Is relational mapping of collections an alternative to object-relational mapping?
This text briefly considers the features of object-relational mapping (Object-Relational Mapping - ORM) and introduces a new concept of relational mapping of collections (Collection-Relational Mapping - CoRM), proposing to discuss the prospects and possibilities of the technical implementation of a new concept of long-term storage of objects
Today, the use of object-relational mapping (ORM), which uses the commonality of some theoretical foundations of object-oriented and relational programming to combine these two, significantly different, ways of modeling reality has become a common place in the development of large and complex systems.
Object-oriented programming relies on concepts that are poorly placed in the paradigm of relational DBMSs , mainly represented as systems that execute SQL queries. Such concepts are hierarchical data structures, polymorphism, encapsulation, and of course, inheritance. And if inheritance has somehow been developed, for example, in PostgreSQL , for example, encapsulation, which directly contradicts the openness and arbitrariness of combining values in SQL tuples, actually creates significant (possibly out of theoretical contradictions) obstacles to the effective use of a relational database system as a long-term state object storage class.
')
However, the prevalence of relational database management systems, their relative efficiency in executing requests for large and very large data arrays, the wide possibilities of combining a heterogeneous computing environment through a relational database management system, and other advantages associated with using such database management systems make it necessary to compromise the convenience of system design in object -oriented style and limitations imposed on the designed system using these DBMS.
The main support for combining the object and relational paradigms within the framework of the ORM is the thesis that just as the relational table contains many elements (rows) of one structure, so the class combines many objects having a single structure and behavior. Therefore, one of the most common patterns commonly used in ORM implementations is the mapping of a class into a table, with the fields of the table being the attributes (all or part, uniquely defining the state) of class objects.
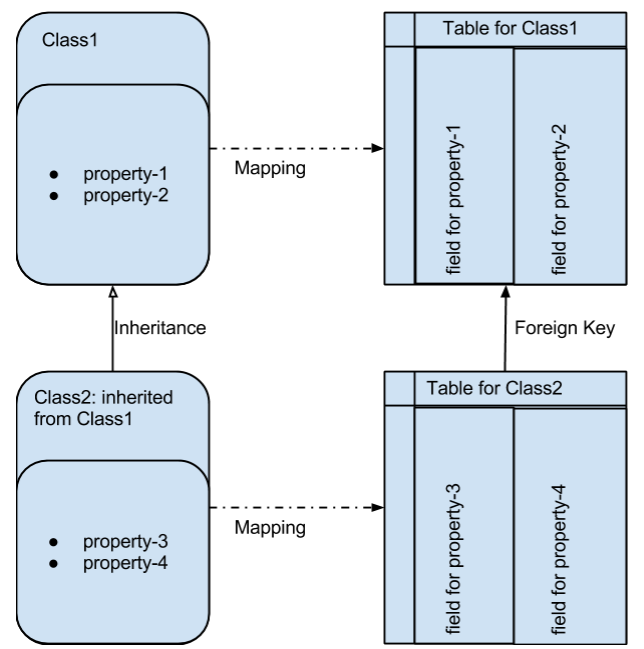
Figure 1 The most common form of object-relational mapping. Classes are mapped to tables, attributes are mapped to table fields
Any technical implementation has its limitations, and the technology of relational DBMS based on the SQL language, far from its theoretical predecessor - Codd algebra , is not an exception. In this case, all the technical limitations of SQL associated with the very existence of the table, as a physical carrier of tuples of values that are interconnected by a one-to-one relationship, naturally move to the class mapped to such a table using the ORM.
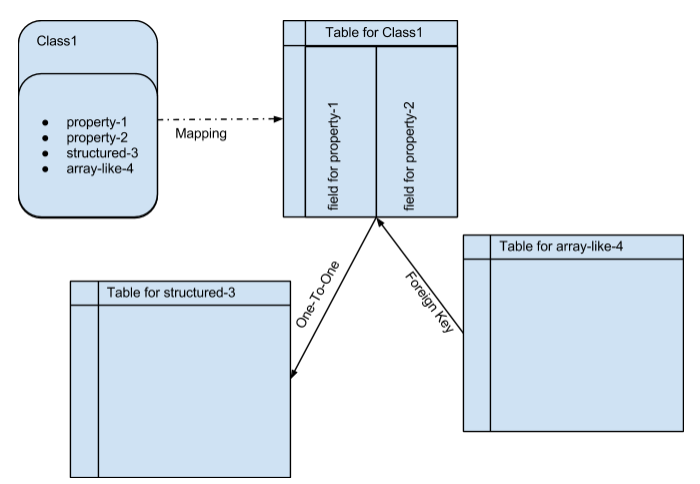
Figure 2 One of the problems with direct mapping of classes to tables: the display of attributes that are multiple in character requires separate tables.
