproducible (resistant to distortion). At the same time, this will also reduce the cost of building each histogram. Here is how we choose such peaks.
Time selection: first, inside one frequency, along the time axis from the beginning to the end of the recording, we launch an imaginary “descending blade”. When each peak is detected that is higher than the current blade position, it cuts off the “tip” —the difference between the blade position and the height of the freshly detected peak. Then the blade rises to the original height of this peak. If the blade does not “find” a peak, it falls a little under its own weight.
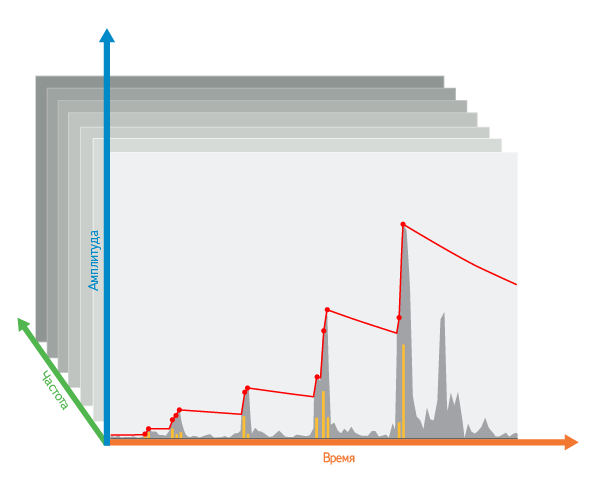
Diversity in frequencies: in order to give preference to the most diverse frequencies, we raise the blade not only at the very frequency of the next peak, but also (to a lesser extent) in the frequencies adjacent to it.
Selection by frequency: then, within one time interval, among all the frequencies, we select the most contrast peaks, i.e. the largest local maximums among the cut off "tops".
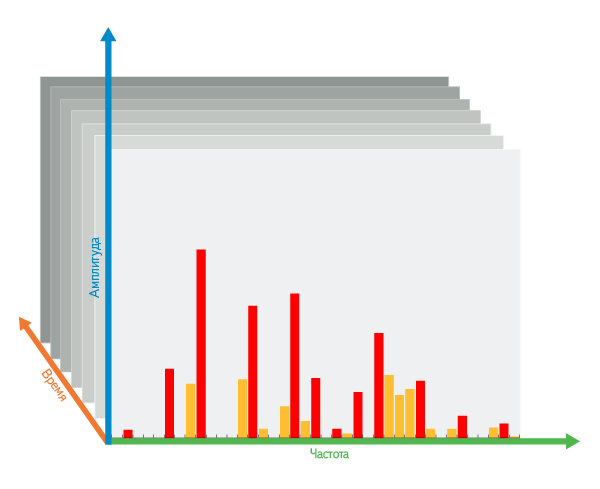
When selecting peaks, there are several parameters: the speed of lowering the blade, the number of selectable peaks in each time interval and the neighborhood of the influence of peaks on neighbors. And we picked up such a combination of them, at which the minimum number of peaks remains, but almost all of them are resistant to distortion.
Search Acceleration
So, we have found a proximity metric that is well resistant to distortion. It provides good search accuracy, but you also need to ensure that our search quickly responds to the user. First you need to learn how to choose a very small number of candidate tracks for calculating the metric in order to avoid complete search of tracks when searching.
Improving key uniqueness : One could build an index
(, ) .Alas, such a "dictionary" of possible frequencies is too poor (256 "words" - the intervals into which we divide the entire frequency range). Most queries contain such a set of “words” that is found in most of our 6 million documents. It is necessary to find more distinctive (discriminative) keys - which are likely to occur in relevant documents, and less likely in irrelevant ones.
A pair of closely spaced peaks are well suited for this. Each pair is much less common.
This win has its price - less likely to play in a distorted signal. If for individual peaks it is on average P, then for pairs it is P 2 (that is, obviously less). To compensate for this, we include each peak in several pairs at once. This slightly increases the size of the index, but drastically reduces the number of documents considered in vain - by almost 3 orders of magnitude:
Win score
For example, if you include each peak in 8 pairs and “pack” each pair in 20 bits (then the number of unique values of pairs increases to ≈1 million), then:
- the number of keys in the query grows 8 times
- the number of documents per key is reduced by ≈4000 times: ≈1 million / 256
- total, the number of documents considered in vain decreases by ≈500 times: ≈4000 / 8
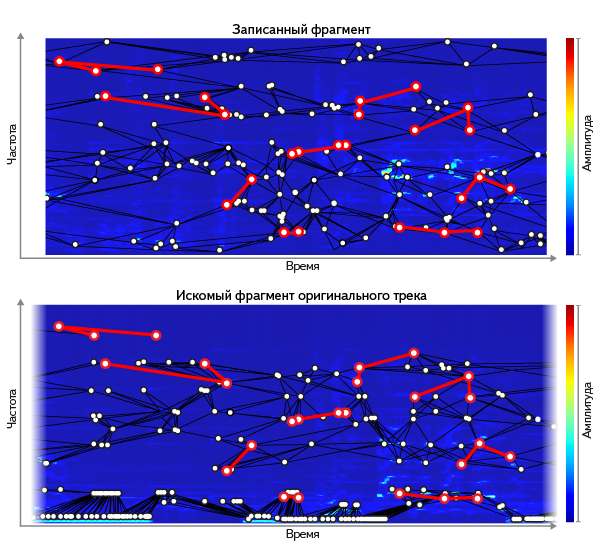
Having selected a small number of documents with the help of pairs, you can proceed to their ranking. Histograms can be applied to pairs of peaks with the same success, replacing the coincidence of one frequency with the coincidence of both frequencies in a pair.