The concept of relational mapping of collections (Collection-Relational Mapping, CoRM) is based on the fact that the table, as a long-term repository of object states, has a completely adequate image in any developed object-oriented environment, namely, the collection (Collection).
Storing the state of a collection of objects as a SQL table is far from a new invention. So, half of the packages dedicated to storing data in the standard python library are dedicated to this technology. The novelty of the CoRM approach lies in the fact that disparate collections of objects are combined by well defined (well-defined) relational relationships between these collections.
(the following updated: 05-30-2013, as I was rightly pointed out, document-oriented DBMS and MongoDB in particular, can also be considered as a prototype of CoRM)
CoRM, as well as document-oriented DBMS and MongoDb in particular, does not impose any restrictions on the ability of different objects of the same class to store their state in different collections, as well as on the ability of the collection to simultaneously contain objects belonging to different classes. The main difference of CoRM from document-oriented DBMS and tools based on them, like ORM, is that CoRM retains the possibility of using SQL (in a slightly modified form) and using relational relations between objects. CoRM differs from the traditional ORM approach in that the collection is not tied directly to the class and theoretically can contain any object, while meeting the minimum requirements for this object (namely, the ability to serialize in some special way). At the same time, these requirements do not include any restrictions on the structure of the object, the use of special data types, and so on.
The latter circumstance distinguishes the CoRM approach, including from the well-known SQLAlchemy library , which also manipulates collections and classes that are separately tied to collections.
The relational relationship between the elements of collections is determined by the presence and content (return value) of the selected properties (properties), attributes, or deterministic ( deterministic ) methods of the objects in the collection. Such selected properties will be called indexes of the collection. Thus, the collection and its indexes are the link between the object-oriented programming paradigm that supplies index values and the relational SQL repository paradigm, which uses the resulting index values to establish relational relationships between stored objects.
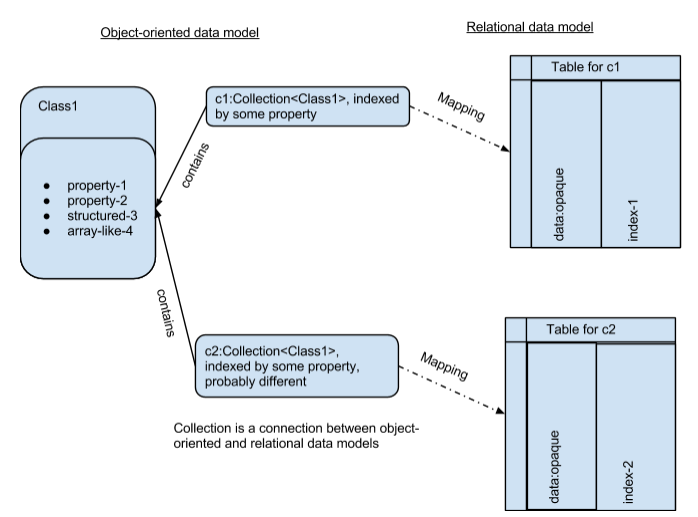
Figure 3 The collection and its indexes are the link between the object and relational data models.
Delving into the relational paradigm, one can define the concept of keys (Key) of a collection, each of which will refer to some combination of indexes of this collection, defining additional optimization and restrictive properties for this combination, for example, the uniqueness of the key (composite in general) within the collection.
The individual keys of a collection can serve as foreign keys for accessing objects stored in another collection, just like a foreign key in a table serves to establish relational relationships with another table. In exactly the same way as a foreign key in a relational DBMS, a foreign key in relational mapping of collections can be used to maintain the integrity of the data, prohibiting the storage of such a foreign key value that does not match any of the key values in the target for the foreign key collections.
The possibility of the practical use of relational relations between collections is determined by the placement of their associated tables in one database. The reflection of this fact for the programmer is the presence of a special storage object (Storage), which determines the specificity of the connection to the database and the general structural and functional characteristics of the DBMS, and also contains access points to the collections, tables for which are contained in this database.
Turning to collections for sampling data, in filtering, grouping, ordering expressions, the programmer manipulates not the properties of the objects stored in the collection, but the values of the indexes, resulting in a list of objects, or a list of tuples composed of objects and additionally counted expressions (defined on collection index values). The objects themselves remain completely encapsulated inside the collection until they are deserialized upon receiving the results of the query.
Encapsulating an object inside a collection and isolating the stored state of the object from the indexes available (as opposed to the state of the object) from the relational repository make senseless attempts to display expressions (filtering, grouping, calculating additional return values and ordering) for any similarity of expressions used by the object language (python in our case), as it happens for example in SQLAlchemy. Instead, a query from a collection can be formulated in a language as close as possible to SQL, as is done for example using Google App Engine Datastore . The GQL language used when accessing Google Datastore collections is an almost optimal pattern (of course, with the exception of the strange restrictions imposed on this language by its implementation) of a language that could be used to get data from collections using CoRM. Names appearing in language expressions should obviously refer to indexes and keys defined on collections, and not to attributes of a stored object hidden from the relational repository.
Bringing the collection query syntax out of the object language syntax allows precompilation and caching of compiled target storage requests, leaving the possibility of deserializing an object from the received data, which can lead to significant optimization of access speed to objects whose state is stored in the relational storage (it should be noted that the issue of optimizing access to objects in the collection, generally speaking, is quite painful for existing ORMs).
An interesting addition is that encapsulation and selection of indexes of a collection, as a separate entity, among other things, make it easy to implement dynamic indexes, the values of which are not directly contained in the attributes of the object's stored state, but are uniquely calculated from them.
Relational mapping of collections, when implemented, can be an excellent alternative to existing ORM implementations, allowing you to remove the application's entity from the constraints of relational storage.
Attention, question:
Object Relational Mapping (ORM)
Today, the use of object-relational mapping (ORM), which uses the commonality of some theoretical foundations of object-oriented and relational programming to combine these two, significantly different, ways of modeling reality has become a common place in the development of large and complex systems.
Object-oriented programming relies on concepts that are poorly placed in the paradigm of relational DBMSs , mainly represented as systems that execute SQL queries. Such concepts are hierarchical data structures, polymorphism, encapsulation, and of course, inheritance. And if inheritance has somehow been developed, for example, in PostgreSQL , for example, encapsulation, which directly contradicts the openness and arbitrariness of combining values in SQL tuples, actually creates significant (possibly out of theoretical contradictions) obstacles to the effective use of a relational database system as a long-term state object storage class.
')
However, the prevalence of relational database management systems, their relative efficiency in executing requests for large and very large data arrays, the wide possibilities of combining a heterogeneous computing environment through a relational database management system, and other advantages associated with using such database management systems make it necessary to compromise the convenience of system design in object -oriented style and limitations imposed on the designed system using these DBMS.
The main support for combining the object and relational paradigms within the framework of the ORM is the thesis that just as the relational table contains many elements (rows) of one structure, so the class combines many objects having a single structure and behavior. Therefore, one of the most common patterns commonly used in ORM implementations is the mapping of a class into a table, with the fields of the table being the attributes (all or part, uniquely defining the state) of class objects.
Figure 1 The most common form of object-relational mapping. Classes are mapped to tables, attributes are mapped to table fields
Any technical implementation has its limitations, and the technology of relational DBMS based on the SQL language, far from its theoretical predecessor - Codd algebra , is not an exception. In this case, all the technical limitations of SQL associated with the very existence of the table, as a physical carrier of tuples of values that are interconnected by a one-to-one relationship, naturally move to the class mapped to such a table using the ORM.
Figure 2 One of the problems with direct mapping of classes to tables: the display of attributes that are multiple in character requires separate tables.
Relational mapping of collections
The concept of relational mapping of collections (Collection-Relational Mapping, CoRM) is based on the fact that the table, as a long-term repository of object states, has a completely adequate image in any developed object-oriented environment, namely, the collection (Collection).