Two-stage search : to further reduce the volume of calculations, we divided the search into two stages:
- We make a preliminary selection (pruning) of tracks for a very sparse set of the most contrasting peaks. Selection parameters are selected so as to narrow the circle of documents as much as possible, but to save the most relevant result among them.
- The guaranteed best answer is chosen - for selected tracks, the exact relevance of a more complete sample of peaks, already on an index with a different structure, is considered:
→( , ).
As a result of all the described optimizations, the entire database required for the search became 15 times smaller than the track files themselves.
Index in memory : And finally, in order not to wait for the disk to be accessed for each request, the entire index is located in RAM and distributed across multiple servers, since occupies units terabytes.
Nothing found?
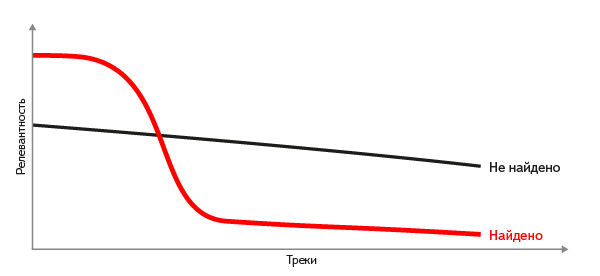
It happens that for the requested fragment either there is no suitable track in our database, or the fragment is not a recording of any track at all. How to make a decision when it is better to answer “nothing is found” than to show the “least inappropriate” track? It is not possible to cut off at some threshold of relevance - for different fragments the threshold differs many times, and a single value for all cases simply does not exist. But if you sort the selected documents by relevance, the shape of the curve of its values gives a good criterion. If we know the relevant answer, a sharp drop (difference) in relevance is clearly visible on the curve, and vice versa - a gentle curve suggests that no suitable tracks have been found.
What's next
As already mentioned, we are at the beginning of a long journey. There are a number of studies and improvements ahead to improve the quality of the search: for example, in cases of pace distortion and increased noise. We will definitely try to apply machine learning to use a more diverse set of features and automatically select the most effective ones.
In addition, we are planning incremental recognition, i.e. give an answer for the first seconds of the fragment.
Other Music Search Tasks
The field of informational search for music is far from exhausted by a task with a fragment from a microphone . Working with a “clean”, un-noisy signal that has only undergone compression, allows you to find duplicate tracks in an extensive music collection, as well as to detect potential copyright infringements . And the search for inaccurate coincidences and different types of similarity is a whole direction, including the search for cover versions and remixes, the extraction of musical characteristics (rhythm, genre, composer) for building recommendations, as well as the search for plagiarism.
Separately, highlight the task of searching for the sang passage . It, in contrast to the recognition of a piece of a musical recording, requires a fundamentally different approach: instead of audio recording, as a rule, a musical representation of the piece is used, and often a request. The accuracy of such solutions turns out to be much worse (at least, due to an incomparably greater variation of the query variations), and therefore they only recognize the most popular works.
What to read
- Avery Wang: An Industrial-Strength Audio Search Algorithm , Proc. 2003 ISMIR International Symposium on Music Information Retrieval, Baltimore, MD, Oct. 2003. This article for the first time (as far as we know) suggests using spectrogram peaks and peak pairs as features that are resistant to typical signal distortion.
- D. Ellis (2009): Robust Landmark-Based Audio Fingerprinting . This paper gives a concrete example of the implementation of the selection of peaks and their pairs using the “decaying threshold” (in our free translation - “descending blade”).
- Jaap Haitsma, Ton Kalker (2002): "A Highly Robust Audio Fingerprinting System . " This article proposed to encode consecutive blocks of audio with 32 bits, each bit describes the change in energy in its frequency range. The described approach is easily generalized to the case of arbitrary coding of a sequence of blocks of an audio signal.
- Nick Palmer: "Review of audio fingerprinting algorithms for a fingerprint generation . " The main interest in this work is a review of existing approaches to solving the described problem. The stages of a possible implementation are also described.
- Shumeet Baluja, Michele Covell: "Audio Fingerprinting: Combining Computer Vision & Data Stream Processing . " The article, written by colleagues from Google, describes an approach based on wavelets using computer vision techniques.
- Arunan Ramalingam, Sridhar Krishnan: “Transform Features For Audio Fingerprinting” (2005). In this article, it is proposed to describe a fragment of audio using a Gaussian mixture model on top of various attributes, such as Shannon entropy, Renyi entropy, spectolol centroids, meelpstral coefficients, and others. Comparative recognition quality values are given.
- Dalibor Mitrovic, Matthias Zeppelzauer, Christian Breiteneder: "Features for Content-Based Audio Retrieval . " Survey work about audio signs: how to choose them, what properties they should have and what they exist.
- Natalia Miranda, Fabiana Piccoli: "Using a GPU to Speed Up" . The article proposes the use of a GPU to speed up signature calculations.
- Shuhei Hamawaki, Shintaro Funasawa, Jiro Katto, Hiromi Ishizaki, Keiichiro Hoashi, Yasuhiro Takishima: "Feature Analysis and Normalization of the Rhythm for Music with Different Bit Rates." The article focuses on increasing the robustness of the audio signal representation based on the chalk-cepstral coefficients (MFCC). For this, the method of normalization of cepstrum (CMN) is used.
Source: https://habr.com/ru/post/181219/
All Articles