Storing the state of a collection of objects as a SQL table is far from a new invention. So, half of the packages dedicated to storing data in the standard python library are dedicated to this technology. The novelty of the CoRM approach lies in the fact that disparate collections of objects are combined by well defined (well-defined) relational relationships between these collections.
(the following updated: 05-30-2013, as I was rightly pointed out, document-oriented DBMS and MongoDB in particular, can also be considered as a prototype of CoRM)
CoRM, as well as document-oriented DBMS and MongoDb in particular, does not impose any restrictions on the ability of different objects of the same class to store their state in different collections, as well as on the ability of the collection to simultaneously contain objects belonging to different classes. The main difference of CoRM from document-oriented DBMS and tools based on them, like ORM, is that CoRM retains the possibility of using SQL (in a slightly modified form) and using relational relations between objects. CoRM differs from the traditional ORM approach in that the collection is not tied directly to the class and theoretically can contain any object, while meeting the minimum requirements for this object (namely, the ability to serialize in some special way). At the same time, these requirements do not include any restrictions on the structure of the object, the use of special data types, and so on.
The latter circumstance distinguishes the CoRM approach, including from the well-known SQLAlchemy library , which also manipulates collections and classes that are separately tied to collections.
The relational relationship between the elements of collections is determined by the presence and content (return value) of the selected properties (properties), attributes, or deterministic ( deterministic ) methods of the objects in the collection. Such selected properties will be called indexes of the collection. Thus, the collection and its indexes are the link between the object-oriented programming paradigm that supplies index values and the relational SQL repository paradigm, which uses the resulting index values to establish relational relationships between stored objects.
Figure 3 The collection and its indexes are the link between the object and relational data models.
Delving into the relational paradigm, one can define the concept of keys (Key) of a collection, each of which will refer to some combination of indexes of this collection, defining additional optimization and restrictive properties for this combination, for example, the uniqueness of the key (composite in general) within the collection.
The individual keys of a collection can serve as foreign keys for accessing objects stored in another collection, just like a foreign key in a table serves to establish relational relationships with another table. In exactly the same way as a foreign key in a relational DBMS, a foreign key in relational mapping of collections can be used to maintain the integrity of the data, prohibiting the storage of such a foreign key value that does not match any of the key values in the target for the foreign key collections.
The possibility of the practical use of relational relations between collections is determined by the placement of their associated tables in one database. The reflection of this fact for the programmer is the presence of a special storage object (Storage), which determines the specificity of the connection to the database and the general structural and functional characteristics of the DBMS, and also contains access points to the collections, tables for which are contained in this database.
Turning to collections for sampling data, in filtering, grouping, ordering expressions, the programmer manipulates not the properties of the objects stored in the collection, but the values of the indexes, resulting in a list of objects, or a list of tuples composed of objects and additionally counted expressions (defined on collection index values). The objects themselves remain completely encapsulated inside the collection until they are deserialized upon receiving the results of the query.
Encapsulating an object inside a collection and isolating the stored state of the object from the indexes available (as opposed to the state of the object) from the relational repository make senseless attempts to display expressions (filtering, grouping, calculating additional return values and ordering) for any similarity of expressions used by the object language (python in our case), as it happens for example in SQLAlchemy. Instead, a query from a collection can be formulated in a language as close as possible to SQL, as is done for example using Google App Engine Datastore . The GQL language used when accessing Google Datastore collections is an almost optimal pattern (of course, with the exception of the strange restrictions imposed on this language by its implementation) of a language that could be used to get data from collections using CoRM. Names appearing in language expressions should obviously refer to indexes and keys defined on collections, and not to attributes of a stored object hidden from the relational repository.
Bringing the collection query syntax out of the object language syntax allows precompilation and caching of compiled target storage requests, leaving the possibility of deserializing an object from the received data, which can lead to significant optimization of access speed to objects whose state is stored in the relational storage (it should be noted that the issue of optimizing access to objects in the collection, generally speaking, is quite painful for existing ORMs).
An interesting addition is that encapsulation and selection of indexes of a collection, as a separate entity, among other things, make it easy to implement dynamic indexes, the values of which are not directly contained in the attributes of the object's stored state, but are uniquely calculated from them.
Instead of output
Relational mapping of collections, when implemented, can be an excellent alternative to existing ORM implementations, allowing you to remove the application's entity from the constraints of relational storage.
Attention, question:
Source: https://habr.com/ru/post/181213/
All Articles